論文修改100遍也別慌!Meta發布全新寫作語言模型PEER:參考文獻都會加
2020年5月至今,GPT-3發布近兩年半的時間里,在其神奇的文本生成能力加持下,已經能夠很好地輔助人類進行寫作了。
但GPT-3說到底也就是個文本生成模型,與人類的寫作過程可以說是完全不同了。
比如要寫一篇論文或者作文,我們需要先在腦海里構造一個框架,查相關資料,打草稿,再找導師不斷地修改、潤色文字,期間可能還會修改思路,最終才可能成為一篇好文章。
而生成模型得到的文本也就是能滿足語法要求,在內容編排上就毫無邏輯,也沒有自我修改的能力,所以讓AI獨立寫作文這件事還很遙遠。
最近Meta AI Research和卡內基梅隆大學的研究人員提出一個新的文本生成模型PEER(計劃Plan,編輯Edit,解釋Explain,重復Repeat),完全模擬人類寫作文的過程,從打草稿、征求建議到編輯文本,再不斷迭代。

論文地址:https://arxiv.org/abs/2208.11663
PEER解決了傳統語言模型只會生成最終結果,并且生成文本無法控制的問題,通過輸入自然語言命令,PEER可以對生成文本進行修改。

最重要的是,研究人員訓練了多個PEER的實例,能夠填補寫作過程中的多個環節,借此可以使用自訓練(self-training)技術提高訓練數據的質量、數量以及多樣性。
能生成訓練數據,也就代表PEER的潛力遠不止寫作文那么簡單,還可以在其他沒有編輯歷史的領域使用PEER,讓它自己逐漸提高遵循指令、編寫有用評論和解釋其行為的能力。
NLP也來仿生學
大型神經網絡在用自然語言進行預訓練后,文本生成的效果已經非常強了,但這些模型的生成方式基本就是從左到右一次性輸出結果文本,與人類寫作的迭代過程有很大不同。
一次性生成也有很多弊端,比如無法追溯文本中的句子進行修改或完善,也無法解釋某句文本的生成原因,并且檢驗生成文本的正確性也很難,結果中經常會生成幻覺(hallucinate)內容,即不符合事實的文本。這些缺陷也限制了模型與人類合作進行寫作的能力,因為人類需要的是連貫且符合事實的文本。
PEER模型通過在文本的「編輯歷史」上進行訓練,使得模型能夠模擬人類的寫作過程。

1、PEER模型運行時,需要用戶或模型指定一個計劃(Plan),通過自然語言描述他們想要執行的行動(action),比如說add some information或者fix grammar errors;
2、然后通過編輯(Edit)文本來實現這一行動;
3、模型可以用自然語言和指向相關資源來解釋(Explain)該次編輯結果,比如在文末加一個參考文獻;
4、重復(Repeat)該過程,直到生成的文本不再需要進一步的更新。
這種迭代的方法不僅使該模型可以將寫一個連貫、一致、事實性的文本這一復雜的任務分解成多個較容易的子任務,還允許人類在生成過程中的任何時刻進行干預,引導模型向正確的方向發展,提供用戶的計劃和評論,或者自己上手進行編輯。

通過方法描述就可以看出來,功能實現上最難的并不是用Transformer搭建模型,而是找訓練數據,想要找到能夠以訓練大型語言模型所需的規模來學習這一過程的數據顯然是很困難的,因為大部分網站都沒有提供編輯歷史,所以通過爬蟲獲得的網頁沒辦法作為訓練數據。
即使通過爬蟲獲取不同時間相同網頁作為編輯歷史也不可行,因為沒有對該次編輯做出計劃或解釋的相關文本。
PEER與之前的迭代編輯方法類似,使用維基百科作為主要編輯和相關評論的數據來源,因為維基百科提供了完整的編輯歷史,包括對各種主題的評論,而且規模很大,文章中經常包含引文,對尋找相關文件很有幫助。
但僅依靠維基百科作為訓練數據的唯一來源也存在各種缺點:
1、僅使用維基百科訓練得到的模型在預期文本內容的樣子和預測的計劃和編輯方面需要和維基百科相似;
2、維基百科中的評論是有噪音的,因此在許多情況下,評論并不是計劃或解釋的恰當輸入;
3、維基百科中的許多段落不包含任何引文,雖然這種背景信息的缺乏可以通過使用檢索系統來彌補,但即使這樣的系統也可能無法為許多編輯找到支持性的背景信息。
研究人員提出了一個簡單的方法來解決因維基百科是唯一的評論編輯歷史來源而產生的所有問題:即訓練多個PEER實例,并用這些實例學習填充編輯過程的各個環節。這些模型可以用來生成合成數據作為訓練語料庫中缺失部分的替代。
最終訓練得到四個encoder-decoder模型:

1、PEER-Edit的輸入為文本x和一組文檔,模型輸出為計劃和編輯后的文本,其中p為計劃文本。

2、PEER-Undo的輸入為編輯后的文本和一組文檔,模型輸出結果為是否撤銷該次編輯。
3、PEER-Explain用來生成該次編輯的解釋,輸入為源文本、編輯后的文本和一組相關文檔。
4、 PEER-Document輸入源文本、編輯后的文本和計劃,模型輸出為該次編輯中最有用的背景信息。
PEER的所有變體模型都用來生成合成數據,既生成缺失的部分來補充的訓練數據,也用來替換現有數據中的「低質量」部分。
為了能夠對任意文本數據進行訓練,即使該段文本沒有編輯歷史,也使用PEER-Undo來生成合成的「后向」編輯,即對源文本反復應用PEER-Undo直到文本為空,再調用PEER-Edit在相反的方向進行訓練。
在生成計劃時,使用PEER-Explain來修正語料庫中許多低質量的評論,或者處理沒有評論的文本。從PEER-Explain的輸出中隨機采樣多個結果作為「潛在的計劃」,通過計算實際編輯的似然概率,并選擇概率最高的作為新計劃。
如果對于特定編輯操作無法找到相關文檔,則使用PEER-Document生成一組合成的文檔,包含執行該次編輯操作的信息。最關鍵的是,僅在訓練PEER-Edit這么做,在推理階段并不提供任何合成文檔。
為了提高生成的計劃、編輯和文檔的質量和多樣性,研究人員還實現了一個控制機制,即在模型被訓練生成的輸出序列中預置特定的控制標記,然后在推理過程中使用這些控制標記來指導模型的生成,標記包括:
1、type用來控制PEER-Explain生成的文本類型,可選值為instructon(輸出必須以不定式開頭to ....)和other;
2、length, 控制PEER-Explain的輸出長度,可選值包括s(少于2個詞), m(2-3個詞),l(4-5個詞)和xl(多于或等于6個詞);
3、overlap, 是否PEER-Explain生成的詞可以與編輯文本重復,可選值為true和false;
4、words,用來控制PEER-Undo在源文本和編輯后文本之間不同詞的個數,可選值為所有整數;
5、contains,用來確保PEER-Document輸出的文本包含某個substring
PEER沒有對PEER-edit引入控制符,即沒有假定用戶可能會用模型解決編輯任務的類型,使得模型更加通用。
在實驗對比階段,PEER使用LM-Adapted T5的3B參數版本預訓練初始化。
為了評估了PEER在不同領域中遵循一系列計劃、利用所提供的文檔和進行編輯的能力,特別是在沒有編輯歷史的領域中的表現,文中引入了一個新的數據集Natural Edits,一個針對不同文本類型和領域的自然發生的編輯的集合。
數據從三個英文網絡資源中收集獲得:從維基百科中收集百科全書式的頁面,從Wikinews收集新聞文章,從StackExchange的烹飪、園藝、法律、電影、政治、旅游和工作場所子論壇收集問題,所有這些網站都提供了帶有評論的編輯歷史,這些評論詳細說明了編輯的意圖,并將其作為計劃提供給模型。

在Wikinews和StackExchange子集的訓練中,只提供純文本數據,而非實際的編輯,從而測試在沒有編輯歷史的領域的編輯能力。
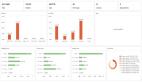
實驗結果可以看出PEER的表現在一定程度上超過了所有的基線,并且計劃和文檔提供了模型能夠使用的互補信息

在Natural Edits的所有子集上評估PEER后可以發現,計劃對各領域都有很大的幫助,這表明理解維基百科編輯中的計劃的能力可以直接轉移到其他領域。重要的是,在Natural Edits的所有子集上,PEER的領域適應性變體明顯優于常規的PEER,尤其是在園藝、政治和電影子集上有很大的改進(分別為84%、71%和48%的EM-Diff),也顯示了在不同領域中應用PEER時,生成合成編輯的有效性。
?
 ?
?