在 Python中處理大型機器學習數據集的簡單方法
本文的目標受眾:
- 想要對大量數據集執行 Pandas/NumPy 操作的人。
- 希望使用Python在大數據上執行機器學習任務的人。

本文將使用 .csv 格式的文件來演示 python 的各種操作,其他格式如數組、文本文件等也是如此。
為什么我們不能將 pandas 用于大型機器學習數據集呢?
我們知道 Pandas 使用計算機內存 (RAM) 來加載您的機器學習數據集,但是,如果您的計算機有8 GB 的內存 (RAM),那么為什么 pandas 仍然無法加載 2 GB 的數據集呢?原因是使用 Pandas 加載 2 GB 文件不僅需要 2 GB RAM,還需要更多內存,因為總內存需求取決于數據集的大小以及您將在該數據集上執行的操作。
以下是加載到計算機內存中的不同大小的數據集的快速比較:

此外,Pandas只使用操作系統的一個內核,這使得處理速度很慢。換句話說,我們可以說pandas不支持并行(將一個問題分解成更小的任務)。
假設電腦有 4 個內核,下圖是加載 CSV 文件的時候 pandas 使用的內核數:

普遍不使用 pandas 處理大型機器學習數據集的主要原因有以下兩點,一是計算機內存使用量,二是缺乏并行性。在 NumPy 和 Scikit-learn中,對于大數據集也面臨同樣的問題。
為了解決這兩個問題,可以使用名為Dask的python庫,它能夠使我們在大型數據集上執行pandas、NumPy和ML等各種操作。
Dask是如何工作的?
Dask是在分區中加載你的數據集,而pandas通常是將整個機器學習數據集作為一個dataframe。在Dask中,數據集的每個分區都被認為是一個pandas dataframe。

Dask 一次加載一個分區,因此您不必擔心出現內存分配錯誤問題。
以下是使用 dask 在計算機內存中加載不同大小的機器學習數據集的比較:

Dask 解決了并行性問題,因為它將數據拆分為多個分區,每個分區使用一個單獨的內核,這使得數據集上的計算更快。
假設電腦有 4 個內核,以下是 dask 在加載 5 GB csv 文件時的方式:

要使用 dask 庫,您可以使用以下命令進行安裝:
pip install dask
Dask 有幾個模塊,如dask.array、dask.dataframe 和 dask.distributed,只有在您分別安裝了相應的庫(如 NumPy、pandas 和 Tornado)后才能工作。
如何使用 dask 處理大型 CSV 文件?
dask.dataframe 用于處理大型 csv 文件,首先我嘗試使用 pandas 導入大小為 8 GB 的數據集。
import pandas as pd
df = pd.read_csv(“data.csv”)
它在我的 16 GB 內存筆記本電腦中引發了內存分配錯誤。
現在,嘗試使用 dask.dataframe 導入相同的 8 GB 數據

dask 只用了一秒鐘就將整個 8 GB 文件加載到 ddf 變量中。
讓我們看看 ddf 變量的輸出。

如您所見,執行時間為 0.5 秒,這里顯示已劃分為 119 個分區。
您還可以使用以下方法檢查數據幀的分區數:

默認情況下,dask 將我的 8 GB CSV 文件加載到 119 個分區(每個分區大小為 64MB),這是根據可用的物理內存和電腦的內核數來完成的。
還可以在加載 CSV 文件時使用 blocksize 參數指定我自己的分區數。

現在指定了一個字符串值為 400MB 的 blocksize 參數,這使得每個分區大小為 400 MB,讓我們看看有多少個分區

關鍵點:使用 Dask DataFrames 時,一個好的經驗法則是將分區保持在 100MB 以下。
使用以下方法可調用dataframe的特定分區:

也可通過使用負索引來調用最后一個分區,就像我們在調用列表的最后一個元素時所做的那樣。
讓我們看看數據集的形狀:

您可以使用 len() 檢查數據集的行數:

Dask 已經包含了示例數據集。我將使用時間序列數據向您展示 dask 如何對數據集執行數學運算。

導入dask.datasets后,ddf_20y 加載了從 2000 年 1 月 1 日到 2021 年 12 月 31 日的時間序列數據。
讓我們看看我們的時間序列數據的分區數。

20 年的時間序列數據分布在 8035 個分區中。
在 pandas 中,我們使用 head 打印數據集的前幾行,dask 也是這樣。

讓我們計算一下 id 列的平均值。

dask不會打印dataframe的總行數,因為它使用惰性計算(直到需要時才顯示輸出)。為了顯示輸出,我們可以使用compute方法。

假設我想對數據集的每一列進行歸一化(將值轉換為0到1之間),Python代碼如下:

循環遍歷列,找到每列的最小值和最大值,并使用簡單的數學公式對這些列進行歸一化。
關鍵點:在我們的歸一化示例中,不要認為會發生實際的數值計算,它只是惰性求值(在需要之前永遠不會向您顯示輸出)。
為什么要使用 Dask 數組?
Dask 將數組分成小塊,其中每個塊都是一個 NumPy 數組。

dask.arrays 用于處理大數組,以下Python代碼使用 dask 創建了一個 10000 x 10000 的數組并將其存儲在 x 變量中。

調用該 x 變量會產生有關數組的各種信息。
查看數組的特定元素

對dask 數組進行數學運算的Python示例:

正如您所看到的,由于延遲執行,它不會向您顯示輸出。我們可以使用compute來顯示輸出:

dask 數組支持大多數 NumPy 接口,如下所示:
- 數學運算:+, *, exp, log, ...
- sum(), mean(), std(), sum(axis=0), ...
- 張量/點積/矩陣乘法:tensordot
- 重新排序/轉置:transpose
- 切片:x[:100, 500:100:-2]
- 使用列表或 NumPy 數組進行索引:x[:, [10, 1, 5]]
- 線性代數:svd、qr、solve、solve_triangular、lstsq
但是,Dask Array 并沒有實現完整 NumPy 接口。
你可以從他們的官方文檔中了解更多關于 dask.arrays 的信息。
什么是Dask Persist?
假設您想對機器學習數據集執行一些耗時的操作,您可以將數據集持久化到內存中,從而使數學運算運行得更快。
從 dask.datasets 導入了時間序列數據

讓我們取數據集的一個子集并計算該子集的總行數。

計算總行數需要 27 秒。
我們現在使用 persist 方法:

持久化我們的子集總共花了 2 分鐘,現在讓我們計算總行數。

同樣,我們可以對持久化數據集執行其他操作以減少計算時間。

persist應用場景:
- 數據量大
- 獲取數據的一個子集
- 對子集應用不同的操作
為什么選擇 Dask ML?
Dask ML有助于在大型數據集上使用流行的Python機器學習庫(如Scikit learn等)來應用ML(機器學習)算法。
什么時候應該使用 dask ML?
- 數據不大(或適合 RAM),但訓練的機器學習模型需要大量超參數,并且調優或集成技術需要大量時間。
- 數據量很大。

正如你所看到的,隨著模型大小的增加,例如,制作一個具有大量超參數的復雜模型,它會引起計算邊界的問題,而如果數據大小增加,它會引起內存分配錯誤。因此,在這兩種情況下(紅色陰影區域)我們都使用 Dask 來解決這些問題。
如官方文檔中所述,dask ml 庫用例:
- 對于內存問題,只需使用 scikit-learn(或其他ML 庫)。
- 對于大型模型,使用 dask_ml.joblib 和scikit-learn estimators。
- 對于大型數據集,使用 dask_ml estimators。
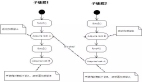
讓我們看一下 Dask.distributed 的架構:

Dask 讓您能夠在計算機集群上運行任務。在 dask.distributed 中,只要您分配任務,它就會立即開始執行。
簡單地說,client就是提交任務的你,執行任務的是Worker,調度器則執行兩者之間通信。
python -m pip install dask distributed –upgrade
如果您使用的是單臺機器,那么就可以通過以下方式創建一個具有4個worker的dask集群

如果需要dashboard,可以安裝bokeh,安裝bokeh的命令如下:
pip install bokeh
就像我們從 dask.distributed 創建客戶端一樣,我們也可以從 dask.distributed 創建調度程序。
要使用 dask ML 庫,您必須使用以下命令安裝它:
pip install dask-ml
我們將使用 Scikit-learn 庫來演示 dask-ml 。
假設我們使用 Grid_Search 方法,我們通常使用如下Python代碼

使用 dask.distributed 創建一個集群:

要使用集群擬合 scikit-learn 模型,我們只需要使用 joblib。