













真的有這么絲滑:3D頭發建模新方法NeuralHDHair,浙大、ETH Zurich、CityU聯合出品
近年來,虛擬數字人行業爆火,各行各業都在推出自己的數字人形象。毫無疑問,高保真度的 3D 頭發模型可以顯著提升虛擬數字人的真實感。與人體的其他部分不同,由于交織在一起的頭發結構極其復雜,因此描述和提取頭發結構更具挑戰性,這使得僅從單一視圖重建高保真的 3D 頭發模型極其困難。一般來說,現有的方法都是通過兩個步驟來解決這個問題:首先根據從輸入圖像中提取的 2D 方向圖估計一個 3D 方向場,然后根據 3D 方向場合成頭發絲。但這種機制在實踐中仍在存在一些問題。
基于實踐中的觀察,研究者們正在尋求一個完全自動化和高效的頭發模型建模方法,可以從具備細粒度特征的單一圖像重建一個 3D 頭發模型(如圖 1),同時顯示出高度的靈活性,比如重建頭發模型只需要網絡的一個前向傳遞。

為了解決這些問題,來自浙江大學、瑞士蘇黎世聯邦理工學院和香港城市大學的研究者提出了 IRHairNet,實施一個由粗到精的策略來生成高保真度的 3D 方向場。具體來說,他們引入了一種新穎的 voxel-aligned 的隱函數(VIFu)來從粗糙模塊的 2D 方向圖中提取信息。同時,為了彌補 2D 方向圖中丟失的局部細節,研究者利用高分辨率亮度圖提取局部特征,并結合精細模塊中的全局特征進行高保真頭發造型。
為了有效地從 3D 方向場合成頭發絲模型,研究者引入了 GrowingNet,一種基于深度學習利用局部隱式網格表征的頭發生長方法。這基于一個關鍵的觀察:盡管頭發的幾何形狀和生長方向在全局范圍內有所不同,但它們在特定的局部范圍內具有相似的特征。因此,可以為每個局部 3D 方向 patch 提取一個高級的潛在代碼,然后訓練一個神經隱函數 (一個解碼器) 基于這個潛在代碼在其中生長頭發絲。在每一個生長步驟之后,以頭發絲的末端為中心的新的局部 patch 將被用于繼續生長。經過訓練后,它可適用于任意分辨率的 3D 定向場。

論文:https://arxiv.org/pdf/2205.04175.pdf
IRHairNet 和 GrowingNet 組成了 NeuralHDHair 的核心。具體來說,這項研究的主要貢獻包括:
- 介紹了一種新穎的全自動單目毛發建模框架,其性能明顯優于現有的 SOTA 方法;
- 介紹了一個從粗到細的毛發建模神經網絡(IRHairNet) ,使用一個新穎的 voxel-aligned 隱函數和一個亮度映射來豐富高質量毛發建模的局部細節;
- 提出了一種基于局部隱函數的新型頭發生長絡(GrowingNet) ,可以高效地生成任意分辨率的頭發絲模型,這種網絡比以前的方法的速度實現了一定數量級的提升。
方法
圖 2 展示了 NeuralHDHair 的 pipeline。對于人像圖像,首先計算其 2D 方向圖,并提取其亮度圖。此外,自動將它們對齊到相同的半身參考模型,以獲得半身像深度圖。然后,這三個圖隨后被反饋到 IRHairNet。
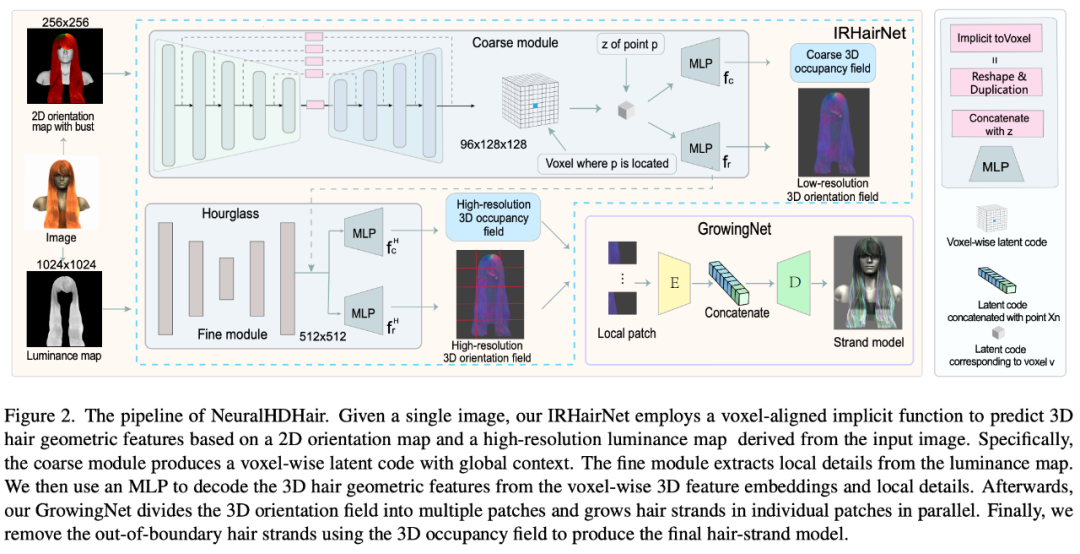
- IRHairNet 設計用于從單個圖像生成高分辨率 3D 頭發幾何特征。這個網絡的輸入包括一個 2D 定向圖、一個亮度圖和一個擬合的半身深度圖,這些都是從輸入的人像圖中得到的。輸出是一個 3D 方向字段,其中每個體素內包含一個局部生長方向,以及一個 3D 占用字段,其中每個體素表示發絲通過 (1) 或不通過(0)。
- GrowingNet 設計用于從 IRHairNet 估計的 3D 定向場和 3D 占用字段高效生成一個完整的頭發絲模型 ,其中 3D 占用字段是用來限制頭發的生長區域。
更多方法細節可參考原論文內容。
實驗
在這一部分,研究者通過消融研究評估了每個算法組件的有效性和必要性 (第 4.1 節),然后將本文方法與當前的 SOTA(第 4.2 節) 進行比較。實施細節和更多的實驗結果可以在補充材料中找到。
消融實驗

研究者從定性和定量的角度評估了 GrowingNet 的保真度和效率。首先對合成數據進行三組實驗:1)傳統的頭發生長算法,2)沒有重疊潛在 patch 方案的 GrowingNet,3)本文的完整模型。
如圖 4 和表 1 所示,與傳統的頭發生長算法相比,本文的 GrowingNet 在時間消耗上具有明顯的優勢,同時在視覺質量上保持了相同的生長性能。此外,通過比較圖 4 的第三列和第四列,可以看到,如果沒有重疊潛在 patch 方案,patch 邊界處的發絲可能是不連續的,當發絲的生長方向急劇變化時,這個問題就更加嚴重。不過值得注意的是,這種方案以略微降低精度為代價,大大提高了效率,提高效率對于其方便、高效地應用于人體數字化是有重要意義的。


與 SOTA 方法對比
為了評估 NeuralHDHair 的性能,研究者將其與一些 SOTA 方法 [6,28,30,36,40] 進行了對比。其中 Autohair 基于數據驅動的方法進行頭發合成,而 HairNet [40]忽略頭發生長過程來實現端到端的頭發建模。相比之下,[28,36]執行一個兩步策略,首先估計一個 3D 方向場,然后從中合成發絲。PIFuHD [30]是一種基于粗到細策略的單目高分辨率 3D 建模方法,可以用于 3D 頭發建模。
如圖 6 所示,HairNet 的結果看起來差強人意,但是局部的細節,甚至整體的形狀與輸入圖像中的頭發不一致。這是因為該方法用一種簡單而粗糙的方式來合成頭發,直接從單一的圖像中恢復無序的發絲。

這里還將重建結果與 Autohair[6]和 Saito[28]進行了比較。如圖 7 所示,雖然 Autohair 可以合成真實的結果,但結構上不能很好地匹配輸入圖像,因為數據庫包含的發型有限。另一方面,Saito 的結果缺乏局部細節,形狀與輸入圖像不一致。相比之下,本文方法的結果更好地保持了頭發的全局結構和局部細節,同時確保了頭發形狀的一致性。

PIFuHD [30]和 Dynamic Hair [36]則致力于估計高保真度的 3D 頭發幾何特征,以生成真實的發絲模型。圖 8 展示了兩個有代表性的比較結果。可以看出,PIFuHD 中采用的像素級隱函數無法充分描繪復雜的頭發,導致結果過于光滑,沒有局部細節,甚至沒有合理的全局結構。Dynamic Hair 可以用較少的細節產生更合理的結果,而且其結果中的頭發生長趨勢可以很好地匹配輸入圖像,但許多局部結構細節 (例如層次結構) 無法捕獲,特別是對于復雜的發型。相比之下,本文的方法可以適應不同的發型,甚至是極端復雜的結構,并充分利用全局特征和局部細節,生成高保真、高分辨率的具有更多細節的 3D 頭發模型。
?
 ?
?

























