作者丨Senthil Nayagan
譯者 | 仇凱
審校丨Noe
如果不理解背后的設計理念和工作原理,那么就會對Rust的所有權和借用特性產生困惑。這種困惑尤其出現在將以前學習的編程風格應用于新范式時,我們稱之為范式轉移。所有權是一個新穎的想法,初次接觸時非常難以理解。但是,隨著使用經驗的逐漸積累,開發人員會越來越深刻的體會到其設計理念的精妙。在進一步學習Rust的所有權和借用特性之前。首先,需要了解下“內存安全”和“內存泄漏”的原理以及編程語言處理這兩種問題的方式。
內存安全
內存安全是指軟件程序的一種狀態,在這種狀態下內存指針或引用始終指向有效內存。因為內存存在損壞的可能性,因此如果無法做到內存安全,那么就幾乎無法保證程序的運行效果。簡而言之,如果程序無法做到真正的內存安全,那么就無法保證其功能可以正常實現和執行。在運行內存不安全的程序時,攻擊方可以利用漏洞在他人設備上竊取機密信息或任意執行惡意代碼。下面我們將使用偽代碼來解釋有效內存。
// pseudocode #1 - shows valid reference
{ // scope starts here
int x = 5
int y = &x
} // scope ends here
在上面的偽代碼中,我們創建了一個值為10的變量x。我們使用&作為運算符或關鍵字來創建引用。因此,語法&x允許我們創建對變量x的值的引用。簡單地說,我們創建了一個值為5的變量x和一個引用x的變量
y。
由于變量x和y在同一個代碼塊或作用域中,因此變量y對x的值的引用是有效引用。因此,變量y的值是5。
下面的偽代碼示例中,正如我們所見,x的作用域僅限于創建它的代碼塊。當我們嘗試在其作用域之外訪問x時,就會遇到懸空引用問題。懸空引用……?它到底是什么?
// pseudocode #2 - shows invalid reference aka dangling reference
{ // scope starts here
int x = 5
} // scope ends here
int y = &x // can't access x from here; creates dangling reference
懸空引用
懸空引用的意思是指向已分配或已釋放內存位置的指針。如果一個程序(也稱為進程)引用了已釋放或已清除數據的內存,就可能會崩潰或產生無法預知的結果。話雖如此,內存不安全也是一些編程語言的特性,程序員使用這些特性處理無效數據。因此,內存不安全引入了很多問題,這些問題可能會導致以下安全漏洞:
- 越界讀取
- 越界寫入
- UAF漏洞(Use-After-Free)
內存不安全導致的漏洞是許多高風險安全威脅的根源。更棘手的是,發現并處理此類漏洞對于開發人員來說是非常困難的。
內存泄漏
我們需要了解內存泄漏的原理及其引發的嚴重后果。內存泄漏是非正常的內存使用形式,在這種情況下,會導致開發人員無法釋放已分配的堆內存塊,即使該內存塊已不再需要存放數據。這與內存安全的概念是相反的。稍后我們將詳細探討不同的內存類型,但現在,我們只需要知道棧會存儲在編譯時就長度固定的變量,而在運行時會改變長度的變量則必須存放在堆上。與堆內存分配相比,棧內存分配被認為是更安全的,因為內存會在與程序無關或不再需要時被自動釋放,釋放過程可以由程序員控制,也可以由運行時系統自動判斷。
但是,當程序員在堆上占用內存并且未能將其釋放,且沒有垃圾回收器(例如C或C++)的情況下,就會發生內存泄漏。此外,如果我們丟失了一塊內存的所有引用且沒有釋放該內存,也會發生內存泄漏。我們的程序將繼續擁有該內存,卻無法再次使用它。
輕微的內存泄漏并不是問題,但是如果一個程序占用了大量的內存卻從不釋放,那么程序的內存占用將持續上升,最終導致拒絕服務。
當程序退出時,操作系統會立即接管并釋放其占用的所有內存。因此,只有當程序運行時內存泄露問題才會存在。一旦程序終止,內存泄露問題就會消失。讓我們回顧一下內存泄漏的主要影響。
內存泄漏能夠通過減少可用內存(堆內存)的數量來降低計算機的性能。它最終會導致系統整體或部分的工作異常或造成嚴重的性能損耗。崩潰通常與內存泄漏有關。不同編程語言應對內存泄漏的方法是不同的。內存泄漏可能會從一個微小的幾乎“不明顯的問題”開始,但這些問題會迅速擴散并對操作系統造成難以承受的影響。我們應該盡最大努力密切關注內存泄露問題,盡可能避免并修正相關錯誤,而非任其發展。
內存不安全和內存泄漏
內存泄漏和內存不安全是預防和補救方面最受關注的兩類問題。而且兩者相對獨立,并不會因為其中一種問題被修復而使另一種問題被自動修復。

圖1:內存不安全與內存泄漏
內存的類型及其工作原理
在我們繼續學習之前,我們需要了解不同類型的內存在代碼中是如何被使用的。如下所示,這些內存的結構是不同的。
- 寄存器
- 靜態內存
- 棧內存
- 堆內存
寄存器和靜態內存類型不在本文的討論范圍。
1.棧內存及其工作原理
棧按照接收順序存儲數據,并以相反的順序將其刪除。棧中的元素是按照后進先出 (LIFO) 的順序進行訪問的。將數據添加到棧中稱為“pushing”,將數據從棧中移除稱為“popping”。
所有存儲在棧上的數據都必須是已知且長度固定的。在編譯時長度未知或長度會發生變化數據必須存儲在堆上。
作為開發人員,我們不必為棧內存的分配和釋放操心;棧內存的分配和釋放是由編譯器“自動完成”。這意味著當棧上的數據與程序無關(即超出范圍)時,它會被自動刪除而無需人工的干預。
這種內存分配方式也被稱為臨時內存分配,因為當函數執行結束時,屬于該函數的所有數據都會“自動”從棧中被清除。Rust中的所有原始類型都存在棧中。數字、字符、切片、布爾值、固定大小的數組、包含原始元素的元組和函數指針等類型都可以存放在棧上。
2.堆內存及其工作原理
與棧不同,當我們將數據存放到堆上時,需要請求一定的內存空間。內存分配器在堆中定位一個足夠大的未占用空間,并將其標記為正在使用,同時返回該位置地址的引用。這就是內存分配。
在堆上存放數據比在棧上存放數據要慢,因為棧永遠不需要內存分配器尋找空位置來放置新數據。此外,由于我們必須通過指針來獲取堆上的數據,所以堆的數據訪問速度要比棧慢。棧內存是在編譯時就被分配和釋放的,與之不同的是,堆內存是在程序指令執行期間被分配和釋放的。在某些編程語言中,使用關鍵字new來分配堆內存。關鍵字new(又名運算符)表示在堆上請求分配內存。如果堆上有充足的可用內存,則運算符new會將內存初始化并返回分配內存的唯一地址。值得一提的是,堆內存是由程序員或運行時系統“顯式”釋放的。
編程語言如何實現內存安全?
談到內存管理,尤其是堆內存,我們希望編程語言具有以下特征:
- 不需要內存時就盡快釋放,且不增加資源消耗。
- 對已釋放數據的引用(也就是懸空引用)進行自動維護。否則,極易發生程序崩潰和安全問題。
編程語言通過以下方式確保內存安全:
- 顯式內存釋放(例如C和C++)
- 自動或隱式內存釋放(例如Java、Python和C#)
- 基于區域的內存管理
- 線性或特殊類型系統
基于區域的內存管理和線性系統都不在本文的討論范圍。
1.手動或顯式內存釋放
在使用顯式內存管理時,程序員必須“手動”釋放或擦除已分配的內存。運算符“釋放”(例如,C中的delete)存在于需要顯式內存釋放的語言中。
在C和C++等系統語言中,垃圾回收的成本很高,因此顯式內存分配一定會長久存在的。將釋放內存的職責留給程序員,能夠讓程序員在變量的生命周期內擁有其完整的控制權。然而,如果釋放運算符使用不當,軟件在執行過程中就極易出現故障。事實上,這種手動分配和釋放內存的過程很容易出錯。常見的編碼錯誤包括:
- 懸空引用
- 內存泄漏
盡管如此,我們更傾向于手動內存管理而非依賴垃圾回收機制,因為這賦予我們更多的控制權并能夠有更出色的性能表現。請注意,任何系統編程語言的設計目標都是擁有更好的魯棒性。換句話說,編程語言的設計者在性能和便利性之間選擇了性能。
確保不使用任何指向已釋放內存的指針,是開發人員的責任。
不久之前,有一些方法已經被驗證可以避免這些錯誤,但這一切最終都歸結為嚴格遵循代碼規范,這需要嚴格使用正確的內存管理方法。
關鍵要點是:
- 嚴格的內存管理。
- 懸空引用和內存泄漏的安全性比較低。
- 較長的開發周期。
2.自動或隱式內存釋放
自動內存管理已成為包括Java在內的現代編程語言的基本特征。
在內存自動釋放的場景中,垃圾回收器就是自動化的內存管理器。垃圾回收器會周期性的遍歷堆內存并回收未使用的內存塊。它代替我們管理內存的分配和釋放。因此,我們不必編寫代碼來執行內存管理任務。這很好,因為垃圾回收器將我們從繁瑣的內存管理職責中解放出來。同時也大大減少了開發時間。
但是,垃圾回收機制并非完美無缺的,它同樣有許多的缺點。在垃圾回收期間,程序需要暫停其他任務,并消耗時間搜索需要清理和回收的內存。
此外,自動內存管理機制對內存有更高優先級的需求。垃圾回收器為我們執行內存釋放的操作,而這些操作會消耗內存和CPU時鐘周期。因此,自動內存管理會降低應用程序的性能,尤其是在資源有限的大型應用程序中。
關鍵要點是:
- 自動內存管理。
- 解決懸空引用或內存泄露問題,并高效提升內存安全性。
- 更簡潔的代碼。
- 更快的開發周期。
- 輕量化的內存管理。
- 由于它消耗內存和CPU時鐘周期,因此延遲較高。
Rust中的內存安全
一些語言提供垃圾回收機制,它在程序運行時尋找不再使用的內存;而其他語言則要求程序員顯式分配和釋放內存。這兩種模型各有優劣。垃圾回收機制雖然已經廣泛應用,但也有一些缺點;它是以犧牲資源和性能為代價,來提升開發人員的工作效率。
話雖如此,一邊是提供高效的內存管理機制,而另一邊通過消除懸空引用和內存泄漏提供更好的安全性。Rust將這兩種優點集于一身。

圖2:Rust有優秀的內存管理機制,并提供很好的安全性
Rust采用了與上述兩種方案不同的方法,即基于規則組的所有權模型,編譯器驗證這些規則組來確保內存安全。只有在完全滿足這些規則的情況下,程序才會被編譯成功。事實上,所有權用編譯時的內存安全檢查替代運行時的垃圾回收機制。

顯式內存管理、隱式內存管理和Rust的所有權模型由于所有權是一個新的概念,因此,即使是與我一樣的程序員,學習和適應它也需要一定時間。
所有權
至此,我們對數據在內存中的存儲方式有了基本的了解。現在我們來認真研究下Rust中的所有權模型。Rust最大的特點就是所有權模型,它在編譯時就保障了內存的安全性。
首先,讓我們從字面意義來理解“所有權”。所有權是合法“擁有”和“控制”“某物”的一種狀態。話雖如此,我們必須明確誰是所有者以及所有者能夠擁有和控制什么。在Rust中,每個值都有對應的變量,變量就是值的所有者。簡而言之,變量就是所有者,變量的值就是所有者能夠擁有和控制的東西。

圖3:變量綁定展示所有者及其值/資源
在所有權模型中,一旦變量超出作用域,內存就會被自動釋放。當值超出作用域或結束其生命周期時,其析構函數就會被調用。析構函數(尤其是自動析構函數)是一個函數,它通過從程序中刪除值的引用痕跡來釋放內存。
1.借用檢查器
Rust通過借用檢查器(一種靜態分析器)實現所有權。借用檢查器是Rust編譯器中的一個組件,它跟蹤整個程序中數據的使用位置,并且根據所有權規則,它能夠識別需要執行釋放的數據的位置。此外,借用檢查器可以確保在運行時,已釋放的內存永遠不會被訪問。它甚至消除了因為數據出現同時突變(或修改)而引起的競爭問題。
2.所有權規則
如前所述,所有權模型建立在一組所有權規則之上,這些規則相對簡單。Rust編譯器
(rustc) 強制執行以下規則:
- 在Rust中,每個值都有對應的變量,變量就是值的所有者。
- 同時只能存在一個所有者。
- 當所有者超出作用域時,該值將被刪除。
編譯時檢查的所有權規則會對以下內存錯誤進行保護:
- 懸空引用:這是一個指向已經不再包含數據的內存地址的指針;此指針指向空數據或隨機數據。
- UAF漏洞:當內存被釋放后,仍試圖訪問該內存,就可能會導致程序崩潰。這個內存位置經常被黑客用來執行惡意代碼。
- 雙重釋放:當已分配的內存被釋放后,再次執行釋放操作。這會導致程序崩潰,進而暴露敏感信息。這種情況同樣允許黑客執行惡意代碼。
- 分段錯誤:程序嘗試訪問被禁止訪問的內存區域時,就會出現分段錯誤。
- 緩沖區溢出:數據量超過內存緩沖區的存儲容量時,就會出現緩沖區溢出,這通常會導致程序崩潰。
在深入了解所有權規則之前,我們需要先了解copy、move和clone之間的區別。
3.copy
長度固定的數據類型(尤其是原始類型)可以存儲在棧中,并在其作用范圍結束時清除數據釋放內存。如果其他代碼在其作用范圍內需要相同數據的時候,還可以從棧中便捷的將該數據復制為一個新的獨立變量。因為棧內存的復制非常高效便捷,因此具有固定長度的原始類型被稱為擁有復制語義特性。它高效的創建了一個完美的復制品。
值得注意的是,具有固定長度的原始類型實現了通過復制特征來進行復制。
let x = "hello";
let y = x;
println!("{}", x) // hello
println!("{}", y) // hello
在Rust中,有兩種字符串:String(堆分配的,可增長的)和&str(固定大小,不能改變)。
因為x存儲在棧中,所以復制它的值來為y生成一個副本非常容易。這種用法并不適用于存儲在堆上的數據。下面是棧的示意圖:

圖4:x和y都有自己的數據
復制數據會增加程序運行時間和內存消耗。因此,大塊數據不適合使用復制。
4.move
在Rust術語中,“move”意味著將轉移內存的所有權。想象一下堆上存儲的數據類型有多復雜。
let s1 = String::from("hello");
let s2 = s1;我們可以假設第二行(即
let s2 = s1;)將復制s1中的值并綁定到s2。然而所見并非所得。
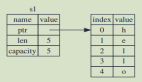
下面我們將研究下String究竟在后臺執行了什么樣的操作。String由存儲在棧中的三部分組成。實際的內容(在本例中是hello)存儲在堆上。
- 指針-指向保存字符串內容的內存。
- 長度-字符串當前使用的內存大小(以字節為單位)。
- 容量-字符串從分配器獲得的內存總量(以字節為單位)。
換句話說,元數據存儲在棧上,而實際數據則存儲在堆上。

圖5:棧存儲元數據,堆存儲實際內容
當我們將s1分配給s2時,會復制字符串的元數據,這意味著我們會復制棧上的指針、長度和容量。不會復制堆上指針所指向的數據。內存中的數據如下所示:

圖6:變量s2獲取s1的指針、長度和容量的副本
值得注意的是,下圖表示的是Rust復制了堆數據后內存的狀態,真實情況并不是這樣的。如果Rust執行此操作,當堆數據很大時,則s2 = s1操作在運行時性能表現會非常差。

圖7:如果Rust復制堆數據,s2 = s1操作的結果就是數據復制。但是,Rust默認不執行數據復制
請注意,當復雜類型不在作用域內時,Rust將調用drop函數對堆內存執行顯式釋放。但是,圖6中的兩個數據指針指向同一個位置,Rust并不會這樣做。我們將很快進入技術實現細節。
如前所述,當我們將s1分配給s2時,變量s2會復制s1的元數據(指針、長度和容量)。但是,將s1分配給s2之后,s1會發生什么呢?Rust認為此時s1是無效的。是的,你沒看錯。
讓我們重新思考下let s2 = s1的賦值操作。假設Rust在此操作之后仍然認為s1是有效的,那么會發生什么。當s2和s1超出范圍時,它們都會嘗試釋放相同的內存。這是個糟糕的情況。這被稱為雙重釋放錯誤,它屬于內存安全錯誤的一種情況。雙重釋放內存可能會導致內存損壞,進而帶來安全風險。
為了確保內存安全,Rust在let s2 = s1操作執行之后會認為s1無效。因此,當s1不在作用域內時,Rust不需要執行內存釋放。假如創建s2后仍然嘗試使用s1會發生什么,下面我們做個試驗。
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Won't compile. 我們得到一個錯誤。我們會得到一個類似下面的錯誤,因為Rust不允許使用無效的引用:
$ cargo run
Compiling playground v0.0.1 (/playground)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:6:28
|
3 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
4 | let s2 = s1;
| -- value moved here
5 |
6 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
左右滑動查看完整代碼
由于Rust在let s2 = s1操作執行之后將s1的內存所有權轉移給了s2,因此它認為s1是無效的。這是s1失效后的內存表示:

圖8:s1無效后的內存表示
當只有s2保持有效時,就會在其超出范圍時執行內存釋放操作。因此,Rust消除了雙重釋放錯誤出現的可能性。這是非常優秀的解決方案!
5.clone
如果我們需要深度復制字符串的堆數據,而不僅僅是棧數據,可以使用一種叫做clone的方法。以下是克隆方法的使用示例:
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);clone方法確實將堆數據復制到s2中了。操作非常完美,下圖是示例:

圖9:clone方法確實將堆數據復制給s2
然而clone方法有一個嚴重的后果;它只復制數據,卻不會同步兩者之間的任何更改。通常情況下,進行clone應當審慎評估其效果和影響。
至此,我們詳細了解了copy、move和clone的技術原理。下面我們將詳細地了解所有權規則。
6.所有權規則1
每個值都有對應的變量,變量就是值的所有者。這意味著值都歸變量所有。在下面的示例中,變量s擁有指向字符串的指針,而在第二行中,變量x擁有值1。
let s = String::from("Rule 1");
let n = 1;7.所有權規則2
在給定時間,一個值只有一個所有者。一個人可以擁有許多寵物,但在所有權模型中,任何時候一個值都只有一個所有者:-)
原始類型是在編譯時就已知其固定長度的數據類型,下面是原始類型的使用示例。
let x = 10;
let y = x;
let z = x;
我們將10分配給變量x;換句話說,變量x擁有10。然后我們將x分配給y,同時將其分配給z。我們知道同一時間只能存在一個所有者,但沒有引發任何錯誤。所以在此示例中,每次當我們將x分配給一個新變量時,編譯器都會對其進行復制。
棧幀如下:x = 10,y = 10 和 z = 10。然而,真實情況似乎與我們的設想(x = 10、y = x 和 z = x)不一樣。我們知道,x是10的唯一所有者,y和z都不能擁有這個值。

圖10:編譯器將x復制到y和z
就像前文所述,由于復制棧內存高效便捷,因此具有固定長度的原始類型被稱為擁有復制語義特性,而復雜類型就只是移動所有權。因此,在這種情況下,編譯器執行了復制操作。
這種情況下,變量綁定的行為與其他的編程語言類似。為了闡釋所有權規則,我們需要復雜的數據類型。
我們通過觀察數據在堆上的存儲方式,來學習Rust如何判斷需要清理哪些數據;字符串類型是就是一個很好的例子。我們將聚焦于字符串類型所有權相關的行為;這些原則也適用于其他復雜的數據類型。
眾所周知,存儲在堆上的復雜數據類型,其內容在編譯時是不可預知的。我們來觀察這個示例:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Won't compile. 我們得到一個錯誤。儲字符串類型的場景下,其存儲在堆上的數據長度可能會發生變化。這就表示:
- 程序在運行的時候就必須從內存分配器請求內存(我們稱之為第一部分)。
- 當不再需要該字符串后,需要將此內存釋放回內存分配器(我們稱之為第二部分)。
開發人員需要重點關注第一部分:當我們從String::開始執行調用時,它會向內存分配器請求內存。這部分的技術實現在編程語言中很常見。
但是,第二部分是不一樣的。在擁有垃圾回收機制的編程語言中,垃圾回收器會跟蹤并清理不再使用的內存,開發人員并不需要在此方面投入精力。在沒有垃圾回收機制的語言中,識別不再需要的內存并顯式釋放內存就是開發人員的職責。確保正確釋放內存是一項很有挑戰性的編程任務:
- 如果我們忘記釋放內存,就會造成內存空間浪費。
- 如果我們過早的釋放內存,那么就會產生一個無效變量。
- 如果我們重復釋放內存,程序就會出現BUG。
Rust以一種新穎的方式處理內存釋放,有效減輕了開發人員的工作壓力:當變量超出其作用域時,內存就會被自動釋放。
讓我們回到正題。在Rust中,對于復雜類型,諸如為變量賦值、參數傳遞或函數返回值這類的操作是不會執行copy操作,而是會執行move操作。簡而言之,對于復雜類型來說,通過轉移其所有權來完成上述任務。
當復雜類型超出其作用域時,Rust將調用drop函數顯式地執行內存釋放。
8.所有權規則3
當所有者超出作用域時,該值將被刪除。再次考慮之前的示例:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Won't compile. The value of s1 has already been dropped.在將s1分配給s2之后(在let s2 = s1賦值語句中),s1的值就被釋放了。因此,賦值語句執行后,s1就失效了。s1被釋放后的內存狀態:

圖11:s1被釋放后的內存狀態
9.所有權如何變動
在Rust程序中,有三種方式可以在變量之間轉移所有權:
(1)將一個變量的值分配給另一個變量(前文已經討論過)。
(2)將值傳遞給函數。
(3)從函數返回值。
將值傳遞給函數
將值傳遞給函數與為變量賦值有相似的語義。就像賦值一樣,將變量傳遞給函數會導致變量被移動或復制。下面的例子向我們展示了復制和移動:
fn main() {
let s = String::from("hello"); // s comes into scope
move_ownership(s); // s's value moves into the function...
// so it's no longer valid from this
// point forward
let x = 5; // x comes into scope
makes_copy(x); // x would move into the function
// It follows copy semantics since it's
// primitive, so we use x afterward
} // Here, x goes out of scope, then s. But because s's value was moved, nothing
// special happens.
fn move_ownership(some_string: String) { // some_string comes into scope
println!("{}", some_string);
} // Here, some_string goes out of scope and `drop` is called.
// The occupied memory is freed.
fn makes_copy(some_integer: i32) { // some_integer comes into scope
println!("{}", some_integer);
} // Here, some_integer goes out of scope. Nothing special happens.如果我們在調用move_ownership之后嘗試使用s,Rust會拋出編譯錯誤。
從函數返回值
從函數返回值同樣可以轉移所有權。下面是一個包含返回值的函數示例,其注釋與上一個示例中的注釋相同。
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return
// value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into
// takes_and_gives_back, which also
// moves its return value into s3
} // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing
// happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string comes into scope
some_string // some_string is returned and
// moves out to the calling
// function
}
// This function takes a String and returns it
fn takes_and_gives_back(a_string: String) -> String { // a_string comes into
// scope
a_string // a_string is returned and moves out to the calling function
}變量的所有權改變始終遵循相同的模式:當值被分配給另一個變量時,就會觸發move操作。除非數據的所有權被轉移至另一個變量,否則當包含堆上數據的變量超出作用域時,該值將被清除。
希望這能讓大家對所有權模型及其對Rust處理數據的方式(例如賦值引用和參數傳遞)有一個基本的了解。
等等。還有一件事…
沒有什么是完美無缺的,Rust所有權模型同樣有其局限性。當我們開始使用Rust后,很快就會發現一些使用不順手的地方。我們已經觀察到,獲取所有權然后函數傳遞所有權就有一些不順手。
令人討厭的是,假設我們想再次使用數據,那么傳遞給函數的所有內容都必須執行返回操作,即使其他函數已經返回了部分相關數據。如果我們需要一個函數只使用數據但是不獲取數據所有權,又該如何操作呢?
參考以下示例。下面的代碼示例將報錯,因為一旦所有權轉移到print_vector函數,變量v就不能再被最初擁有它的main函數(在 println 中!)使用。
fn main() {
let v = vec![10,20,30];
print_vector(v);
println!("{}", v[0]); // this line gives us an error
}
fn print_vector(x: Vec<i32>) {
println!("Inside print_vector function {:?}",x);
}跟蹤所有權看似很容易,但是當我們面對復雜的大型程序時,它就會變得非常復雜。所以我們需要一種在不轉移“所有權”的情況下傳遞數據的方法,這就是“借用”概念發揮作用的地方。
借用
借用,從字面意義上來說,就是收到一個物品并承諾會歸還。在Rust的上下文中,借用是一種在不獲取所有權的情況下訪問數據的方式,因為它必須在恰當的時機返還給所有者。
當我們借用一個數據時,我們用運算符&引用它的內存地址。&被稱為引用。引用本身并沒有什么特別之處——它只是對內存地址的指向。對于熟悉C語言指針的人來說,引用是指向內存的指針,其中包含屬于另一個變量的數據。值得注意的是,Rust中的引用不能為空。實際上,引用就是一個指針;它是最基本的指針類型。大多數編程語言中只有一種指針類型,但Rust有多種指針類型。指針及其類型是另外一個話題,以后有機會將會單獨討論。
簡而言之,Rust將對某個數據的引用稱為借用,該數據最終必須返回給所有者。示例如下:
let x = 5;
let y = &x;
println!("Value y={}", y);
println!("Address of y={:p}", y);
println!("Deref of y={}", *y);
上述代碼生成以下輸出:
Value y=5
Address of y=0x7fff6c0f131c
Deref of y=5
示例中,變量y借用了變量x擁有的數據,而x仍然擁有該數據的所有權。我們稱之為y對x的引用。當y超出范圍時,借用關系結束,由于y沒有該數據的所有權,因此該數據不會被銷毀。要借用數據,請使用運算符&進行引用。{:p}代表輸出以十六進制表示的內存位置。
在上面的代碼示例中,“*”(即星號)是對引用變量進行操作的解引用運算符。這個解引用運算符允許我們獲取指針指向的內存地址中的數據。
下面是函數通過借用,在不獲取所有權的情況下使用數據的示例:
fn main() {
let v = vec![10,20,30];
print_vector(&v);
println!("{}", v[0]); // can access v here as references can't move the value
}
fn print_vector(x: &Vec<i32>) {
println!("Inside print_vector function {:?}", x);
}我們將引用 (&v)(又名pass-by-reference)而非所有權(即pass-by-value)傳遞給print_vector函數。因此在main函數中調用print_vector函數后,我們就可以訪問v了。
1.通過解引用運算符跟蹤指針的指向數據
如前所述,引用是指針的一種類型,可以將指針視為指向存儲在其他位置的數據的箭頭。下面是一個示例:
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
在上面的代碼中,我們創建了一個對i32類型數據的引用,然后使用解引用運算符跟蹤被引用的數據。變量x存儲一個i32類型的值5。我們將y設置為對x的引用。
下面是棧內存的狀態:

棧內存狀態
我們可以斷言x等于5。然而,假如我們需要對y中的數據進行斷言,就必須使用*y來跟蹤它所引用的數據(因此在這里解引用)。一旦我們解開了y的引用,就可以訪問y指向的整型數據,然后將其與5進行比較。
如果我們嘗試寫assert_eq!(5, y);就會得到以下編譯錯誤提示:
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:11:5
|
11 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`左右滑動查看完整代碼由于它們是不同的數據類型,因此無法對數字和數字的引用進行比較。所以,我們必須通過解引用運算符來跟蹤其指向的真實數據。
2.默認情況下,引用是不可變的
默認情況下,引用和變量一樣是不可變的——可以通過mut使其可變,但前提是它的所有者也是可變的:
let mut x = 5;
let y = &mut x;
不可變引用也被稱為共享引用,而可變引用也被稱為獨占引用。
我們觀察下面的案例。我們賦予對引用的只讀權限,因為我們使用的是運算符&而非&mut。即使源變量n是可變的,ref_to_n和another_ref_to_n也不是可變的,因為它們只是n借用,并沒有n的所有權。
let mut n = 10;
let ref_to_n = &n;
let another_ref_to_n = &n;
借用檢查器將拋出以下錯誤:
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:4:9
|
3 | let x = 5;
| - help: consider changing this to be mutable: `mut x`
4 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
3.借用規則
有人可能會有疑問,為什么有些情況下開發人員更傾向于使用move而非借用。如果這是關鍵點,那么為什么Rust還會有move語義,以及為什么不將默認機制設置為借用?根本原因是在Rust中借用的使用是受到限制的。只有在特定情況下才允許借用。
借用有自己的一套規則,借用檢查器在編譯期間會嚴格執行這些規則。制定這些規則是為了防止數據競爭。規則如下:
(1)借用者的作用域不能超過所有者的作用域。
(2)不可變引用的數量不受限制,但可變引用只能存在一個。
(3)所有者可以擁有可變引用或不可變引用,但不能同時擁有兩者。
(4)所有引用必須有效(不能為空)。
4.引用的作用域不能超過所有者的作用域
引用的作用域必須包含在所有者的作用域內。否則,可能會引用一個已釋放的數據,從而導致UAF錯誤。
let x;
{
let y = 0;
x = &y;
}
println!("{}", x);
上面的示例程序嘗試在所有者y超出作用域后取消x對y的引用。Rust阻止了這種UAF錯誤。
5.可以有很多不可變引用,但只允許有一個可變引用
特定數據可以擁有數量不受限制的不可變引用(又名共享引用),但只允許有一個可變引用(又名獨占引用)。這條規則的存在是為了消除數據競爭。當兩個引用同時指向一個內存位置,至少有一個在執行寫操作,且它們的動作沒有進行同步時,這就被稱為數據競爭。
我們可以有數量不受限制的不可變引用,因為它們不會更改數據。另一方面,借用機制限制我們同一時刻只能擁有一個可變引用(&mut),目的是降低在編譯時出現數據競爭的可能性。
我們看看如下示例:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
}上面的代碼嘗試為s創建兩個可變引用(r1 和 r2),這最終會執行失敗:
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:6:14
|
5 | let r1 = &mut s;
| ------ first mutable borrow occurs here
6 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
7 |
8 | println!("{}, {}", r1, r2);
| -- first borrow later used here
總結
希望本文能夠澄清所有權和借用的概念。我還簡單介紹了借用檢查器,它是實現所有權和借用的基礎。正如我在開頭提到的,所有權是一個很有創意的想法,即使對于經驗豐富的開發人員來說,初次接觸也會很難理解其設計理念和使用方法,但是隨著使用經驗的增加,它就會成為開發人員得心應手的工具。這只是Rust如何增強內存安全的簡要說明。我試圖使這篇文章盡可能的易于理解,同時提供足夠的信息來掌握這些概念。有關Rust所有權特性的更多詳細信息,請查看他們的在線文檔。
當開發項目對性能要求高時,Rust是一個不錯的選擇,它解決了困擾其他語言的很多痛點,并以陡峭的學習曲線向前邁出了重要的一步。Rust連續第六年成為Stack Overflow最受歡迎的語言,這意味著很多人將會有機會使用它并愛上了它。Rust社區正在持續發展壯大。隨著我們走向未來,Rust似乎正走在無限光明的道路上。祝大家學習愉快!
原文鏈接:
https://hackernoon.com/rusts-ownership-and-borrowing-enforce-memory-safety
譯者介紹
仇凱,51CTO社區編輯,目前就職于北京宅急送快運股份有限公司,職位為信息安全工程師。主要負責公司信息安全規劃和建設(等保,ISO27001),日常主要工作內容為安全方案制定和落地、內部安全審計和風險評估以及管理。