Pandas中常用的七個時間戳處理函數(shù)
Python 程序允許我們使用 NumPy timedelta64 和 datetime64 來操作和檢索時間序列數(shù)據(jù)。 sklern庫中也提供時間序列功能,但 Pandas 為我們提供了更多且好用的函數(shù)。

Pandas 庫中有四個與時間相關(guān)的概念
- 日期時間:日期時間表示特定日期和時間及其各自的時區(qū)。 它在 pandas 中的數(shù)據(jù)類型是 datetime64[ns] 或 datetime64[ns, tz]。
- 時間增量:時間增量表示時間差異,它們可以是不同的單位。 示例:“天、小時、減號”等。換句話說,它們是日期時間的子類。
- 時間跨度:時間跨度被稱為固定周期內(nèi)的相關(guān)頻率。 時間跨度的數(shù)據(jù)類型是 period[freq]。
- 日期偏移:日期偏移有助于從當(dāng)?前日期計算選定日期,日期偏移量在 pandas 中沒有特定的數(shù)據(jù)類型。
時間序列分析至關(guān)重要,因為它們可以幫助我們了解隨著時間的推移影響趨勢或系統(tǒng)模式的因素。 在數(shù)據(jù)可視化的幫助下,分析并做出后續(xù)決策。
現(xiàn)在讓我們看幾個使用這些函數(shù)的例子
1、查找特定日期的某一天的名稱
import pandas as pd
day = pd.Timestamp(‘2021/1/5’)
day.day_name()
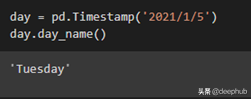
上面的程序是顯示特定日期的名稱。 第一步是導(dǎo)入 panda 的并使用 Timestamp 和 day_name 函數(shù)。 “Timestamp”功能用于輸入日期,“day_name”功能用于顯示指定日期的名稱。
2、執(zhí)行算術(shù)計算
import pandas as pd
day = pd.Timestamp(‘2021/1/5’)
day1 = day + pd.Timedelta(“3 day”)
day1.day_name()
day2 = day1 + pd.offsets.BDay()
day2.day_name()
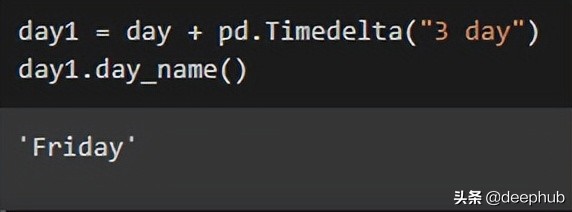
在第一個代碼中,顯示三天后日期名稱。“Timedelta”功能允許輸入任何天單位(天、小時、分鐘、秒)的時差。
在第二個代碼中,使用“offsets.BDay()”函數(shù)來顯示下一個工作日。 換句話說,這意味著在星期五之后,下一個工作日是星期一。
3、使用時區(qū)信息來操作轉(zhuǎn)換日期時間
獲取時區(qū)的信息
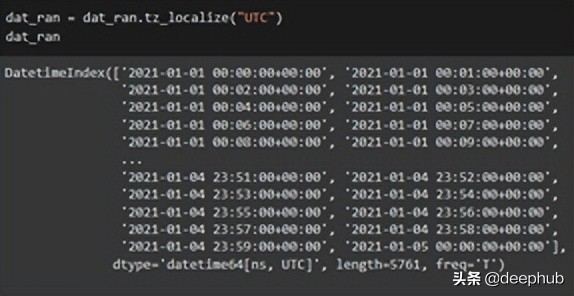
import pandas as pd
import numpy as np
from datetime import datetime
dat_ran = dat_ran.tz_localize(“UTC”)
dat_ran
轉(zhuǎn)換為美國時區(qū)
dat_ran.tz_convert(“US/Pacific”)
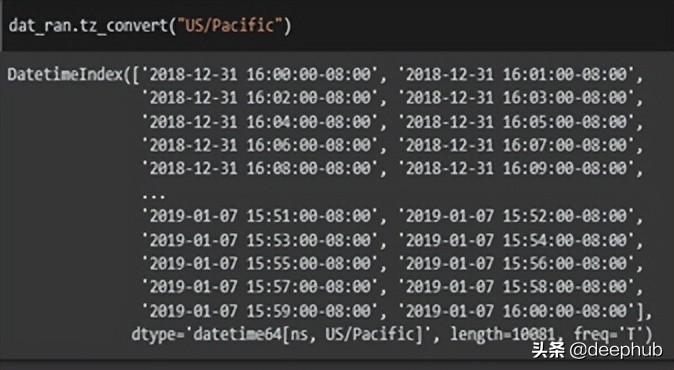
代碼的目標(biāo)是更改日期的時區(qū)。 首先需要找到當(dāng)前時區(qū)。 這是“tz_localize()”函數(shù)完成的。 我們現(xiàn)在知道當(dāng)前時區(qū)是“UTC”。使用“tz_convert()”函數(shù),轉(zhuǎn)換為美國/太平洋時區(qū)。
4、使用日期時間戳
import pandas as pd
import numpy as np
from datetime import datetime
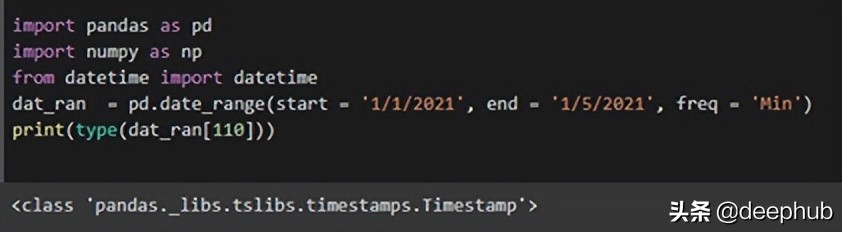
dat_ran = pd.date_range(start = ‘1/1/2021’, end = ‘1/5/2021’, freq = ‘Min’)
print(type(dat_ran[110]))
5、創(chuàng)建日期系列
import pandas as pd
import numpy as np
from datetime import datetime
dat_ran = pd.date_range(start = ‘1/1/2021’, end = ‘1/5/2021’, freq = ‘Min’)
print(dat_ran)
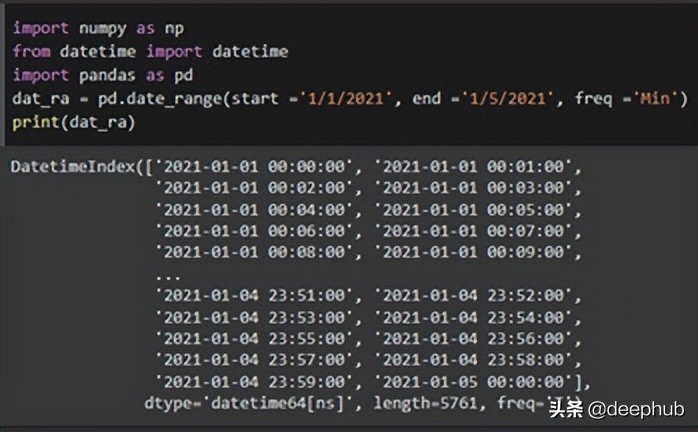
上面的代碼生成了一個日期系列的范圍。使用“date_range”函數(shù),輸入開始和結(jié)束日期,可以獲得該范圍內(nèi)的日期。
6、操作日期序列
import pandas as pd
from datetime import datetime
import numpy as np
dat_ran = pd.date_range(start =’1/1/2019', end =’1/08/2019',freq =’Min’)
df = pd.DataFrame(dat_ran, columns =[‘date’])
df[‘data’] = np.random.randint(0, 100, size =(len(dat_ran)))
print(df.head(5))
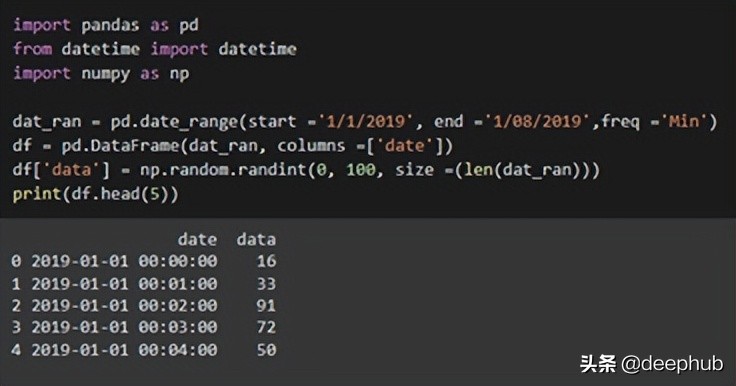
在上面的代碼中,使用“DataFrame”函數(shù)將字符串類型轉(zhuǎn)換為dataframe。 最后“np.random.randint()”函數(shù)是隨機生成一些假定的數(shù)據(jù)。
7、使用時間戳數(shù)據(jù)對數(shù)據(jù)進(jìn)行切片
import pandas as pd
from datetime import datetime
import numpy as np
dat_ran = pd.date_range(start =’1/1/2019', end =’1/08/2019', freq =’Min’)
df = pd.DataFrame(dat_ran, columns =[‘date’])
df[‘data’] = np.random.randint(0, 100, size =(len(dat_ran)))
string_data = [str(x) for x in dat_ran]
print(string_data[1:5])
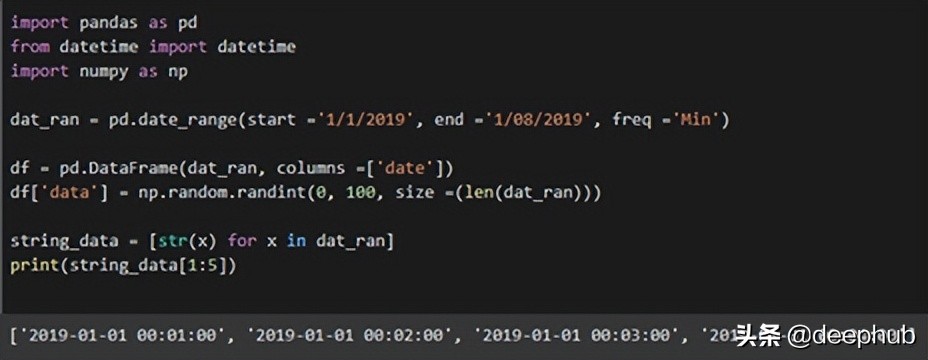
上面代碼是是第6條的的延續(xù)。 在創(chuàng)建dataframe并將其映射到隨機數(shù)后,對列表進(jìn)行切片。
最后總結(jié),本文通過示例演示了時間序列和日期函數(shù)的所有基礎(chǔ)知識。 建議參考本文中的內(nèi)容并嘗試pandas中的其他日期函數(shù)進(jìn)行更深入的學(xué)習(xí),因為這些函數(shù)在我們實際工作中非常的重要。