都是同樣條件的MySQL Select語(yǔ)句,為什么讀到的內(nèi)容卻不一樣?
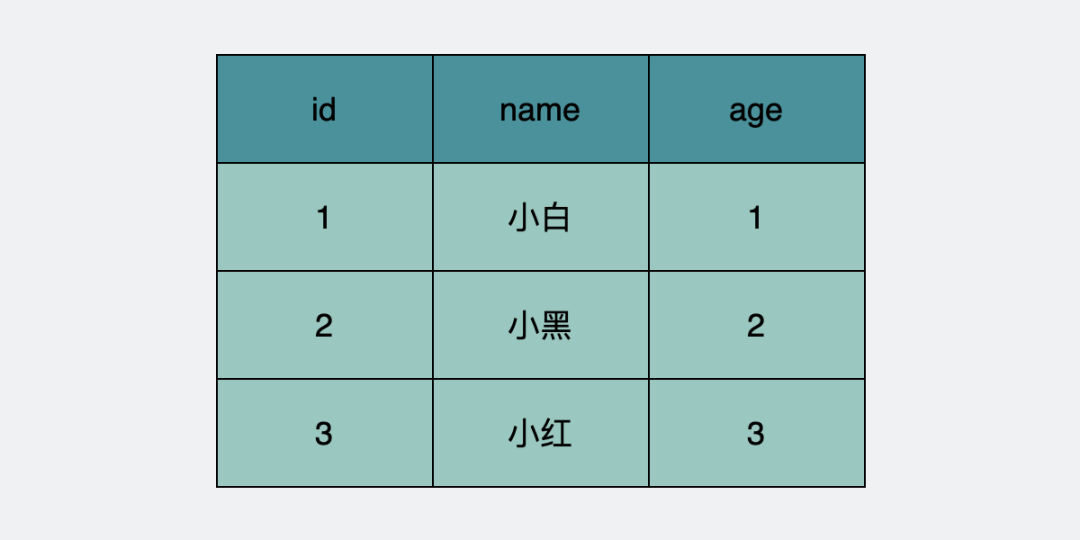
假設(shè)當(dāng)前數(shù)據(jù)庫(kù)里有下面這張表。
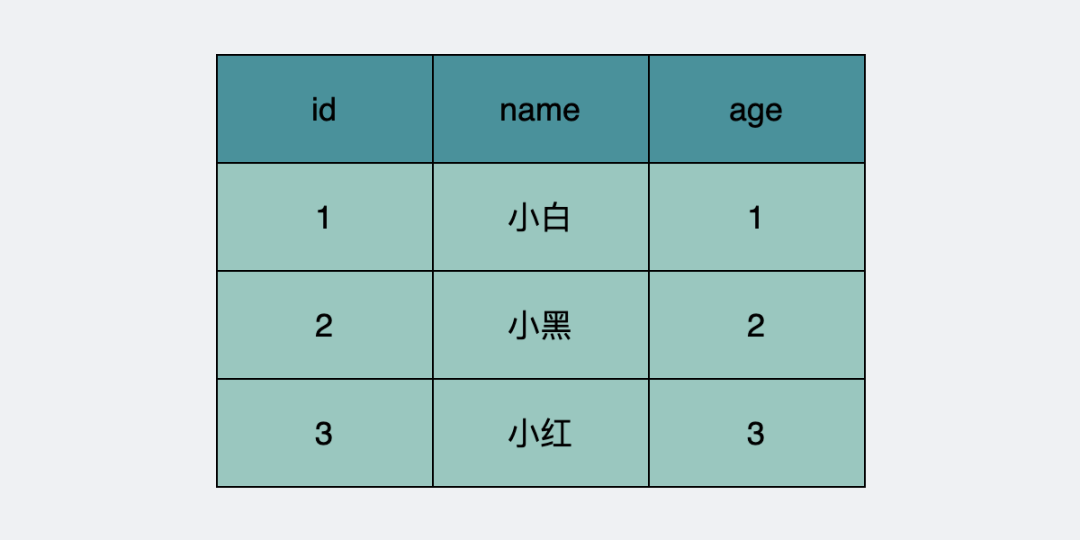
user表數(shù)據(jù)庫(kù)原始狀態(tài)
老規(guī)矩,以下內(nèi)容還是默認(rèn)發(fā)生在innodb引擎的可重復(fù)讀隔離級(jí)別下。
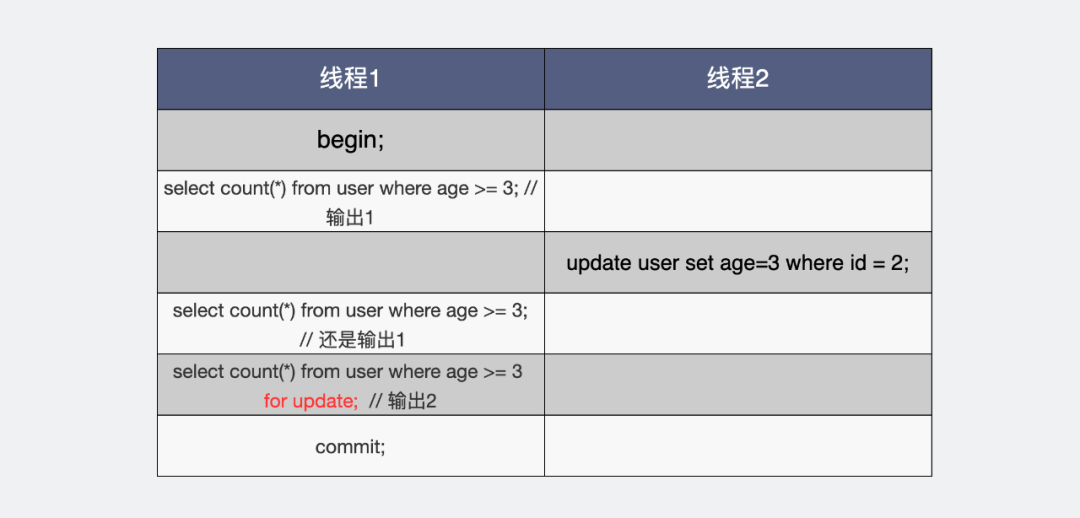
都是select結(jié)果卻不同
大家可以看到,線程1,同樣都是讀 age >= 3 的數(shù)據(jù)。第一次讀到1條數(shù)據(jù),這個(gè)是原始狀態(tài)。這之后線程2將id=2的age字段也改成了3。
線程1此時(shí)再讀兩次,一次讀到的結(jié)果還是原來(lái)的1條,另一次讀的結(jié)果卻是2條,區(qū)別在于加沒(méi)加for update。
為什么同樣條件下,都是讀,讀出來(lái)的數(shù)據(jù)卻不一樣呢?
可重復(fù)讀不是要求每次讀出來(lái)的內(nèi)容要一樣嗎?
要回答這個(gè)問(wèn)題。
我需要從盤古是怎么開(kāi)天辟地這個(gè)話題開(kāi)始聊起。
不好意思。
失態(tài)了。
那就從事務(wù)是怎么回滾的開(kāi)始聊起吧。
事務(wù)的回滾是怎么實(shí)現(xiàn)的
我們?cè)趫?zhí)行事務(wù)的時(shí)候,一般都是下面這樣的格式
begin;
操作1;
操作2;
操作3;
xxxxx
....
commit;
在提交事務(wù)之前,會(huì)執(zhí)行各種操作,里面可以包含各種邏輯。
只要是執(zhí)行邏輯,那就有可能會(huì)報(bào)錯(cuò)。
回想下事務(wù)的ACID里有個(gè)A,原子性,整個(gè)事務(wù)就是個(gè)整體,要么一起成功,要么一起失敗。
ACID
如果失敗了的話,那就要讓執(zhí)行到一半的事務(wù)有能力回到?jīng)]執(zhí)行事務(wù)前的狀態(tài),這就是回滾。
執(zhí)行事務(wù)的代碼就類似寫成下面這樣。
begin;
try:
操作1;
操作2;
操作3;
xxxxx
....
commit;
except Exception:
rollback;
如果執(zhí)行rollback能回到事務(wù)執(zhí)行前的狀態(tài)的話,那說(shuō)明mysql需要知道某些行,執(zhí)行事務(wù)前的數(shù)據(jù)長(zhǎng)什么樣子。
那數(shù)據(jù)庫(kù)是怎么做到的呢?
這就要提到undo日志了,它記錄了某一行數(shù)據(jù),在執(zhí)行事務(wù)前是怎么樣的。
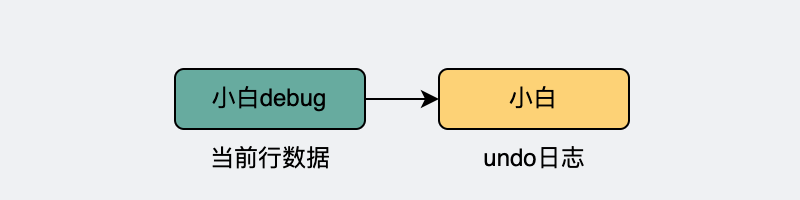
比如id=1那行數(shù)據(jù),name字段從"小白"更新成了"小白debug",那就會(huì)新增一個(gè)undo日志,用于記錄之前的數(shù)據(jù)。
 un
un
do日志會(huì)記錄之前的數(shù)據(jù)
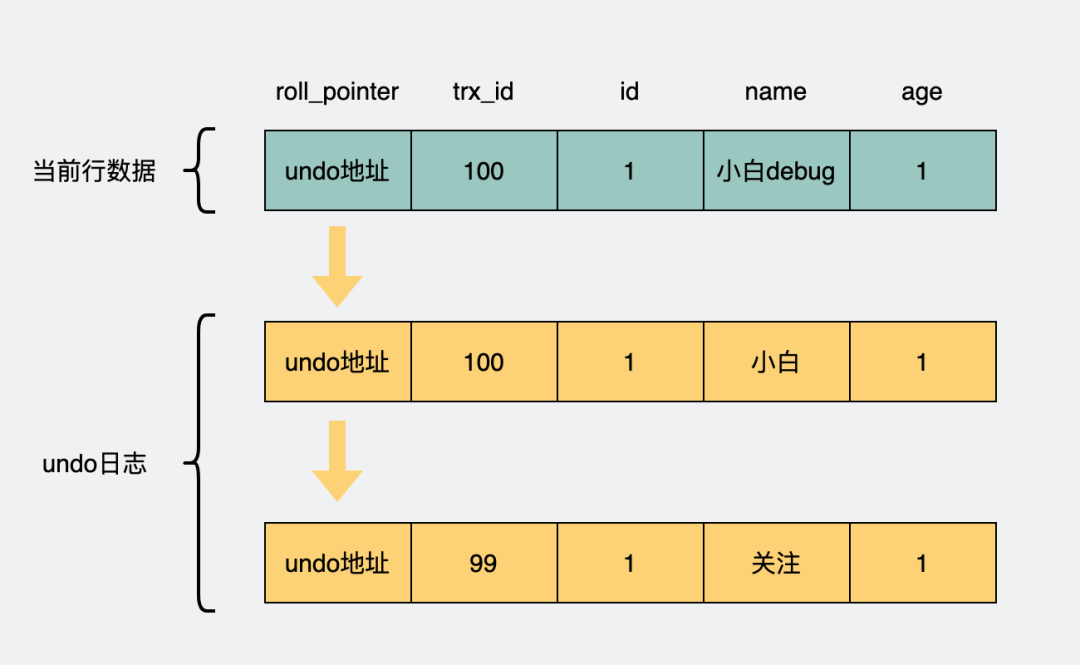
由于同時(shí)并發(fā)執(zhí)行的事務(wù)可以有很多,于是可能會(huì)有很多undo日志,日志里加入事務(wù)的id(trx_id)字段,用于標(biāo)明這是哪個(gè)事務(wù)下產(chǎn)生的undo日志。
同時(shí)將它們用鏈表的形式組織起來(lái),在undo日志里加入一個(gè)指針(roll_pointer),指向上一個(gè)undo日志,于是就形成了一條版本鏈。
 undo日志版本鏈
undo日志版本鏈
有了這個(gè)版本鏈,當(dāng)某個(gè)事務(wù)執(zhí)行到一半發(fā)現(xiàn)失敗時(shí),就直接回滾,這時(shí)候就可以順著這個(gè)版本鏈,回到執(zhí)行事務(wù)前的狀態(tài)。
當(dāng)前讀和快照讀是什么
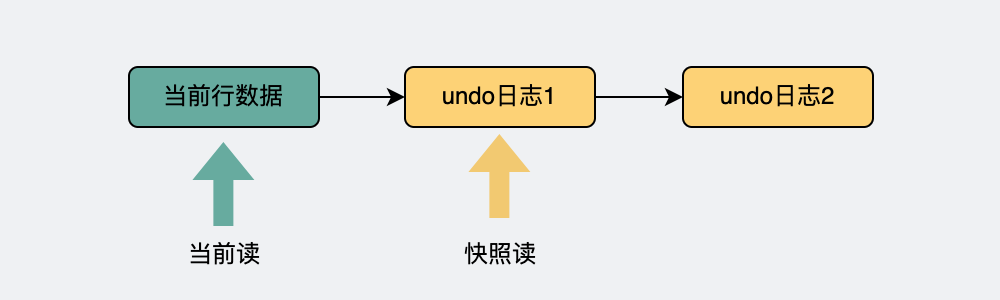
有了上面的undo日志版本鏈之后,我們可以看到最新的數(shù)據(jù)在表頭,在這之后的都是一個(gè)個(gè)舊的數(shù)據(jù)版本。不管是最新的,還是舊的數(shù)據(jù)版本,我們都叫它數(shù)據(jù)快照。
當(dāng)前讀,讀的就是版本鏈的表頭,也就是最新的數(shù)據(jù)。
快照讀,讀的就是版本鏈里的其中一個(gè)快照,當(dāng)然如果這個(gè)快照正好就是表頭,那此時(shí)快照讀和當(dāng)前讀的結(jié)果一樣。

當(dāng)前讀和快照讀
我們平時(shí)執(zhí)行的普通select語(yǔ)句,比如下面這種,就是快照讀。
select * from user where phone_no=2;
而特殊的select語(yǔ)句,比如在select后面加上lock in share mode或for update,都屬于當(dāng)前讀。
除此之外insert,update,delete操作都屬于寫操作,既然寫,那必然是寫最新的數(shù)據(jù),所以都會(huì)引發(fā)當(dāng)前讀。
那么問(wèn)題來(lái)了。
當(dāng)前讀,讀的是版本鏈的表頭,那么執(zhí)行當(dāng)前讀的時(shí)候,有沒(méi)有可能恰好有其他事務(wù),生成更加新的快照,替代當(dāng)前表頭,成為新的表頭呢,那這時(shí)候豈不是讀的不是最新數(shù)據(jù)了?
答案是不會(huì),不管是select … for update這些(特殊的)讀操作,還是insert、update這些寫操作,都會(huì)對(duì)這行數(shù)據(jù)加鎖。而生成undo日志快照,也是在寫操作的情況下生成的,執(zhí)行寫操作前也需要獲得鎖。所以寫操作需要阻塞等待當(dāng)前讀完成后,獲得鎖后才能更新版本鏈。
read view
數(shù)據(jù)庫(kù)里可以同時(shí)并發(fā)執(zhí)行非常多的事務(wù), 每個(gè)事務(wù)都會(huì)被分配一個(gè)事務(wù)ID, 這個(gè) ID 是遞增的,越新的事務(wù),ID 越大。
而數(shù)據(jù)表里某行數(shù)據(jù)的undo日志版本鏈,每個(gè)undo日志上面也有一個(gè)事務(wù)id (trx_id),它是創(chuàng)建這個(gè)undo日志的事務(wù)id。
并不是所有事務(wù)都會(huì)生成undo日志,也就是說(shuō)某行數(shù)據(jù)的undo日志版本鏈上只有部分事務(wù)的id。但是,所有事務(wù)都有可能會(huì)訪問(wèn)這行數(shù)據(jù)對(duì)應(yīng)的版本鏈。而且版本鏈上雖然有很多undo日志快照,但也不是所有undo日志都能被讀,畢竟有些undo日志,創(chuàng)建它們的事務(wù)還沒(méi)提交呢,人家隨時(shí)可能失敗并回滾。
現(xiàn)在的問(wèn)題就成了,現(xiàn)在有一個(gè)事務(wù),通過(guò)快照讀的方式去讀undo日志版本鏈,那它能讀哪些快照?并且它應(yīng)該讀哪個(gè)快照?
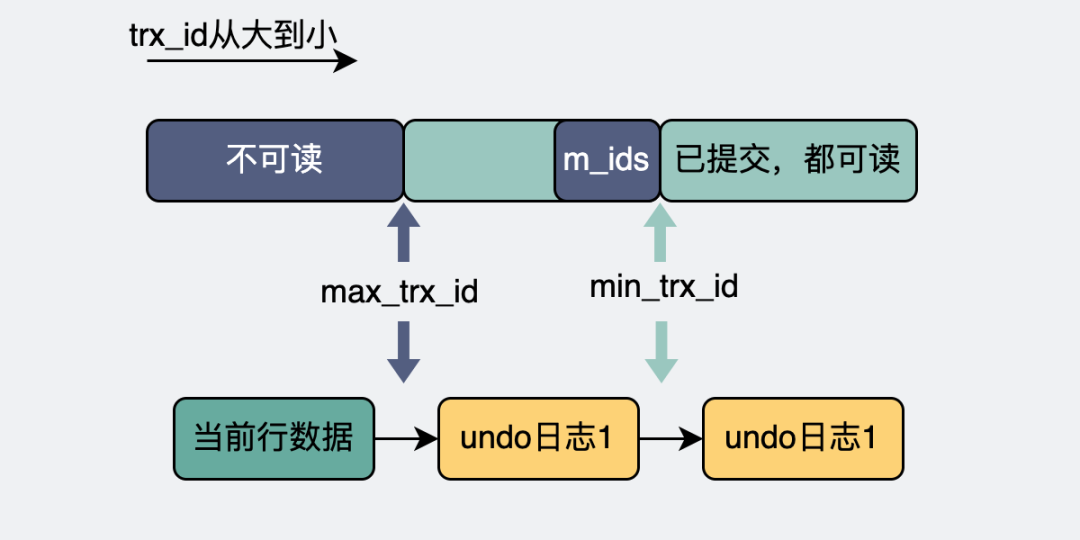
這里就要引入一個(gè)read view的概念。它就像是一個(gè)有上下邊界的滑動(dòng)窗口。
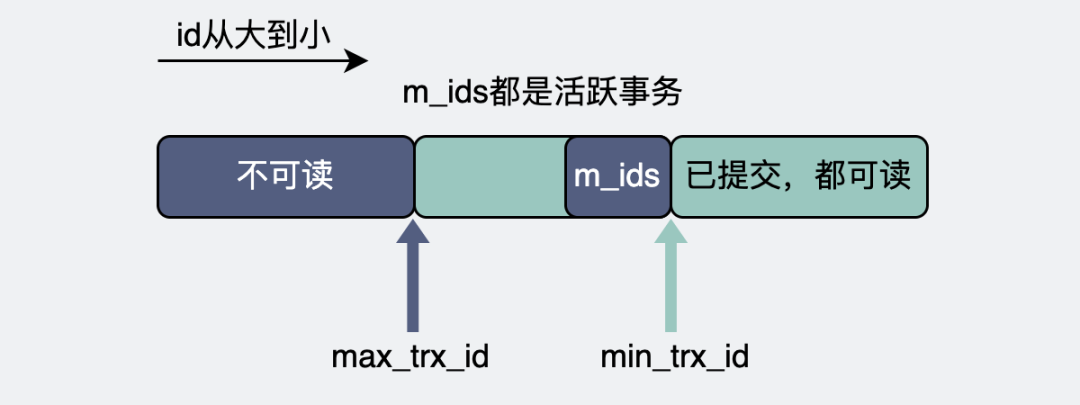
整個(gè)數(shù)據(jù)庫(kù)里有那么多事務(wù),這些事務(wù)分為已經(jīng)提交(commit)的,和沒(méi)提交的。沒(méi)提交的,意味著這些事務(wù)還在進(jìn)行中,也就是所謂的活躍事務(wù)。所有的活躍事務(wù)的id,組成m_ids。而這其中最小的事務(wù)id就是read view的下邊界,叫min_trx_id。
產(chǎn)生read view的那一刻,所有事務(wù)里最大的事務(wù)id,加個(gè)1,就是這個(gè)read view的上邊界,叫max_trx_id。
概念太多,有點(diǎn)亂?沒(méi)事的,繼續(xù)往下看,后面會(huì)有例子的。
事務(wù)能讀哪些快照
有了這些基礎(chǔ)信息之后,我們先看下事務(wù)在read view下,他能讀哪些快照呢?
記住一個(gè)大前提:事務(wù)只能讀到自己產(chǎn)生的undo日志數(shù)據(jù)(事務(wù)提不提交都行),或者是其他事務(wù)已經(jīng)提交完成的數(shù)據(jù)。
現(xiàn)在事務(wù)(假設(shè)就叫事務(wù)A吧)有了read view之后,不管看哪個(gè)undo日志版本鏈,我們都可以把read view往版本鏈上一放。版本鏈就被分成了好幾部分。

readview
- 版本鏈快照的trx_id < read view的min_trx_id。
從上面的描述中,我們可以知道read view的m_ids來(lái)源于數(shù)據(jù)庫(kù)所有活躍事務(wù)的id,而最小的min_trx_id就是read view的下邊界,因?yàn)槭聞?wù)id是根據(jù)時(shí)間遞增的,所以如果版本鏈快照的trx_id比 min_trx_id 還要小,那這些肯定都是非活躍(已經(jīng)提交)的事務(wù)id,這些快照都能被事務(wù)A讀到。
- 版本鏈快照的trx_id >= read view的max_trx_id。
max_trx_id是在事務(wù)A創(chuàng)建read view的那一刻產(chǎn)生的,它比那時(shí)候所有數(shù)據(jù)庫(kù)已知的事務(wù)id都還要大。所以如果undo日志版本鏈上的某個(gè)快照上含有比 max_trx_id 還要大的 trx_id,那說(shuō)明這個(gè)快照已經(jīng)超出事務(wù)A的"理解范圍了",它不該被讀到。
- read view的min_trx_id <= 版本鏈快照的trx_id < read view的max_trx_id。
- 如果版本鏈快照的trx_id正好就是事務(wù)A的id,那正好是它自己生成的undo日志快照,那不管有沒(méi)有提交,都能讀。
- 如果版本鏈快照的trx_id正好在活躍事務(wù)m_ids中, 那這些事務(wù)數(shù)據(jù)都還沒(méi)提交,所以事務(wù)A不能讀到它們。
- 除了上面兩種情況外,剩下的都是已經(jīng)提交的事務(wù)數(shù)據(jù),可以放心讀。
事務(wù)會(huì)讀哪個(gè)快照
上面提到,事務(wù)在read view的可見(jiàn)范圍里,有機(jī)會(huì)能讀到N多快照。但那么多快照版本,事務(wù)具體會(huì)讀哪個(gè)快照呢?
事務(wù)會(huì)從表頭開(kāi)始遍歷這個(gè)undo日志版本鏈,它會(huì)拿每個(gè)undo日志里的trx_id去跟自己的read view的上下邊界去做判斷。第一個(gè)出現(xiàn)的小于max_trx_id的快照。
- 如果快照是自己產(chǎn)生,那提不提交都行,就決定是讀它了。
- 如果快照是別人產(chǎn)生的,且已經(jīng)提交完成了,那也行,決定讀它了。
比如下圖,undo日志1正好小于max_trx_id,且事務(wù)已經(jīng)提交,那么就讀它了。
readview與undo版本鏈
MVCC是什么
像上面這種,維護(hù)一個(gè)多快照的undo日志版本鏈,事務(wù)根據(jù)自己的read view去決定具體讀那個(gè)undo日志快照,最理想的情況下是每個(gè)事務(wù)都讀自己的一份快照,然后在這個(gè)快照上做自己的邏輯,只有在寫數(shù)據(jù)的時(shí)候,才去操作最新的行數(shù)據(jù),這樣讀和寫就被分開(kāi)了,比起單行數(shù)據(jù)沒(méi)有快照的方式,它能更好的解決讀寫沖突,所以數(shù)據(jù)庫(kù)并發(fā)性能也更好。其實(shí)這就是面試?yán)锍?wèn)的MVCC,全稱Multi-Version Concurrency Control,即多版本并發(fā)控制。

MVCC
四個(gè)隔離級(jí)別是怎么實(shí)現(xiàn)的
之前的寫的一篇文章最后留了個(gè)問(wèn)題,四個(gè)隔離級(jí)別是怎么實(shí)現(xiàn)的。
知道了undo日志版本鏈和MVCC之后,我們?cè)倩剡^(guò)頭來(lái)看下這個(gè)問(wèn)題。
 四層隔離級(jí)別
四層隔離級(jí)別
讀未提交,每次讀到的都是最新的數(shù)據(jù),也不管數(shù)據(jù)行所在的事務(wù)是否提交。實(shí)現(xiàn)也很簡(jiǎn)單,只需要每次都讀undo日志版本鏈的鏈表頭(最新的快照)就行了。
與讀未提交不同,讀提交和可重復(fù)讀隔離級(jí)別都是基于MVCC的read view實(shí)現(xiàn)的,反過(guò)來(lái)說(shuō), MVCC也只會(huì)出現(xiàn)在這兩個(gè)隔離級(jí)別里。
讀已提交隔離級(jí)別,每次執(zhí)行普通select,都會(huì)重新生成一個(gè)新的read view,然后拿著這個(gè)最新的read view到某行數(shù)據(jù)的版本鏈上挨個(gè)遍歷,找到第一個(gè)合適的數(shù)據(jù)。這樣就能做到每次都讀到其他事務(wù)最新已提交的數(shù)據(jù)。
可重復(fù)讀隔離級(jí)別下的事務(wù)只會(huì)在第一次執(zhí)行普通select時(shí)生成read view,后續(xù)不管執(zhí)行幾次普通select,都會(huì)復(fù)用這個(gè) read view。這樣就能保持每次讀的時(shí)候都是在同一標(biāo)準(zhǔn)下進(jìn)行讀取,那讀到的數(shù)據(jù)也會(huì)是一樣的。
串行化目的就是讓并發(fā)事務(wù)看起來(lái)就像單線程執(zhí)行一樣,那實(shí)現(xiàn)也很簡(jiǎn)單,和讀未提交隔離級(jí)別一樣,串行化隔離界別下事務(wù)只讀undo日志鏈的鏈表頭,也就是最新版本的快照,并且就算是普通select,也會(huì)在版本鏈的最新快照上加入讀鎖。這樣其他事務(wù)想寫,也得等這個(gè)讀鎖釋放掉才行。所有對(duì)這行數(shù)據(jù)進(jìn)行操作的事務(wù),都老老實(shí)實(shí)地阻塞等待加鎖,一個(gè)接一個(gè)進(jìn)行處理,從效果上看就跟單線程處理一樣。
再看文章開(kāi)頭的例子
我們用上面提到的概念,重新回到文章開(kāi)頭的例子,梳理一遍。
user表數(shù)據(jù)庫(kù)原始狀態(tài)
我們假設(shè)數(shù)據(jù)庫(kù)一開(kāi)始的三條數(shù)據(jù),都是由trx_id=1的事務(wù)insert生成的。
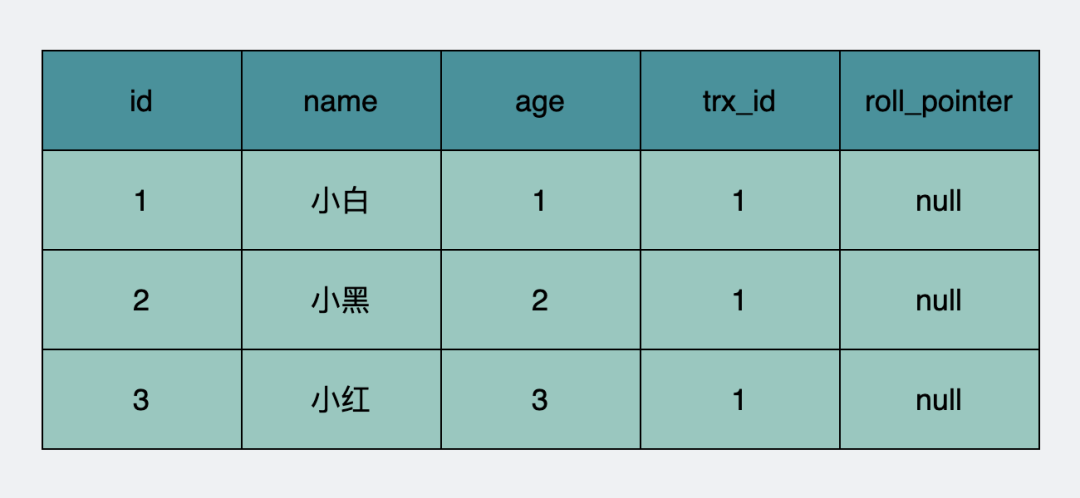
于是數(shù)據(jù)表一開(kāi)始長(zhǎng)下面這樣。每行數(shù)據(jù)只有一個(gè)快照。注意快照里,trx_id填的是創(chuàng)建它們的事務(wù)id,也就是剛剛提到的事務(wù)1。roll_pointer原本應(yīng)該指向insert產(chǎn)生的undo日志,為了簡(jiǎn)化,這里寫為null(insert undo日志在事務(wù)提交后可以被清理掉)。
user表數(shù)據(jù)庫(kù)原始trx信息
下面這個(gè)圖,還是文章開(kāi)頭的圖,這里放出來(lái)是為了方便大家,不用劃回去看了。
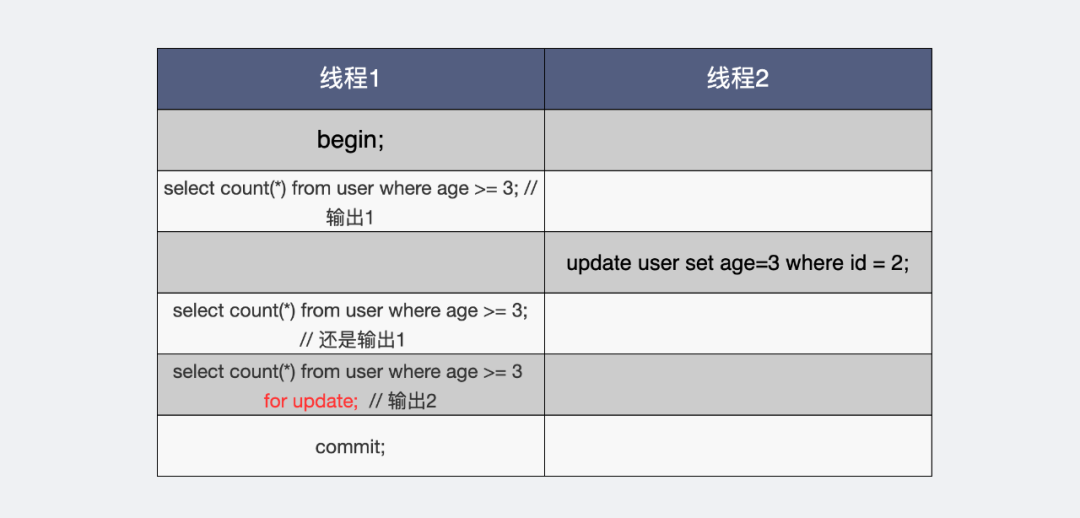
都是select結(jié)果卻不同
在線程1啟動(dòng)事務(wù),我們假設(shè)它的事務(wù)trx_id=2,第一次執(zhí)行普通select,是快照讀,在可重復(fù)讀隔離級(jí)別,會(huì)生成一個(gè)read view。當(dāng)前這個(gè)數(shù)據(jù)庫(kù),活躍事務(wù)只有它一個(gè),那m_ids =[2]。m_ids里最小的id,也就是min_trx_id=2。max_trx_id是當(dāng)前最大數(shù)據(jù)庫(kù)事務(wù)id(只有它自己,所以也是2),加個(gè)1,也就是max_trx_id=3。
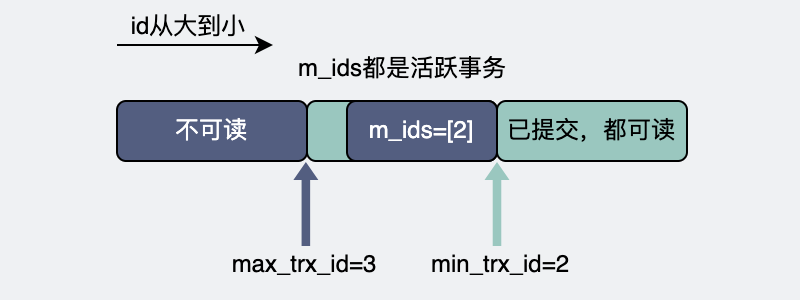
 事務(wù)1的readview
事務(wù)1的readview
此時(shí)線程1的事務(wù),拿著這個(gè)read view去讀數(shù)據(jù)庫(kù)表。
因?yàn)檫@三條數(shù)據(jù)的trx_id=1都小于min_trx_id=2,都屬于可見(jiàn)范圍,因此能讀到這三條數(shù)據(jù)的所有快照,最后返回符合條件(age>=3)的數(shù)據(jù),有1條。
這時(shí)候事務(wù)2,假設(shè)它的事務(wù)trx_id=3,執(zhí)行更新操作,生成新的undo日志快照。
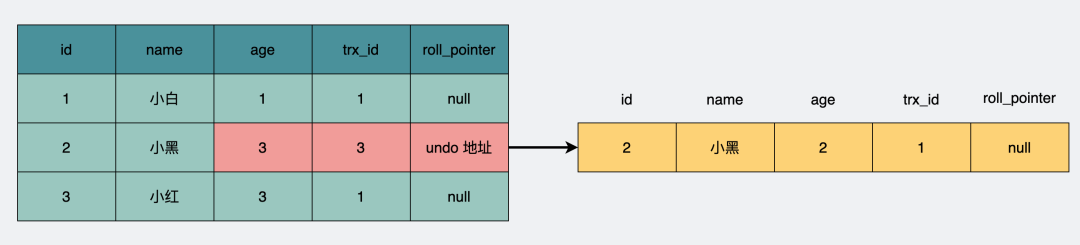
 user表數(shù)據(jù)庫(kù)加入undo日志
user表數(shù)據(jù)庫(kù)加入undo日志
此時(shí)線程1第二次執(zhí)行普通select,還是快照讀,由于是可重復(fù)讀,會(huì)復(fù)用之前的read view,再執(zhí)行一次讀操作,這里重點(diǎn)關(guān)注id=2的那行數(shù)據(jù),從版本鏈表頭開(kāi)始遍歷,第一個(gè)快照trx_id=3 >= read view的max_trx_id=3,因此不可讀,遍歷下一個(gè)快照trx_id=1 < min_trx_id=2,可讀。于是id=2的那行數(shù)據(jù),還是拿到age=2,而不是更新后的age=3,因此快照讀結(jié)果還是只有1條數(shù)據(jù)符合age>=3。
但是線程1第三次讀,執(zhí)行select for update,就成了當(dāng)前讀了,直接讀undo日志版本鏈里最新的那行快照,于是能讀到id=2,age=3,所以最終結(jié)果返回符合age>=3的數(shù)據(jù)有2條。
總的來(lái)說(shuō)就是,由于快照讀和當(dāng)前讀,讀數(shù)據(jù)的規(guī)則不同,我們看到了不一樣的結(jié)果。
看到這里,大家應(yīng)該理解了,所謂的可重復(fù)讀每次讀都要讀到一樣的數(shù)據(jù),這里頭的"讀",指的是快照讀。
如果下次面試官問(wèn)你,可重復(fù)讀隔離級(jí)別下每次讀到的數(shù)據(jù)都是一樣的嗎?
你該知道怎么回答了吧?
總結(jié)
- 事務(wù)通過(guò)undo日志實(shí)現(xiàn)回滾的功能,從而實(shí)現(xiàn)事務(wù)的原子性(Atomicity)。
- 多個(gè)事務(wù)生成的undo日志構(gòu)成一條版本鏈。快照讀時(shí)事務(wù)根據(jù)read view來(lái)決定具體讀哪個(gè)快照。當(dāng)前讀時(shí)事務(wù)直接讀最新的快照版本。
- mysql的innodb引擎通過(guò)MVCC提升了讀寫并發(fā)。