作者 | 黃冬發
背景介紹
在一個典型的分布式文件系統中,目錄文件元數據操作(包括創建目錄或文件,重命名,修改權限等)在整個文件系統操作中占很大比例,因此元數據服務在整個文件系統中扮演著重要的角色,隨著大規模機器學習、大數據分析和企業級數據湖等應用,分布式文件系統數據規模已經從 PB 級到 EB 級,當前多數分布式文件系統(如 HDFS 等)面臨著元數據擴展性的挑戰。
以 Google、Facebook 和 Microsoft 等為代表的公司基本實現了能夠管理 EB 級數據規模的分布式文件系統,這些系統的共同架構特征是依賴于底層分布式數據庫能力來實現元數據性能的水平擴展,如 Google Colossus 基于 BigTable,Facebook 基于 ZippyDB,Microsoft ADLSv2 基于 Table Storage,還有一些開源文件系統包括 CephFS 和 HopsFS 等也基本實現了水平擴展的能力。
這些文件系統實現由于對底層分布式數據庫的依賴,對文件系統的語義支持程度也各有不同,如大多數基于分布式文件系統的計算分析框架依賴底層目錄原子 Rename 操作來提供數據的原子更新,而 Tectonic 和 Colossus 因為底層數據庫不支持跨分區事務所以不保證跨目錄 Rename 的原子性,而 ADLSv2 支持對任意目錄的原子 Rename。
DanceNN 是公司自研的一個目錄樹元信息存儲系統,致力于解決所有分布式存儲系統的目錄樹需求(包括不限于 HDFS,NAS 等),極大簡化上層存儲系統依賴的目錄樹操作復雜性,包括不限于原子 Rename、遞歸刪除等。解決超大規模目錄樹存儲場景下的擴展性、性能、異構系統間的全局統一命名空間等問題,打造全球領先的通用分布式目錄樹服務。
當前 DanceNN 已經為公司在線 ByteNAS,離線 HDFS 兩大分布式文件系統提供目錄樹元數據服務。
(本篇主要介紹在離線大數據場景 HDFS 文件系統下 DanceNN 的應用,考慮篇幅,DanceNN 在 ByteNAS 的應用會在后續系列文章介紹,敬請期待)
元數據演進
字節 HDFS 元數據系統分三個階段演進:

NameNode
最開始公司使用 HDFS 原生 NameNode,雖然進行了大量優化,依然面臨下列問題:
- 元數據(包括目錄樹,文件和 Block 副本等)全內存存儲,單機承載能力有限
- 基于 Java 語言實現,在大內存場景 GC 停頓時間比較長,嚴重影響 SLA
- 使用全局一把讀寫鎖,讀寫吞吐性能較差
- 隨著集群數據規模增加,重啟恢復時間達到小時級別
DanceNN v1
DanceNN v1 的設計目標是為了解決上述 NameNode 遇到的問題。
主要設計點包括:
- 重新實現 HDFS 協議層,將目錄樹文件相關元數據存儲到 RocksDB 存儲引擎,提供 10 倍元數據承載
- 使用 C++ 實現,避免 GC 問題,同時使用高效數據結構組織內存 Block 信息,減少內存使用
- 實現一套細粒度目錄鎖機制,極大提升不同目錄文件操作間的并發
- 請求路徑全異步化,支持請求優先級處理
- 重點優化塊匯報和重啟加載流程,降低不可用時間
DanceNNv1 最終在 2019 年完成全量上線,線上效果基本達到設計目標。
下面是一個十幾億文件數規模集群,切換后大致性能對比:

DanceNN v1 開發中遇到很多技術挑戰,如為了保證上線過程對業務無感知,支持現有多種 HDFS 客戶端訪問,后端需要完全兼容原有的 Hadoop HDFS 協議。
Distributed DanceNN
一直以來 HDFS 都是使用 Federation 方式來管理目錄樹,將全局 Namespace 按 path 映射到多組元數據獨立的 DanceNN v1 集群,單組 DanceNN v1 集群有單機瓶頸,能處理的吞吐和容量有限,隨著公司業務數據的增長,單組 DanceNN v1 集群達到性能極限,就需要在兩個集群之間頻繁遷移數據,為了保證數據一致性需要在遷移過程中上層業務停寫,對業務影響比較大,并且當數據量大的情況下遷移比較慢,這些問題給整個系統帶來非常大的運維壓力,降低服務的穩定性。
Distributed 版本主要設計目標:
- 通用目錄樹服務,支持多協議包括 HDFS,POSIX 等
- 單一全局 Namespace
- 容量、吞吐支持水平擴展
- 高可用,故障恢復時間在秒級內
- 包括跨目錄 Rename 等寫操作支持事務
- 高性能,基于 C++ 實現,依賴 Brpc 等高性能框架
Distributed DanceNN 目前已經在 HDFS 部分集群上線,正在進行存量集群的平滑遷移。
文件系統概覽
分層架構
最新 HDFS 分布式文件系統實現采用分層架構,主要包括三層:
數據層:用于存儲文件內容, 處理 Block 級別的 IO 請求
- 由 DataNode 節點提供服務
Namespace 層:負責目錄樹相關元數據,處理目錄和文件創建、刪除、Rename 和鑒權等請求
- 由 Distributed DanceNN 集群提供服務
文件塊層:負責文件相關的元數據、文件與 Block 的映射以及 Block 副本位置信息,處理文件創建刪除,文件 Block 的添加等請求
- 一個 BSGroup 負責管理集群部分文件塊元數據,由多臺的 DanceBS 組成提供高可用服務
- 通過 BSGroup 動態擴容來適應集群負載,當某個 BSGroup 快達到性能極限后可以控制寫入
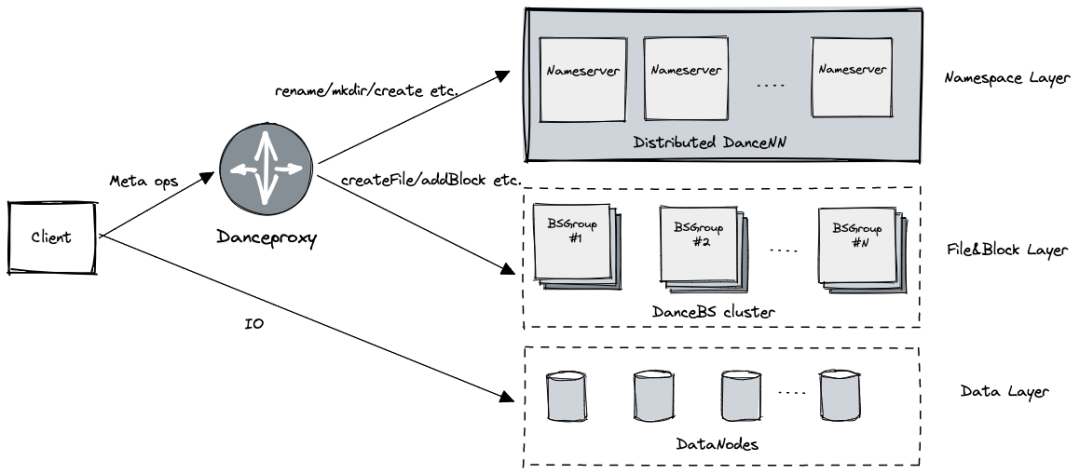
DanceProxy
C++ 實現,基于高性能框架 Brpc 實現了 Hadoop RPC 協議,支持高吞吐,無縫對接現有 HDFS Client。
主要負責對 HDFS Client 請求的解析,拆分處理后,將 Namespace 相關的請求發送到 DanceNN 集群,文件塊相關的請求路由到對應的 BSGroup 處理,當所有后端請求回復后生成最終客戶端的響應。
DanceProxy 通過一定的請求路由策略來實現多組 BSGroup 負載均衡。
DanceNN 接口
Distributed DanceNN 為文件系統提供主要接口如下:
class DanceNNClient {
public:
DanceNNClient() = default;
virtual ~DanceNNClient() = default;
// ...
// Create directories recursively, eg: MkDir /home/tiger.
ErrorCode MkDir(const MkDirReq& req);
// Delete a directory, eg: RmDir /home/tiger.
ErrorCode RmDir(const RmDirReq& req);
// Change the name or location of a file or directory,
// eg: Rename /tmp/foobar.txt /home/tiger/foobar.txt.
ErrorCode Rename(const RenameReq& req);
// Create a file, eg: Create /tmp/foobar.txt.
ErrorCode Create(const CreateReq& req, CreateRsp* rsp);
// Delete a file, eg: Unlink /tmp/foobar.txt.
ErrorCode Unlink(const UnlinkReq& req, UnlinkRsp* rsp);
// Summarize a file or directory, eg: Du /home/tiger.
ErrorCode Du(const DuReq& req, DuRsp* rsp);
// Get status of a file or directory, eg: Stat /home/tiger/foobar.txt.
ErrorCode Stat(const StatReq& req, StatRsp* rsp);
// List directory contents, eg: Ls /home/tiger.
ErrorCode Ls(const LsReq& req, LsRsp* rsp);
// Create a symbolic link named link_path which contains the string target.
// eg: Symlink /home/foo.txt /home/bar.txt
ErrorCode Symlink(const SymlinkReq& req);
// Read value of a symbolic link.
ErrorCode ReadLink(const ReadLinkReq& req, ReadLinkRsp* rsp);
// Change permissions of a file or directory.
ErrorCode ChMod(const ChModReq& req);
// Change ownership of a file or directory.
ErrorCode ChOwn(const ChOwnReq& req);
// Change file last access and modification times.
ErrorCode UTimeNs(const UTimeNsReq& req, UTimeNsRsp* rsp);
// Set an extended attribute value.
ErrorCode SetXAttr(const SetXAttrReq& req, SetXAttrRsp* rsp);
// List extended attribute names.
ErrorCode GetXAttrs(const GetXAttrsReq& req, GetXAttrsRsp* rsp);
// remove an extended attribute.
ErrorCode RemoveXAttr(const RemoveXAttrReq& req,
RemoveXAttrRsp* rsp);
// ...
};
DanceNN 架構
功能介紹
Distributed DanceNN 基于底層分布式事務 KV 存儲來構建,實現容量和吞吐水平擴展,主要功能:
- HDFS 等協議層的高效實現
- 服務無狀態化,支持高可用
- 服務節點的快速擴縮容
- 提供高性能低延遲的訪問
- 對 Namespace 進行子樹劃分,充分利用子樹 Cache Locality
- 集群根據負載均衡策略對子樹進行調度
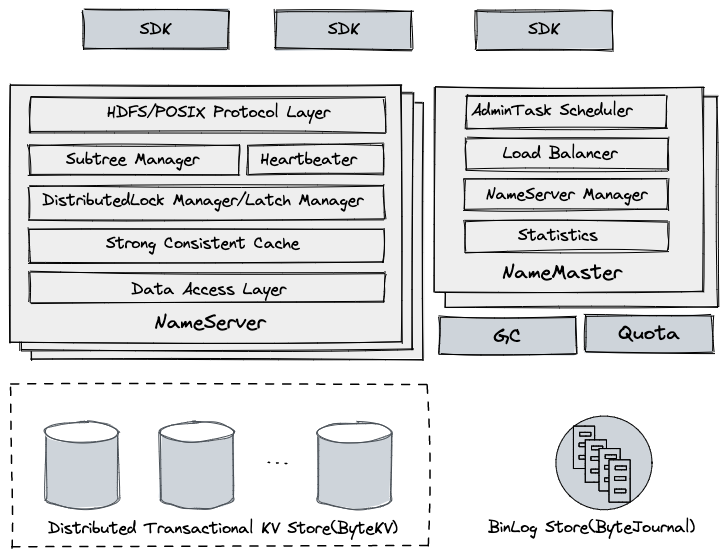
模塊劃分
SDK
緩存集群子樹、NameServer 位置等信息,解析用戶請求并路由到后端服務節點上,如果服務節點響應請求不合法,可能強制 SDK 刷新相應的集群緩存。
NameServer
- 作為服務節點,無狀態,支持橫向擴展
- HDFS/POSIX Protocol Layer:處理客戶端請求,實現了 HDFS 等協議層語義,包括路徑解析,權限校驗,刪除進入回收站等
- Subtree Manager:管理分配給當前節點的子樹,負責用戶請求檢查,子樹遷移處理等
- Heartbeater:進程啟動后會自動注冊到集群,定期向 NameMaster 更新心跳和負載信息等
- DistributedLock Manager:基于 LockTable,對跨目錄 Rename 請求進行并發控制
- Latch Manager:對所有路徑讀寫請求進行加鎖處理,降低底層事務沖突,支持 Cache 的并發訪問
- Strong Consistent Cache:維護了當前節點子樹的 dentry 和 inode 強一致 Cache
- Data Acess Layer:對底層 KV 存儲的訪問接口的抽象,上層讀寫操作都會映射到底層 KV 存儲請求
NameMaster
- 作為管理節點,無狀態,多臺,通過選主實現,由主節點提供服務
- AdminTask Scheduler:后臺管理相關任務調度執行,包括子樹切分,擴容等
- Load Balancer:根據集群 NameServer 負載狀態,通過自動子樹遷移來完成負載均衡
- NameServer Manager:監控 NameServer 健康狀態,進行相應的宕機處理
- Statistics:通過消費集群變更日志,實時收集統計信息并展示
Distributed Transactional KV Store
- 數據存儲層,使用自研的強一致 KV 存儲系統 ByteKV
- 提供水平伸縮能力
- 支持分布式事務,提供 Snapshot 隔離級別
- 支持多機房數據災備
BinLog Store
BinLog 存儲,使用自研的低延遲分布式日志系統 ByteJournal,支持 Exactly Once 語義
從底層 KV 存儲系統中實時抽取數據變更日志,主要用于 PITR 和其他組件的實時消費等
GC(Garbage collector)
從 BinLog Store 實時消費變更日志,讀到文件刪除記錄后,向文件塊服務下發刪除命令,及時清理用戶數據
Quota
對用戶認領的目錄,會周期性全量、實時增量的統計文件總數和空間總量,容量超限后限制用戶寫
關鍵設計
存儲格式
一般基于分布式存儲的元數據格式有兩種方案:
方案一類似 Google Colossus,以全路徑作為 key,元數據作為 value 存儲,優點有:
- 路徑解析非常高效,直接通過用戶請求的 path 從底層的 KV 存儲讀取對應 inode 的元數據即可
- 掃描目錄可以通過前綴對 KV 存儲進行掃描
但是有下列缺點:
- 跨目錄 Rename 代價大,需要對目錄下的所有文件和目錄進行移動
- Key 占用的空間相對比較大
另外一種類似 Facebook Tectonic 和開源的 HopsFS,以父目錄 inode id + 目錄或文件名作為 key,元數據作為 value 存儲,這種優點有:
跨目錄 Rename 非常輕量,只需要修改源和目標節點以及它們的父節點
掃描目錄同樣可以用父目錄 inode id 作為前綴進行掃描
缺點有:
路徑解析網絡延遲高,需要從 Root 依次遞歸讀取相關節點元數據直到目標節點
例如:MkDir /tmp/foo/bar.txt,有四次元數據網絡訪問:/、/tmp、/tmp/foo 和 /tmp/foo/bar.txt
層級越小,訪問熱點越明顯,從而導致底層存儲負載嚴重不均衡
例如:每個請求都要讀取一次根目錄/的元數據
考慮到跨目錄 Rename 請求在線上集群占比較高的比例,并且對于大目錄 Rename 延遲不可控,DanceNN 主要采用第二種方案,方案二的兩個缺點通過下面的子樹分區來解決。
子樹分區
DanceNN 通過將全局 Namespace 進行子樹分區,子樹被指定一個 NameServer 實例維護子樹緩存。
子樹緩存
- 維護這個子樹下所有目錄和文件元數據的強一致緩存
- 緩存項有一定淘汰策略包括 LRU,TTL 等
- 所有請求路徑在這個子樹下的可以直接訪問本地緩存,未命中需要從底層 KV 存儲進行加載并填充緩存
- 通過對緩存項添加版本的方法來指定某個目錄下所有元數據的緩存過期,有利于子樹快速遷移清理
利用子樹本地緩存,路徑解析和讀請求基本能夠命中緩存,降低整體延遲,也避免了靠近根節點訪問的熱點問題。
路徑凍結
在子樹遷移、跨子樹 Rename 等操作過程中,為了避免請求讀取過期的子樹緩存,需要將相關的路徑進行凍結,凍結期間該路徑下的所有操作會被阻塞,由 SDK 負責重試,整個流程在亞秒級內完成
路徑凍結后會將該目錄下的所有緩存項設置為過期
凍結的路徑信息會被持久化到底層的 KV 存儲,重啟后會重新加載刷新
子樹管理
子樹管理主要由 NameMaster 負責:
- 支持通過管理員命令進行手動子樹分裂和子樹遷移
- 定期監控集群節點的負載狀態,動態調整子樹在集群分布
- 定期統計子樹的訪問吞吐,提供子樹分裂建議,未來支持啟發式算法選擇子樹完成分裂
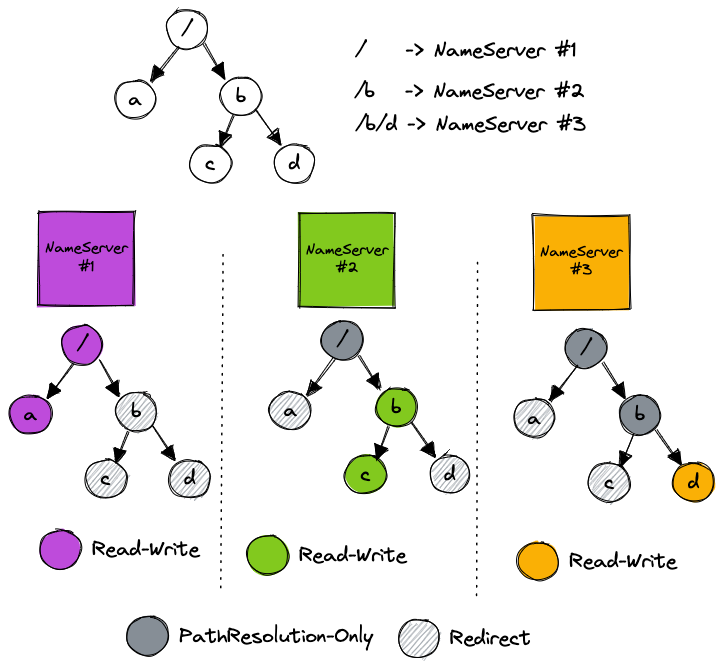
舉個例子,如下圖:
目錄 / 調度到 NameServer #1,目錄 /b 調度到 NameServer #2,目錄 /b/d 調度到 NameServer #3
- MkDir /a 請求發送到 NameServer #1,發送到其他 NameServer 會校驗失敗,返回重定向錯誤,讓 SDK 刷新緩存重試
- Stat /b/d 請求將會發送到 NameServer #3,直接讀取本地緩存即可
- ChMod /b 請求將會發送到 NameServer #2,更新 b 目錄的權限信息并持久化,對 NameServer #2 和 NameServer #3 進行 Cache 刷新,最后回復客戶端
并發控制
底層 KV 存儲系統 ByteKV 支持單條記錄的 Put、Delete 和 Get 語義,其中 Put 支持 CAS 語義,還提供多條記錄的原子性寫入接口 WriteBatch。
客戶端寫操作一般會涉及多個文件或目錄的更新,例如 Create /tmp/foobar.txt 會更新 /tmp 的 mtime 記錄、創建 foobar.txt 記錄等,DanceNN 會將多條記錄的更新轉換成 ByteKV WriteBatch 請求,保證了整個操作的原子性。
分布式鎖管理
雖然 ByteKV 提供事務的 ACID 屬性且支持 Snapshot 隔離級別,但是對于多個并發寫操作如果涉及底層數據變更之間沒有 Overlap 的話,仍然會有 Write Skew 異常,這可能導致元數據完整性被破壞。
其中一個例子是并發 Rename 異常,如下圖:
單個 Rename /a /b/d/e 操作或者單個 Rename /b/d /a/c 操作都符合預期,但是如果兩者并發執行(且都能成功),可以導致目錄 a,c,d,e 的元數據出現環,破壞了目錄樹結構的完整性。

我們選擇使用分布式鎖機制來解決,對于可能導致異常的并發請求進行串行處理,基于底層 KV 存儲設計了 Lock Table,支持對于元數據記錄進行加鎖,提供持久性、水平擴展、讀寫鎖、鎖超時清理和冪等功能。
Latch 管理
為了支持對子樹內部緩存的并發訪問和更新,維護緩存的強一致,會對操作涉及的緩存項進行加鎖(Latch),例如:Create /home/tiger/foobar.txt,會先對 tiger 和 foobar.txt 對應的緩存項加寫 Latch,再進行更新操作;Stat /home/tiger 會對 tiger 緩存項加讀 Latch,再進行讀取。
為了提升服務的整體性能做了非常多的優化,下面列兩個重要優化:
熱點目錄下大量創建和刪除文件
例如:有些業務像大型 MapReduce 任務會在相同目錄一下子創建幾千個目錄或文件。
一般來說根據文件系統語義創建文件或目錄都會更新父目錄相關的元數據(如 HDFS 協議更新父目錄的 mtime,POSIX 要求更新父目錄 mtime,nlink 等),這就導致同目錄下創建文件操作對父目錄元數據的更新產生嚴重的事務沖突,另外底層 KV 存儲系統是多機房部署,機房延遲更高,進一步降低了這些操作的并發度。
DanceNN 對于熱點目錄下的創建刪除等操作只加讀 latch,之后放到一個 ExecutionQueue 中, 由一個的輕量 Bthread 協程進行后臺異步串行處理,將這些請求組合成一定大小的 Batch 發送給底層的 KV 存儲,這樣避免了底層事務沖突,提升幾十倍吞吐。
請求間的相互阻塞
有些場景可能會導致目錄的更新請求阻塞了這個目錄下的其他請求,例如:
SetXAttr /home/tiger 和 Stat /home/tiger/foobar.txt 無法并發執行,因為第一個對 tiger 緩存項加寫 Latch,后面請求讀 tiger 元數據緩存項會被阻塞。
DanceNN 使用類似 Read-Write-Commit Lock 實現對 Latch 進行管理,每個 Latch 有 Read、Write 和 Commit 三種類型,其中 Read-Read、Read-Write 請求可以并發,Write-Write、Any-Commit 請求互斥。
基于這種實現,上述兩個請求能夠在保證數據一致性的情況下并發執行。
請求冪等
當客戶端因為超時或網絡故障而失敗時,進行重試會導致同一個請求到達 Server 多次。有些請求如 Create 或者 Unlink 是非冪等的請求,對于這樣的操作,需要在 Server 端識別以保證只處理一次。
在單機場景中,我們通常使用一個內存的 Hash 表來處理重試請求,Hash 表的 key 為 {ClientId, CallId},value 為 {State, Response},當請求 A 到來之后,我們會插入 {Inprocess State} 到 Hash 表;這之后,如果重試請求 B 到來,會直接阻塞住請求 B,等待第請求 A 執行成功后喚醒 B。當 A 執行成功之后,我們會將 {Finished State, Response} 寫到 Hash 表并喚醒 B,B 會看到更新的 Finished 狀態后響應客戶端。
類似的 DanceNN 寫請求會在底層的 WriteBatch 請求里加一條 Request 記錄,這樣可以保證后續的重試請求操作一定會在底層出現事務 CAS 失敗,上層發現后會讀取該 Request 記錄直接響應客戶端。另外,何時刪除 Request 記錄呢,我們會給記錄設置一個相對較長時間的 TTL,可以保證該記錄在 TTL 結束之后一定已經處理完成了。
性能測試
壓測環境:
DanceNN 使用 1 臺 NameServer,分布式 KV 存儲系統使用 100+臺數據節點,三機房五副本部署(2 + 2 + 1),跨機房延遲 2-3ms 左右,客戶端通過 NNThroughputBenchmark 元數據壓測腳本分別使用單線程和 6K 線程并發進行壓測。
截取部分延遲和吞吐數據如下:
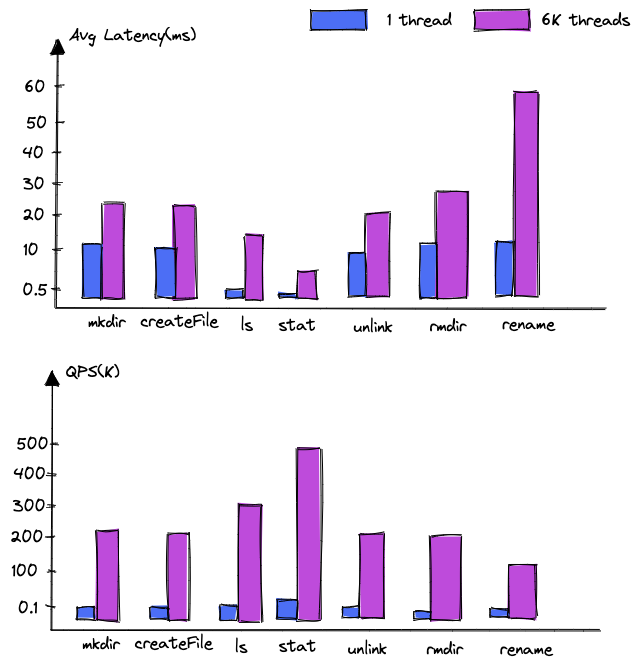
測試結果表明:
- 讀吞吐:單臺 NameServer 支持讀請求 500K,隨著 NameServer 數量的增加吞吐基本能夠線性增長;
- 寫吞吐:目前依賴底層 KV 存儲的寫事務性能,隨著底層 KV 節點數據量的增加也能夠實現線性增長。