基于MVCC,我用C++自己手擼了個MySQL!
沒錯,真如標題所示,我基于MVCC算法(這里我姑且叫它算法吧,畢竟在實際寫代碼時,確實是利用算法實現(xiàn)的),使用C++寫了個簡易版的MySQL,實現(xiàn)了簡易版的CRUD操作。
其實,今天我并不打算先向小伙伴們演示我寫的簡易版MySQL,這個項目待我再優(yōu)化下,會開源出來的,到時大家可以一起學習,一起進步,一起來維護它。
今天,我想跟大家重點聊聊MVCC,網(wǎng)上關于MVCC的文章很多,大部分都是基于版本鏈進行介紹的,其實對于初學者來說,使用版本鏈介紹MVCC其實還是挺難理解的。今天,我就來跟大家聊聊我是如何理解MVCC的,MVCC其實很簡單,不用版本鏈你也可以徹底理解透徹。
MVCC技術
MVCC是一種通過記錄數(shù)據(jù)的歷史版本來提升事務并發(fā)處理能力的一項技術,它能夠極大的提升在并發(fā)事務下數(shù)據(jù)的處理性能,目前,大部分關系型數(shù)據(jù)庫都實現(xiàn)了MVCC機制。
MVCC主要解決多事務并發(fā)控制問題,也就是保證事務的隔離性。
MVCC的存儲方式
MVCC大體上可以分為三種存儲方式,分別為Append-Only方式、Delta方式和Time-Travle方式,如下所示。
(1)Append-Only方式:將數(shù)據(jù)的歷史版本直接存儲在數(shù)據(jù)表中,代表數(shù)據(jù)庫為PostgreSQL。
(2)Delta方式:將數(shù)據(jù)的增量歷史版本存儲在獨立的表空間,代表數(shù)據(jù)庫為MySQL和Oracle。
(3)Time-Travle方式:將數(shù)據(jù)的每個版本都全量存儲下來,代表數(shù)據(jù)庫為HANA。
MVCC的工作原理
MVCC主要用來保證事務的隔離性,這里,我們就分別以讀已提交和可重復讀兩種隔離級別為例,來聊聊MVCC是如何工作的。
讀已提交MVCC的工作原理
在讀已提交隔離級別下,當前事務只能看到兩類數(shù)據(jù),如下所示。
(1)當前事務自身產(chǎn)生的數(shù)據(jù)。
(2)當前事務開啟之前,其他已經(jīng)提交的事務所產(chǎn)生的數(shù)據(jù)。
為了便于小伙伴們理解,這里我畫了一張簡易的事務執(zhí)行圖,如下所示。
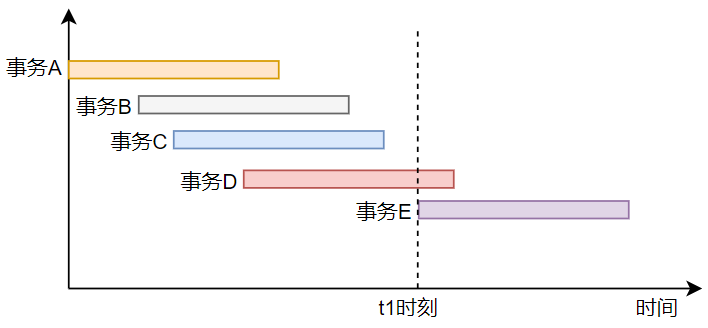
事務A到事務E是在數(shù)據(jù)庫中執(zhí)行的五個事務,它們按照先后順序執(zhí)行,分別操作的是數(shù)據(jù)表中data1~data5的五條記錄。在t1時刻,啟動事務E,事務E要讀取事務A到事務D的這四條記錄,在t1時刻,事務E啟動時,會向系統(tǒng)申請一個活動事務列表,所謂的活動事務,就是已經(jīng)啟動但是并未提交或者回滾的事務。
所以,在申請的活動事務列表中會看到事務D,當事務E查詢到data4這條數(shù)據(jù)記錄時,其對應的事務D正好在活動事務列表中,事務E就會讀取data4的上一個版本。
而事務A、事務B和事務C在事務E啟動時已經(jīng)提交,并且最新版本的事務id小于活動事務D對應的事務id,所以事務E能夠看到事務A、事務B和事務C對應的data1、data2和data3記錄的最新版本。
可重復讀MVCC的工作原理
在重復讀隔離級別下,MVCC又是如何工作的呢?先來看張圖。
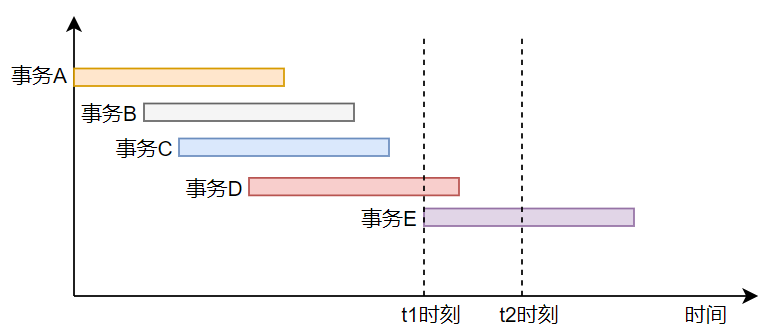
如果在讀已提交隔離級別下,則在t1時刻,事務E啟動時,事務A、事務B和事務C已經(jīng)提交,所以,事務E能夠讀取到事務A、事務B和事務C對應的data1、data2和data3記錄的最新版本。而事務D屬于活動事務,所以,事務E能夠讀取到data4的上一個版本。
事務E執(zhí)行到t2時刻時,事務D也已經(jīng)提交,按照之前的分析可知,在t2時刻,事務E能夠讀取到事務A、事務B、事務C和事務D對應的數(shù)據(jù)data1、data2、data3和data4的最新版本。
在可重復讀隔離級別下,這顯然是不符合要求的。
在可重復讀隔離級別下,MVCC機制是如何解決這個問題的呢?
其實解決的辦法很簡單,就是在系統(tǒng)中記錄下t1時刻啟動事務E時的活動事務列表,在事務E執(zhí)行的過程中,一直使用在t1時刻記錄的活動事務列表即可,這個一直使用的活動事務列表被稱為“快照”。
很顯然,在t2時刻使用在t1時刻保存的活動事務列表,則事務E在t1時刻和t2時刻讀取到的數(shù)據(jù)是一致性。
讀已提交與可重復讀MVCC的區(qū)別
讀已提交隔離級別下每個SQL語句都會有一個自己的快照,它們看到的數(shù)據(jù)庫中的數(shù)據(jù)是不同的。而在可重復讀隔離級別下,所有的SQL語句使用同一個快照,能夠看到數(shù)據(jù)庫中同樣的數(shù)據(jù)。
快照優(yōu)化
在實現(xiàn)MVCC時,并只是簡單的存儲事務id列表,而是會統(tǒng)計最小活動事務id和最大已提交事務id,這樣做的好處是:大部分事務id通過比較這些邊界值就能夠迅速判別是讀取最新版本還是上一個版本,如果事務id正好落在這些邊界值的范圍之內(nèi),則只需要進一步查找當前事務id是否與活動事務的id相匹配即可。如果相匹配,則說明當前事務是活動事務,可以看到當前數(shù)據(jù)。
好了,關于MVCC,小伙伴們,你們理解了嗎?理解透徹后,再學習下MySQL的底層原理,有條件的話,閱讀下MySQL的源碼,然后跟冰河一起手寫MySQL。