MPP與Hadoop,兩種主流大數(shù)據(jù)系統(tǒng)架構有啥區(qū)別?
同樣都可以處理大規(guī)模數(shù)據(jù)的MPP數(shù)據(jù)庫架構與Hadoop體系架構屬于不同的技術體系,二者沒有直接的相關性,卻常常被放在一起進行比較。特別是在企業(yè)數(shù)據(jù)倉庫建設中,MPP架構與Hadoop架構代表兩類典型的技術路線選型,事實上,在2015年左右甚至有人認為基于Hadoop體系的數(shù)倉將徹底取代基于MPP數(shù)據(jù)庫的數(shù)倉。

1. 設計思路對比
兩類系統(tǒng)運行的硬件架構是相同的,都是普通服務器組成的集群,但從資源管理角度來說,它們并行化軟件實現(xiàn)的設計思路卻是相反的。
MPP架構相當于對單機的各類資源進行垂直綜合管理,再將多個單機系統(tǒng)橫向連接進行集成,可以說是先垂直后水平。
Hadoop架構相當于將所有機器的存儲資源與計算資源抽象出來,分開管理,再進行組件級的垂直集成,可以說是先水平后垂直。
MPP與Hadoop架構對比如圖1所示。
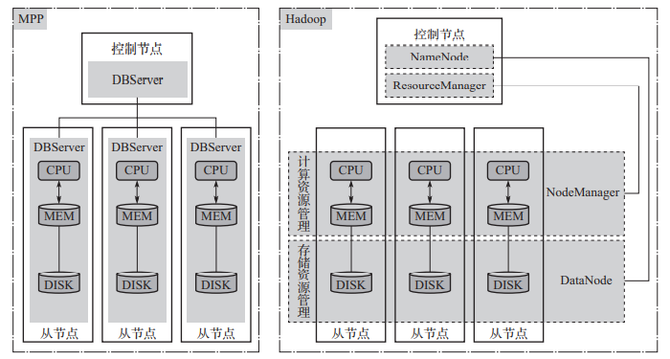
▲圖1 MPP與Hadoop架構對比
具體分析如下:
MPP架構是將許多單機數(shù)據(jù)庫通過網(wǎng)絡連接起來,相當于將一個個垂直系統(tǒng)橫向連接,形成一個統(tǒng)一對外服務的分布式數(shù)據(jù)庫系統(tǒng),每個節(jié)點由一個單機數(shù)據(jù)庫系統(tǒng)獨立管理和操作該節(jié)點所在物理機上的所有資源(CPU、內(nèi)存、磁盤、網(wǎng)絡),節(jié)點內(nèi)系統(tǒng)的各組件間的相互調(diào)用不需要通過控制節(jié)點,即對控制節(jié)點來說,每個節(jié)點的內(nèi)部運行過程相對透明。
Hadoop架構是將不同的資源管理與功能進行分層抽象設計,每層形成一類組件,實現(xiàn)一定程度的解耦,包括存儲資源管理、計算資源管理、通用并行計算框架、各類分析功能等,在每層內(nèi)進行跨節(jié)點的資源統(tǒng)一管理或功能并行執(zhí)行,層與層之間通過接口調(diào)用,相互透明,節(jié)點內(nèi)不同層的組件間的相互調(diào)用需要由控制節(jié)點掌握或通過控制節(jié)點協(xié)調(diào),即控制節(jié)點了解每個節(jié)點內(nèi)不同層組件間的互動過程。
2. 優(yōu)缺點對比
MPP架構的優(yōu)缺點總結(jié)如下:
- 支持標準SQL,每個節(jié)點都有豐富的事務處理和管理功能;
- 資源管理精細;
- 更適合預知數(shù)據(jù)結(jié)構模型的中等規(guī)模的固定模式數(shù)據(jù)管理;
- 集群規(guī)模調(diào)整要求較多,增減節(jié)點時通常需要停機,且有的系統(tǒng)只能增加不能減少;
- 延遲小,相對吞吐量一般,單節(jié)點緩慢會拖累整體性能;
表記錄進行水平分割存儲,方法通常包括一致性哈希(Consistent Hashing)、循環(huán)寫入(Round Robin),但容易產(chǎn)生數(shù)據(jù)熱點。
Hadoop架構的優(yōu)缺點總結(jié)如下:
- 每個節(jié)點功能簡單,不具備豐富的數(shù)據(jù)管理功能,不支持事務;
- 數(shù)據(jù)更新采用追加方式實現(xiàn),同等數(shù)據(jù)量處理需要的資源更多;
- 可以不用預先了解數(shù)據(jù)的格式與內(nèi)容;
- 擴展性好,支持集群規(guī)模更大,能動態(tài)擴容,支持擴充僅用于計算的節(jié)點;
- 延遲高、吞吐量大、容錯性(Failover)好。
總體來說,Hadoop架構在數(shù)據(jù)量較低的情況下,運行速度遠不及MPP架構,但數(shù)據(jù)量一旦超過某個量級,Hadoop架構在吞吐量方面將非常有優(yōu)勢。有些大數(shù)據(jù)數(shù)據(jù)倉庫產(chǎn)品也采用混合架構,以融合兩者的優(yōu)點,例如Impala、Presto等都是基于HDFS的MPP分析引擎,僅利用HDFS實現(xiàn)分區(qū)容錯性,放棄MapReduce計算模型,在面向OLAP場景時可實現(xiàn)更好的性能,降低延遲。