20行Python代碼,輕松提取PPT文字到Word!

大家好,我是菜鳥(niǎo)哥!今天跟大家分享一個(gè)非常實(shí)用的Python程序。
遇到的困惑
許多小伙伴不管在學(xué)校還是在工作當(dāng)中,都會(huì)遇到一個(gè)問(wèn)題,就是將PPT中的文字提取出來(lái)保存到word當(dāng)中,這樣可以方便自己的閱讀或者是將文字打印出來(lái)。但是很多時(shí)候,小伙伴們只能將PPT中的文字通過(guò)復(fù)制粘貼的方式,來(lái)一張張的提取出來(lái)。這樣的操作方式無(wú)疑非常的低效,今天菜鳥(niǎo)哥就帶給大家新的方法,利用程序來(lái)批量的提取PPT中的文字,并保存到word文檔中,一起來(lái)看看吧。

1.應(yīng)有的場(chǎng)景
比如我有這么一個(gè)PPT的內(nèi)容,里面有很多的文字和圖片,其中的文字我是比較感興趣的,尤其是在論文或者是一些重要的學(xué)術(shù)的報(bào)告的ppt中,很多的文字需要提取分析。下面我舉例一個(gè)簡(jiǎn)單的PPT頁(yè)面:

可以看到,上圖的PPT中包含了一些文字和圖片的內(nèi)容信息,但是我只想提取文字,其實(shí)這個(gè)用Python就可以輕松搞定,看一下最后的效果:
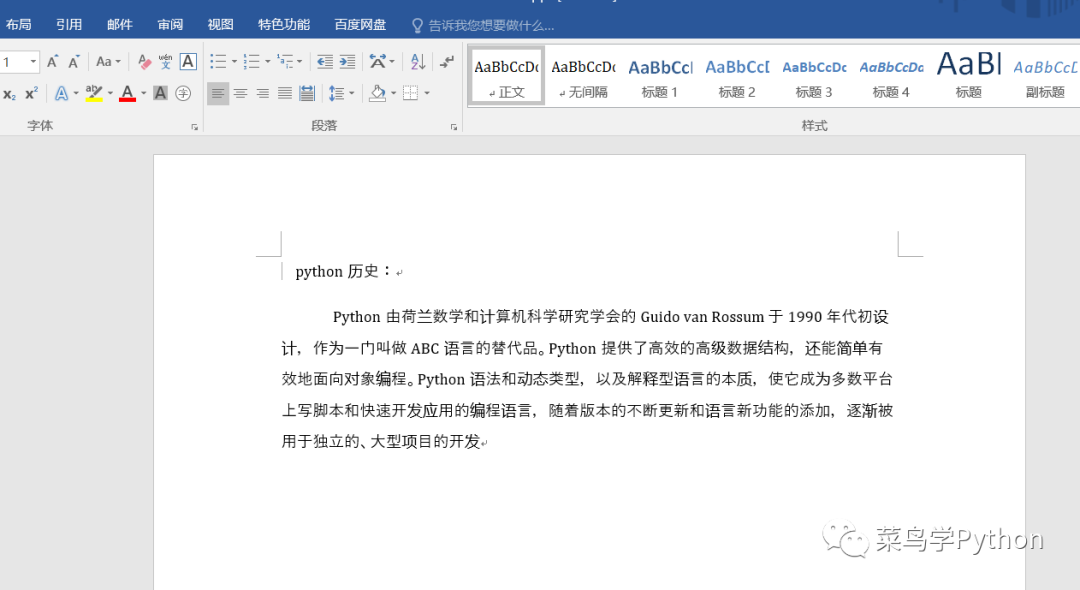
效果還不錯(cuò)吧,其實(shí)非常簡(jiǎn)單的,一起看一下怎么做的。
2.程序的設(shè)計(jì)
我們主要是用到的是python-pptx庫(kù)以及python-docx庫(kù)。分別用于PPT文件以及word文件的處理。用pip3即可直接安裝,整個(gè)程序非常短小精悍,這其核心代碼僅僅只需要六行,程序如下圖所示:
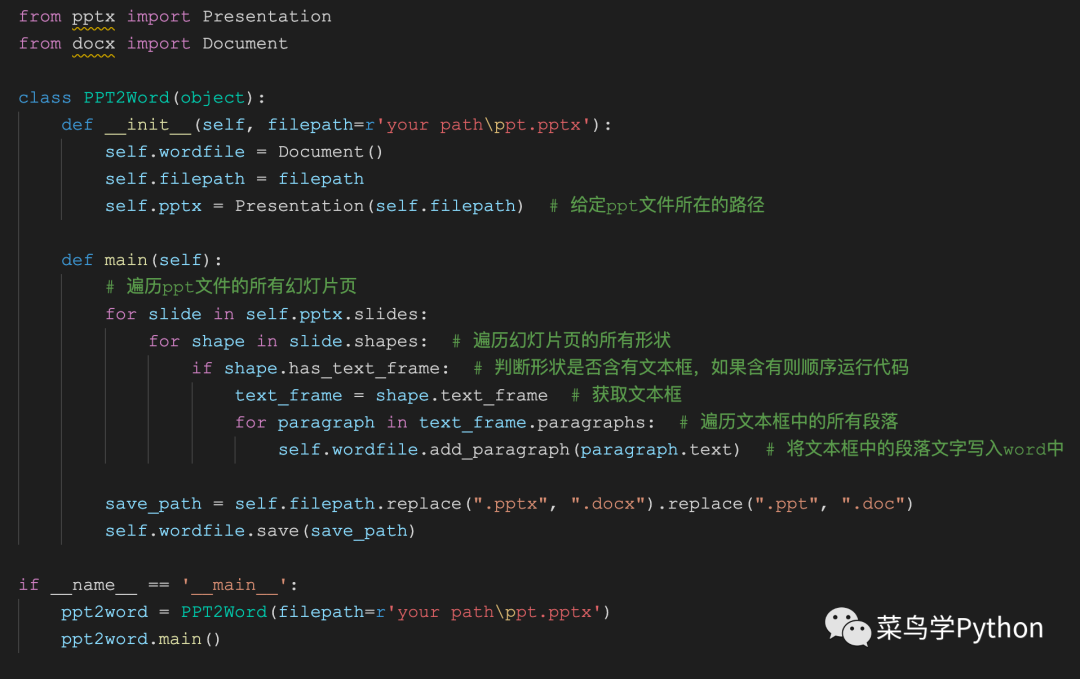
代碼其實(shí)很簡(jiǎn)短的,為了讓大家更好的理解這個(gè)程序,可以結(jié)合下面這張圖來(lái)給大家一一解釋。
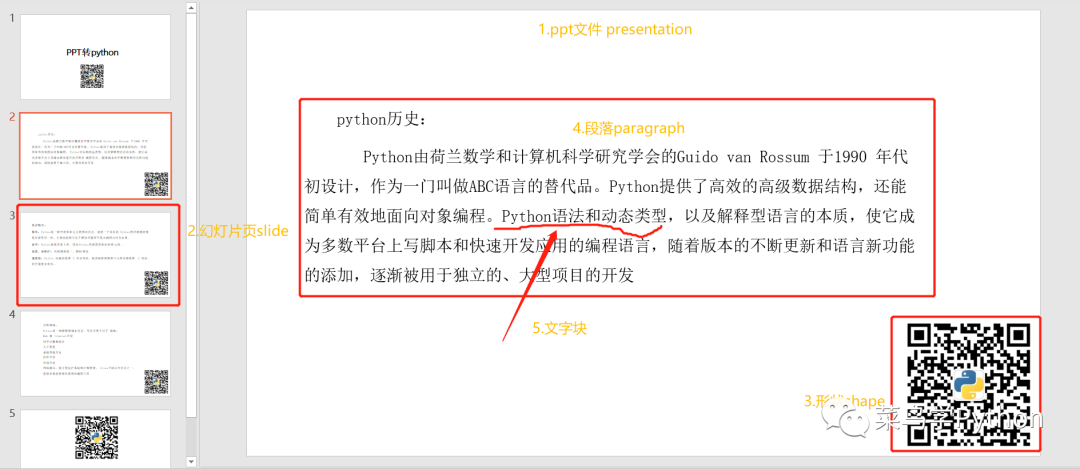
在程序中,我們一共用了3層循環(huán)來(lái)處理:
1).第一層的for循環(huán)用來(lái)循環(huán)每一頁(yè)的幻燈片頁(yè)slide;
2).第二個(gè)循環(huán)中判斷幻燈片中的每一個(gè)形狀,然后判斷該頁(yè)中是否含有文本框,如果有文本框,則獲取文本框,并命名為text_frame。
3).第三個(gè)for循環(huán)則遍歷了文本框中的所有段落內(nèi)容,提取其中的文字保存到word當(dāng)中。
當(dāng)遍歷完整個(gè)的PPT文件后,將所有提取到的文字信息保存到本地的word文檔當(dāng)中。效果如下圖所示:

上圖的PPT文件當(dāng)中,包含了四張帶有文字的slide幻燈片。當(dāng)運(yùn)行程序后,其文字的提取結(jié)果如下圖所示。

以上就是菜鳥(niǎo)哥今天為大家?guī)?lái)的自動(dòng)化案例分享,通過(guò)短短的幾行代碼,可以大大的提高大家的工作效率,大家也利用程序,進(jìn)行快速的提取吧。