













關(guān)于MySQL數(shù)據(jù)庫性能優(yōu)化方法,看這一篇文章就夠了

數(shù)據(jù)庫大量應(yīng)用程序開發(fā)項(xiàng)目中,大多數(shù)情況下,數(shù)據(jù)庫的操作性能成為整個應(yīng)用的性能瓶頸。數(shù)據(jù)庫的性能是程序員需要去關(guān)注的事情,當(dāng)設(shè)計數(shù)據(jù)庫表結(jié)構(gòu)以及操作數(shù)據(jù)庫(尤其是查詢數(shù)據(jù)時),都需要注意數(shù)據(jù)操作的性能。本文我們以MySQL數(shù)據(jù)庫為例進(jìn)行討論。
一、數(shù)據(jù)庫優(yōu)化目標(biāo)
1. 減少 IO 次數(shù)
IO永遠(yuǎn)是數(shù)據(jù)庫最容易瓶頸的地方,這是由數(shù)據(jù)庫的職責(zé)所決定的,大部分?jǐn)?shù)據(jù)庫操作中超過90%的時間都是 IO 操作所占用的,減少 IO 次數(shù)是 SQL 優(yōu)化中需要第一優(yōu)先考慮,當(dāng)然,也是收效最明顯的優(yōu)化手段。
2. 降低 CPU 計算
除了 IO 瓶頸之外,SQL優(yōu)化中需要考慮的就是 CPU 運(yùn)算量的優(yōu)化了。order by,group by,distinct … 都是消耗 CPU 的大戶(這些操作基本上都是 CPU 處理內(nèi)存中的數(shù)據(jù)比較運(yùn)算)。當(dāng)我們的 IO 優(yōu)化做到一定階段之后,降低 CPU計算也就成為了我們 SQL 優(yōu)化的重要目標(biāo)。
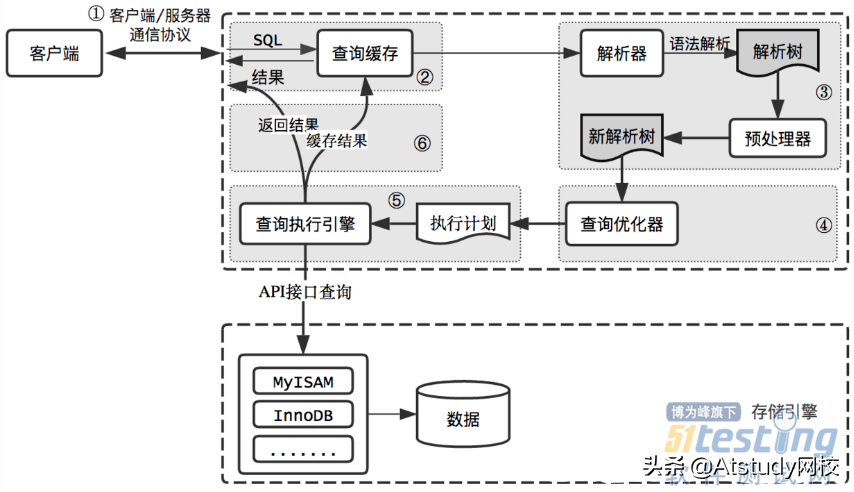
MySql查詢過程
二、數(shù)據(jù)庫優(yōu)化方法
1. SQL語句優(yōu)化
明確了優(yōu)化目標(biāo)之后,我們需要確定達(dá)到我們目標(biāo)的方法。對于SQL語句來說,達(dá)到上述2個優(yōu)化目標(biāo)的方法其實(shí)只有一個,那就是改變SQL的執(zhí)行計劃,讓他盡量“少走彎路”,盡量通過各種“捷徑”來找到我們需要的數(shù)據(jù),以達(dá)到“減少IO次數(shù)”和“降低CPU計算”的目標(biāo)。
(1) 盡量少 join。MySQL 的優(yōu)勢在于簡單,但這在某些方面其實(shí)也是其劣勢。MySQL優(yōu)化器效率高,但是由于其統(tǒng)計信息的量有限,優(yōu)化器工作過程出現(xiàn)偏差的可能性也就更多。對于復(fù)雜的多表 Join,一方面由于其優(yōu)化器受限,再者在Join這方面所下的功夫還不夠,所以性能表現(xiàn)離Oracle等關(guān)系型數(shù)據(jù)庫前輩還是有一定距離。但如果是簡單的單表查詢,這一差距就會極小甚至在有些場景下要優(yōu)于這些數(shù)據(jù)庫前輩。
(2) 盡量少排序
(3) 排序操作會消耗較多的 CPU 資源,所以減少排序可以在緩存命中率高等 IO 能力足夠的場景下會較大影響 SQL的響應(yīng)時間。
(4) 盡量避免 select *,并盡量用join代替子查詢
(5) 盡量少使用“or”關(guān)鍵字
當(dāng) where 子句中存在多個條件以“或”并存的時候,MySQL 的優(yōu)化器并沒有很好的解決其執(zhí)行計劃優(yōu)化問題,再加上 MySQL 特有的 SQL 與 Storage 分層架構(gòu)方式,造成了其性能比較低下,很多時候使用 union all 或者是union(必要的時候)的方式來代替“or”會得到更好的效果。
(6) 盡量用 union all 代替 union
union 和 union all 的差異主要是前者需要將兩個(或者多個)結(jié)果集合并后再進(jìn)行唯一性過濾操作,這就會涉及到排序,增加大量的 CPU 運(yùn)算,加大資源消耗及延遲。所以當(dāng)我們可以確認(rèn)不可能出現(xiàn)重復(fù)結(jié)果集或者不在乎重復(fù)結(jié)果集的時候,盡量使用 union all 而不是 union。
(7) 避免類型轉(zhuǎn)換
(8) 能用DISTINCT的就不用GROUP BY
(9) 盡量不要用SELECT INTO語句 ?
(10) 從全局出發(fā)優(yōu)化,而不是片面調(diào)整
SQL 優(yōu)化不能是單獨(dú)針對某一個進(jìn)行,而應(yīng)充分考慮系統(tǒng)中所有的 SQL,尤其是在通過調(diào)整索引優(yōu)化 SQL的執(zhí)行計劃的時候,千萬不能顧此失彼,因小失大。
2. 表結(jié)構(gòu)優(yōu)化
MySQL數(shù)據(jù)庫是基于行(Row)存儲的數(shù)據(jù)庫,而數(shù)據(jù)庫操作 IO 的時候是以 page(block)的方式,也就是說,如果我們每條記錄所占用的空間量減小,就會使每個page中可存放的數(shù)據(jù)行數(shù)增大,那么每次 IO 可訪問的行數(shù)也就增多了。反過來說,處理相同行數(shù)的數(shù)據(jù),需要訪問的 page 就會減少,也就是 IO 操作次數(shù)降低,直接提升性能。
(1) 數(shù)據(jù)類型選擇
原則是:數(shù)據(jù)行的長度不要超過8020字節(jié),如果超過這個長度的話在物理頁中這條數(shù)據(jù)會占用兩行從而造成存儲碎片,降低查詢效率;字段的長度在最大限度的滿足可能的需要的前提下,應(yīng)該盡可能的設(shè)得短一些,這樣可以提高查詢的效率,而且在建立索引的時候也可以減少資源的消耗。
- 數(shù)字類型:非萬不得已不要使用DOUBLE,不僅僅只是存儲長度的問題,同時還會存在精確性的問題。同樣,固定精度的小數(shù),也不建議使用DECIMAL,建議乘以固定倍數(shù)轉(zhuǎn)換成整數(shù)存儲,可以大大節(jié)省存儲空間,且不會帶來任何附加維護(hù)成本。
- 字符類型:定長字段,建議使用 CHAR 類型(char查詢快,但是耗存儲空間,可用于用戶名、密碼等長度變化不大的字段),不定長字段盡量使用VARCHAR(varchar查詢相對慢一些但是節(jié)省存儲空間,可用于評論等長度變化大的字段),且僅僅設(shè)定適當(dāng)?shù)淖畲箝L度,而不是非常隨意的給一個很大的最大長度限定,因?yàn)椴煌拈L度范圍,MySQL也會有不一樣的存儲處理。
- 時間類型:盡量使用TIMESTAMP類型,因?yàn)槠浯鎯臻g只需要DATETIME 類型的一半。對于只需要精確到某一天的數(shù)據(jù)類型,建議使用DATE類型,因?yàn)樗拇鎯臻g只需要3個字節(jié),比TIMESTAMP還少。不建議通過INT類型類存儲一個unix timestamp 的值,因?yàn)檫@太不直觀,會給維護(hù)帶來不必要的麻煩,同時還不會帶來任何好處。
- ENUM &SET:對于狀態(tài)字段,可以嘗試使用 ENUM 來存放,因?yàn)榭梢詷O大的降低存儲空間,而且即使需要增加新的類型,只要增加于末尾,修改結(jié)構(gòu)也不需要重建表數(shù)據(jù)。
(2) 字符編碼
字符集直接決定了數(shù)據(jù)在MySQL中的存儲編碼方式,由于同樣的內(nèi)容使用不同字符集表示所占用的空間大小會有較大的差異,所以通過使用合適的字符集,可以幫助我們盡可能減少數(shù)據(jù)量,進(jìn)而減少IO操作次數(shù)。
(3) 盡量使用 NOT NULL
NULL 類型比較特殊,SQL 難優(yōu)化。雖然 MySQL NULL類型和 Oracle 的NULL有差異,會進(jìn)入索引中,但如果是一個組合索引,那么這個NULL 類型的字段會極大影響整個索引的效率。雖然 NULL空間上可能確實(shí)有一定節(jié)省,倒是帶來了很多其他的優(yōu)化問題,不但沒有將IO量省下來,反而加大了SQL的IO量。所以盡量確保 DEFAULT 值不是 NULL,也是一個很好的表結(jié)構(gòu)設(shè)計優(yōu)化習(xí)慣。
3. 數(shù)據(jù)庫架構(gòu)優(yōu)化
分布式和集群化:
- 負(fù)載均衡。負(fù)載均衡集群是由一組相互獨(dú)立的計算機(jī)系統(tǒng)構(gòu)成,通過常規(guī)網(wǎng)絡(luò)或?qū)S镁W(wǎng)絡(luò)進(jìn)行連接,由路由器銜接在一起,各節(jié)點(diǎn)相互協(xié)作、共同負(fù)載、均衡壓力,對客戶端來說,整個群集可以視為一臺具有超高性能的獨(dú)立服務(wù)器。MySQL一般部署的是高可用性負(fù)載均衡集群,具備讀寫分離,一般只對讀進(jìn)行負(fù)載均衡。
- 讀寫分離。讀寫分離簡單的說是把對數(shù)據(jù)庫讀和寫的操作分開對應(yīng)不同的數(shù)據(jù)庫服務(wù)器,這樣能有效地減輕數(shù)據(jù)庫壓力,也能減輕io壓力。主數(shù)據(jù)庫提供寫操作,從數(shù)據(jù)庫提供讀操作,其實(shí)在很多系統(tǒng)中,主要是讀的操作。當(dāng)主數(shù)據(jù)庫進(jìn)行寫操作時,數(shù)據(jù)要同步到從的數(shù)據(jù)庫,這樣才能有效保證數(shù)據(jù)庫完整性。
- 數(shù)據(jù)切分。通過某種特定的條件,將存放在同一個數(shù)據(jù)庫中的數(shù)據(jù)分散存放到多個數(shù)據(jù)庫上,實(shí)現(xiàn)分布存儲,通過路由規(guī)則路由訪問特定的數(shù)據(jù)庫,這樣一來每次訪問面對的就不是單臺服務(wù)器了,而是N臺服務(wù)器,這樣就可以降低單臺機(jī)器的負(fù)載壓力。
4. 其他優(yōu)化
(1) 適當(dāng)使用視圖加速查詢。
把表的一個子集進(jìn)行排序并創(chuàng)建視圖,有時能加速查詢(特別是要被多次執(zhí)行的查詢)。它有助于避免多重排序操作,而且在其他方面還能簡化優(yōu)化器的工作。視圖中的行要比主表中的行少,而且物理順序就是所要求的順序,減少了磁盤I/O,所以查詢工作量可以得到大幅減少。
(2) 算法優(yōu)化。
盡量避免使用游標(biāo),因?yàn)橛螛?biāo)的效率較差,如果游標(biāo)操作的數(shù)據(jù)超過1萬行,那么就應(yīng)該考慮改寫。使用基于游標(biāo)的方法或臨時表方法之前,應(yīng)先尋找基于集的解決方案來解決問題,基于集的方法通常更有效。與臨時表一樣,游標(biāo)并不是不可使用。對小型數(shù)據(jù)集使用 FAST_FORWARD 游標(biāo)通常要優(yōu)于其他逐行處理方法,尤其是在必須引用幾個表才能獲得所需的數(shù)據(jù)時。
(3)封裝存儲過程。
經(jīng)編譯和優(yōu)化后存儲在數(shù)據(jù)庫服務(wù)器中,運(yùn)行效率高,可以降低客戶機(jī)和服務(wù)器之間的通信量,有利于集中控制,易于維護(hù)。
























