注意:雪花算法并不是ID的唯一選擇!
在《悟空傳》篇外篇里,有一個憂傷的故事。
秋天,樹上掉下兩片葉子,你要和它們說再見。但你如何知道這片葉子,不是另外一片葉子?是通過它的形狀,還是通過它的重量?
當我們在分布式環境中存儲一些數據的時候,不得不面對的一個選擇,就是ID生成器。
使用一個唯一的字符串,來標識一條完整的記錄。
這時候,不能使用md5或者sha1來對整個記錄做摘要,因為我們后續還要改動這個記錄。也不能使用單機的計數器,因為計數器容易重啟清零,也會存在多臺機器上的數值重復,這違背了無狀態服務的建設目標。
無奈的選擇UUID
雖然UUID在大多數語言中都有相關的類庫,但除非破不得以,我們一般不會使用它。UUID雖然不會重復,但它非常的長,長的讓人望而生畏。
XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
標準的UUID有5個部分組成:8-4-4-4-12,一共32個十六進制字符。因此,一共是128位。

當把UUID作為數據庫的索引時,會因為它沒有順序性造成索引的隨機分布和;因為數據量巨大造成查詢性能降低。
同時,UUID也是不可讀的。如果你把它打印在紙質的訂單上,并不是一個好的主意。
UUID同時還有信息安全的隱患,它的數據計算里有MAC地址的參與,比較知名的是,曾被用于尋找梅麗莎病毒的制作者位置。
改造時間戳
如果你是單機應用,那么使用時間戳沒什么問題,即使不用納秒,使用毫秒也是足夠的。但在分布式環境下面,時間戳同樣不是一個好的選擇。
即使你在機器安裝了ntpd時間同步,但由于網絡和機器的差異,計算機的時鐘總是存在差異,你的時間戳總會出現重復。為了解決這個問題,你需要增加一些其他的標識,比如機器的ID,或者更多細分的信息減少時間的碰撞。
這種自定義的ID生成器,只適合特定的業務。
做著做著你就會發現,它本質上是雪花算法的變種。
雪花算法
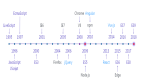
雪花算法生成的ID是long類型,默認字符串長度是19位,它分為4個部分。

- 保留位 1 位。
- 毫秒時間戳 — 41 位(比如從現在開始,支持到未來的69年),這個其實也挺尷尬的,因為70年之后就會失效。但你不會在一家公司工作70年,所以,隨它去吧。
- 配置的機器/節點/分片 ID — 10 位(總共支持 2^10 = 1024 個節點)
- 序列號 - 12 位(機器的本地計數,所以支持的并發已經很高了)
相比起UUID來,雪花算法所生成的ID是排序的,具有更好的緊湊性,是目前大多數業務優先采用的ID生成算法。
值得注意的是,雪花算法在JavaScript中有一個坑。后端在返回ID的時候,需要使用String類型代替Long類型,否則會產生預想不到的錯誤。
這是因為。在JavaScript中,存在兩種數字。Number和BigInt。最常用的,就是number。
最大的Number,叫做Number.MAX_SAFE_INTEGER,它的值為:
- 2^53-1 或者
- +/- 9,007,199,254,740,991
眾所周知,Java中的Long,是64位的。Js中的這個安全Integer,完全達不到Java中定義的長度。
這就是萬惡的IEEE_754規范,它在Long長度大于17位時會出現精度丟失的問題。
NanoID
NanoID是從JavaScript庫中演變過來的,目前在多個語言上通用。它長下面這樣。
V1StGXR8_Z5jdHi6B-myT
雖然NanoID無法替代雪花算法,但就憑這長度,替換UUID是綽綽有余的。NanoID 大小只有 108 字節,比UUID小了35%,更加緊湊。
另外,它的速度更快,它可以使用默認字母表每秒生成超過 220 萬個唯一 ID,使用自定義字母表時每秒可以生成超過 180 萬個唯一 ID,且幾乎沒有碰撞幾率。
如果你的ID對順序性沒有什么嚴格的要求,比如使用了kv等非常松散的數據庫,那么NanoID是你的不二選擇。
介紹了這么多,你會用哪種ID生成器呢?其實,一個組件如果使用的量增加到一定程度,都會出現問題,需要專門進行組件設計。
比如美團的leaf,在大型互聯網中肯定有用武之地。但對于一般互聯網,甚至是中型互聯網來說,這到底是躺椅還是炮彈,作為決策者的你不得不思量思量。
作者簡介:小姐姐味道 (xjjdog),一個不允許程序員走彎路的公眾號。聚焦基礎架構和Linux。十年架構,日百億流量,與你探討高并發世界,給你不一樣的味道。