淺談大數據的數據災備建設
?一、引言
大數據時代,數據呈爆炸趨勢增長,很多企業都從大數據中獲得了利益,推動各自的業務上升了一個臺階。通過大數據技術的完善尤其是大數據和云容器技術相結合,各個企業已經把自己的重要業務遷移到了大數據平臺。與此同時企業對數據可靠性和業務連續性保證的訴求也與日俱增,大數據災備刻不容緩。
信息系統的災備,會按照業務恢復的要求,設置為三級:數據級、應用級和業務級。因業務級,除了需要IT系統的災備建設,還需要其他非IT資源的配合,所以不在本文討論范圍內。
二、基礎概念
在討論信息系統災備之前,需要明確兩個概念:RTO和RPO
RTO:(RecoveryTime Object)是指災難發生后,從IT系統宕機導致業務停頓之刻開始,到IT系統恢復至可以支持各部門運作,業務恢復運營之時,此兩點之間的時間段稱為RTO。
RPO:(RecoveryPoint Objective,復原點目標)是指數據中心能容忍的最大數據丟失量,是指當業務恢復后,恢復得來的數據和災難發生前數據的差異,也就是能夠容忍的數據丟失量。
三、大數據的數據級災備
大數據底層數據存儲使用HDFS實現。對HDFS的備份,其目的在于當集群A上的數據出現問題,可以使用集群B上的數據進行恢復。
HDFS在兩個集群間使用distcp命令實現數據復制。因distcp命令最終產生的是MR任務,所以可以實現數據的并發拷貝。HDFS中的數據的存放,是以目錄的方式進行存放。使用distcp時,需要指定源端集群的目錄和目標端集群目錄。
- hadoop distcp
- hdfs://cluster1/user/app1
- hdfs://cluster2/user
如果有多個目標集群,可以在目錄中指定更多的目標集群。在使用distcp命令,也可以增加一些參數,比如使用overwrite覆蓋已有的備份,或者使用update參數備份修改過的文件。
使用distcp的好處在于備份過程簡單。并且可以根據自身的需要,對整體集群或對指定的目標進行備份。由于distcp能夠靈活使用,所以非常方便配合各種業務操作。當每日完成數據加工操作后,可以在批量作業中調用disctcp將重要數據備份到異地機房進行保存。
使用此種方法,需要建立目標集群,同時對網絡帶寬有一定需求,所以此種災備系統的成本較高。如果需要降低成本同時對備份和恢復的效率要求不高,也可以將HDFS中的數據導出為文本,使用磁帶庫的方式進行備份。
大數據平臺中不僅需要對HDFS的數據進行備份,HBase數據庫的災備也尤為重要。HBase在大數據體系中,不僅承載OLAP的業務,同時也具備OLTP業務承載能力。
在OLTP業務場景下,通常對RTO要求較高。可以考慮使用HBase數據庫提供的Replication(復制)技術。HBase當前有3種Replication方式:
- 異步Replication
- 串行Replication
- 同步Replication
使用哪一種復制方式,需要根據對RTO和RPO的要求進行確定。不同種類的復制方式,對于前端業務在數據庫中的操作效率,會有不同的感受。
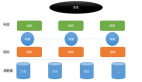
HBase數據庫的備份原理,是對HLog進行讀取并發給Slave端中進行應用,從而實現數據同步。每個Master節點中的RegionServer都有HLog,開啟HBase的復制方式,在RegionServer上會開啟一個單獨的線程讀取HLog,同時發送給Slave端。并通過Zookeeper記錄已經發送的HLog的偏移量。在3種復制方式中,異步的復制方式對源端的HBase影響最小。

圖1.HBase Replication原理
HBase的Replication是一種較為高級的災備方法。除了使用Replication也可以使用CopyTable、Export/Impor方式進行HBase數據庫的數據災備。
CopyTable是一種邏輯的數據備份技術,其原理是對表的scan操作,對RegionServer會產生較大的壓力,對于OLTP的業務會有寫入操作的影響。但由于CopyTable的原理是使用HBase的API對表進行scan操作,從而可以讓用戶自定義對表中數據抽取,同時目標表的位置可以是本集群或遠端集群。
- hbase.org.apache.hadoophbase.mapreduce.CopyTable
- --peer.adr=BkCluster:2181:/hbase
- --new.name=BkTable AppTable如果需要備份到本地集群,去掉peer.adr參數。
HBase的邏輯備份,還可以使用export/import方式。export\import方式不同于CopyTable方法的是,將備份的數據以sequence的格式,將數據保存到HDFS中。此方法相比于CopyTable在備份和恢復效率方面有所下降,但備份的數據可以離線進行長期保留。
- 數據導出方法
- hbase.org.apache.hadoop.hbase.coprocessor.Export<tablename><outputdir>
- 數據導入方法hbase.org.apache..hadoop.hbase.comprocessor.Import<tablename><inputdir>
CopyTable和export/import兩種方法,都可以靈活的生成備份數據,配合數據加工操作,完成重要數據進行備份。但需要考慮在備份過程中對HBase的性能影響。
四、大數據的應用級災備
應用級災備,主要對業務等級較高,對RTO和RPO要求較高的業務系統而設計的。在大數據領域內,完成應用級災備,主要的實現方法是數據的雙加載方式。所謂的雙加載方式,是前端應用對部署在不同地點的集群,同時加載數據。所有集群都寫入成功后,返回數據寫入成功的標志。G行目前采用的是,應用級災備和數據級災備的混合模式。聯機業務采用應用級災備,聯機業務數據使用異步批量提交的方法,將數據提交給主數據集群。主機群通過定時批量的方法,將數據分別同步給兩個數據查詢集群,前端連接其中一個集群對外提供查詢服務,并在一個查詢集群出現問題時,通過應用程序的手動切換完成數據源的隔離,實現數據讀操作的切換。此種方式,將讀和寫的操作進行了分離,在寫入操作出現問題時,讀操作任然可用。批量作業業務,采用數據級容災,對重要數據進行數據克隆或導出進行保存。
應用級災備是一個系統工程,基礎數據層形成了多點保護,相關的應用系統和存儲系統也會改造為多活架構。G行考慮到今后基于大數據平臺的聯機業務的發展,將平臺進行了縱向切分,對聯機業務單獨建立集群,分離出OLTP業務,并形成同城兩中心的多活架構。

圖2.OLTP集群災備
五、后續與展望
各行各業基于大數據技術在快速發展自己的業務,將隨著業務的變化對大數據的災備會提出更多的要求。G行也在根據自己的業務,完善大數據系統的災備建設,尤其是基于大數據的實時業務的災備建設。我們會將最新的大數據災備建設方法,寫在此公眾號上。請關注我們的更新。