網易互娛全球監控體系:億萬級指標下,從分鐘級到秒級監控的演進
在開始進入主題之前,我想先給大家科普一個名詞——可觀測性,它主要有Tracing(鏈路追蹤)、Logging(事件日志)、 Metric(聚合指標)三個大部分,我今天分享的主題主要圍繞的是Metric部分。

為什么叫聚合指標?因為我們收集存儲的指標很多,大部分場景下我們關注的是指標的聚合值,比如1分鐘內或者5分鐘內的最大值、平均值等,或者是像一些 Top10的數據,或者是一些分位值,比如95分位或90分位,代表的產品大家也或多或少地接觸過,比如ELK是Logging的一個代表,Prometheus是近幾年比較火的。
一、自研時序數據庫EyesTSDB的介紹
第一部分我會從概覽、架構設計、核心功能、應用場景、問題與挑戰5個方面向大家介紹我們自研的時序數據庫EyesTSDB。
?1、概覽
我們自研的時序數據庫是支持全球監控的,它覆蓋了全球10多個國家和20多個地區,也支持國內私有云、公有云和混合云的監控,能夠同時滿足公司游戲出海的監控需求。

我們有多種監控方式,包括基礎監控、網絡監控、進線程和業務自定義等監控。
我們也有豐富的數據采集方式,目前有1000+個Agent采集的插件,SDK上報或通過HTTP等網絡協議上報監控數據,還支持內部的日志數據轉化,以便程序開發時能夠快速接入我們的監控平臺。
另外我們的服務對象包括我們的基礎設施,有超過30萬的物理機,以及云監控、k8s的容器監控,服務產品包括公司的頭部產品,比如夢幻西游、大話西游、陰陽師等。
上圖也列舉了我們目前的量級,我們現在的監控實體有1500萬,總的持續指標數量達到了15億。
?2、架構設計
接下來介紹我們的架構設計,這是一個簡化版的架構圖,可以分為上下兩個部分,上面是監控中心,下面是Region區域。

1)監控中心
監控中心包括前端系統UI和報警界面,以及下面的監控調度、數據總線、數據存儲和插件倉庫,這幾方面后面都會詳細介紹。
2)監控Region
監控Region主要包括Region節點以及被監控的機器,被監控的機器會安裝一個Agent插件。
- Arbiter:我們的監控調度中心,也是一個核心的模塊,它會結合CMDB生成監控機器的配置,也負責Region的保活和調度,使用Active-Standby的主備模式保證高可用。
- 數據總線:主要負責收集監控數據,然后通過kafka流轉。
- 數據存儲:我們設計了冷熱存儲,以存儲我們的時序數據。
- 插件倉庫:是我們的一個特色,會聯動gitlab保存用戶的插件,用戶可以通過自定義插件代碼實現想要的任何監控方式。
- 監控調度:結合cmdb生成配置,負責Region的保活與調度,使用Active-Standby的模式保證高可用。
- Agent:負責采集監控指標上報到Region,統一由Region上報到數據總線,包括核心模塊、系統插件、網絡插件以及用戶自定義插件。

右邊的圖是一個服務端監控的基礎架構。當CMDB發生變更時,Arbiter會去訂閱變更,然后生成一個最新的配置,下發到Region區域,比如Publisher收到變更之后,會同步到agent去詢問,agent會詢問Arbiter:我應該到哪一個Publisher上報數據?然后Arbiter會告訴它所屬的Region和Publisher列表,agent嘗試連接,成功就會入網,它會與Publisher保持一個?鏈接,把它產生的數據全部交給Publisher去中轉。Publisher到中央我們會做網絡優化,比agent直接連到中央會快很多。
?3、核心功能
1)監控對象設計
接下來給大家講一下我們的監控對象設計,這也是我們的核心功能之一。

我們把監控對象抽象為Entity,用EntityType描述它是屬于什么類型的,用Tag描述它的屬性。同時tag也會有一個類似交叉表的用途,把entity關聯在一起,比如機器是一類實體,進程是一類實體,而具體的機器名如hostname01是機器的一個Entity,正在運行的agent進程是進程的一個實體,最終我們可以通過Entity或Metric的tag過濾到我們期望得到的TimeSeries(時序數據)。目前我們大概有500+個EntityType,1500萬Entity實體模型,覆蓋了大約15億的時序指標。
2)自定義插件監控(python)
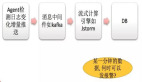
我剛才提到了有一個測試是我們的自定義插件,這里講一下它的工作流程。
①首先用戶在前端界面創建插件,我們會自動創建一個gitlab倉庫;
②然后用戶會在這個倉庫里編寫插件代碼,代碼提交后,會觸發pip包的構建;
③監控調度中心會生成Agent所需的插件配置,然后下發到Agent;
④Agent獲取到插件信息后,從pip源拉取pip包并安裝運行。

這里也給大家看一下我們插件的代碼量,例子它其實我們這里定義了一個基類,用戶只需要實現這個sample方法即可。
3)數據總線
插件安裝之后,監控數據是怎么流轉的?這是由我們的數據總線控制的。

各種上報端的數據匯總到kafka后,我們會有一個模塊進行數據的清洗與預處理,然后再流轉到下一個kafka,用于存儲、報警或者其他訂閱系統。同時我們也有一個預聚合的模塊用于對用戶關注的數據進行一次預聚合,能夠減少數據量,加快數據查詢,預聚合的規則可以從我們的UI上進行配置。
4)數據存儲
下面介紹我們的數據存儲,它具有冷熱分離、過期刪除和HDFS永久存儲的特點。

- 冷熱分離:數據總線會流到kafka,由數據的寫入模塊負責寫到我們的熱數據庫,我們使用Redis進行熱數據的存儲,只存每個實體6小時的數據,然后通過冷數據寫入模塊每半小時把Redis中的數據寫到MongoDB的冷庫中。
- 過期刪除:我們的冷庫分成4種粒度:1分鐘、5分鐘、30分鐘、1天,當用戶查的時間范圍不同時,我們會根據時間范圍選擇不同粒度的數據庫查詢。每一種粒度的保存周期不一樣,比如1分鐘只保存7天,5分鐘保存30天,數據過期會自動刪除。
- HDFS歸檔存儲:每天通過歸檔寫入模塊把冷數據庫中的時序數據存儲到廉價的HDFS中,用于AI、異常檢測等數據分析的業務場景。
當用戶發起查詢的時候,我們會根據時序數據庫的UUID拉取到時序數據,再根據UUID查詢到對應的時序數據,然后把冷熱數據合并完再返回給用戶。
?4、應用場景
接下來給大家看一些應用場景,主要有4個應用場景,分別是機器視圖、進程視圖、容器視圖和一個我們自定義的儀表盤。
1)機器視圖
主要負責一些基礎監控的機器,我們關注的基礎指標有CPU、內存、IO等,我們會與CMDB做一些聯動的,分群組、服務、機器三元組,一臺機器可以綁定不同的服務,再綁定到一個群組上,我們就可以在這里面做不同的樹形展示。

當點到具體某一個機器時,我們會展開這個機器的面板,可以看到詳細的時序數據指標,也可以選擇聚合方式,auto是一個時間粒度,剛才講到我們會根據不同的查詢范圍選擇不同的粒度展示給用戶,面板左邊也可以切不同類型的數據進行查看。
2)進程視圖

這里展示的是我們的進程視圖,我們可以把實體類型的tag做一個目錄層級展示,比如我有三個進程,都屬于一個進程組,我在這上面可以看到Redis最大的CPU使用率、最大的RSS內存使用率等信息。點到具體的每一個層級下可以展示每一個進程具體的指標詳情,再點開就像剛才展示的機器視圖的面板,會有更加詳細的指標。
3)儀表盤
再給大家介紹一下我們自定義的儀表盤,用戶可以在這里面配置實體類型。

儀表盤能夠填寫查詢的指標,過濾條件Tag,這里支持靈活的括號邏輯表達式 比如(a|b)&c,同時能夠按照tag進行分組聚合,也能指定返回的時間間隔,默認會根據查詢范圍算出一個合適的間隔。
配完之后即可按不同的類型展示我們的數據,比如這是一個大盤,它會展示我們整個項目運行了哪些服務,服務的基礎指標使用的情況,也可以點開機器詳情或一些其他的業務監控之類的。
?5、問題與挑戰
這一套監控系統運行了好幾年,看起來也沒有什么問題,但是我們知道科技發展是日新月異的,比如從之前的單體架構到分布式架構,以及到現在的service mesh的服務網格化,我們傳統的監控也很難滿足用戶的需求。
- 整套的監控系統設計是基于分鐘粒度設計的,最低只能存儲1分鐘的監控數據,無法滿足一些敏感業務的監控場景,比如數據庫的OP監控,1分鐘會發生很多次,導致錯過了波峰波谷,從而會導致DBA處理不及時而影響業務。
- 越來越多的云原生場景監控粒度都是秒級,業務期望也能支持到秒級的監控。
- 這一套TSDB基本是基于python寫的,在海量的數據處理上,python顯得有點力不從心,雖然我們使用golang重構了大部分模塊,但是還有部分核心模塊由于復雜性沒有重構。
二、結合開源指標設計秒級監控
我們要怎么去支持秒級?其實我們也做過一些調研:

- Thanos,目前內部有用過OpenTSDB做存儲,但是不支持正則查詢,而且第三方存儲、集群管理等需要較大的人力與資源成本。
- 原生的Prometheus是單機存儲,無法支持集群橫行擴容,也滿足不了需求。
- EyesTSDB改造支持秒級,需要在Agent端支持秒級采集,然后存儲端分粒度存儲,基本屬于推倒重建,收益不明顯。
最終我們選擇了一個支持集群部署的Prometheus遠端存儲,既能滿足秒級、又能支持云原生等場景——VictoriaMetrics。VictoriaMetrics是一個開源的時序數據庫,有以下幾個特點:
- 開源時序數據庫
- 快速高效可擴展
- 高性能監控系統
- 開源版永久免費
此外,它還支持上面講到的Prometheus查詢API,也有較高的壓縮比,支持多種協議寫入,也支持OpenTSDB的HTTP寫協議。最重要的一點是它支持多租戶,因為目前我們這套EyesTSDB也是多租戶的,不同產品是按租戶接進來的。
?1、目錄結構
首先介紹一下VictoriaMetrics的目錄結構,它把數據和索引分開了,data是它的數據目錄,indexdb是它的索引目錄。

data數據目錄里分成big目錄和small目錄,為什么要分成big目錄和small目錄?
這個主要是從磁盤空間占用上來考慮的。時序數據經常讀取最近寫入的數據,較少讀歷史數據。而且,時序數據的數據量比較大,通常會使用壓縮算法進行壓縮,所以歷史的數據就放在big目錄里,它會用比較高的壓縮算法進行壓縮,而small會用比較低的壓縮級別壓縮數據,small會定期合并成big。
index是使用保存周期保存的,主要有兩個,一個是當前的保存周期,比如我配置了一個月的保存周期,那么一個月的數據都會存在這里,然后這是下一個保存周期的數據。索引支持保存最小時間和最大時間,便于做一些二分查找,能夠快速定位到具體的數據位置。
?2、數據結構
這里講一下它大概的數據結構:

- AccountID和ProjectID是它的租戶信息;
- MetricGroupID是它的指標分組ID;
- JobID和InstanceID是tag指標,比如JobID是第一個tag的哈希值,InstanceID是第二個tag的哈希值;
- 最后的MetricID是它的指標ID,是一個自增的時間戳ID。
?3、整體架構

右邊的圖是它的整體架構,我們可以從中間看起,中間主要是存儲,上下分別是查詢和寫入,它的查詢是vmselect,協助是vminsert,兩者是沒有狀態的,我可以隨時擴增節點。
再下面是寫入協議,它支持Prometheus的寫入或InfluxDB的線路協議寫入。
其中的存儲其實是有狀態的,但也支持我們的橫向擴容,比如存儲塊碼,我們可以加入節點支持數據廠寫入。
目前它無縫支持Grafana和Prometheus API的查詢。
以上是VictoriaMetrics的架構,我們怎么將其改造成為我們能用的架構?
?4、新架構設計

這是我們目前一整套新的架構,中間紅框部分就是我們剛才講到的VictoriaMetrics的基礎架構。
我們可以從上面入口看起,agent,比如我有一個exporter,它會寫入到transfer,這個是支持Remote Write協議的,然后會流轉到一個kafka,下面有一個proxy模塊,負責數據的預處理和清洗,然后發給我們的報警系統做一些報警匹配和規則匹配。再下面是它的存儲,左邊是數據存儲,右邊是index的存儲,這一方面我們有進行改造。
上面主要是一些API和UI的模塊,底部我們可以看到右邊有一個冷數據的存儲節點,這一塊會寫入到冷數據,data集群里我們增加了一個Shuffle模塊,它負責解析vm的文件,將同一個指標的所有時序數據發送到冷數據存儲,然后由downsample降采樣模塊進行降粒度存到冷存儲集群中。Data cluster有多套,而index cluster是公用一套,從而降低存儲成本。
?5、如何與內部CMDB聯動
那么秒級和云原生我們都支持了,最后如何繼承我們的CMDB聯動?

剛才講到我們的Entity和Metric都會有tag,而這些tag就包括我們內部的CMDB屬性,比如右側圖。我們是將這些tag單獨存了一份,與Metric的tag是分開的。它會把指標與TSID去做索引,最后是tag與MetricID去做索引,每一個tag它都會去做一遍索引。

TSDB分為兩個模塊,第一個是Meta信息,我們可以看到最上面一條例子,它是一個指標,后面是它的時間戳和值,Meta信息會包括指標名、labels。下面一部分是它的時序數據,timestamp和value就存在這邊,中間通過一個ID關聯起來。
大部分TSDB的不支持單個label key、多個label value,如 gid=1,gid=2。如何把CMDB的tag加到labels中?

我們是將其單獨一份存儲下來的,tag是用不同的index索引去存的,因為VictoriaMetrics本身有index的命名空間,不同的命名空間是不一樣的,然后我們增加了命名空間去傳數據,同時也增加了這些tag的增刪查改接口以滿足我們CMDB tag的寫入和查詢,再提供到不同的數據庫去查詢。
?6、新增功能
1)vmshuffle
vmshuffle是我們自己做的一個功能,因為一個指標可能存儲在不同節點上,而我們是把一個指標的數據統一匯總到一個存儲節點上,然后定期存儲到一個冷數據集群上。
目前支持的場景:
- 長時間以前一小段時間內的高精度數據查看
- 歷史數據統計和分析
- 利用歷史數據進行模型訓練
我們如何把一個指標存儲到一個節點上?其實我們是按它提供的一些原數據進行統一規整,比如MetricGroupID、ProjectID、AccountID、MetricName,哈希到不同的vmstorage里,同一個Metric下的數據會存儲在相同的vmstorage里,然后經過Metric之后,數據會出現在文件的相鄰位置。
2)vmdownsample
另外我們還做了一個降采樣的功能,我們之前那套EyesTSDB有不同力度的降采樣,那么這一套我們是怎么去支持的?
我們有一個備份集群,剛才講的vmshuffle統一把數據存在冷數據集群,然后每一個節點會跑一個數據聚合的模塊,然后去導,因為一個指標只會存儲在一個節點上,把該指標一整塊數據拉出來,比如一天跑一次,就把前一天的數據拉出來做聚合,然后按不同的力度,比如5分鐘、30分鐘、一天存儲到不同的集群上,就能滿足從之前的EyesTSDB到這一套的過渡,都能完全兼容支持。
?7、問題與挑戰
1)如何在查詢側讓tag和label一樣都能過濾到時序數據?
剛才講到我們開辟了一個label的命名空間去存儲的,其實它與原本存儲的label命名空間是類似的,那么它就能夠復用已有的支持的功能,比如label的promql的查詢語句、過濾、聚合等功能。
2)如何滿足已有的業務查詢場景?
它已經支持promql的查詢語法了,那么我們可以通過靈活的查詢語句匹配到我們的儀表盤。比如我們之前提供的那些聚合方式,avg、min、sum等,它可以通過avg(avg_over_time)支持不同曲線、不同時間區間的聚合值,比如avg_over_time用作5分鐘內的平均值,然后avg則是把這5分鐘內的平均曲線再做一個平均,就能滿足到上面提到的儀表盤的查詢。
三、未來展望
?1、數據質量
目前我們存儲的數據比較多,但是有一些數據看起來其實數據質量不高,比如用戶上報各種各樣的數據,但他真正關注的可能只有20%~30%,我們后續會提高數據質量,提高我們存儲的效能。
?2、業務多元化需求
我們內部有多套集群,不同的集群有不同的需求,比如一套集群需要做到一些去重,一些集群不需要做CMDB關聯,以及我們后續甚至會做一些SaaS化之類的。
?3、Agent與調度中心性能
這是EyesTSDB那一套的性能優化,老的那套是Python寫,中間也用GoLand進行重構,目前還在重構中,未完全重構。
?4、回饋開源
最后主要是我們會開源,我們開發的一些額外的功能后續穩定之后,也會考慮反哺開源社區與大家共同發展一起進步。我們還有很多設想,比如自動化集群搭建、SaaS化集群管理,后面有機會再跟大家分享。
Q&A
Q1:這個數據庫采用的是哪種冷熱數據分離方案?是否會有數據丟失風險?
A1:新的這一套我們有一個熱數據庫,冷數據是從備份集群里同步下來的。數據丟失的風險方面,目前我們主庫有一個儲備,我們的各種降采樣粒度的冷庫也是都有儲備的。
Q2:CMDB數據的準確性如何提升?有什么方案嗎?
A2:這一方面我們EyesTSDB那一套其實有一些延遲,比如這么大體量的CMDB數據如何流到數據里面再存儲下來,或者到報警部分其實是有延遲的。然后我們是有與CMDB系統合作做到一些實時同步,我們新的一套CMDB有一些拓撲結構,它用圖數據庫存儲CMDB的數據,然后當中間某個節點發生變更時,它會觸發一個變更消息,收到消息之后會把這個節點相關的信息都進行更新,這里涉及一些批量合并以及時間的策略,這套也是我們目前正在做的,基本上已經落地了,后面有機會再跟大家分享一下我們是怎么做的。