













三端一體計算方案:Unify SQL Engine
背景
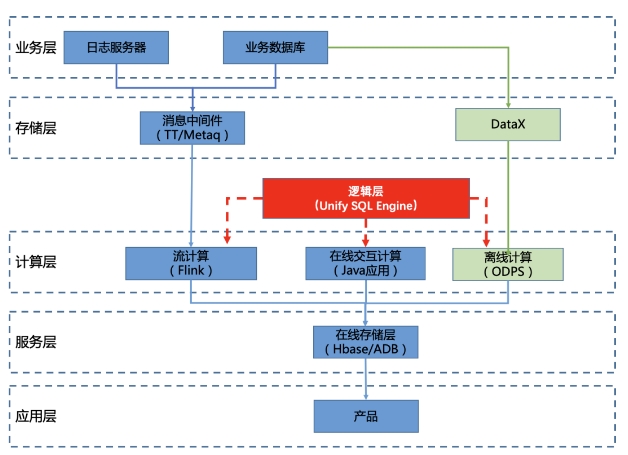
在漫長的數倉建設過程中,實時數倉與離線數倉分別由不同的團隊進行獨立建設,有大而廣的離線數倉體系,也有需要追求業務時效,需要建設實時數倉。然而,業務數據需求和數據產品需求中,往往需要把實時數據與離線數據結合在一起進行比對和分析,但是這兩個天然不一樣的數據存儲和計算結構,需要同時開發兩套數據模型。在數據處理過程中,實時數倉需要使用Blink/Flink 處理,離線需要寫ODPS SQL處理,還有在線計算模型,需要開發java代碼處理。

如上圖所示,實時數據與離線數據在存儲層、計算層、服務層,都是割裂分離、獨立建設的。實時數據,有著增量式計算的特性,需要快速的流轉與計算,它主要以DataHub、Flink、Hbase等異構系統做為支撐,串聯形成一個完整實時計算全鏈路。而離線數據,是定時、批量計算的特性,由存儲計算統一的ODPS系統做為支撐。它們除了計算鏈路的差異,還有著數據處理的邏輯差異:
- 流批處理不能復用,ODPS和Blink/Flink的SQL標準不一致,他們的底層調度和數據處理邏輯也有根本的差別,一個是以MR作為核心的批處理方式,一個是以Flink/Blink為核心的流處理。
- 有些流批處理場景需要調用HSF接口,調用HSF接口,在Java Spring環境里,是信手拈來的事情,但到了ODPS/Flink環境里,就變得額外的一個大挑戰,甚至不可實現,因為在ODPS/Flink是無法加載或者極難使用Spring容器的,這就會讓開發在面對復雜流處理場景,更傾向使用自己熟悉的Java環境,但同時也意味失去ODPS/Flink那種貼近業務表達的SQL表達。
- 計算處理除了流批處理,還更廣泛存在在線交互計算,這個和流處理異步處理還不太一樣,是需要同步計算并返回結果,這通常是在Java環境開發HSF接口,但如果你要對外同時提供三種能力:流計算、批計算和在線計算的時候,就面臨需要三端開發,流計算和批計算尚且還有SQL,雖然不太一致,但至少大同小異,但在線交互計算就是需要純Java開發了,將SQL翻譯成Java代碼可是個不小的挑戰。
Unify SQL VS 流批一體
面對三種計算模式,較低的研發效率、不可控的數據質量,以及臃腫數據接口服務的困境,三端(流計算、批計算、在線計算)一體計算的想法自然油然而生,在20年做價格力業務時候,我就一直思考有什么解法,其實,這個也是大數據架構經常面臨的問題,業界達成共識,可以歸納兩種方案:
? 流批一體計算
同一個引擎承載流、批兩種計算模式,在流計算模式下進行實時數據計算,在批計算模式下進行離線數據計算。

流批一體計算的典型架構是:Flink + Kappa架構。Flink可以實現基于SQL的流批一體的計算表達,復雜計算通過Java應用承接,價格力計算架構就是典型這種架構,但是這種架構存在以下問題:
- 沒有解決在線交互計算
Flink解決了流計算、批計算一體的能力,這兩種都是異步處理,只是時效不同而已,但沒有解決在線計算的能力,如果要提供在線計算能力,不得不在以下兩個方案選擇:
- 通過Java應用提供同步計算接口,這樣就存在兩套邏輯:一個是Flink實現的流批處理,另一個是Java實現的在線處理。
- 提供兩個接口,一個接口是發起計算請求,將計算請求交到Flink處理后,再提供一個輪訓查詢接口,查詢計算好后的數據,這個方案至少在計算上做到一套代碼,但這種同步轉異步處理的方案勢必會影響產品的設計。
- Flink的批處理吞吐量
Flink實現批處理,其實是有點一廂情愿,為啥這么說,因為其吞吐規模,跟MR批計算(ODPS)完全不是一個量級,如果Flink真能實現和ODPS完全對等的吞吐規模和資源成本,那完全不需要ODPS什么事了,但現實是,對于一些只有批量處理場景的(比如特征預處理、統計計算),ODPS仍然是第一優先選擇,只有當面臨流批同時存在的場景時候,并且對批處理規模要求不大時候,Flink的確提供非常不錯的一體化解決方案。
? Unify SQL
同一SQL代碼通過自動化轉義,翻譯到流計算引擎和批計算引擎上進行流、批計算,也包括翻譯到HSF接口代碼,提供在線交互計算能力。
Flink的流批一體架構非常優秀,能解決90%的流批一體問題,但不幸的是,我們有些業務場景(典型的價格計算場景),遠不是Flink寫寫SQL可以解決的:
- 整個電商是個非常復雜的業務體系,就以我所處在的營銷域里,就要面對招商模型、投放模型、活動模型、權益等等,這些都遠不是一個單一系統可以承接的,也不是一個單一團隊可以承接的,阿里針對這樣復雜的業務,設計了HSF這樣微服務電商架構,但是Flink和電商這樣的Java技術棧明顯是割裂的,怎么結合兩種體系架構,一方面發揮電商的微服務架構的紅利,一方面又能利用到Flink的SQL流批處理能力,考慮到Flink本身的局限性,與其讓Flink支持HSF,不如讓Java環境支持Flink SQL,換句話說,設計一個SQL引擎,它能通過sql的流處理方式,處理Java對象,將流引擎嵌入到Java里,隨調隨用。
- Flink的批引擎,在面對T級離線數據批量處理,是非常耗資源,幾乎不可用,正如上面所講的,Flink批處理的吞吐量遠不及ODPS的MR批處理,那么,我們為何不讓這樣計算仍然交接給ODPS處理,但是,ODPS和Flink的SQL標準不一致,需要兩端開發,現在問題變成:怎么統一ODPS和Flink的開發,說的再通俗點,我們可不可以在ODPS和Flink上面架設一層統一Unify SQL,這個SQL引擎可以翻譯成ODPS或者Flink能理解的處理(ODPS翻譯成MR程序,Flink翻譯成Stream Operator)方式,抹平ODPS和Flink的SQL語義差別。
- 如果僅僅是抹平ODPS和Flink的SQL差異,帶來的收益其實并不大,但是其統一SQL表達計算的設計,是可以進一步擴寬其應用范圍,比如在線交互計算,或者說,我們可以進一步打造統一計算引擎,包括編排不同模式的計算能力,比如:有些場景對時效要求比較高,我們可以調度Flink計算,對時效沒有要求,但數據量巨大,可以只調度離線計算,有些需要提供HSF接口,就調度應用啟動spring接口。
Unify SQL Engine
淘系價格計算引擎,以Flink + Kappa為核心的數據架構,關于這種數據架構演進,可以參考我其他文章,三種計算模式的疊加是價格服務計算引擎的常態模式,他們都在各自核心計算發揮自己最大的優勢:
- ODPS:離線批量計算引擎,核心優勢,非常高的計算吞吐量,但時效差,有面向MR和SQL編程模式,業務和BI友好,主要用在數據預處理、離線特征加工、常見維表ETL等。
- Flink:流式處理引擎,核心優勢,低延遲計算,時效好,極高的容錯和高可靠性,但吞吐量相比ODPS一般,有面向Stream API和SQL API的編程模式,業務和BI友好,主要用在實時數據加工(優惠、訂單等)、消息預處理等
- Java計算:核心優勢,豐富的電商Java HSF接口,復雜的領域模型,面向對象設計,開發友好,但是業務和BI不友好,容錯和可靠性依賴開發設計,延遲和吞吐量也高度依賴開發設計。
那么如何整合這3個不同計算架構,Flink提出一個引擎承接所有計算模式,也就是Flink的流批一體引擎,但這帶來的問題就是,不同計算模式,底層的引擎本身就很難完全周全到,與其去統一計算引擎,為何不統一表達和調度,而把真正的計算下放到各自計算引擎,這就是Unify Engine的核心思想。
? SQL引擎技術
在實現三端一體化時候,有個核心技術難點,就是SQL引擎,很多數據產品都自帶自己的SQL引擎,Flink內部有SQL引擎,ODPS內部有C++實現的SQL引擎,Hive也有,Mysql內部也有SQL解析引擎,這些SQL引擎都高度集成到各自的存儲和計算里,如果你說要找個獨立的可用在Java環境的SQL引擎,市面上有是有,不過要么是非常復雜的calcite sql引擎,要么是非常簡單的select * 簡易sql引擎,能做的事情非常少,開箱即用的幾乎沒有。但Unify SQL引擎又是實現三端一體化的核心組件,沒有它,其他什么事情都無從談起。從無設計一個SQL引擎成本是非常高的,其中不說復雜的語法解析,生成AST語法樹,就單單SQL邏輯計劃優化,就是非常復雜,幸運的是,業界是存在一個可以二次開發的SQL引擎,就是calcite SQL引擎,其實,很多SQL引擎都是基于calcite二次開發的,比如Flink、Spark內部的SQL解析引擎就是基于calcite二次開發的,我們設計的SQL引擎也是基于calcite的。Calcite 使用了基于關系代數的查詢引擎,聚焦在關系代數的語法分析和查詢邏輯的規劃,通過calcite提供的SQL API(解析、驗證等)將它們轉換成關系代數的抽象語法樹,并根據一定的規則或成本估計對AST關系進行優化,最后進一步生成ODPS/Flink/Java環境可以理解的執行代碼。calcite的主要功能:
- SQL解析:Calcite的SQL解析是通過JavaCC實現,使用JavaCC變成SQL語法描述文件,將SQL解析成未經校驗(unvalided AST)的AST語法樹。
- SQL校驗:無狀態校驗,即驗證SQL語句是否符合規范;有狀態校驗,通過和元數據驗證SQL的schema,字段,UDF是否存在,以及類型是否匹配等。這一步生成的是未經優化的RelNode(邏輯計劃樹)
- SQL查詢優化:對上面步驟的輸出(RelNode),進行優化,這一過程會循環使用優化器(RBO規則優化器和CBO成本優化器),在保持語義等價的基礎上,生成執行成本最低的SQL邏輯樹(Lo)
至于calcite的比較詳細的原理,可以詳解:Apache Calcite 處理流程詳解(地址:https://xie.infoq.cn/article/1df5a39bb071817e8b4cb4b29),這里不詳解了。有了calcite,解決了SQL->邏輯樹,但是真正執行SQL計算的,還需要進一步將邏輯數轉換成物理執行樹(Physical Exec DAG),在這個DAG,是包含可執行的Java代碼(JavaCode)片段,最后下發到不同執行環境,會被進一步串聯可被環境執行的鏈路,比如在ODPS環境,會生成MR代碼,在Flink環境,會被轉換成Stream Operator,在Java環境,會被轉換成Collector Chain,在Spring環境,會被轉換成Bean組件。
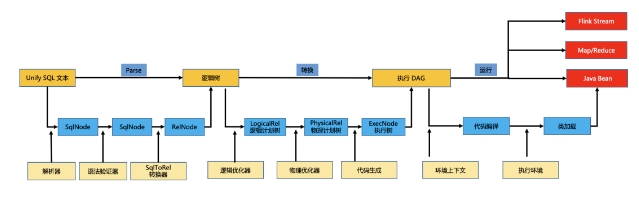
PS:如果你們看過Flink源碼,對上面流程會非常眼熟,是的,Unify SQL Engine不是從頭設計的,是基于Flink 1.12源碼魔改的,其中Parse和下面要說的Codegen技術都是直接參考了Flink設計,當然說是魔改的,就是還有大量代碼需要基于上面做二次開發,比如從執行DAG到各個環境真正可執行的MR/Bean/Stream。
? Codegen技術
在SQL解析后,經過邏輯優化器和物理優化器,產生的PhyscialRel物理計劃樹,包含大量的復雜數據邏輯處理,比如SQL常見的CASE WHEN語句,常見的做法是給所有符號運算定義個父類(比如ExecNode),實際運行時,委派給真實的子類運行,這涉及到大量虛擬函數表的搜尋,最終這種分支指令一定程度阻止指令的管道化和并行執行,導致這種搜尋成本比函數本身執行成本還高。
Codegen技術就是專門針對這樣的場景孕育而生,行業做的比較出色的Codegen技術,有LLVM和Janino,LLVM主要針對編譯器,而Java的代碼codegen通常使用Janino,Janino做為一種小巧快速的Java編譯器,不僅能像Javac將一組java文件編譯成Class文件,也可以將Java表達式、語句塊、類定義塊或者Java文件進行編譯,直接加載成ByteCode,并在同一個JVM里進行運行。
Unify SQL Engine也使用Janino用來做CodeGen技術,并有效地提升代碼的執行效率。關于Janino更多內容,可以參考這篇文章:Java CodeGen編譯器Janino(地址:https://zhuanlan.zhihu.com/p/407857568)。這里有采用Codegen和不采用Codegen的技術性能對比:
表達式 | 100*x+20/2 | (x+y)(xx+y)/(x-y)100/(xy) |
Node樹遍歷執行 | 10ms | 88ms |
Janino生成代碼執行 | 6ms | 9ms |
可以看出當表達式越復雜時,使用Janino的效果就會體現越明顯。
? 有狀態計算
通常計算分為無狀態計算和有狀態計算,無狀態計算一般是過濾、project映射,其每次計算依賴當前數據上下文,相互獨立的,不依賴前后數據,因此,不需要有額外的存儲保存中間計算結果或者緩存數據,但還有一類是有狀態計算,除了當前數據上下文,還需要依賴之前計算的中間態數據,典型的比如:
- sum求和:需要有存儲保存當前求和的結果,當有新的數據過來,結合當前中間結果基礎上累加
- 去重:去掉之前重復出現的數據,需要保存之前已經處理過哪些數據,然后有新的數據需要計算,要和保存的數據比較是否重復
- 排序:需要有存儲保存之前排好的數據,當有新的數據過來,會變更之前的排序結果,并diff后,將重新排序后有變動的數據重新發到下游

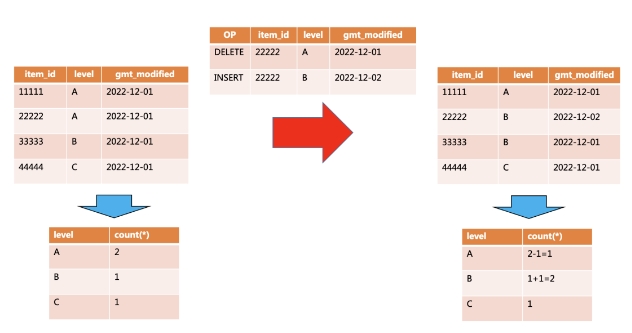
可見,當需要進行有狀態計算,需要有后背存儲來承載中間狀態結果,Unify SQL Engine是支持3種后背存儲:內存、Redis和Hbase:
- 內存State是只保存到內存,一旦重新啟動,就丟失歷史數據,內存State通常用在單機有狀態計算,并且容忍數據丟失。一般用在ODPS的MR程序里,因為一次MR調用狀態計算,只需要當前執行上下文的累計結果,不需要放在全局緩存,不同批次之間的累計是通過MR API之間傳輸,內存State完全夠用。
- Redis:對于需要跨多機狀態計算,就會用到Redis作為后背存儲,Unify SQL Engine在Java環境里默認是使用這個作為后背存儲。Redis后備存儲一般用在Java計算環境,數據會流經過不同生產機器,計算的中間結果需要全局可見。
- Hbase:如果狀態數據超過100G,可以選擇Hbase做為后背存儲,性能雖然比不上Redis,但狀態可以保存很長時間,對于長周期的狀態計算非常有用。
? JOIN語義
Flink是可以支持雙流Join,但是Flink的雙流Join的語義完全照搬了SQL的JOIN語義,就是一邊的數據會和另一邊的所有數據JOIN,這個對于離線分析沒有任何問題,但是對于實時計算是會存在重復計算,在有些場景還有損業務邏輯,比如:當訂單流去雙流JOIN優惠表的時候,就會出現這個問題,優惠表的數據是會不停變化的,但是我們希望以快照數據做為JOIN的依據,而不是把優惠變更的數據都復現一遍,Unify SQL Engine是做到后者語義的,也就是SNAPSHOT JOIN,也是業務場景常見的語義:

一些想法
? 統一調度
Unify SQL Engine現在已經可以做到將SQL翻譯成不同執行環境可運行的任務,通過Unify SQL統一表達了不同環境的邏輯計算,但是離最終我們期望的還很遠,其中一點就是要做到統一調度和分配,現在不同環境的協調是需要開發者自己去分配和調度,比如哪些計算需要下發到ODPS MR計算,哪些是在Java環境運行,未來我們希望這些分配也是可以做到統一調度和運行,包括全量和增量計算的自動協同,離線和在線數據協同等
? 資源成本
通過Unify SQL Engine,開發者可以自己選擇底層的計算引擎,對于數據量較大但對時效要求不高的場景,可以選擇在ODPS計算,對于時效有要求同時數據規模可接受內,可以選擇在Flink調度,對于計算邏輯復雜,需要大量依賴HSF接口,可以選擇在Java環境啟動,選擇自己最容易接受的資源和成本,承接其計算語義。
同時,也是希望通過Unify SQL Engine最大化的利用計算資源,比如Java應用,很多情況下是空閑狀態的,CPU利用率是比較低下的,比如一些流計算可以下發到這些空閑的應用,并占用非常小的CPU(比如5%以內),整體的資源利用率就提升了,還比如,Flink計算資源是比較難申請,那么可以選擇在Java環境里計算(Java相比Flink環境缺乏一些特性,比如Exactly once語義)等等。
團隊介紹
我們是大淘寶技術營銷工具團隊,承擔天貓各種大促活動,開發面向消費者端/商家端營銷產品,負責雙11核心玩法、價格管控、權益發放的核心業務團隊。這里覆蓋全域營銷產品,擁有億級用戶規模、千萬商家規模,這里充滿技術挑戰,有復雜的業務場景、T級大規模的數據處理,千萬級的QPS、秒級億數據實時處理等。



















