Kafka多種跨IDC災備方案調研對比
1.前言
為了盡量減少自然和人為災難(如停電、災難性軟件故障和網絡中斷)對業務的影響,以及隨著我行基于Kafka的實時業務不斷增長,Kafka的重要性日益增長,在我行逐步優化跨IDC的Kafka連續性建設已經成為我們目前亟待解決的問題。
本文就目前已有的災備方案在元數據同步、數據復制、消費位移同步、災備模式等方面進行調研對比。
2.現有災備方案
方案 | 描述 | 使用方 |
MirrorMaker1(簡稱MM1) | 原理是啟動消費者從源集群進行消費,然后發送到目標集群,功能較簡單 | |
MirrorMaker2(簡稱MM2)或 基于MM2的改進 | 基于Kafka Connect框架實現,由LinkedIn工程師貢獻,修復MM1的局限性,Topic和分區可自動感知,acl和配置可自動同步,支持雙活,提供offset轉換功能 | 360 |
Confluent Replicator | Confluent收費版,與MM2相比,雙活模式更優雅,可支持單條消息的修改 | Confluent |
基于Follower的同步機制 | 利用Kafka的副本同步機制創建Fetcher線程同步數據,需要在原生Kafka上進行二次開發 | 字節、滴滴 |
uReplicator | 改進MM1,利用分布式的任務管理框架Apache Helix控制Partition的分配,不需要全部rebalance | Uber |
brooklin | 改進MM1,實現思路和MM2類似,與uReplicator一樣,為了減少rebalance,采用Sticky Assignment控制Partition的分配,除了支持Kafka集群間的復制,還能作為Azure Event Hubs,AWS Kinesis流式服務之間的通道,另外還能作為CDC連接器 |
3.各方案的主要設計點對比分析
3.1 元數據同步
元數據同步主要是指Topic、Partition、Configuration、ACL的同步,我們需要評估各方案在新增Topic,分區擴容后、修改Configuration和ACL后能否自動感知,以及評估方案中選擇復制的Topic是否靈活(比如是否支持白名單、黑名單機制,是否支持正則),目標集群中Topic名稱是否發生改變(決定是否支持雙向復制,是否會發生循環復制)。
MM1方案中,選擇復制的Topic只支持白名單機制(--whitelist或者--include參數指定),且白名單支持正則寫法,但是當源集群新增Topic后,目標集群的auto.create.topics.enable設置為true時,才能自動在目標集群創建相同名稱的Topic(可以擴展messagehandler改名),否則必須重啟MirrorMaker才能發現新增的Topic,關于目標集群上的Topic的分區數,MM1是按默認值num.partitions進行配置(其他方案均無該問題),無法和源集群上保持一致,ACL也無法同步。
相比MM1,MM2彌補了上述不足,主要是依賴MirrorSourceConnector里的多個定時任務實現該功能,更新Topic/Partition、Configuration、ACL的間隔時長分別由三個參數指定,非常靈活。在MM2中,目前截至3.0.0的版本,支持兩種復制策略,默認的DefaultReplicationPolicy中目標集群中復制后Topic名稱發生變化,前面會加一個源集群的前綴,為了兼容MM1,3.0.0中新增的IdentityReplicationPolicy中目標集群中復制后Topic名稱不會發生變化。
Confluent Replicator,根據官網描述,也同樣具備上述功能,原理和MM2類似,只是檢測更新只由一個參數確定。Replicator可以定義復制后Topic的名稱,由參數topic.rename.format指定,默認值是保持Topic名稱不變。
基于Follower的同步機制的方案,由于網上資料不足,具體實現無法得知,但是原理估計和MM2類似,復制后在目標集群中Topic名稱保持不變。
uReplicator的實現略有不同,復制哪些Topic,由參數enableAutoWhitelist和patternToExcludeTopics一起決定,當enableAutoWhitelist設置為true時,若源集群和目標集群中存在相同Topic,那么不需要其他設置即可實現數據復制,若設置為false,需要將復制的Topic名稱等信息提交給uReplicator Controller,由該Controller來控制分區的分配,另外黑名單參數patternToExcludeTopics控制哪些Topic不用復制;分區擴容是否自動感知,是由參數enableAutoTopicExpansion控制的;關于Configuration和ACL無法實現同步。
brooklin選擇復制的Topic只支持白名單機制,可支持正則,新增Topic和分區擴容后可自動感知,檢測更新由參數partitionFetchIntervalMs確定,復制后Topic名稱前可加前綴,由參數DESTINATION_TOPIC_PFEFIX確定。
總結如下:
方案 | MM1 | MM2 | Confluent Replicator | 基于Follower的同步機制 | uReplicator | brooklin |
復制后Topic名稱變化 | 不變,也可自定義 | 可保持不變,也可以增加固定前綴 | 可保持不變,也可以自定義 | 不變 | 不變 | 可保持不變,也可定義前綴 |
自動檢測和復制新Topic | 部分支持(取決于目標集群的自動創建topic是否開啟) | 支持 | 支持 | 取決于二次開發的功能 | 不支持 | 支持 |
自動檢測和復制新分區 | 不支持 | 支持 | 支持 | 取決于二次開發的功能 | 支持 | 支持 |
源集群和目標集群總Topic配置一致 | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
配置和ACL更新是否同步 | 不支持 | 支持 | 支持 | 取決于二次開發的功能 | 不支持 | 不支持 |
選擇復制Topic的靈活度:是否具有白名單、黑名單和正則表達式的主題 | 部分支持 | 支持 | 支持 | 取決于二次開發的功能 | 部分支持 | 部分支持 |
3.2 數據復制
數據復制是災備方案的最核心點之一,我們需要評估各方案中復制后消息offset能否對齊,復制期間數據的一致性能否保證即是否會丟失數據或者會出現重復數據。首先說明一下,由于復制會有延遲,因此所有這些災備方案里RPO都不等于0。
基于Follower的同步機制的方案可以保持offset對齊,由于副本同步存在延遲,當主機房異常時,備機房上仍有丟失部分數據的可能性,offset可保持一致,不會出現重復數據的可能性。其他方案均不能保證offset對齊(除非是復制時源Topic的offset從0開始),關于每個方案中消費者從源集群消費,再寫入到目標集群的邏輯,我們一一詳細解釋下:
先從MM1開始,這是他的設計架構:
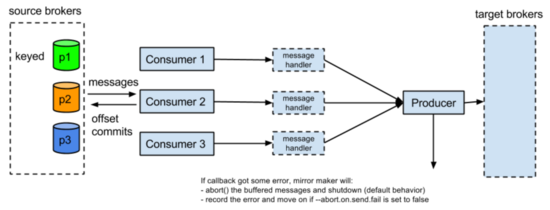
在KIP-3 MirrorMaker Enhancement里,設計了上述架構,從以下幾處保證不丟數:
1.關掉消費者的自動提交位移,提交位移之前會調用producer.flush()刷出緩存里數據
2.在producer端,通過設置這幾個參數max.in.flight.requests.per.connection=1(多個consumer共享一個producer,這個producer每次只給broker發一個request),retries=Int.MaxValue(返回是可重試異常,無限次重試直到緩沖區滿),ack=-1(發給所有副本)
3.設置abortOnSendFail,當producer端收到不可重試異常后(比如消息過大之類的異常),停止MirrorMaker進程,否則會丟失發送失敗的部分數據
另外為了避免在consumer發生rebalance的是時候出現重復數據(rebalance時候有些數據位移沒提交),定義了一個新的consumerRebalance監聽器,在發生partitionRevoke的時候,先刷出producer緩存里數據,再提交位移。
從上面設計來看,MM1是不丟數,但是還是存在數據重復的可能性,這是Kafka的非冪等Producer決定的,另外MM1的設計還有很多缺陷,比如只有一個Producer,發送效率低,另外這個Producer是輪詢發送,消息發送到目的Topic上的分區和源Topic的分區不一定一致,由于是輪詢,這個Producer和集群里每個broker會建立連接。對比uReplicator,同樣也是在flush之后再提交位移去避免丟數,在MM1的缺陷都得到了改進,每個WorkerInstance里有多個FetcherThread和多個ProducerThread,從源集群fetch數據后會放到一個隊列里,ProducerThread從隊列里取走數據并發到目標集群的Topic,每條消息發送到目的Topic上分區和源分區保持一致,可以保持語義上一致。
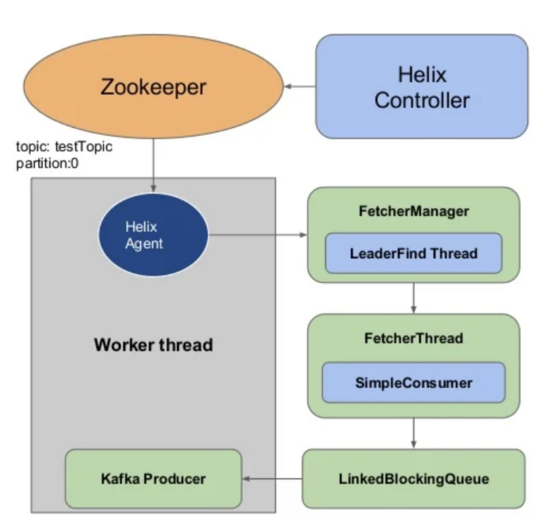
在brooklin中,每個Brooklin Instance中可以起多個Consumer和Producer,也可保持語義上一致,比uReplicator更有優勢的一處就是提供了flushless的生產者(也可提供flush的Producer),哪些消息發送成功,才會提交這些位移,因為調用Producer.flush()可以將緩沖區的數據強制發送,但是代價較高,在清空緩沖前會堵塞發送線程。
consumer.poll()->producer.send(records)->producer.flush()->consumer.commit()
優化為:
consumer.poll()->producer.send(records)->consumer.commit(offsets)
在MirrorMaker2中,采用Kafka Connect框架進行復制數據,從源端消費數據后,存到一個類型為IdentityHashMap的內存結構outstandingMessages中,Producer發送到目的端成功后,會從該內存結構中刪除該消息,另外會定時將從源端消費的進度保存到Kafka Topic中。這種實現機制不會丟失數據,但是Producer發送成功后,未將進度持久化前進程異常掛掉,那么會產生重復消息。目前在KIP-656: MirrorMaker2 Exactly-once Semantics提出了一種可實現Exactly Only Once的方案,思路是將提交消費位移和發送消息放在一個事務里,但是相關Patch KAFKA-10339仍然沒被合進主分支,最后更新停留在20年8月份。
根據Confluent Replicator官網描述,復制不會丟數,但是可能會重復,因此和上述MM2、uReplicator、brooklin一樣,提供的都是At least Once Delivery消息傳遞語義。
方案 | MM1 | MM2 | Confluent Replicator | 基于Follower的同步機制 | uReplicator | brooklin |
復制前后分區語義一致 | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
offset對齊 | 不能 | 不支持 | 不支持 | 支持 | 不支持 | 不支持 |
消息傳遞語義 | 不丟數,可能重復 At least Once | 不丟數,可能重復 At least Once, 未來會提供EOS語義 | 不丟數,可能重復 At least Once | 取決于二次開發的功能, 從Kafka副本同步的原理看, 在參數設置合理的情況下,在副本之間同步過程中數據可保持一致 | 不丟數,可能重復 At least Once | 不丟數,可能重復 At least Once |
3.3 消費位移同步
災備方案中除數據復制,消費位移的同步也非常關鍵,災備切換后消費者是否能在新的集群中恢復消費,取決于consumer offset是否能同步。
在MM1設計中,若要同步消費位移,只能將__consumer_offsets作為一個普通的Topic進行同步,但是由于源集群和目標集群的offset可能存在不對齊的情況,因此無法進行offset轉換。
在MM2設計中,解決了上述MM1問題,設計思路是會定期在目標集群的checkpoint Topic中記錄消費位移,包括源端和目標端的已提交位移,消息包括如下字段:
- consumer group id (String) 消費組
- topic (String) – includes source cluster prefix topic名稱
- partition (int) 分區名稱
- upstream offset (int): latest committed offset in source cluster 源集群的消費位移
- downstream offset (int): latest committed offset translated to target cluster 目標集群的消費位移
- metadata (String) partition元數據
- timestamp
另外,還設計了一個offset sync Topic用于記錄源端和目的端offset的映射。
同時,MM2還提供了MirrorClient接口做位移轉換:
// Find the local offsets corresponding to the latest checkpoint from a specific upstream consumer group.
Map<TopicPartition, OffsetAndMetadata> remoteConsumerOffsets(String consumerGroupId,
``String remoteClusterAlias, Duration timeout)
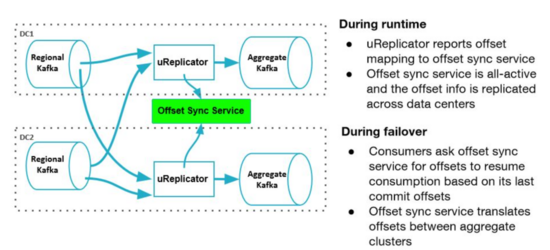
在uReplicator中,另外設計了一個offset Sync的服務,跟MM2類似(可能是MM2參考了uReplicator的設計),這個服務可以實時收集不同集群offset 的映射關系,計算出從一個DC切換到另一個DC后需要從哪個 offset 進行讀取。
在brooklin中,沒有類似uReplicator里的offset Sync服務,需要自己實現。
在Confluent Replicator中,用另外一種思路解決該問題,不同DC的時間是一致的,在Kafka的消息里包含時間戳,5.0 版引入了一項新功能,該功能使用時間戳自動轉換偏移量,以便消費者可以故障轉移到不同的數據中心并開始在目標集群中消費他們在源集群中中斷的數據。要使用此功能,需要在Consumer中設置Consumer Timestamps Interceptor 的攔截器,該攔截器保留消費消息的元數據,包括:
? Consumer group ID
? Topic name
? Partition
? Committed offset
? Timestamp
此消費者時間戳信息保存在位于源集群中名為 __consumer_timestamps 的 Kafka Topic中。然后Replicator通過以下步驟進行offset轉換:
- 從源集群中的 consumer_timestamps 主題中讀取消費者偏移量和時間戳信息,以獲取消費者組的進度
- 將源數據中心中的已提交偏移量轉換為目標數據中心中的相應偏移量
- 將轉換后的偏移量寫入目標集群中的 __consumer_offsets 主題
那么消費者切換到目標中心的集群后,可繼續進行消費。
基于Follower的同步機制方案,Topic完全一致,只要將__consumer_offsets也同步,那么消費者故障轉移后仍可繼續消費。
在消費位移同步方面,各方案總結如下:
方案 | MM1 | MM2 | Confluent Replicator | 基于Follower的同步機制 | uReplicator | brooklin |
復制消費位移 | 部分支持 | 支持 | 支持 | 支持 | 部分支持 | 部分支持 |
offset轉換 | 不支持 | 支持 | 支持 | 不需要 | 支持 | 不支持 |
客戶端切換 | 客戶端自定義 seek offset | 通過接口獲取目標集群 的offset,再seek | 不需要做額外轉換, 啟動即可 | 不需要做額外轉換, 啟動即可 | 通過sync topic服務 查看目標集群的offset,再seek | 客戶端自定義 seek offset |
3.4 是否支持雙活
為了提升資源利用率,災備模式的選取也是一個重要考量點。
MM1是不支持雙活模式的,兩個集群無法配置為相互復制(“Active/Active”),主要是因為如果在兩個集群中若存在相同名稱的Topic,無法解決Topic循環復制的問題。
MM1這個可能循環復制的問題在MM2中解決,解決思路是復制后的Topic與原Topic名稱不一致,會加上源集群的名稱作為前綴,例如如下示例中,A集群中的topic1在復制到B集群后,名稱變更為A.topic1。
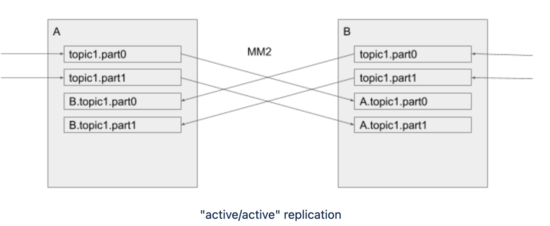
但是MM2默認的DefaultReplicationPolicy是復制后Topic名稱改變,對客戶端來說會增加切換代價,可以考慮改成IdentityReplicationPolicy,這種復制策略只能支持單向復制,主集群提供業務服務,即Active/Standy模式。
在Confluent Replicator 5.0.1中,為了避免循環復制,利用了KIP-82 Add Record Headers的特性,在消息的header里加入了消息來源,如果目標集群的集群 ID 與header里的源集群 ID 匹配,并且目標Topic名稱與header的Topic名稱匹配,則 Replicator 不會將消息復制到目標集群。如下圖所示:
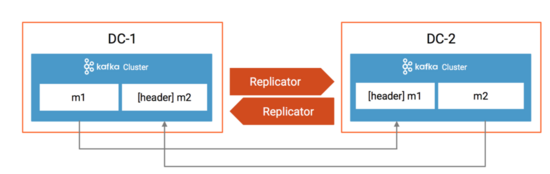
DC-1的m1復制后DC-2,消息的header里加入了標記,這條消息是從DC-1復制過來的,那么Replicator不會把DC-2的m1再復制到DC-1,同理,DC-1的m2也不會復制到DC-2。因此Confluent Replicator是可以支持Active/Active模式的。
在uReplicator中,通過數據的冗余提供Region級別的故障轉移,在這種設計中,每個區域除部署一套本地Kafka集群,還會部署一套聚合集群,這套聚合集群里存儲了所有區域的數據。
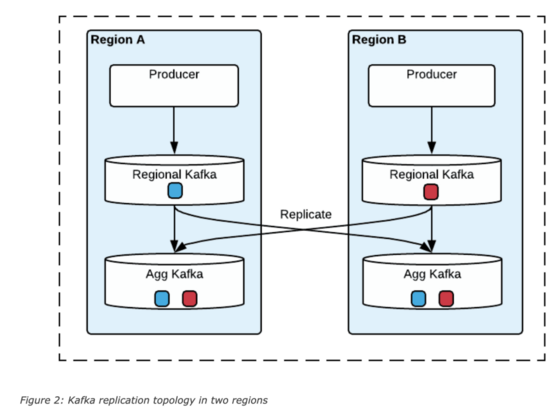
當區域集群A和B中存在相同Topic,那么匯聚后,在區域A和B中的消息offset可能不一致,uReplicator設計了一個offset管理服務,會記錄這個對應關系,示例如下:
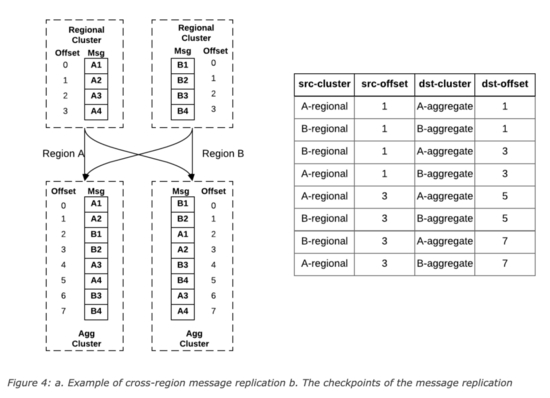
這種設計中,可以支持消費者的Active/Active和Active/Standy模式,前者是每個區域起一個消費者消費聚合集群的的數據,只有一個區域是主區域,只有主區域的數據可以更新數據到后端數據庫中,當主區域故障后,指定新的主區域,新的主區域繼續消費計算,在Active/Standy模式中,所有區域中只有一個消費者,該區域故障后,在其他區域啟動一個消費者,根據offset管理服務里記錄的offset對應關系,從每個區域的區域集群中找到所有最新的checkpoints,然后根據該checkpoints在Standy區域的聚合集群查找最小offset,從Standy區域的該offset開始消費。
在brooklin中,也可以通過類似uReplicator的設計利用數據的冗余實現Active/Active災備模式。
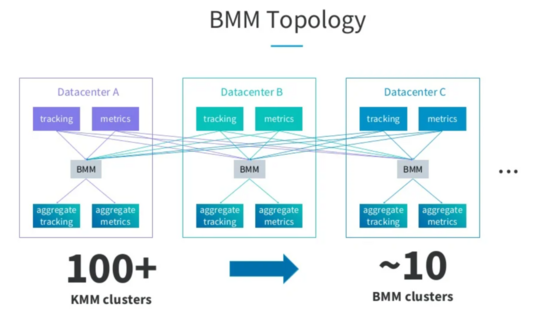
在字節介紹的災備方案中,Producer只能往主集群寫(主備集群中的信息是存儲在配置中心里的,客戶端需要先從配置中心查詢),Producer可以在雙中心部署,但是通過配置中心路由到主集群,Consumer也可在雙中心部署,若采用Active/Standy模式,各自消費本地機房的數據,但是只有主集群里消費者的消費位移可以生效,在采用Active/Active模式下,消費者只能從主集群進行消費,這兩種模式下,都是將雙中心所有消費者的消費位移采用一個存儲統一存儲。
在災備模式方面,各方案總結如下:
方案 | MM1 | MM2 | Confluent Replicator | 基于Follower的同步機制 | uReplicator | brooklin |
雙集群是否可互相復制 | 不支持 | 支持 | 支持 | 不支持 | 支持,依靠聚合集群 | 支持,依靠聚合集群 |
Producer Active/Active | 不支持 | 支持 | 支持 | 支持,但是其實只寫入主集群 | 支持 | 支持 |
Consumer Active/Standy | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
Consumer Active/Active | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
4.各方案的主要設計點總結
總結來說,這些方案里歸結為三類:
1.Kafka社區的設計路線方案,從源集群消費,再寫入到目標集群,包含MM1,MM2,uReplicator,brooklin這幾種方案,MM2是參考了uReplicator的設計,實現方案和brooklin類似,那么在這四種方案中,MM2可以作為優先考慮方案。
2.Confluent Replicator的商業收費方案,也是利用Kafka Connect框架進行消費寫入,在避免Topic循環復制和消費位移轉換方面做得非常出色,客戶端切換的代價很低。
3.以字節、滴滴為代表的基于Follower同步機制的方案,這種方案里復制后的Topic是源Topic的鏡像,客戶端不需要做offset轉換,需要改造Kafka代碼,考慮到后續和原生Kafka代碼的版本融合,技術要求較高。
目前來說,沒有一個完美的解決方案,各公司可根據自身實際需求制定。