













天天用MySQL開發,你知道數據庫能抗多大并發壓力嗎?
今天給大家分享一個知識點,是關于MySQL數據庫架構演進的,因為很多兄弟天天基于mysql做系統開發,但是寫的系統都是那種低并發壓力、小數據量的,所以哪怕上線了也就是這么正常跑著而已,但是你知道你連接的這個MySQL數據庫他到底能抗多大并發壓力嗎?如果MySQL數據庫扛不住壓力了,應該如何演進你知道嗎?

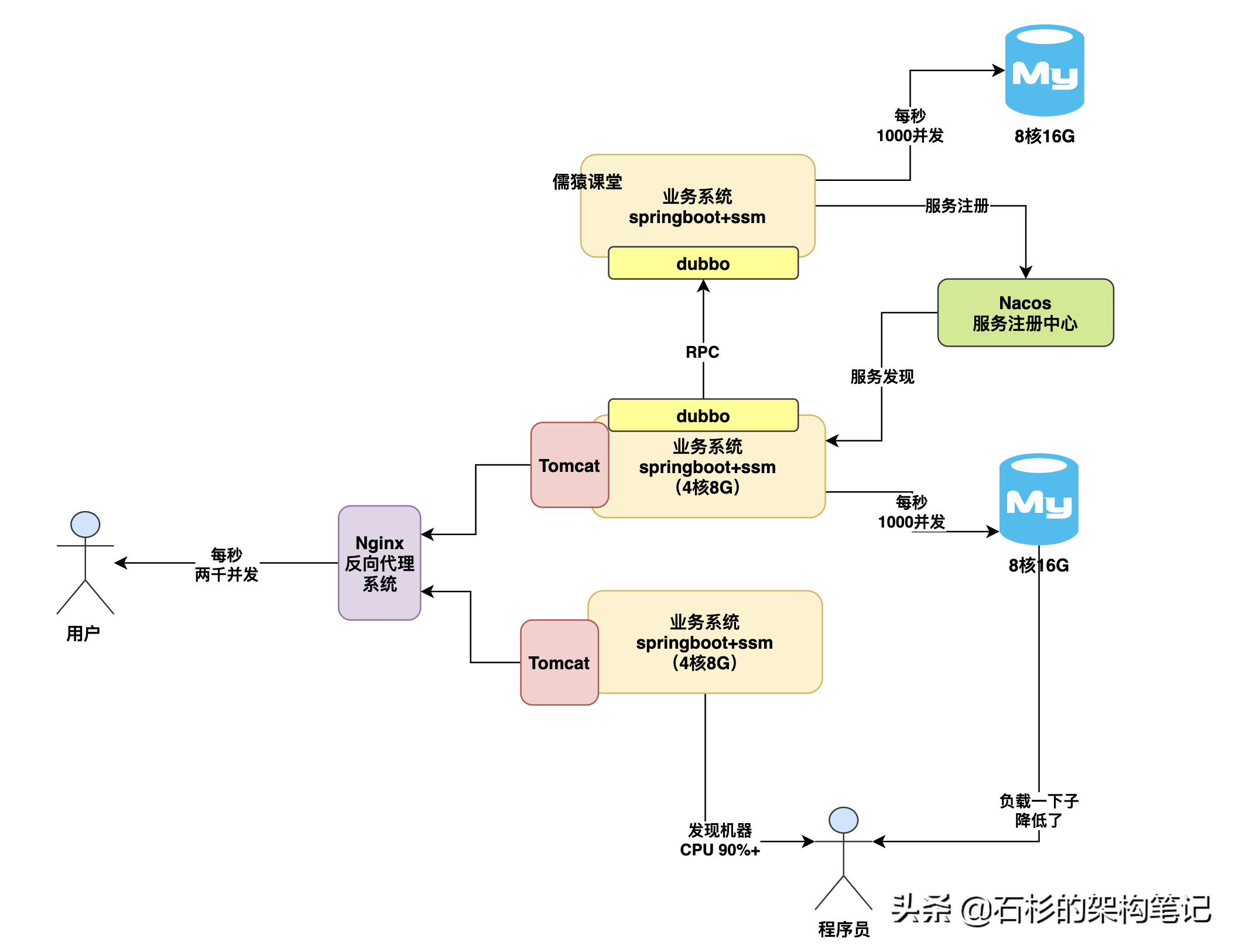
一般業務系統運行流程圖
首先,我們先來看一個最最基礎的java業務系統連接數據庫運行的架構,其實簡單來說,我們平時都是用spring boot+ssm技術棧開發一個java業務系統的,用spring boot內嵌tomcat就可以對外提供http接口了,然后最多現在會加上nacos+dubbo調用別的系統接口,數據全部靠連接mysql數據庫進行crud就可以了,如下圖。
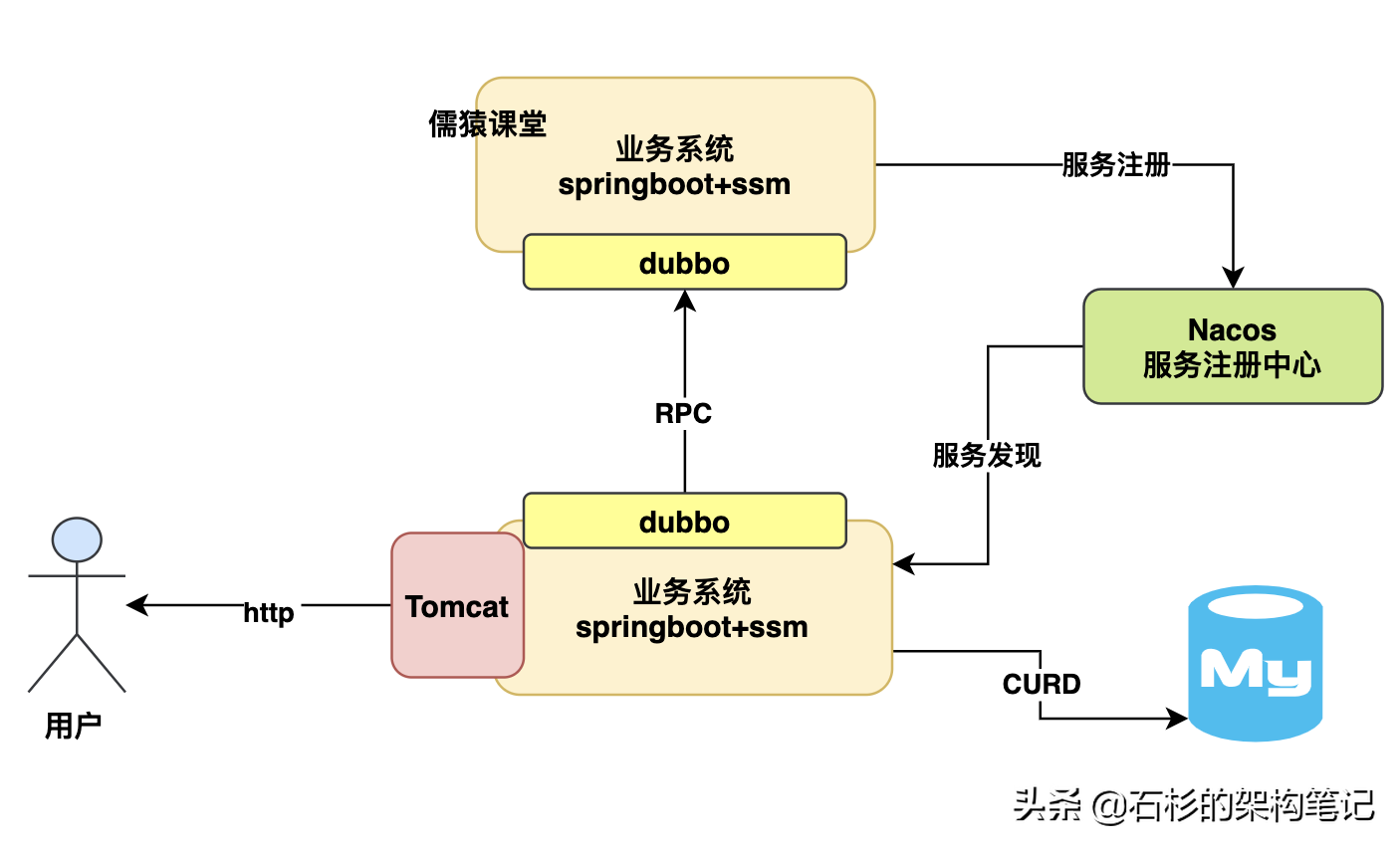
上面那種架構的系統,估計就是很多兄弟日常做的最多的系統架構了,有的兄弟稍微做的高大上一點,大概來說,可能就是會加入一些es、redis、rocketmq一類的中間件簡單使用一下,但是大致來說也就這么回事了,那么還是回歸主題,大家知道你上述那種系統下,他連接的數據庫能抗多大壓力嗎?
一臺4核8G的機器能扛多少并發量呢?
說實話,要解決這個問題,一般來說,不是先聊數據能抗多少壓力,因為往往不是數據庫先去抗高并發,而是你連接數據庫的web系統得先去抗高并發!也就是我們的spring boot+ssm那套業務系統能抗多高并發我們得先搞清楚!
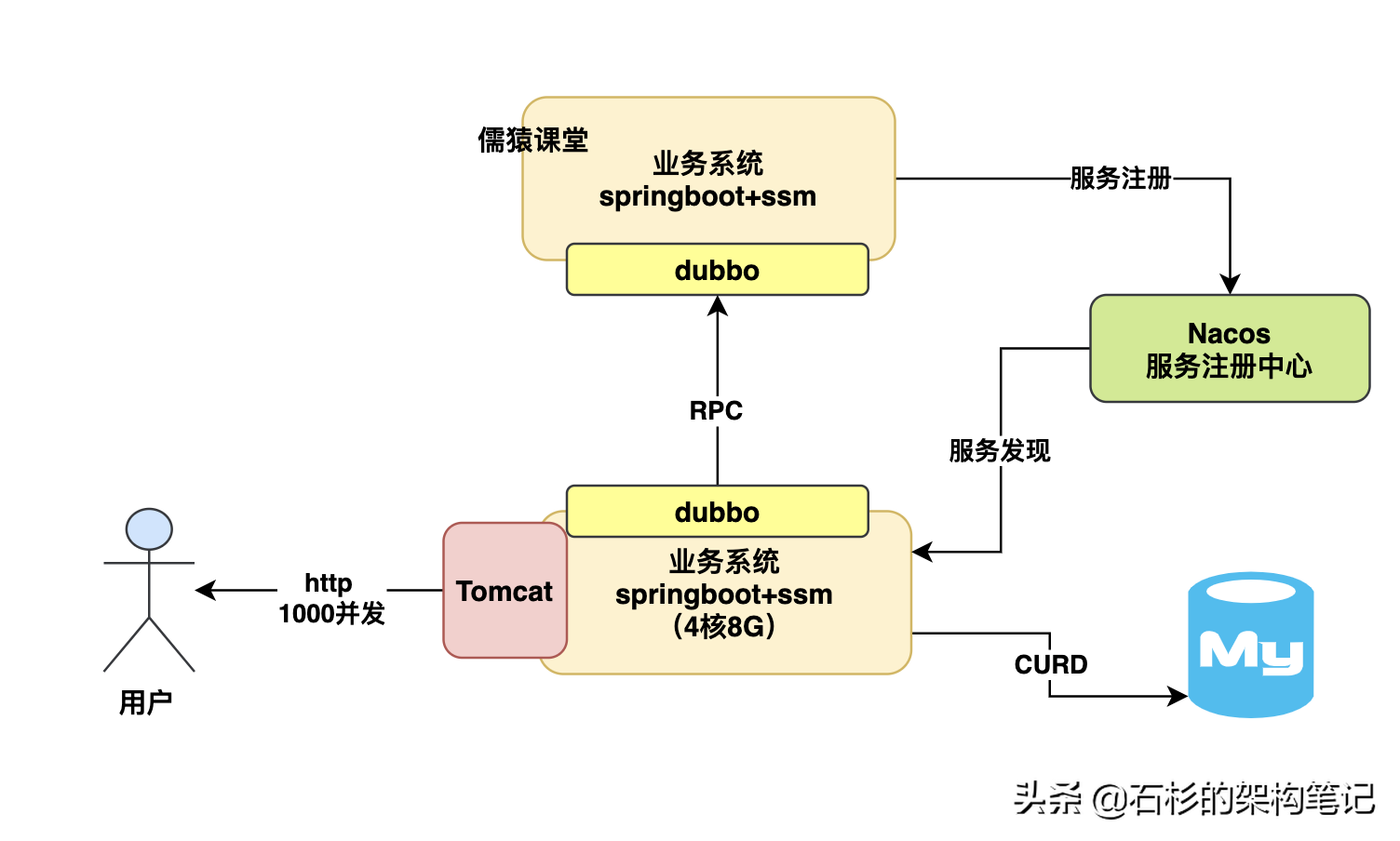
所以要搞明白這個問題,就得先說一個主題,一般來說我們的spring boot應用系統大致就是部署在2核4G或者4核8G的機器上,這個機器配置其實是很關鍵的,所以這里直接告訴大家一個經驗值,即使說咱們如果部署的是一個4核8G的機器,然后spring boot內嵌的tomcat默認開了200個線程來處理請求,接著每個請求都要讀寫多次數據庫,那么此時,大致來說你的一臺機器可以抗大概500~1000這個并發量,具體多少得看你的接口復雜度,如下圖。
高并發來襲時數據庫會先被打死嗎?
所以其實一般來說,當你的高并發壓力來襲的時候,通常不會是數據庫先扛不住了,而是你的業務系統所在機器抗不住了,比如你部署了2臺機器,那么其實到每秒一兩千并發的時候,這兩臺機器基本上cpu負載都得飆升到90%以上 ,壓力很大,而且接口性能會開始往下掉很多了,如下圖。
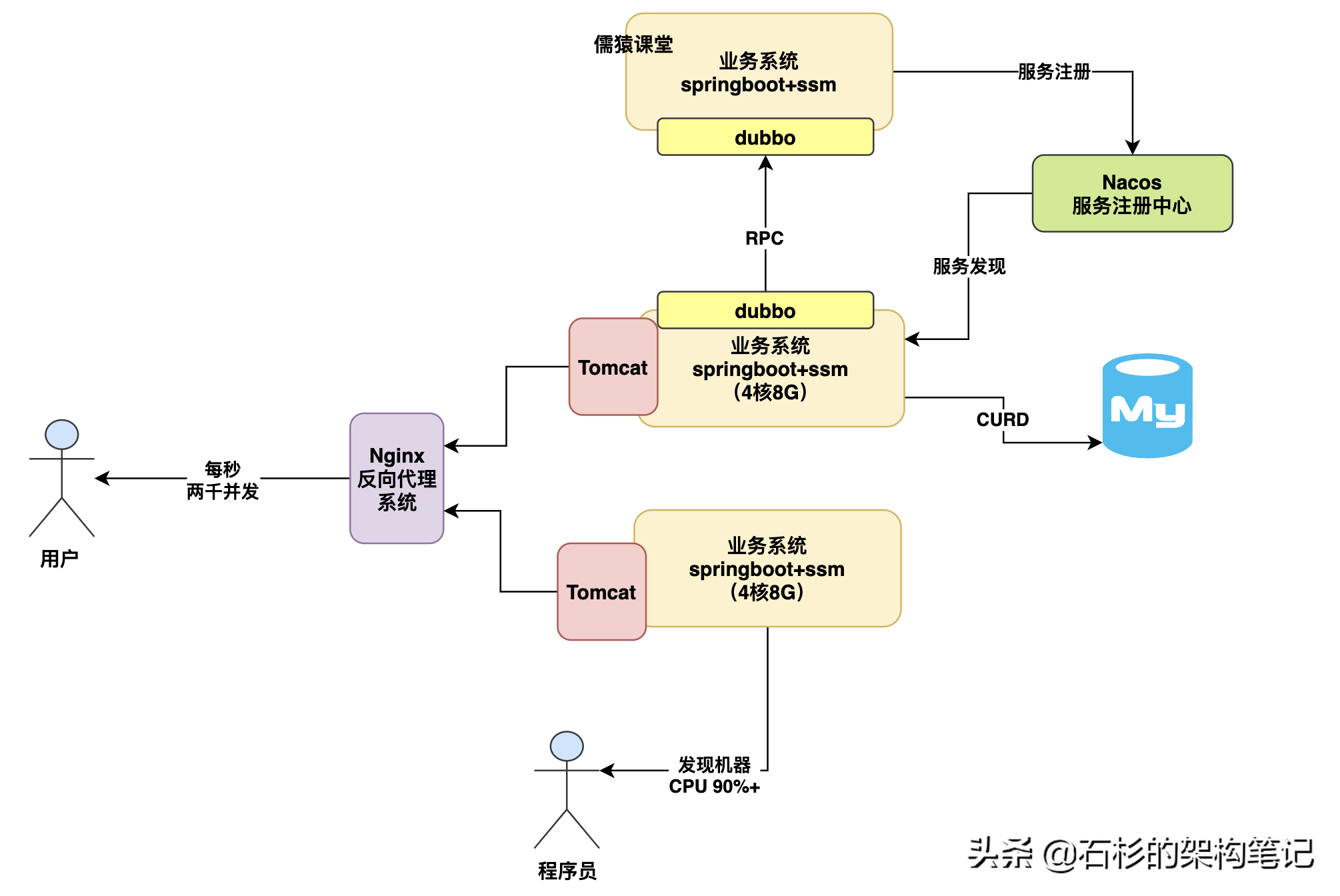
那么這個時候我們的數據庫壓力會如何呢?其實一般來說你的兩臺機器抗下每秒一兩千的請求的時候后,數據庫壓力通常也會到一個小瓶頸,因為為什么呢?關鍵是你的業務系統處理每個業務請求的時候,他是會讀寫多次數據庫的,所以業務系統的一次請求可能會導致數據庫有多次請求,也正因為這樣,所以此時可能你的數據庫并發壓力會到幾千的樣子。
8核16G的數據庫每秒大概可以抗多少并發壓力?
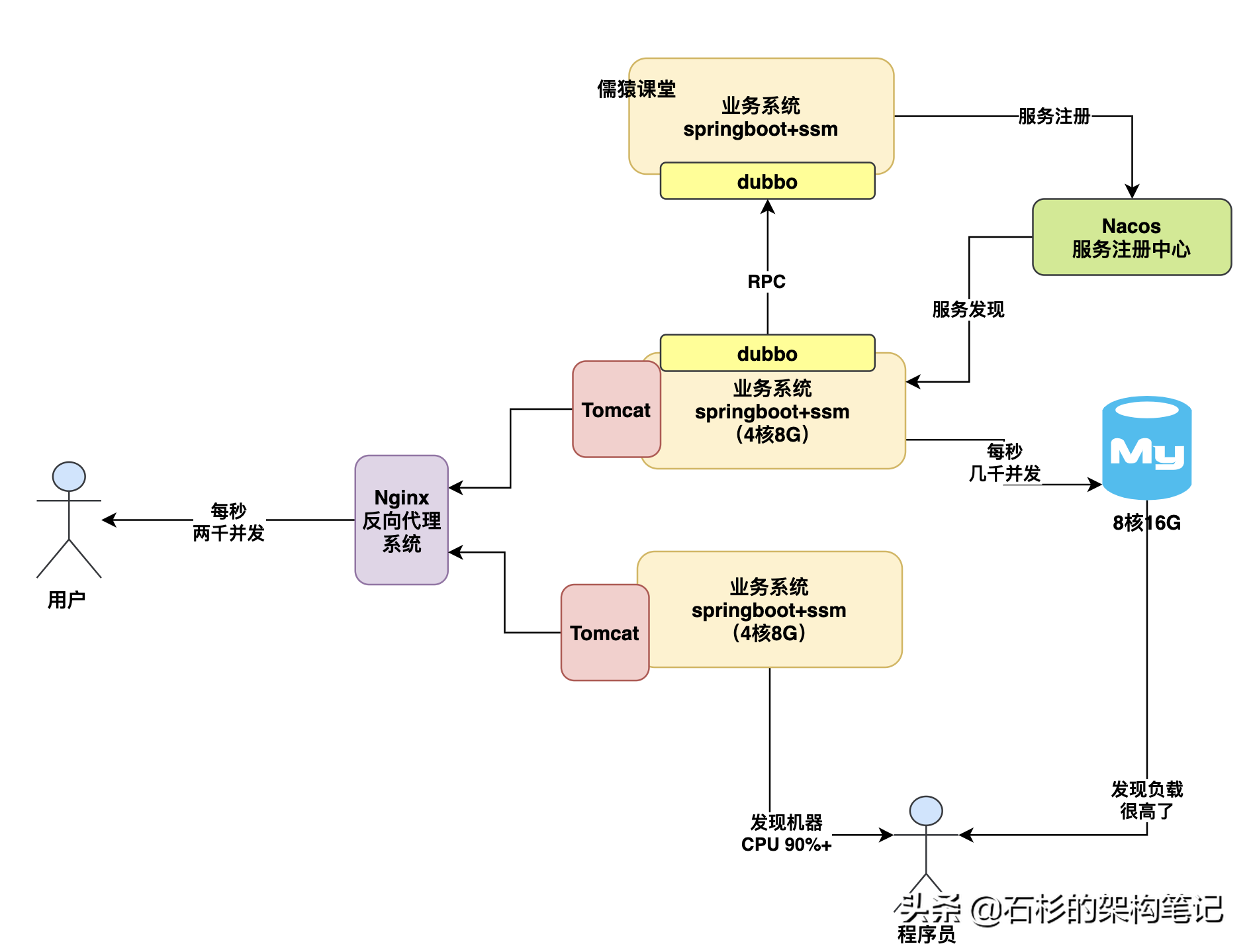
那么所以下一個問題來了,你的數據庫通常是部署在什么樣配置的機器上?一般來說給大家說,數據庫的配置如果是那種特別低并發的場景,其實2核4G或者4核8G也是夠了,但是如果是常規化一點的公司的生產環境數據庫,通常會是8核16G。那么8核16G的數據庫每秒大概可以抗多少并發壓力?大體上來說,在幾千這個數量級。
因為這個具體能抗多少并發也得看你數據庫里的數據量 以及你的SQL語句的復雜度,所以一般來說8核16G的機器,大概也就是抗到每秒幾千并發就差不多了,量再大基本就扛不住了,因為往往到這個量級下,數據庫的cpu、內存、網絡、io的負載基本都很高了,尤其是cpu,可能至少也在百分之七八十了,如下圖。
數據庫架構可以從哪些方面優化?
1、根據業務系統拆分多個數據庫機器優化方案
那么接著說,如果到了這個并發壓力之下,通常來說可以如何進行數據庫架構的優化呢?其實也簡單,我們完全可以加機器,把數據庫部署到多臺機器上去。因為通常來說,我們的一個數據庫里會放很多業務系統的db和tables,所以首先就是可以按照業務系統來進行拆分,比如說多加一臺機器,再部署一個數據庫,然后這里放一部分業務系統的db和tables,老數據庫機器放另外一部分業務系統的db和tables,此時一下子就可以緩解老數據庫機器的壓力了,如下圖。
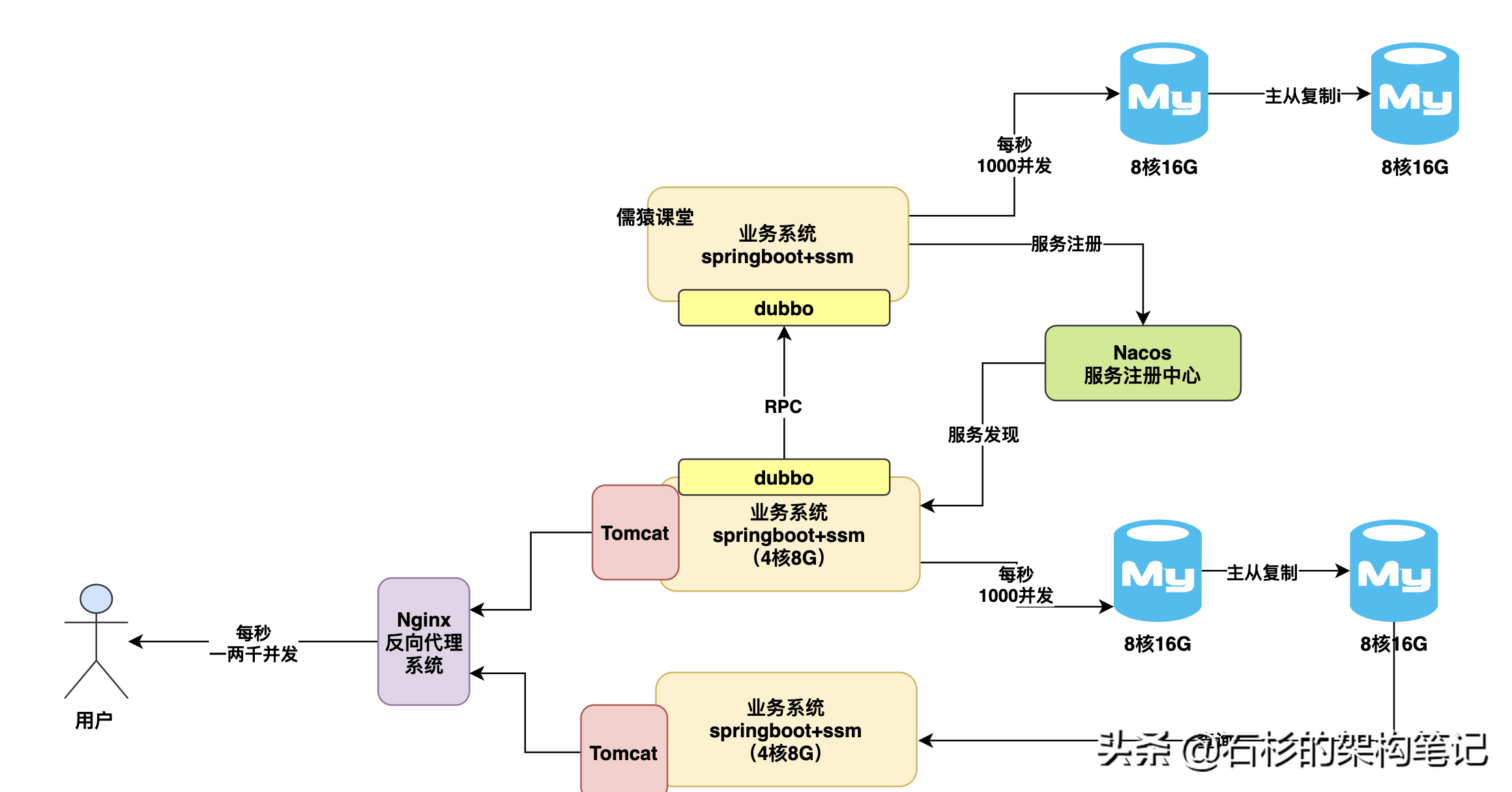
2、讀寫分離架構優化方案
那么接著問題來了,如果說并發壓力繼續提升,導致拆分出去的兩臺數據庫壓力越來越大了呢?此時可以上一招,叫做讀寫分離,就是說給每個數據庫掛一個從庫,讓主數據庫基于binlog數據更新日志同步復制給從數據庫,讓主從數據庫保持數據一致,然后我們的系統其實可以往主庫里寫入,在從庫里查詢,此時就又可以緩解原來的主數據庫的壓力了,如下圖。
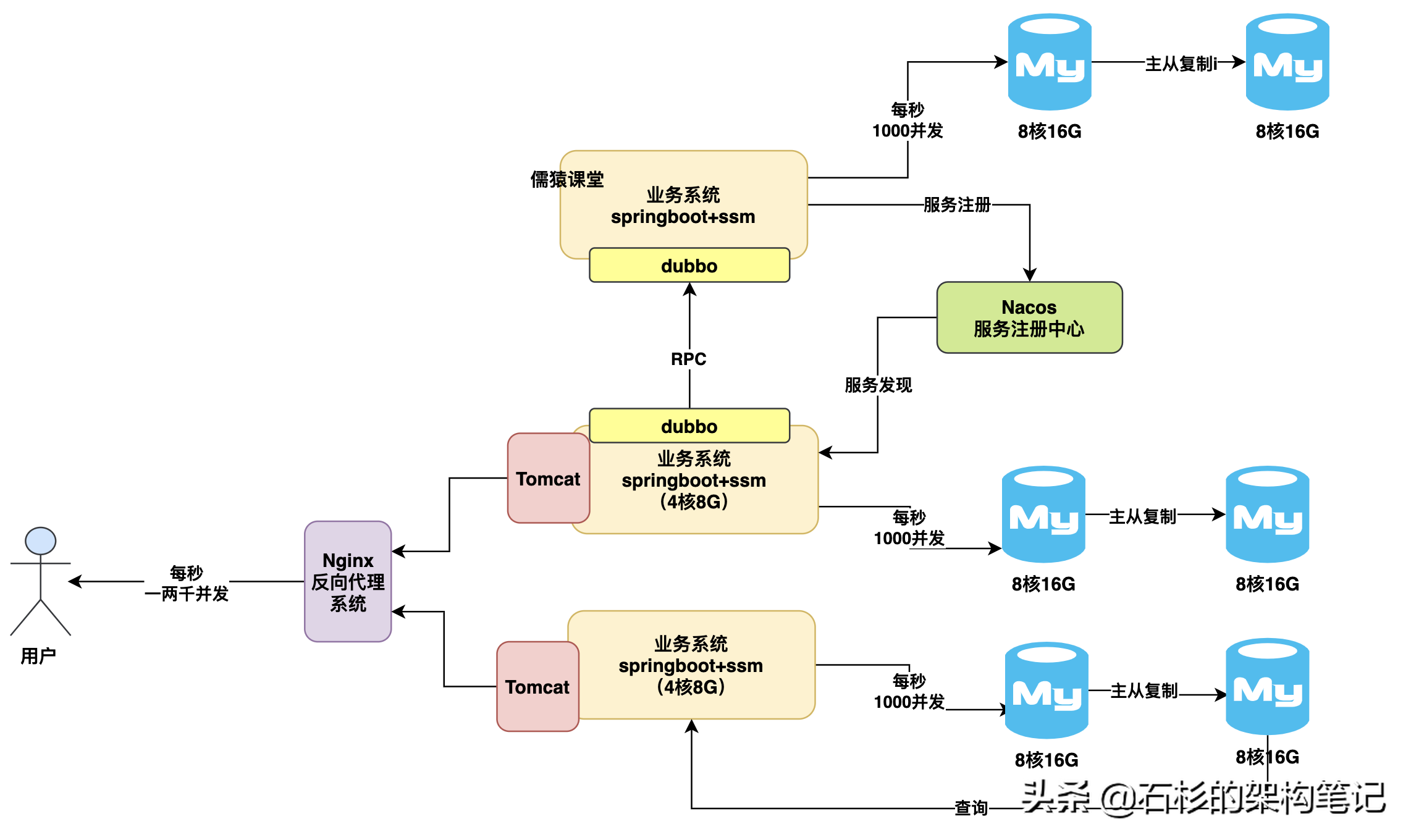
3、分庫分表架構優化方案
再往下說,如果說即使是給主數據庫掛了從庫,然后接著并發壓力繼續提升,讓我們的主數據庫寫入壓力過大,每秒幾千寫入,又要扛不住了呢?此時就只能上終極方案,分庫分表了,就是把主庫拆分為多個庫,每個庫里放一個表的部分數據,然后用多個主庫抗高并發寫入壓力,這樣就可以再次分散我們的壓力了,如下圖所示。
總結
好了,今天分享的知識就到這里了,其實我們的數據庫架構演進基本上就是按照今天說的這個順序和思路逐步逐步的演進的,剛開始你單臺數據庫機器抗幾千并發扛不住了,就按照業務系統拆分多個數據庫機器,然后再扛不住了,就上主從架構分攤讀寫壓力,再扛不住了就分庫分表,多個機器抗數據庫寫入壓力,最后總是可以用數據庫架構抗住高并發 壓力的。
























