













NLP預(yù)訓(xùn)練范式大一統(tǒng),不再糾結(jié)下游任務(wù)類型,谷歌這個新框架刷新50個SOTA
在這篇論文中,來自谷歌的研究者提出了一種統(tǒng)一各種預(yù)訓(xùn)練范式的預(yù)訓(xùn)練策略,這種策略不受模型架構(gòu)以及下游任務(wù)類型影響,在 50 項 NLP 任務(wù)中實現(xiàn)了 SOTA 結(jié)果。
當(dāng)前,NLP 研究人員和從業(yè)者有大量的預(yù)訓(xùn)練模型可以選擇。在回答應(yīng)該使用什么模型的問題時,答案通常取決于需要完成什么任務(wù)。
這個問題并不容易回答,因為涉及許多更細(xì)節(jié)的問題,例如使用什么樣的架構(gòu)?span corruption 還是語言模型?答案似乎取決于目標(biāo)下游任務(wù)。
來自谷歌的研究者重新思考了這一問題,他們具體回答了為什么預(yù)訓(xùn)練 LM 的選擇要依賴于下游任務(wù),以及如何預(yù)訓(xùn)練在許多任務(wù)中普遍適用的模型。
該研究試圖讓普遍適用的語言模型成為可能,提出了一個統(tǒng)一的語言學(xué)習(xí)范式,簡稱 UL2 框架。該框架在一系列非常多樣化的任務(wù)和環(huán)境中均有效。

論文鏈接:https://arxiv.org/pdf/2205.05131.pdf
代碼地址:https://github.com/google-research/google-research/tree/master/ul2
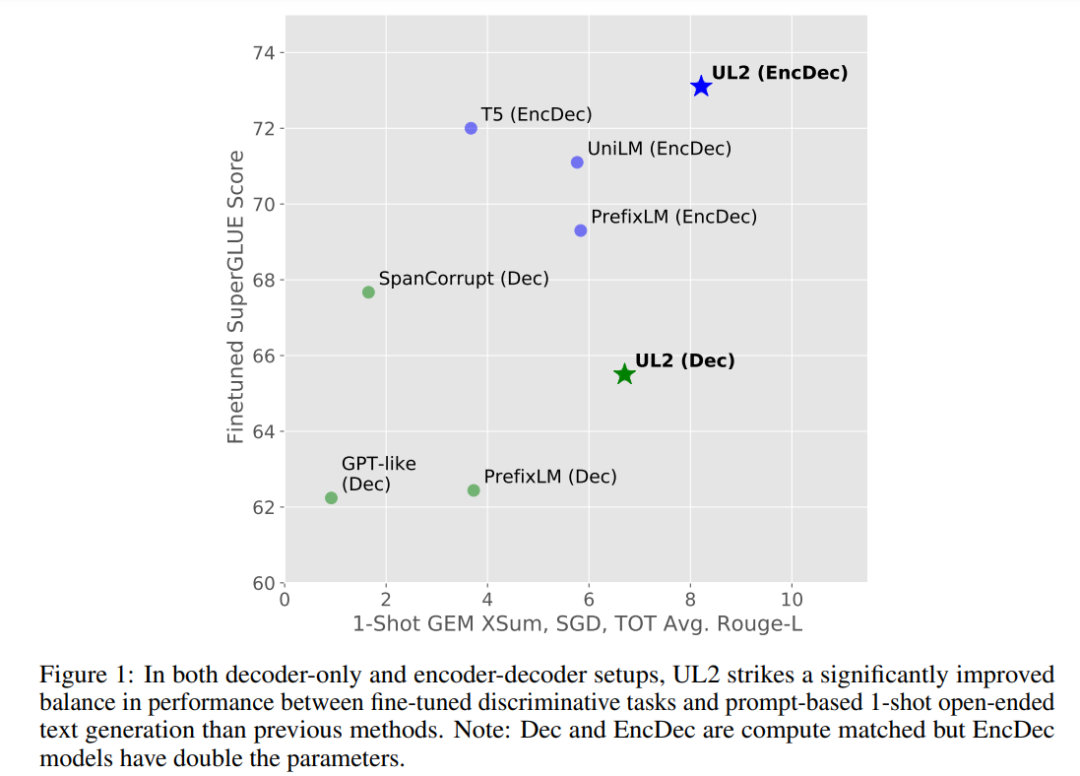
如下圖 1 所示,與其他需要權(quán)衡取舍的模型不同。UL2 模型的性能普遍良好。
通用模型的優(yōu)勢是顯而易見的。有了通用模型,研究者就可以集中精力改進(jìn)和擴(kuò)展單個模型,而不是在 N 個模型上分散資源。此外,在只能為少數(shù)模型提供資源的受限環(huán)境下,最好有一個可以在多種任務(wù)上表現(xiàn)良好的預(yù)訓(xùn)練模型。
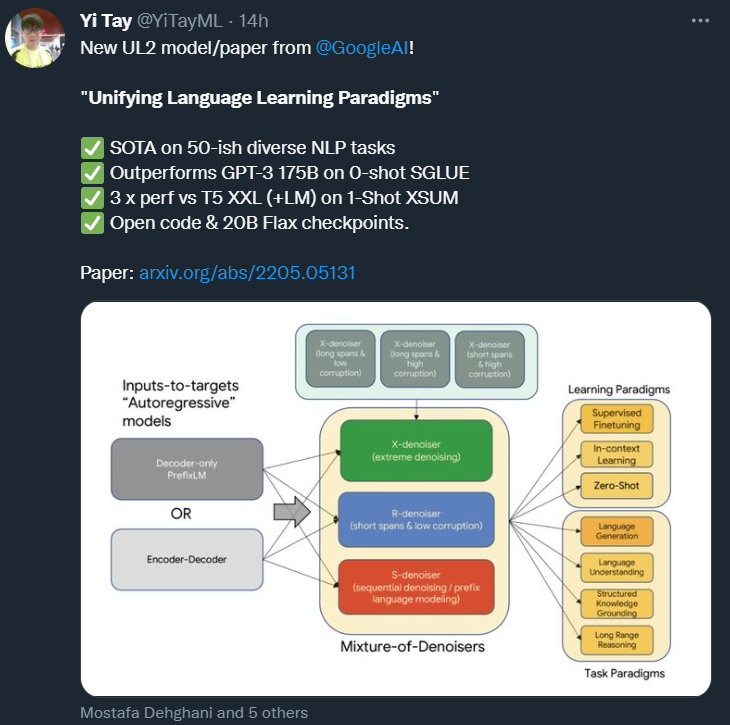
UL2 的核心是一種新提出的預(yù)訓(xùn)練目標(biāo) Mixture-of-Denoisers(MoD),可實現(xiàn)跨任務(wù)的強(qiáng)大性能。MoD 是幾個成熟的去噪目標(biāo)和新目標(biāo)的混合體,包括考慮 extreme span 長度和損壞率的 X-denoising(extreme denoising)、嚴(yán)格遵循序列順序的 S-denoising(sequential denoising)和標(biāo)準(zhǔn) span 損壞目標(biāo)的 R-denoising(regular denoising)。該研究表明,MoD 雖然在概念上很簡單,但對于多種任務(wù)都非常有效。
該方法利用一種思路:對于大多數(shù)預(yù)訓(xùn)練目標(biāo)來說,模型所依賴的上下文類型各有不同。例如,span corruption 目標(biāo)類似于調(diào)用前綴語言建模 (PLM) 的多個區(qū)域(Liu et al., 2018; Raffel et al., 2019),其中前綴是 non-corrupted token 的連續(xù)片段,目標(biāo)(target)具有所有 PLM 片段前綴的訪問權(quán)限。span 接近全序列長度的設(shè)置可以近似看作一個以長程上下文為條件的語言建模目標(biāo)。
因此,研究者認(rèn)為可以設(shè)計一個預(yù)訓(xùn)練目標(biāo),將這些不同的范式結(jié)合起來( span corruption vs 語言建模 vs 前綴語言建模)。
不難看出,每個去噪器(denoiser)的難度不同,其外推或內(nèi)插的性質(zhì)也不同。
根據(jù) MoD 的公式,研究者推測該模型不僅能在預(yù)訓(xùn)練期間區(qū)分不同的去噪器,而且在學(xué)習(xí)下游任務(wù)時能自適應(yīng)地切換模式,這種形式是很有益的。
該研究提出了模式切換,這是一個將預(yù)訓(xùn)練任務(wù)與專用標(biāo)記 token 相關(guān)聯(lián)的新概念,允許通過離散 prompting 進(jìn)行動態(tài)模式切換。該模型在經(jīng)過預(yù)訓(xùn)練后能夠按需在 R、S 和 X 去噪器之間切換模式。
然后,研究者將該架構(gòu)與自監(jiān)督方案解耦。雖然「預(yù)訓(xùn)練模型的主要特征是其主干架構(gòu)」這一說法可能是一個常見的誤解,但研究者發(fā)現(xiàn),denoiser 的選擇實際上具有更大的影響。MoD 支持任一主干架構(gòu),類似于 T5 的 span corruption 可以用一個 decoder-only 模型來訓(xùn)練。因此,架構(gòu)的選擇對 UL2 影響不大。研究者認(rèn)為主干架構(gòu)的選擇主要是不同效率指標(biāo)之間的權(quán)衡。
研究者在 9 種不同的任務(wù)上進(jìn)行了系統(tǒng)的消融實驗,這 9 個任務(wù)旨在解決不同的問題。
此外,該研究在開放文本生成任務(wù)上進(jìn)行了評估,并在基于 prompt 的單樣本環(huán)境下對所有任務(wù)進(jìn)行了評估。消融實驗的結(jié)果表明,UL2 在所有 9 個任務(wù)上都優(yōu)于 T5 和 GPT 類基線。平均而言,UL2 比 T5 基線高出 +43.6%,比一個語言模型高出 +76.1%。在其他競爭基線中,UL2 是唯一在所有任務(wù)上都優(yōu)于 T5 和 GPT 類模型的方法。
研究者進(jìn)一步將 UL2 擴(kuò)展到大約 20B(準(zhǔn)確地說是 19.5 B)參數(shù)的中等規(guī)模,并在包含 50 多個 NLP 任務(wù)的多樣化的組合中進(jìn)行實驗,這些任務(wù)包括語言生成(具有自動和人工評估)、語言理解、文本分類、問答、常識推理、長文本推理、結(jié)構(gòu)化知識基礎(chǔ)和信息檢索。實驗結(jié)果表明,UL2 在絕大多數(shù)任務(wù)和環(huán)境下都達(dá)到了 SOTA。
最后,研究者使用 UL2 進(jìn)行了零 / 少樣本實驗,并表明 UL2 在零樣本 SuperGLUE 上的性能優(yōu)于 GPT-3 175B。與 GLaM (Du et al., 2021)、PaLM (Chowdhery et al., 2022) 和 ST-MoE (Zoph et al., 2022) 等較新的 SOTA 模型相比,UL2 盡管僅在 C4 語料庫上進(jìn)行了訓(xùn)練,但在計算匹配環(huán)境下的性能仍然極具競爭力。
研究者深入分析了零樣本與微調(diào)性能之間的權(quán)衡,表明 UL2 在兩種學(xué)習(xí)范式上都是帕累托有效的。UL2 的性能是一個 LM adapted T5 XXL 模型的三倍,在相同的計算成本下可與 PaLM 和 LaMDA 媲美。
這篇論文的(并列)第一作者是谷歌 AI 高級研究科學(xué)家 Yi Tay 和谷歌大腦研究科學(xué)家 Mostafa Dehghani。
Yi Tay 2019 年在新加坡南洋理工大學(xué)拿到計算機(jī)科學(xué)博士學(xué)位。他是一位高產(chǎn)的論文作者,曾在 2018 年一年之內(nèi)以第一作者身份發(fā)表了 14 篇領(lǐng)域內(nèi)頂會論文。此外,他的論文也拿到過多個獎項,如 ICLR 2021 年杰出論文獎、WSDM 2021 年最佳論文獎(亞軍)和 WSDM 2020 年最佳論文獎(亞軍)。此外,他還曾擔(dān)任 EMNLP 和 NAACL 等頂級 NLP 會議的區(qū)域主席。
Mostafa Dehghani 在阿姆斯特丹大學(xué)拿到的博士學(xué)位,獲得過 ACM SIGIR ICTIR 2016 年最佳論文獎等獎項。他在谷歌主要研究基于注意力的視覺和語言模型,是熱門論文《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》的作者之一。
以下是論文細(xì)節(jié)。
UL2 詳解
用統(tǒng)一視角看預(yù)訓(xùn)練任務(wù)
許多預(yù)訓(xùn)練任務(wù)可以被簡單地表述為「輸入到目標(biāo)(input-to-target)」型任務(wù),其中輸入指的是模型所依賴的任何形式的記憶或上下文,而目標(biāo)是模型的預(yù)期輸出。語言模型使用所有以前的時間步作為輸入來預(yù)測下一個 token,即目標(biāo)。在 span corruption 中,模型利用來自過去和未來的所有未損壞的 token 作為預(yù)測 corrupted span(目標(biāo))的輸入。Prefix-LM 是使用過去的 token 作為輸入的語言模型,但它雙向使用輸入:這比普通語言模型中輸入的單向編碼提供了更強(qiáng)的建模能力。
從這個角度來看,我們可以將一個預(yù)訓(xùn)練目標(biāo)簡化為另一個目標(biāo)。例如,在 span corruption 目標(biāo)中,當(dāng) corrupted span(目標(biāo))等于整個序列時,該問題實際上就變成了一個語言建模問題。考慮到這一點(diǎn),使用 span corruption,通過將 span 長度設(shè)置得很大,我們可以在局部區(qū)域中有效地模擬語言建模目標(biāo)。
研究者們定義了一個符號,它涵蓋了本文中使用的所有不同的去噪任務(wù)。去噪任務(wù)的輸入和目標(biāo)由 SPANCORRUPT 函數(shù)生成,該函數(shù)由三個值 (μ, r, n) 來參數(shù)化,其中 μ 是平均 span 長度,r 是 corruption rate,n 是 corrupted span 的數(shù)量。注意,n 可能是輸入長度 L 和 span 長度 μ 的函數(shù),如 L/μ,但在某些情況下,研究者使用 n 的固定值。給定輸入文本,SPANCORRUPT 將 corruption 引入從具有 u 均值的(正態(tài)或均勻)分布中提取的長度的 span。在 corruption 之后,輸入文本被饋送到去噪任務(wù),corrupted span 被用作要恢復(fù)的目標(biāo)。
舉個例子,用這個公式來構(gòu)建一個類似于因果語言建模的目標(biāo),只需設(shè)置 (μ = L, r = 1.0, n = 1) ,即單個 span 的長度等于序列的長度。要表達(dá)一個類似于 Prefix LM 的目標(biāo),可以設(shè)置 (μ = L ? P, r = 1.0 ? P/L, n = 1) ,其中 P 是 prefix 的長度,附加的約束是單個 corrupted span 總是到達(dá)序列的末尾。
研究者注意到,這種 inputs-to-target 的公式既可以應(yīng)用于編碼器 - 解碼器模型,也可以應(yīng)用于單棧 Transformer 模型(如解碼器模型)。他們選擇了預(yù)測下一個目標(biāo) token 的模型,而不是就地預(yù)測的模型(例如 BERT 中的預(yù)測當(dāng)前掩蔽 token),因為下一個目標(biāo)公式更通用,并且可以包含更多的任務(wù),而不是使用特殊的「CLS」token 和特定于任務(wù)的 projection head。
Mixture of Denoisers
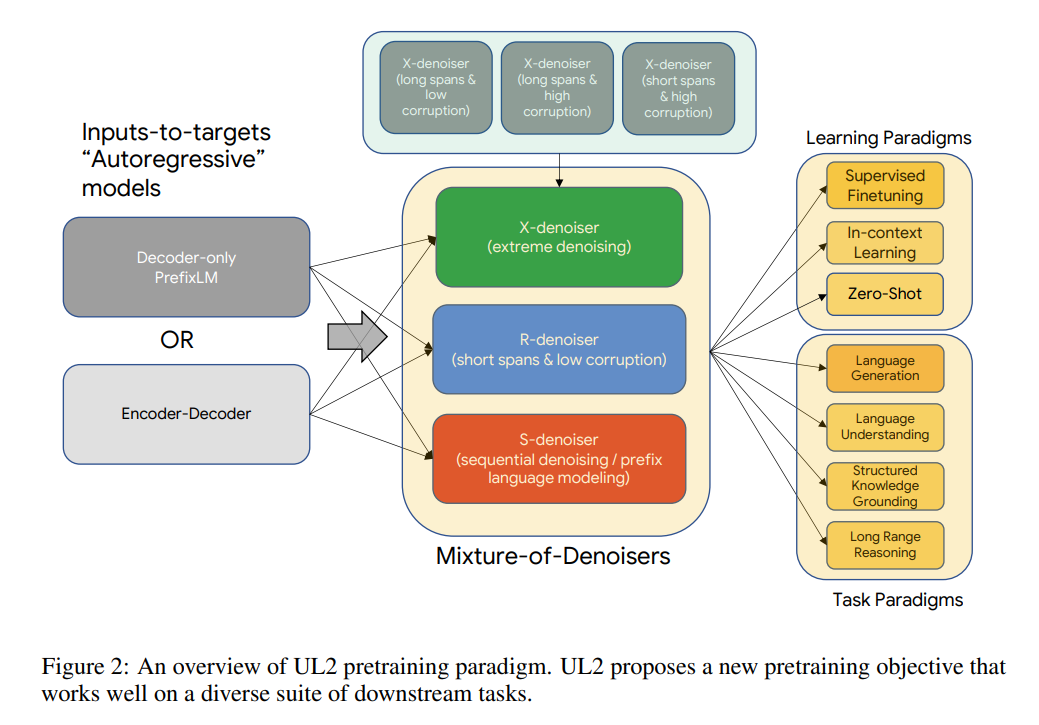
研究者認(rèn)為,在預(yù)訓(xùn)練期間,一個強(qiáng)大的通用模型必須去面對、解決不同的問題集。假設(shè)預(yù)訓(xùn)練是使用自監(jiān)督完成的,研究者認(rèn)為這種多樣性應(yīng)該被注入到模型的目標(biāo)中,否則模型可能會缺乏某種能力,比如連貫長文本生成能力。
基于此,以及當(dāng)前的目標(biāo)函數(shù)類型,他們定義了預(yù)訓(xùn)練期間使用的三種主要范式:
R-Denoiser,regular denoising 是 Raffel et al. (2019) 引入的標(biāo)準(zhǔn) span corruption,它使用 2 到 5 個 token 作為 span length,遮蔽了大約 15% 的輸入 token。這些 span 非常短,可能有助于知識獲取(而非學(xué)習(xí)生成流暢的文本)。
S-Denoiser,去噪的一種具體情況,在構(gòu)建 inputs-to-targets 任務(wù)時遵守嚴(yán)格的順序,即 prefix 語言建模。為此,研究者只需將輸入序列劃分為兩個 token 子序列,分別作為上下文和目標(biāo),這樣目標(biāo)就不依賴于未來的信息。這與標(biāo)準(zhǔn) span corruption 不同,在標(biāo)準(zhǔn) span corruption 中,可能存在位置比上下文 token 更早的目標(biāo) token。注意,與 Prefix-LM 設(shè)置類似,上下文(prefix)保留了一個雙向感受野。研究者注意到,具有非常短的記憶或沒有記憶的 S-Denoising 與標(biāo)準(zhǔn)的因果語言建模的精神是相似的。
X-Denoiser,去噪的一種 extreme 版本,模型必須恢復(fù)輸入的絕大部分。這模擬了模型需要借助有限信息記憶生成長目標(biāo)的情況。為此,研究者選擇了包含積極去噪的例子,其中大約 50% 的輸入序列被遮蔽。這是通過增加 span 長度和 / 或 corruption 率來實現(xiàn)的。如果預(yù)訓(xùn)練任務(wù) span 長(如≥ 12 個 token)或 corruption 率高(如≥ 30%),就認(rèn)為該任務(wù)是 extreme 的。X-denoising 的動機(jī)是作為常規(guī) span corruption 和類似目標(biāo)的語言模型之間的插值而存在。

這組 denoiser 與先前使用的目標(biāo)函數(shù)有很強(qiáng)的聯(lián)系:R-Denoising 是 T5 span corruption 目標(biāo),S-Denoising 與類 GPT 的因果語言模型相關(guān),而 X-Denoising 可以將模型暴露給來自 T5 和因果 LM 的目標(biāo)的組合。值得注意的是,X-denoiser 也被連接起來以提高樣本效率,因為在每個樣本中可以學(xué)習(xí)到更多的 token 來預(yù)測,這與 LM 的理念類似。研究者提出以統(tǒng)一的方式混合所有這些任務(wù),并有一個混合的自監(jiān)督的目標(biāo)。最終目標(biāo)是混合 7 個去噪器,配置如下:

對于 X - 和 R-Denoiser,span 長度從均值為 μ 的正態(tài)分布中采樣。對于 S-denoiser,他們使用均勻分布,將 corrupted span 的數(shù)量固定為 1,并且具有額外的約束,即 corrupted span 應(yīng)該在原始輸入文本的末尾結(jié)束,在 corrupted 部分之后不應(yīng)該出現(xiàn)未被裁剪的 token。這大致相當(dāng)于 seq2seq 去噪或 Prefix LM 預(yù)訓(xùn)練目標(biāo)。
由于 LM 是 Prefix-LM 的一種特殊情況,研究者認(rèn)為沒有必要在混合中包含一個偶然的 LM 任務(wù)。所有任務(wù)在混合中具有大致相同的參與度。研究者還探索了一種替代方案,他們將混合配置中 S-denoiser 的分量增加到 50%,其余份額由其他 denoiser 共享。
最后,「混合」這一動作使得 Mixture-of-Denoisers 具有非常強(qiáng)的通用性。單獨(dú)來看,一些 denoiser 類型表現(xiàn)不佳。例如,最初的 T5 論文探索了一個具有 50% corruption rate 的選項(X-denoising),但發(fā)現(xiàn)效果不佳。
UL2 的 Mixture-of-Denoisers 的實現(xiàn)非常簡單,使用 seqio3 之類的庫很容易實現(xiàn)。
模式切換
研究者引入了通過模式切換進(jìn)行范式轉(zhuǎn)換的概念。在預(yù)訓(xùn)練期間,他們?yōu)槟P吞峁┝艘粋€額外的范式 token,即 {[R],[S],[X]},這有助于模型切換到更適合給定任務(wù)的模式。對于微調(diào)和下游 few-shot 學(xué)習(xí),為了觸發(fā)模型學(xué)習(xí)更好的解決方案,研究者還添加了一個關(guān)于下游任務(wù)的設(shè)置和要求的范式 token。模式切換實際上是將下游行為綁定到上游訓(xùn)練中使用的模式之一上。
消融實驗結(jié)果
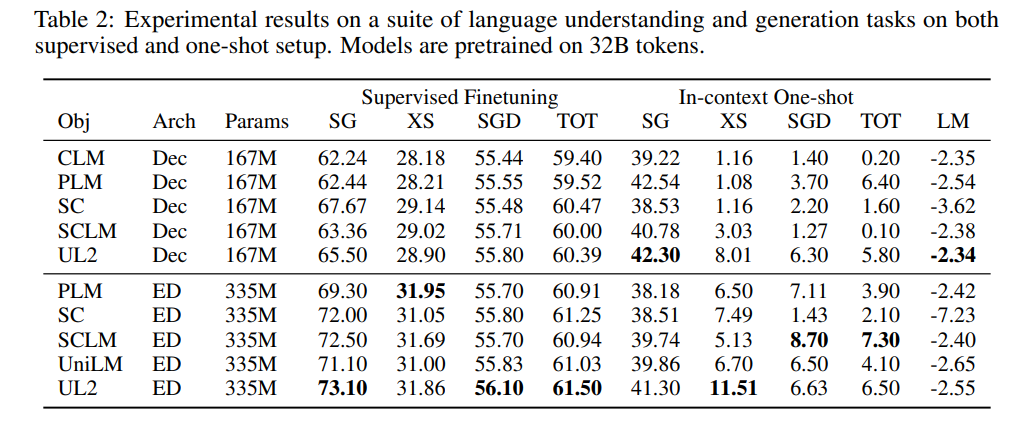
表 2 顯示了在所有基準(zhǔn)測試任務(wù)和數(shù)據(jù)集上的原始結(jié)果。
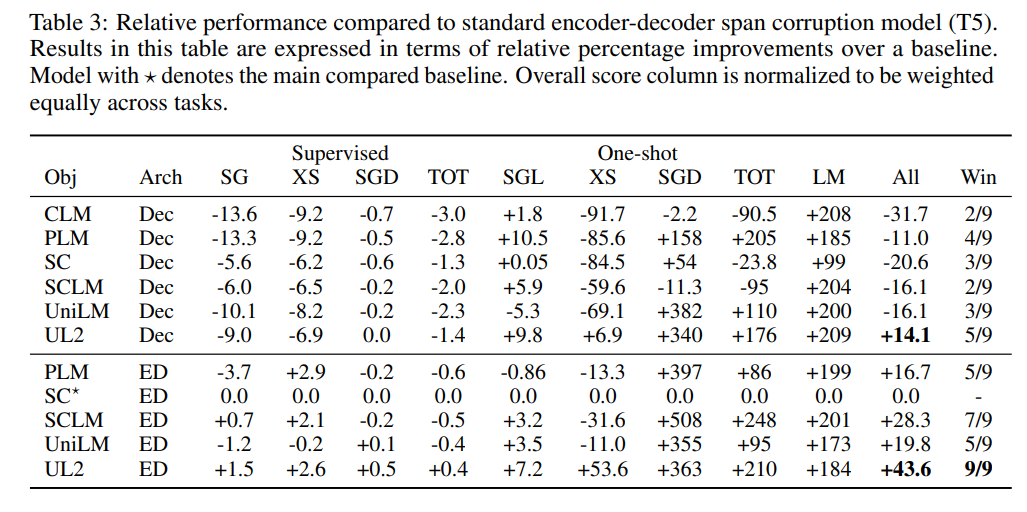
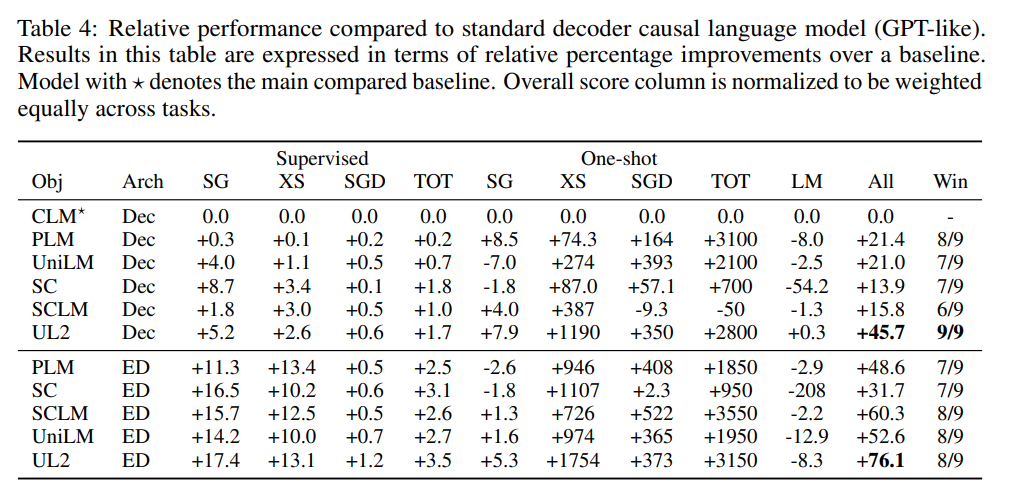
為了方便不同設(shè)置之間的比較,研究者還給出了 UL2 與已建立的基線(如 T5 和 GPT 模型)的相對比較,如表 3 和表 4 所示。
擴(kuò)展到 200 億參數(shù)之后的結(jié)果
圖 8 顯示了 UL20B 在不同任務(wù)中與之前 SOTA 的對比結(jié)果。

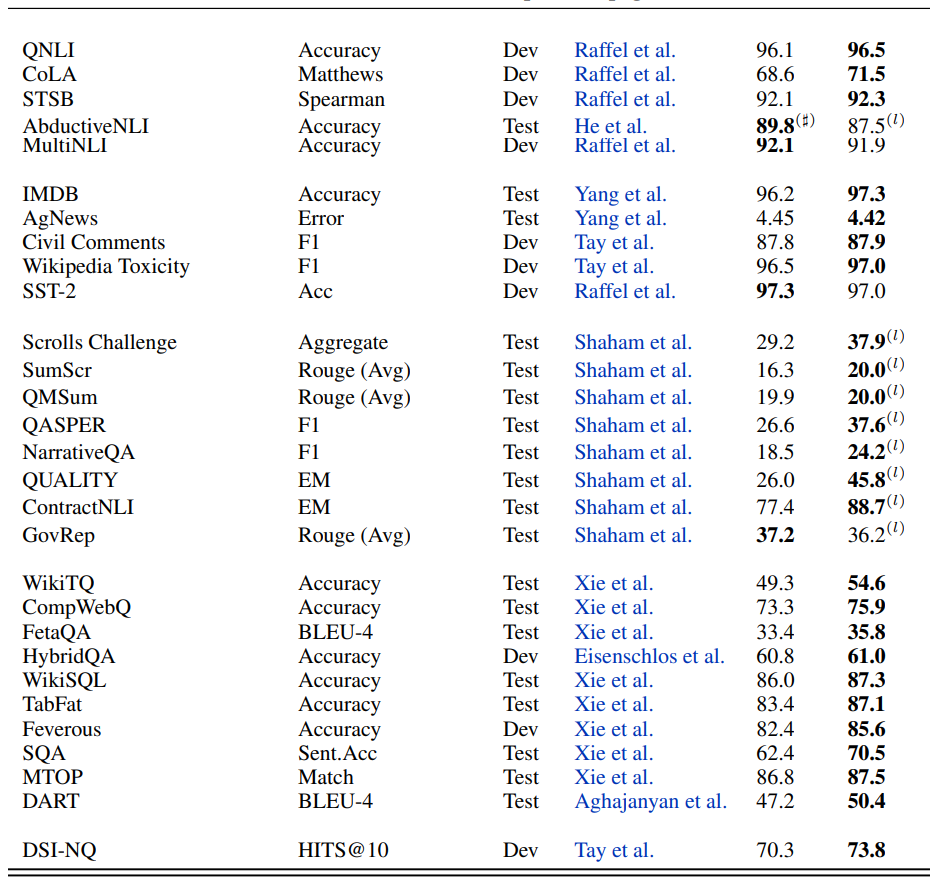
更多細(xì)節(jié)請參見原論文。

























