













高效壓縮位圖在推薦系統中的應用
一、背景
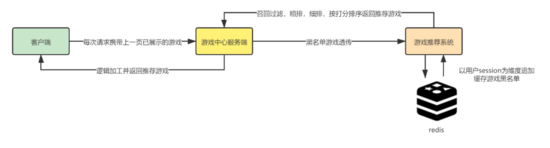
用戶在瀏覽游戲中心/應用商店的某些模塊內容時,會進行一系列滑屏操作并多次請求游戲推薦業務來進行游戲推薦展示,這段時間我們稱之為一個用戶session。
一個session內用戶一般會進行十幾次滑屏操作,每次滑屏操作都會請求推薦業務,所以在這個session內游戲推薦需要對推薦過的游戲進行去重,避免出現重復推薦同一款游戲影響用戶體驗。
精簡后的業務流程如下所示:用戶進行滑屏操作時會觸發一次推薦請求,此時客戶端會將上一頁的黑名單游戲通過游戲中心服務端透傳給推薦系統,推薦系統將一個session內每次請求的黑名單信息都累加存儲到Redis中作為一個總的過濾集合,在召回打分時就會過濾掉這些黑名單游戲。
以實際業務場景為例,用戶瀏覽某模塊的session時長一般不會超過10分鐘,模塊每頁顯示的游戲為20個左右,假設每個用戶session內會進行15次的滑屏操作,那么一個session就需要存儲300 個黑名單游戲的appId(整數型Id)。因此該業務場景就不適合持久化存儲,業務問題就可以歸結為如何使用一個合適的數據結構來緩存一系列整數集合以達到節省內存開銷的目的。
二、技術選型分析
接下來我們隨機選取300個游戲的appId([2945340, ....... , 2793501,3056389])作為集合來分別實驗分析intset,bloom filter,RoaringBitMap對存儲效果的影響。
2.1 intset
實驗結果表明用 intset保存300個游戲集合,得到占用的空間大小為1.23KB。這是因為對于300個整數型appId游戲,每個appId用4Byte的int32就能表示。根據intset的數據結構,其開銷僅為encoding + length + 400 個int所占的空間。

typedef struct intset{
unit32_t encoding; // 編碼類型
unit32_t length; // 元素個數
int8_t contents[]; // 元素存儲
} intset;
2.2 bloom filter
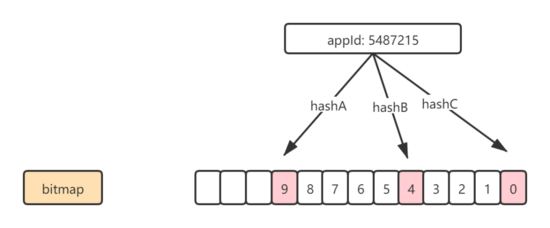
布隆過濾器底層使用的是bitmap,bitmap本身就是一個數組可以存儲整形數字,arr[N] = 1 表示數組里存儲了N這個數字。

bloom filter會先用hash函數對數據進行計算,映射到bitmap相應的位置,為減少碰撞(不同的數據可能會有相同的hash值),會使用多個hash算子對同一份數據進行多次映射。在業務中我們假設線上有一萬個游戲,同時業務場景不允許出現誤判,那么誤差就必須控制在10^-5,通過bloom filter的計算工具https://hur.st/bloomfilter/?n=10000&p=1.0E-5&m=&k=得出,需要17個hash算子,且bitmap空間要達到29KB才能滿足業務需求,顯然這樣巨大的開銷并不是我們想要的結果。
2.3 RoaringBitMap
RoaringBitMap和bloom filter本質上都是使用bitmap進行存儲。但bloom filter 使用的是多個hash函數對存儲數據進行映射存儲,如果兩個游戲appId經過hash映射后得出的數據一致,則判定兩者重復,這中間有一定的誤判率,所以為滿足在該業務場景其空間開銷會非常的大。而RoaringBitMap是直接將元數據進行存儲壓縮,其準確率是100%的。
實驗結果表明:RoaringBitMap對300個游戲集合的開銷僅為0.5KB,比直接用intset(1.23KB)還小,是該業務場景下的首選。所以下文我們來著重分析下RoaringBitMap為什么為如此高效。
2.3.1 數據結構
每個RoaringBitMap中都包含一個RoaringArray,存儲了全部的數據,其結構如下:
short[] keys;
Container[] values;
int sizer;
它的思路是將32位無符號整數按照高16位分桶(container),并做為key存儲到short[] keys中,最多能存儲2^16 = 65536 個桶(container)。存儲數據時按照數據的高16位找到container,再將低16位放入container中,也就是Container[] values。size則表示了當前keys和values中有效數據的數量。為了方便理解,下圖展示了三個container:
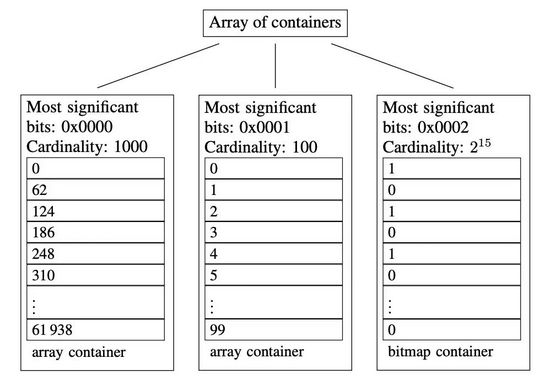
圖片引用自: https://arxiv.org
- 高16位為0000H的container,存儲有前1000個62的倍數。
- 高16位為0001H的container,存儲有[2^16, 2^16+100)區間內的100個數。
- 高16位為0002H的container,存儲有[2×2^16, 3×2^16)區間內的所有偶數,共215個。
當然該數據結構的細節不是我們關注的重點,有興趣的同學可以去查閱相關資料學習。現在我們來分析一下在推薦業務中RoaringBitMap是如何幫助我們節省開銷的。RoaringBitMap中的container分為ArrayContainer,BitmapContainer 和 RunContainer 但其壓縮方式主要分為兩種,姑且就稱為可變長度壓縮和固定長度壓縮, 這兩種方式在不同的場景下有不同的應用。
2.3.2 壓縮方式與思考
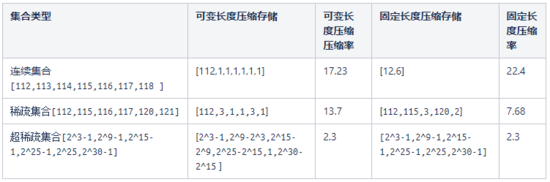
假設兩串數字集合 [112,113,114,115,116,117,118 ], [112, 115, 116, 117, 120, 121]使用可變長度壓縮可以記錄為:
- 112,1,1,1,1,1,1 使用的字節大小為 7bit + 6bit = 13bit, 壓縮率為 (7 * 32 bit) / 13 bit = 17.23
- 112,3,1,1,3,1 使用的字節大小為 7bit + 2bit + 1bit + 1bit + 2bit + 1bit = 14bit, 壓縮率為(6 * 32bit)/ 14 = 13.7
使用固定長度壓縮可以記錄為:
- 112, 6,使用的字節大小為 7bit + 3bit = 10bit , 壓縮率為(7 * 32bit)/ 10bit = 22.4
- 112, 115, 3, 120,2 使用的字節大小為 7bit + 7bit + 2bit + 7bit + 2bit = 25bit,壓縮率為(6 * 32bit)/ 25 = 7.68
顯然稀疏排列對于兩種壓縮方式都有影響,可變長度壓縮適合于稀疏分布的數字集合,固定長度壓縮合于連續分布的數字集合。但在過于稀疏的情況下,即使是可變長度壓縮方式也不好使。
假設集合存儲范圍是Interger.MaxValue,現在要存儲數字集合是[ 2^3 - 1 , 2^9 - 1 , 2^15 -1 , 2^25 - 1 , 2^25 , 2^30 -1 ]這6個數。使用可變長壓縮方式表示為: 2^3 -1 , 2^9 - 2^3 , 2^15 - 2^9 , 2^25 - 2^15 , 1 , 2^30 - 2^ 15 使用字節大小 3bit + 9bit +15bit + 25bit + 1bit + 30bit = 83bit, 壓縮率為 6 * 32 bit / 83 = 2.3。
這個壓縮率和固定長度壓縮方式無異,均為極限情況下對低位整數進行壓縮,無法利用偏移量壓縮來提高壓縮效率。
2.3.3 業務分析
更為極端的情下對于數據集合[ 2^25 - 1 , 2^26 - 1 , 2^27 - 1 , 2^28 - 1 , 2^29 - 1 , 2^30 - 1 ], RoaringBitMap壓縮后只能做到 25 + 26 + 27 + 28 + 29 + 30 = 165bit, 壓縮率為 6 * 32 / 165 = 1.16 就更別說加上組件數據結構,位數對齊,結構體消耗,指針大小等開銷了。在特別稀疏的情況下,用RoaringBitMap效果可能還更差。
但對于游戲業務來說游戲總量就10000多款,其標識appId一般都是自增主鍵,隨機性很小,分布不會特別稀疏,理論上是可以對數據有個很好的壓縮。同時使用RoaringBitMap存儲Redis本身采用的bit,不太受Redis本身數據結構的影響,能省下不少額外的空間。
三、總結
在文章中我們探討了在過濾去重的業務中,使用Redis存儲的情況下,利用intset,bloom filter 和 RoaringBitMap這三種數據結構保存整數型集合的開銷。
其中傳統的bloom filter 方式由于對準確率的要求以及短id映射空間節省有限的不足,使得該結構在游戲推薦場景中反而增加了存儲開銷,不適合在該業務場景下存儲數據。而intset結構雖然能滿足業務需求,但其使用的空間復雜度并不是最優的,還有優化的空間。
最終我們選擇了RoaringBitMap這個結構進行存儲,這是因為游戲推薦業務保存的過濾集合中,游戲id在大趨勢上是自增整數型的,且排列不是十分稀疏,利用RoaringBitMap的壓縮特性能很好的節省空間開銷。我們隨機抽選300個游戲的id集合進行測試,結合表格可以看到,相比于intset結構使用的1.23KB空間,RoaringBitMap僅使用0.5KB的大小,壓縮率為2.4。

對于Redis這種基于內存的數據庫來說,使用適當的數據結構提升存儲效率其收益是巨大的:不僅大大節約了硬件成本,同時減少了fork阻塞線程與單次調用的時延,對系統性能的提升是十分顯著的,因此在該場景下使用RoaringBitMap是十分合適的。





















