呂豪:京東搜索EE場景排序鏈路升級實踐
在JD搜索體系中,EE模塊被定義的核心定位是:在給定流量和時間的約束下,探索出更多高效率的商品。EE的優化目標即為,以保障搜索效率為前提,提升廣義中長尾商品的探索成功率,提升搜索結果的流動性、豐富性。
全文將圍繞以下幾點展開:
- EE場景迭代閉環
- 模型Debias迭代
- 在線AB指標
- 離線評估體系
- 總結
01 EE場景迭代閉環
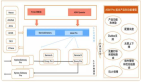
由于EE場景的特殊性,其從核心定位 → 在線指標 → 離線評估體系 → 模型迭代的優化鏈路中的每一步,都需結合EE特點進行針對性升級。

以下分別從模型迭代、在線實驗指標、離線評估體系介紹相應模塊的優化。
02 模型Debias迭代
1. 問題背景
EE的核心定位在于探索更多更高效的潛力中長尾商品,其首要回答的問題便是,在目前搜索體系中,哪些因素阻礙中長尾商品獲得更公平合理的展現機會?系統性的各類bias。
①Position-bias(展示位置偏置)?
當前打分模型基于每天dump的搜索日志進行訓練更新。由于搜索結果的position-bias(位置偏置)效應,user的行為動作不僅與商品本身質量有關,而且受position(展示位置)較大影響。position-bias(位置偏置)效應對頭部商品的增益,加劇了平臺生態的馬太效應。使用position-bias的日志數據進行訓練,而未對position(展示位置)做去偏,不利于中長尾商品的正確效率預估,不利于平臺流動性、豐富性和長期價值。
②Polularity-bias(流行度偏置)?
存在與user偏好匹配程度相當的多個商品時,由于商品間的歷史累計銷量、累計評論等流行度特征的差異,造成傾向于給用戶呈現熱門流行商品,已流行商品則更流行。而匹配程度相似的中長尾商品,則難有機會被展現,中長尾更中長尾。
③Exposure-bias(曝光偏置)?
一次搜索請求下,只有有限的商品列表展現給user,絕大多商品無法展示;搜索系統一天內,整體被展現的商品集也只占全部商品集的小部分。由此帶來兩方面問題:一方面是模型泛化問題,訓練在已展現商品的日志上進行,serving需在所有商品上做推斷,如何平衡訓練、推斷樣本分布差異化的矛盾,尤其是頭、尾部商品的巨大差距。另一方面是商品label問題,商品未累積獲得用戶正反饋,是因為與用戶不匹配,還是未有展現機會?
針對以上bias問題,EE排序模型從位置偏置建模、反事實推理學習方面進行升級,嘗試緩解position-bias和polularity-bias,取得一定收益。而Exposure-bias由于隨機dump樣本的label問題,還需要做更多探索。
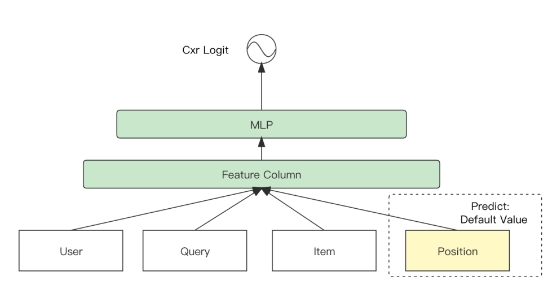
目前EE排序模型整體結構圖:
 ?
?
- 針對位置偏置,設計position-bias net于訓練時建模位置作用、預測時mask,進行展示位置去偏。
- 針對流行度偏置,構建 U-I net/ item_net/ user_net 分別建模用戶-商品內容匹配度、流行度因子、用戶心智偏好因子的影響,依據因果效應消除偏置因子作用,還原用戶對商品本身內容的偏好度。
2. 位置去偏迭代?
(1)Position-bias 位置偏置建模

EE模型升級至訓練、預測兩階段的position-debias方案,通過pos-bias tower建模position-bias影響,并在高語義層級與輸出均值融合,擬合訓練label,而后在預測階段摘除,以期去除pos-bias影響。
①Pos的建模方式?
- pos as feat?
訓練階段,pos作為模型特征使用,與其他u/q/i側特征聯合,共同輸入模型網絡,計算相應logits并梯度回傳。預測推理階段,所有樣本強制采用同一個pos值,近乎理解為:同一個user/query下, 所有商品在同樣的展示位置上,進行預測分數比較。

其潛在風險如下:?
強制pos數值如何選擇。展示位置一般可限制在 [0-30/60] 內,然而不同強制位置的設定,會帶來排序結果的變化,如何在 [0-60] 間選擇合理的強制位置,以及不同時間和分布下,強制位置的選擇是否要重新進行。
pos特征的重要性。將pos特征由網絡底層輸入,其重要性可能難以在最后的logits中得以充分體現,其物理意義(位置因素影響用戶商品交互行為的作用大小)不易直觀理解。
- multi-pos predict?
設計最后一層為多位置通道輸出的網絡,預測商品在各枚舉位置上的logits輸出。訓練階段計算商品在所有位置上的輸出結果,只激活真實的pos通道計算logit和loss,其他位置通道進行mask。推斷時,貪心地從第一個位置開始,無放回地選擇當前位置上的最優商品,直至最后一個位置。

此方案適配用于排序位置較為固定的場景,如重排N選N,在搜索EE現有架構下并不適配,一方面是SVGP結構對多通道結果輸出并不友好;另一方面,EE現有插入范圍較大[1-60]、比較插入機制也需做非常復雜化的適配改造,方案過重。
- pos as tower
升級現有DNN + 稀疏變分高斯(svgp) 采樣打分模型,采用基于position-bias net(位置偏置)的模型方案,方案具體為訓練、預測兩階段的位置去偏。
訓練階段通過引入展示位置表征作為位置偏好網絡,與基于user/query/item的主網絡共同輸入,預估商品在當前位置(位置偏好網絡)及自身質量(主網絡)下的打分。
預測階段通過摘除位置偏好網絡,預測商品僅基于自身質量的采樣打分,去除展示位置影響。通過此方案可以緩解訓練數據的position-bias(位置偏執),降低頭部商品由于展示位置的打分增益,同時減少中長尾商品由于靠后位置的打分折損,優化搜索結果豐富性和平臺生態。
(2)個性化位置偏置建模?
用戶對商品的偏好是個性化的,不同用戶對商品的偏好不同。用戶對位置的偏好也是差異化的,不同用戶對位置的敏感度存在差異。?
上文的bias-net建模方式,假定所有用戶對同一位置偏好相同,忽略了用戶間的位置偏好差異。典型例子如下,偏逛用戶在系統中對position相對不敏感,position的排名前后對用戶的行為決策影響相對更小,而對偏快速夠買用戶則影響截然相反。
個性化位置偏置建模。升級現有bias-net結構,引入用戶個性化特征,包括靜態profile和動態行為序列。通過個性化bias-net計算不同用戶對不同position的位置偏好,更準確地還原用戶對商品內容的真實偏好。
現有EE模型結構為DNN+SVGP+TS,DNN對用戶和商品進行個性化表征,SVGP通過訓練樣本的反饋label以及樣本間表征距離,推導計算待預測樣本的效率打分和不確定性,結合TS算法采樣出商品的最終探索得分。
如何結合SVGP和Pos-bias Net,在不確定性打分模型中進行位置去偏?
①Pos Tower 與 svgp的結合方式?
- SVGP簡介
 ?
?
GP(Gaussian process,高斯過程)是用于在樣本間存在相關關系的情況下,通過觀測值對未知樣本label 進行修正預測的算法。簡言之,距離觀測點越近的未知樣本,其均值被修正越多、更接近觀測值,方差也越收斂,反之亦然。SVGP(Sparse Variational Gaussian Process, 基于稀疏變分的高斯過程),針對大樣本量下協方差矩陣和求逆難以計算的問題,設計一定數量的可學習的引導點,對所有訓練樣本進行歸納,未知樣本通過與引導點的協方差來計算均值和方差。
- 表征層融合(Representation Fusion)?
Pos-tower與Main-tower融合方式有兩種,表征層融合和logit層融合。在SVGP計算前進行融合,即表征層向量進行融合,可以采用 concat/sum/avg 等各種方式。其難點在于,向量間的相加、平均操作,無法直觀理解其物理意義和作用,向量疊加是否導致logit正向增大,向量帶來多大的logit提升,這些位置偏置作用難以解析。
另外從模型結構來看,svgp依賴樣本內容間相似度計算均值和方差,而position-bias的影響應該獨立于樣本內容的計算。
- logit層融合(Logit Fusion)
在svgp之后的logit層融合,可采用 logits 相乘相加方式,其直接從模型結構上詮釋了這樣的公式 Label = f(content) + f(position) / Label = f(content) * f(position) ,其中 f(position)的絕對值大小,直觀地表示 position 帶來的增益大小。
②位置偏置建模線上效果
保持大盤效率持平的情況下,EE核心指標提升明顯,探索成功率指標(探索更高效商品)顯著提升,探索流動性指標(探索更多商品)全面提高。
3. 流行度去偏
流行度去偏的常見思路簡介如下:
①IPS?
對每個商品預估 propensity score,然后采用逆向 propensity score 權重的方式,消除傾向分的影響,預估商品真實的內容匹配度得分。
挑戰點:?
- 如何準確獲得 propensity score,這是對后續糾偏的前提挑戰。
- 整體為兩段式訓練,鏈路上有一定復雜度。
②流行度降權
在實際搜推數據中,在user側、item側分別依據其流行程度,設計對應降權權重,緩解整體被熱門用戶、商品所主導的趨勢,增強所關注樣本的影響力。
面臨難點:?
- 合理的設計權重方案。
- 如何挖掘hard example。
③基于因果關系的反事實推理?
如何緩解流行度偏置問題?在訓練鏈路中,增強改善中長尾商品的學習是一類重要方法;對用戶交互行為進行解構,拆分出商品流行度等因子的作用,是另一個視角的解決思路。?
(1)因果圖、因果關系簡介

因果圖是有向無環圖,其中節點表示隨機變量、有向邊表示節點之間的因果作用方向。如上圖對于節點Y變量,有兩條路徑的因果作用,分別是 I → Y 、I → K → Y。
- I → Y 表示從 I 節點開始的自然直接因果效應 (NDE),作用路徑上沒有中間節點。
- I → K → Y 表示從 I 節點開始的間接因果效應(TIE),K是路徑上的中間節點。
- 直接因果效應和間接因果效應之和,即為Y變量的總因果效應(TE)。
總因果效應計算,可以由自變量的單位擾動帶來的因變量變化進行計算,自然因果和間接因果效應計算亦然:

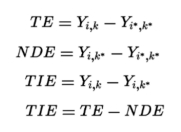
以上公式可得,求出TE和NDE時,可推導計算中間接因果效應 TIE。
(2)搜索中的因果效應?
在電商搜索場景下,用戶對商品的交互行為,可表示為 U-I 間各種因子的綜合作用。常見思路為考慮 U-I 間內容匹配程度作為待預測因子,學習此因子在交互行為中的作用,在未來樣本上進行預測排序。
從電商搜索的現實情況出發,對交互行為進一步拆分,影響用戶商品交互行為的因子大體包含如下三方面:
- (U-I) → Y, U-I 內容匹配度因子,用戶與item本身內容的匹配程度、喜好程度對交互行為的影響,越喜歡則越點擊購買,
- I → Y, Item流行度特征,內容偏好匹配程度相當的幾個商品時,由于歷史累計銷量等流行度特征,熱門商品展現更多、被交互概率更高。
- U → Y, 用戶天然心智,user對流行商品的偏好程度不同,有些用戶更傾向于熱門商品,部分用戶則并不敏感。

以上因子的拆解,包括了U/I 內容匹配度的間接因子的效應,也包括了 U、I 的直接效應影響。因此在EE模型中設計如下網絡,分別建模各個因子的作用:

具體分別設計 UI-Match-Net, User-Net, Item-Net 分別預測對應三種因子的作用,其中總效應,U/I 效應分別表示為:

在訓練中Loss的設計如下,分別表示:

- U-I 與 label 的loss,優化主模型的準確性
- U、I 側直接因子的loss,通過這種方式分別預測兩種直接因子對交互結果的影響
- alpha/beta 為訓練時超參
預測階段緩解流行度偏置,主要在于去除流行度因素、用戶心智因果(偏置因子)的影響,具體通過總因果效應減去自然直接效應(偏置因子效應),盡量準確還原 U-I 內容匹配程度的影響。
TIE = TE - NDE:
 ?
?
反事實推理后的因果圖狀態如下,將U/I 的直接效應消除,保留U-I 內容匹配度的效應:

(3)反事實推理建模線上效果?
保持大盤效率持平的情況下,EE核心指標提升明顯,探索成功率指標(探索更高效商品)和探索流動性指標(探索更多商品)均顯著提升。
03 在線AB指標
探索成功率指標,用于在小流量AB期間指導EE效果分析,其設計思路從EE核心價值出發,推導出長期價值相關聯的AB期間核心指標。
具體而言,即論證探索成功率指標 → EE核心價值。
滿足探索成功率的商品,跟蹤其一定時間后在搜索中的承接狀態,是否被大盤較好承接。判斷商品在搜索中的承接狀態,主要為三要素:流量、點擊、訂單。
通過對商品概況和承接定義、商品承接統計、分層承接分析等方面進行分析,迭代出搜索EE在AB實驗期間所關注的EE核心指標集——探索成功率。
04 離線評估體系
EE線上指標主要關注:
- 大盤效率,UCVR和UV價值。
- 探索成功率,其余輔助觀測指標包括流動性指標、豐富性指標。
在線的探索成功率和輔助指標,現階段難以與模型離線指標(AUC等)關聯,無法在離線評測EE模型的探索能力,限制EE模型迭代速度,極大增加迭代時間成本。
針對EE場景特異性的指標,設計了離線指標評測集合,分別從效率、中長尾探索強度、不確定預估等方面,綜合評測EE模型,加速迭代。
05 總結
搜索EE是提升搜索場景流動性、多樣性的關鍵模塊,其面臨的問題和以效率排序為主模塊的問題有很大差異,對EE同學提出了不一樣的挑戰。
針對EE場景的特點,排序模型從Debias(打分公平性)入手,拆解存在于各種排序場景的bias問題,對位置偏置和流行度偏置問題升級較通用化的解決方案,取得了EE核心指標的顯著提升。同時對于迭代鏈路中的在線AB指標、離線評估體系,也進行了論證和迭代,完成對整個EE排序閉環鏈路的升級。限于篇幅,AB指標和離線評估體系在本文不做全面展開,感興趣的同學歡迎隨時交流,共同探討。
EE場景面臨的挑戰很多,后續計劃從如下方面繼續深入探索:?
- 引入更豐富的用戶探索信號的表達,增加explore-net和監督loss,提升EE模型對探索偏好的學習。
- 思考EE的長期價值,如何在模型結構、Loss設計上結合長期價值。
- 優化EE探索機制和EE候選集,提升EE全鏈路探索能力。
今天的分享就到這里,謝謝大家。