













BIO、NIO 到多路復用的演進路徑,你明白了嗎?
從 NIO 到 Netty
IO 是編程中一個重要的概念,不論是數據存儲和網絡通信,底層都是會用到,理解 IO 對面試和工作都有很大的幫助,也能從基礎理論層面扎實基礎,理解其上層應用就簡單的多了。在常用的軟件中,例如 Nginx、Redis、Dubbo、Kafka 都涉及到了 NIO 的一些基礎知識,本文就從簡單的 IO 開始剖析,從 BIO 到 NIO 再到 Netty,從理論到實踐進行深入的理解。
計算機組成
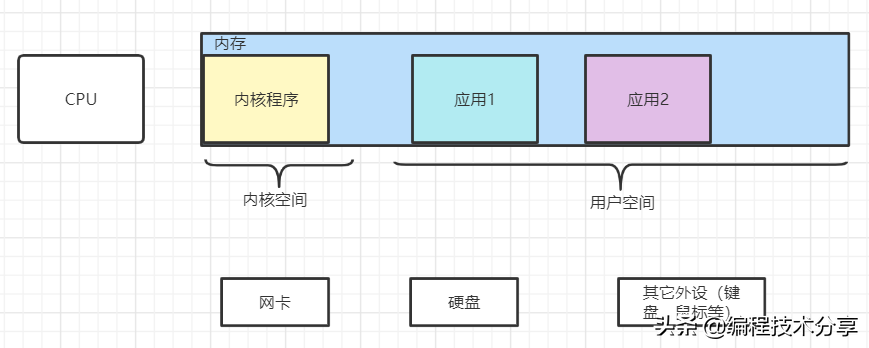
計算機的組成包括 CPU、內存存儲、網卡、磁盤存儲和其它外部設備。在 Linux 操作系統中,一切皆文件(即文件描述符 fd,file descriptor),在服務啟動時,會加載內核程序到 CPU 中運行。為了保證服務的正常運行,內核程序具有較高的優先級,所占用的空間為內核空間,其它應用程序所占用的空間為用戶空間。以 Java 程序為例來講,其也是一個程序并且占用一定的內存空間,在應用運行過程中,如果有 IO 操作或者計算需求,則需要將其轉交給內核程序來完成。因為內核(kernel)保護模式的存在,應用程序是沒有權限調用 CPU 的,一切的操作都需要通過內核程序來完成,只有這樣才能保證一旦應用程序錯誤,內核程序不會受影響,整個系統就沒有宕機的風險。
內核程序和應用程序之間通過中斷(通常的有 80 中斷)來完成操作的切換,應用系統通過內核程序提供的系統調用(System Call,是一系列的系統操作函數,是內核系統暴露出來的 API)來實現對 CPU 或 IO 的操作,CPU 通過 FCFS(非搶占式的先來先服務算法)分配各個任務的時間片,來實現各個任務并發運算。在 Java 的多線程應用中,有個上下文切換的概念,這就是應用線程將任務切換到內核線程,在 CPU 的時間片內繼續進行操作,完成操作后將內核線程切換到應用線程。
進程是系統分配資源的基本單位,線程是 cpu 執行調度的基本單位,線程也稱之為輕量級的進程(LWP)。java 的線程就是通過內核的系統調用,在操作系統中獲取到的輕量級進程。
阻塞與非阻塞/同步與異步
這里線說一下小編理解的阻塞與非阻塞以及同步和異步的概念:
阻塞和非阻塞描述的是用戶線程調用內核 IO 操作的方式,阻塞是發起調用后需要等待直至內核給出結果數據是否可讀可寫,非阻塞是發起用調用后無需等待結果,給出狀態值-1 表示正在處理。
同步和異步描述的是用戶線程和內核的交互數據的方式,同步是需要用戶線程自己獲取數據,即使是多路復用器也是解決了阻塞的問題,還需要用戶線程自己獲取數據,依舊是同步 IO 模型。而異步是用戶線程發起調用后不需要主動獲取數據,而是內核處理完畢后將數據放入用戶空間中再通知用戶線程繼續業務處理。
在常見 socket 編程中,如下所示:
//把Socket服務端啟動
ServerSocket server = new ServerSocket(8986);
while (true) {
// 阻塞方法,等待客戶端的接入
Socket client = server.accept();
// 得到輸入流
InputStream input = client.getInputStream();
// 建立緩沖區
byte[] buff = new byte[4096];
int len = input.read(buff);
// 只要一直有數據寫入,len就會一直大于0
if (len > 0) {
String msg = new String(buff, 0, len);
System.out.println("收到" + msg);
}
}
在操作系統中運行使,如何監聽其操作系統級別的指令呢?首先需要將創建 java 文件
# 創建 java 文件
Bio001Test.java
# 然后使用 javac 命令編譯成 Bio001Test.class
javac Bio001Test.java
# 執行java 代碼
java Bio001Test
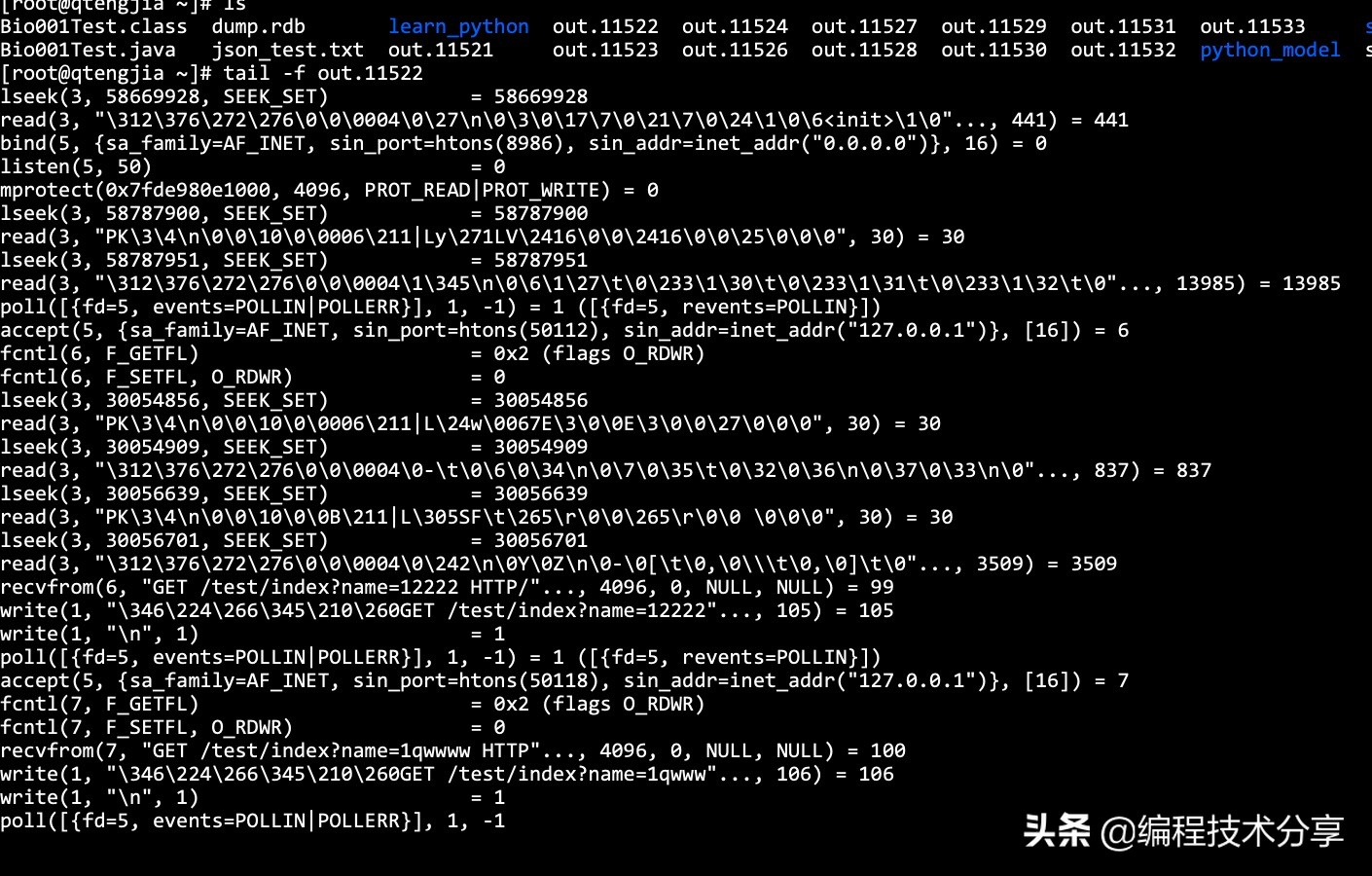
# 使用 strace 命令進行監聽系統調用的情況,其底層是使用內核的ptrace 特性來實現的
strace -ff -o out java Bio001Test
下圖是 java 代碼打印出的信息,顯示了 http 的請求記錄:
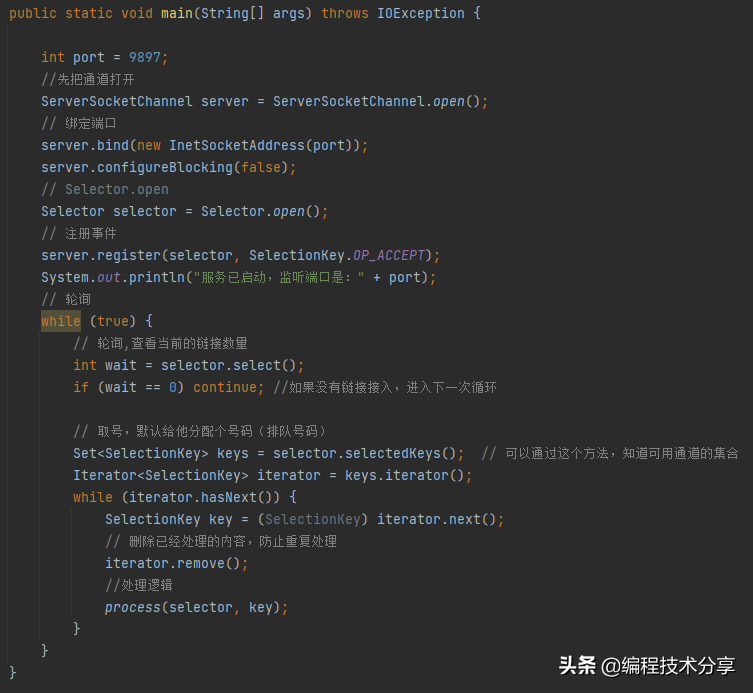
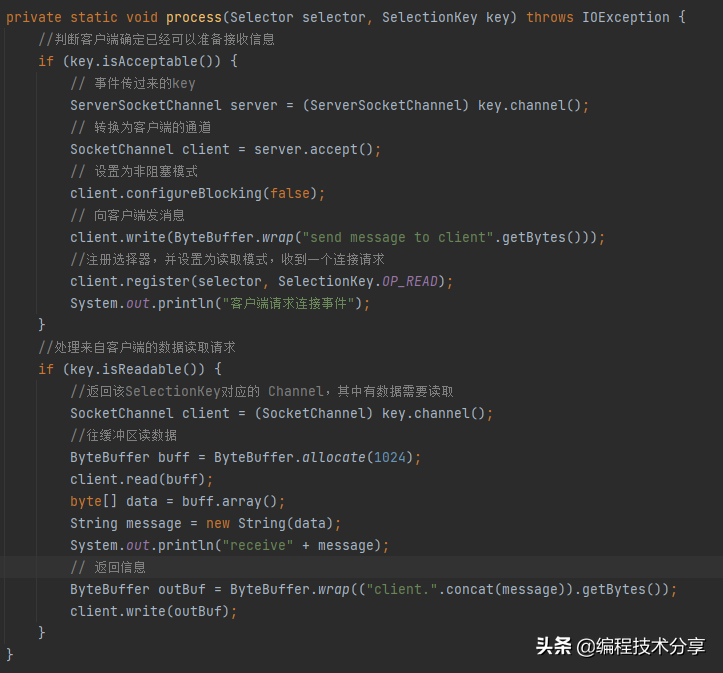
相比 BIO 的代碼, NIO 的代碼就比較復雜了,BIO 是阻塞的,NIO 是非阻塞的, BIO 是面向流的,只能單向讀寫,NIO 是面向緩沖的, 可以雙向讀寫。
# bio 的阻塞方法
server.accept()
# nio 的非阻塞方法,提出 channel selector buffer 的概念來解決io,利用事件注冊狀態來處理請求信息
selecter.select()
使用 man socket 來查看操作系統中 socket 傳入的參數,如下所示:
# 操作系統的函數都是 C 語言編寫的,java 也是類C 的語言
socket()
# 創建一個用于通信的文件描述符
creates an endpoint for communication and returns a descriptor.
...
# 設置非阻塞參數項
SOCK_NONBLOCK
Set the O_NONBLOCK file status flag on the new open file description. Using this flag saves extra calls to fcntl(2) to achieve the same result.
socket 稱之為套接字、或者插座,屬于網絡應用程序接口。即是應用層到傳輸層的接口,也是用戶進程與系統內核交互的接口。一個 TCP 連接的標記為四元組,即源 ip:源 port + 目標 ip:目標 port, 我們都知道計算機的端口范圍為 0-65535,也就是說一個客戶端最多可以向目標服務器發起 65535 個連接。
BIO 的模型
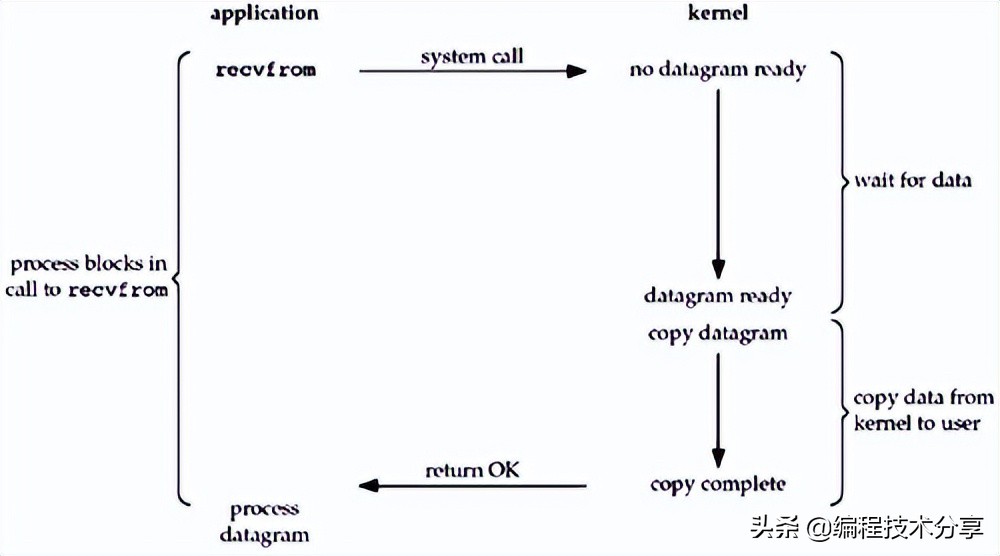
當應用發起調用后,在 kernel 沒有準備好數據之前,應用進程一直會阻塞 block 進入等待階段,當 kernel 準備好數據之后,才會返回數據,此時應用進程阻塞解除。
NIO 的模型
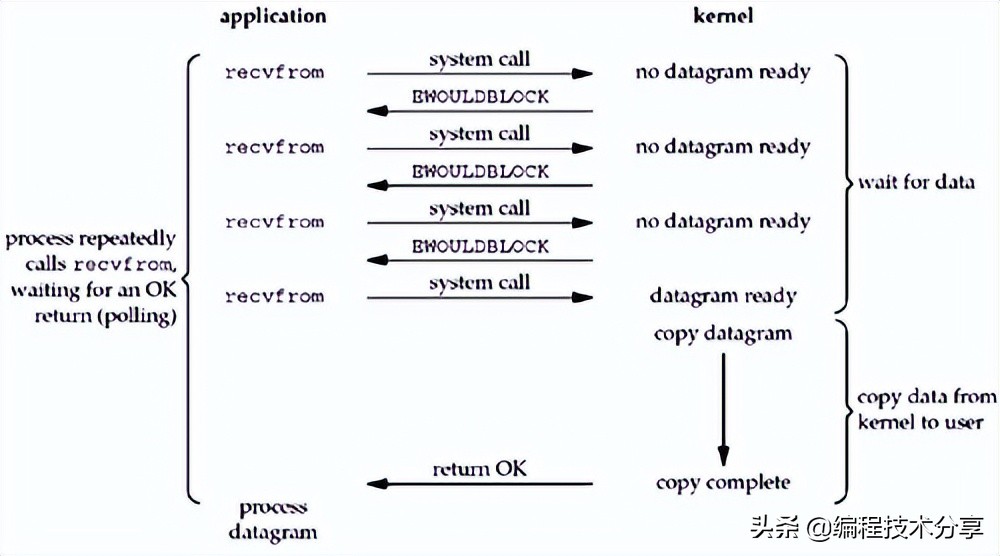
因為 kernel 是阻塞的,在引入了 nio 之后,在應用發起調用后會立即返回結果-1,代表內核尚未準備好數據,應用進程無需等待,可以輪詢查看結果,直到數據準備好為止,此時應用進程阻塞獲取數據。
多路復用器
即便是 nio 解決了阻塞的問題,但是無效的輪詢會造成 cpu 空轉,浪費資源,使用 IO 多路復用技術,當內核將數據準備好之后,通知應用進程來獲取數據,就解決了這個問題,根據其操作的方式不同,分為 select/poll/epoll 三種多路復用器。 由內核 kernel 監控所有的 socket 當數據準備好之后,發起系統調用,即 system call 將數據從內核拷貝到用戶進程。
所以,I/O 多路復用的特點是通過一種機制一個進程能同時等待多個文件描述符,而這些文件描述符(套接字描述符)其中的任意一個進入讀就緒狀態,select()函數就可以返回。
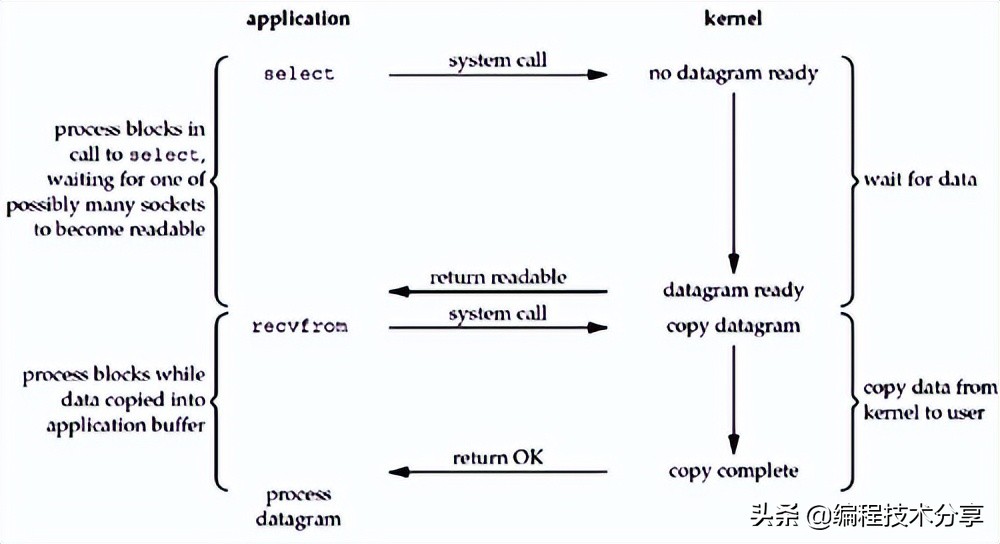
I/O 多路復用的優勢是:同時處理多個連接請求。
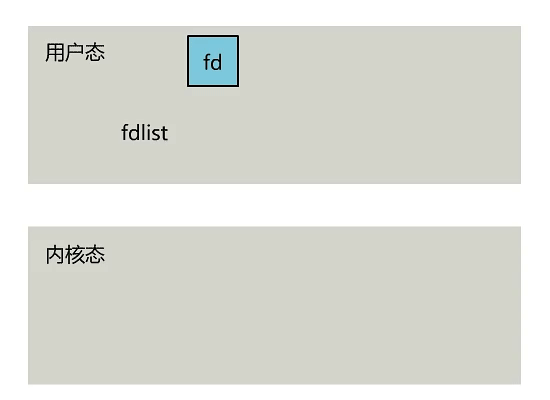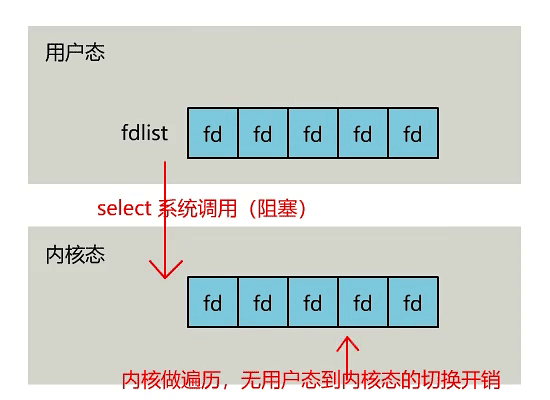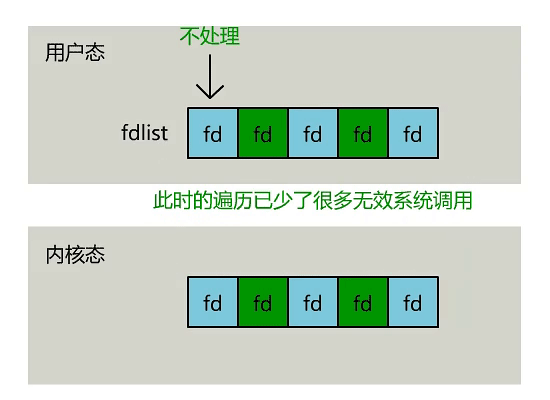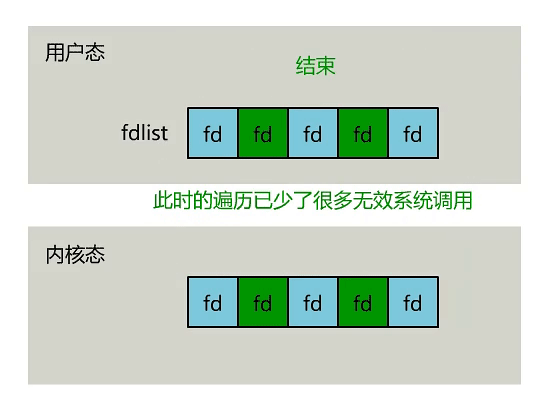
select 是操作系統提供的系統調用函數,通過它,可以把一個文件描述符的數組發給操作系統, 讓操作系統去遍歷,確定哪個文件描述符可以讀寫, 然后告訴我們去處理:
select 是操作系統提供的調用函數,通過這個函數可以把一組 fd 傳給操作系統,操作系統遍歷 fd,將完成準備的文件描述符個數返回給用戶線程,用戶線程再去逐個遍歷 fd 查看哪個 fd 已經處于就緒的狀態,然后再去處理。
select 的特點如下:
- 用戶需要將監聽的 fd list 傳入到操作系統內核中,內核來完成遍歷操作并將解決返回,這樣在高并發場景數組的復制操作下會過多的消耗資源。select 的這一操作僅解決了系統的上下文切換的開銷,遍歷數組是依舊存在的。select 返回結果是就緒的 fd 個數,用戶線程還需要判斷哪個 fd 處于就緒狀態。
- select 可以傳入一組 socket 然后等待內核的處理結果,但是其 list 大小只有 1024 個,每次調用 select 都需要將 fd 數組從用戶態復制到內核態,其開銷比較大。調用 select 后返回的是就緒 fd 數量,還需要用戶再次遍歷。
針對 select 的缺點,poll 為了增加單次監聽 socket 的個數,采用了鏈表的結構,放棄了數組的結構,但是其核心需要遍歷的缺點依然沒有解決。
針對 select 和 poll 的缺點,epoll 應運而生,其核心主要包括三個方法:
# 在內核開辟一個區域用來存放需要監聽的fd
epoll_create
# 向內核中添加、修改、刪除需要監控的fd
epoll_ctl
# 返回已經就緒的fd
epoll_wait
核心如下:
- 內核中存儲了一份文件描述符 fd 的集合,無需用戶每次都從用戶態傳入,只需要告訴內核修改的部分就可以。
- 內核中不再通過輪詢的方式找到就緒的文件描述符 fd,而是通過異步 IO 事件進行喚醒。
- 內核會將有 IO 事件發生的文件描述符 fd 返回給用戶,用戶不需要自己進行遍歷。
epoll 的數據操作有兩種模式:水平模式 LT(level trigger)和邊緣模式 ET(edge trigger)。LT 是 epoll 的默認操作模式
- LT 模式: epollwait 函數檢測到有事件發生時需要通知應用程序,但是應用程序不一定及時進行處理,當 epollwait 函數再次檢測到該事件的時還會通知應用程序,直到事件被處理。可以理解為 mq 發送消息的 at least once 模型。
- ET 模式:epollwait 函數檢測到事件發生只會通知應用程序一次,后續 epollwait 函數將不再監控該事件。因此 ET 模式降低了同一個事件被 epoll 觸發的次數,效率比 LT 模式高。可以理解為 mq 發送消息的 exactly once 模型。

IO 多路復用方式有 select,poll 以及 epoll,該函數都是內核層面的,從 BIO 的代碼中可以看到 accept 函數,從之前的分析可以知道該方法是阻塞的,
Netty 實戰
大家都可能注意到了,在實際的操作中 NIO 的代碼是比較復雜的,Netty 就是對 NIO 做了包裝,保證在實際操作中方便使用。 針對 Server 端的代碼如下:
//Netty的Reactor線程池,初始化了一個NioEventLoop數組,用來處理I/O操作,如接受新的連接和讀/寫數據
EventLoopGroup boss = new NioEventLoopGroup(1);
EventLoopGroup work = new NioEventLoopGroup(8);
try {
//用于啟動NIO服務
ServerBootstrap serverBoot = new ServerBootstrap();
serverBoot.group(boss, work)
//通過工廠方法設計模式實例化一個channel
.channel(NioServerSocketChannel.class)
//設置監聽端口
.localAddress(new InetSocketAddress(port))
// 設置 server 端的一些參數項
.childOption(ChannelOption.CONNECT_TIMEOUT_MILLIS,30000)
.childOption(ChannelOption.MAX_MESSAGES_PER_READ,16)
.childOption(ChannelOption.WRITE_SPIN_COUNT,16)
// 設置監聽的處理 channel initializer
.childHandler(new AppServerChannelInitializer());
//綁定服務器,該實例將提供有關IO操作的結果或狀態的信息
ChannelFuture channelFuture = serverBoot.bind().sync();
System.out.println("在" + channelFuture.channel().localAddress() + "上開啟監聽");
//阻塞操作,closeFuture()開啟了一個channel的監聽器(這期間channel在進行各項工作),直到鏈路斷開
channelFuture.channel().closeFuture().sync();
} catch (Exception e) {
log.error("encounter exception and detail is {}", e.getMessage());
} finally {
boss.shutdownGracefully().sync();//關閉EventLoopGroup并釋放所有資源,包括所有創建的線程
work.shutdownGracefully().sync();//關閉EventLoopGroup并釋放所有資源,包括所有創建的線程
}
一般情況下 IO 的壓力都是在服務端,默認情況下客戶端也是采用的 BIO,除非是在客戶端也是需要提供服務。
// 配置相應的參數,提供連接到遠端的方法
// I/O線程池
EventLoopGroup group = new NioEventLoopGroup();
try {
//客戶端輔助啟動類
Bootstrap bs = new Bootstrap();
bs.group(group)
//實例化一個Channel
.channel(NioSocketChannel.class)
.remoteAddress(new InetSocketAddress(host, port))
//通道初始化配置
.handler(new AppClientChannelInitializer());
//連接到遠程節點;等待連接完成
ChannelFuture future = bs.connect().sync();
//發送消息到服務器端,編碼格式是utf-8
future.channel().writeAndFlush(Unpooled.copiedBuffer("Hello World", CharsetUtil.UTF_8));
//阻塞操作,closeFuture()開啟了一個channel的監聽器(這期間channel在進行各項工作),直到鏈路斷開
future.channel().closeFuture().sync();
} finally {
group.shutdownGracefully().sync();
}
總結
IO 從開始的瓶頸就是在操作系統的 read 數據讀取方法,由于這個阻塞的方法導致了 BIO 的產生,為了解決阻塞 IO 的問題,同時提高效率,就產生了使用多線程技術操作 IO 來提升性能,但是 IO 的瓶頸問題并沒有解決。后來操作系統做出了改變,提供了非阻塞的 read 函數,這樣應用程序在發起調用后不需要等待解決,而是采用輪詢的方式查詢數據有沒有準備好,這樣相比 BIO 在同一時間內就可以完成更多的 fd 操作,這就是 NIO。但是在高并發的場景下,對文件描述符的遍歷和讀取帶來了更多的輪詢操作,額外增加的系統調用增加了 cpu 的負擔,并沒有帶來期望的性能提升。
后來操作系統做出了改進,將遍歷文描述符的操作放進了內核來實現,這就是 IO 多路復用技術。多路復用的技術分為三個函數, select、poll 和 epoll。 poll 解決了 select 單次傳入文件描述符的限制,但是沒有解決客戶端遍歷查詢文件描述符的問題,epoll 的產生解決了這個問題,只是將數據準備好的 fd 返回給客戶端,減少了客戶端的遍歷操作。IO 模型的演進也是根據應用的需求而升級,倒逼操作系統的內核增加更多的提升性能的操作。





















