你必須要掌握的大數據計算技術,都在這了

01離線批處理
這里所說的批處理指的是大數據離線分布式批處理技術,專用于應對那些一次計算需要輸入大量歷史數據,并且對實時性要求不高的場景。目前常用的開源批處理組件有MapReduce和Spark,兩者都是基于MapReduce計算模型的。
1.MapReduce計算模型?
MapReduce是Google提出的分布式計算模型,分為Map階段和Reduce階段。在具體開發中,開發者僅實現map()和reduce()兩個函數即可實現并行計算。Map階段負責數據切片,進行并行處理,Reduce階段負責對Map階段的計算結果進行匯總。
這里舉一個通俗的例子幫助你理解。假如現在有3個人想打一種不需要3~6的撲克牌游戲,需要從一副撲克牌中去掉這些牌,過程描述如下:
第一步,將這一副牌隨機分成3份,分給3個人,然后每個人一張張查看手中的牌,遇到3~6的牌就挑出去;
第二步,等所有人都完成上面的步驟后,再將每個人手上剩余的牌收集起來。
在這個過程中,第一步操作屬于Map階段,相當于對每張牌做一次判斷(映射、函數運算),是否保留;第二步屬于Reduce階段,將結果匯總。
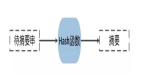
MapReduce數據流圖如圖1所示。

▲圖1 MapReduce數據流圖
MapReduce處理的數據格式為鍵-值格式,一個MapReduce作業就是將輸入數據按規則分割為一系列固定大小的分片,然后在每一個分片上執行Map任務,Map任務相互獨立,并行執行,且會在數據所在節點就近執行;當所有的Map任務執行完成后,通過緩存機制將分散在多個節點的鍵值相同的數據記錄拉取到同一節點,完成之后的Reduce任務,最后將結果輸出到指定文件系統,比如HDFS、HBase。基于以上解釋和描述,可以看出MapReduce不適合實現需要迭代的計算,如路徑搜索。
2.Spark
Spark是基于內存計算的大數據并行計算框架,最初由美國加州大學伯克利分校的AMP實驗室于2009年開發,于2010年開源,是目前最主流的批處理框架,替代了MapReduce。
整個Spark項目由四部分組成,包括SparkSQL、Spark Streaming、MLlib、Graphx,如圖2所示。其中SparkSQL用于OLAP分析,Streaming用于流式計算的(微批形式),MLlib是Spark的機器學習庫,Graphx是圖形計算算法庫。Spark可在Hadoop YARN、Mesos、Kubernetes上運行,可以訪問HDFS、Alluxio、Cassandra、HBase等數據源。

▲圖2 Spark組件
Spark使用先進的DAG(Directed Acyclic Graph,有向無環圖)執行引擎,支持中間結果僅存儲在內存中,大大減少了IO開銷,帶來了更高的運算效率,并且利用多線程來執行具體的任務,執行速度比MapReduce快一個量級。
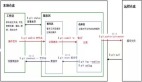
在Spark中,Spark應用程序(Application)在集群上作為獨立的進程集運行,由主程序(稱為Driver)的SparkContext中的對象協調,一個Application由一個任務控制節點(Driver)和若干個作業(Job)構成。Driver是Spark應用程序main函數運行的地方,負責初始化Spark的上下文環境、劃分RDD,并生成DAG,控制著應用程序的整個生命周期。Job執行MapReduce運算,一個Job由多個階段(Stage)構成,一個階段包括多個任務(Task),Task是最小的工作單元。在集群環境中,Driver運行在集群的提交機上,Task運行在集群的Worker Node上的Executor中。Executor是運行在Spark集群的Worker Node上的一個進程,負責運行Task,Executor既提供計算環境也提供數據存儲能力。在執行過程中,Application是相互隔離的,不會共享數據。Spark集群架構示意圖如圖3所示。

▲圖3 Spark集群架構?
具體來說,當在集群上執行一個應用時,SparkContext可以連接到集群資源管理器(如YARN),獲取集群的Worker Node的Executor,然后將應用程序代碼上傳到Executor中,再將Task發送給Executor運行。
Spark的核心數據結構是RDD(Resilient Distributed Dataset,彈性分布式數據集),只支持讀操作,如需修改,只能通過創建新的RDD實現。
02實時流處理
當前實時處理數據的需求越來越多,例如實時統計分析、實時推薦、在線業務反欺詐等。相比批處理模式,流處理不是對整個數據集進行處理,而是實時對每條數據執行相應操作。流處理系統的主要指標有以下幾個方面:時延、吞吐量、容錯、傳輸保障(如支持恰好一次)、易擴展性、功能函數豐富性、狀態管理(例如窗口數據)等。
目前市面上有很多成熟的開源流處理平臺,典型的如Storm、Flink、Spark Streaming。三者的簡單對比如下:Storm與Flink都是原生的流處理模型,Spark Streaming是基于Spark實現的微批操作;Spark Streaming的時延相對前兩者高;Flink與Streaming的吞吐量高,支持的查詢功能與計算函數也比Storm多。總體來說,Flink是這三者中綜合性能與功能更好的流平臺,當前的社區發展也更火熱。
1.Flink簡介
Flink最初由德國一所大學開發,后進入Apache孵化器,現在已成為最流行的流式數據處理框架。Flink提供準確的大規模流處理,支持高可用,能夠7×24小時全天候運行,支持exactly-once語義、支持機器學習,具有高吞吐量和低延遲的優點,可每秒處理數百萬個事件,毫秒級延遲,支持具有不同的表現力和靈活性的分層API,支持批流
一體。
2.Flink的架構
Flink是一個分布式系統,可以作為獨立群集運行,也可以運行在所有常見的集群資源管理器上,例如Hadoop YARN、Apache Mesos和Kubernetes。
Flink采用主從架構,Flink集群的運行程序由兩種類型的進程組成:JobManager和一個或多個TaskManager。TaskManager連接到JobManager,通知自己可用,并被安排工作。兩者的功能如下所示:
- JobManager負責協調Flink應用程序的分布式執行,完成任務計劃、檢查點協調、故障恢復協調等工作。高可用性設置需要用到多個JobManager,其中一個作為領導者(leader),其他備用。
- TaskManager,也稱為Worker,負責執行數據處理流(dataflow)的任務,并緩沖和交換數據流。TaskManager中資源調度的最小單位是任務槽(slot),TaskManager中slot的數量代表并發處理任務的數量。
Flink架構示意圖如圖4所示。

▲圖4 Flink架構
客戶端(Client)不是Flink運行程序的一部分,它在給JobManager發送作業后,就可以斷開連接或保持連接狀態以接收進度報告。
3.Flink對數據的處理方式
流處理是對沒有邊界數據流的處理。執行時,應用程序映射到由流和轉換運算符組成的流式數據處理流。這些數據流形成有向圖,以一個或多個源(source)開始,以一個或多個輸出(sink)結束。程序中的轉換與運算符之間通常是一對一的關系,但有時一個轉換可以包含多個運算符。Flink流式處理步驟示例如圖5所示。

▲圖5 Flink流式處理步驟示例
4.Flink的接口抽象
Flink為開發流、批處理的應用提供了四層抽象,實踐中大多數應用程序是基于核心API的DataStream/DataSet API進行編程的,四層抽象從低到高的示意圖如圖6所示。

▲圖6 Flink接口抽象層次
- Low-level:提供底層的基礎構建函數,用戶可以注冊事件時間和處理時間回調,從而允許程序實現復雜的計算。
- Core API:DataStream API(有界/無界流)和DataSet API(有界數據集)。基于這些API,用戶可以實現transformation、join、aggregation、windows、state等形式的數據處理。
- Table API:基于表(table)的聲明性領域特定語言(DSL)。Table API遵循(擴展的)關系模型,表具有附加的表結構(schema),并且該API提供類似關系模型的操作,例如select、join、group-by、aggregate等。Table API的表達性不如Core API,但優點是使用起來更為簡潔,編碼更少。Flink支持在表和DataStream/DataSet之間進行無縫轉換,因此可以將Table API與DataStream/DataSet API混合使用。
- SQL:此層是最高層的抽象,在語義和表達方式上均類似于Table API,但是將程序表示為SQL查詢表達式。