













作者 | 丕天
Redis是目前最受歡迎的kv類數據庫,當然它的功能越來越多,早已不限定在kv場景,消息隊列就是Redis中一個重要的功能。
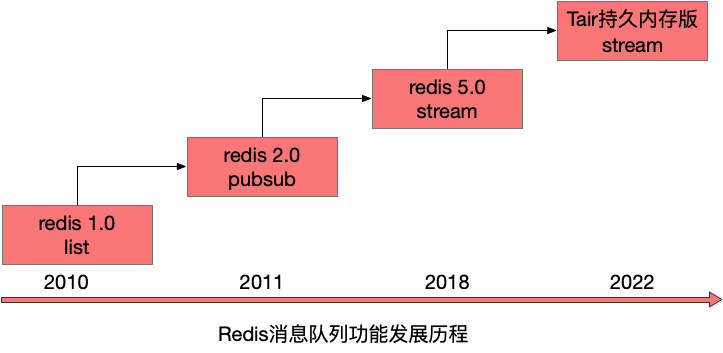
Redis從2010年發布1.0版本就具備一個消息隊列的雛形,隨著10多年的迭代,其消息隊列的功能也越來越完善,作為一個全內存的消息隊列,適合應用與要求高吞吐、低延時的場景。
我們來盤一下Redis消息隊列功能的發展歷程,歷史版本有哪些不足,后續版本是如何來解決這些問題的。
一、Redis 1.0 list
從廣義上來講消息隊列就是一個隊列的數據結構,生產者從隊列一端放入消息,消費者從另一端讀取消息,消息保證先入先出的順序,一個本地的list數據結構就是一個進程維度的消息隊列,它可以讓模塊A寫入消息,模塊B消費消息,做到模塊A/B的解耦與異步化。但想要做到應用級別的解耦和異步還需要一個消息隊列的服務。
1.list的特性
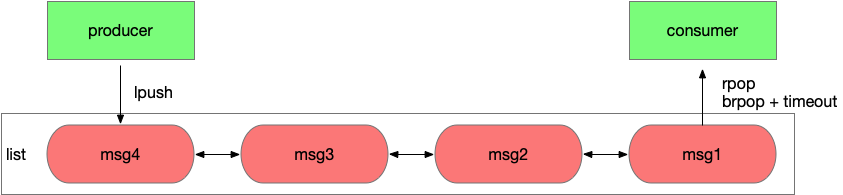
Redis 1.0發布時就具備了list數據結構,應用A可以通過lpush寫入消息,應用B通過rpop從隊列中讀取消息,每個消息只會被讀取一次,而且是按照lpush寫入的順序讀到。同時Redis的接口是并發安全的,可以同時有多個生產者向一個list中生產消息,多個消費者從list中讀取消息。
這里還有個問題,消費者要如何知道list中有消息了,需要不斷輪詢去查詢嗎。輪詢無法保證消息被及時的處理,會增加延時,而且當list為空時,大部分輪詢的請求都是無效請求,這種方式大量浪費了系統資源。好在Redis有brpop接口,該接口有一個參數是超時時間,如果list為空,那么Redis服務端不會立刻返回結果,它會等待list中有新數據后在返回或是等待最多一個超時時間后返回空。通過brpop接口實現了長輪詢,該效果等同于服務端推送,消費者能立刻感知到新的消息,而且通過設置合理的超時時間,使系統資源的消耗降到很低。
#基于list完成消息的生產和消費
#生產者生產消息msg1
lpush listA msg1
(integer) 1
#消費者讀取到消息msg1
rpop listA
"msg1"
#消費者阻塞式讀取listA,如果有數據立刻返回,否則最多等待10秒
brpop listA 10
1) "listA"
2) "msg1"
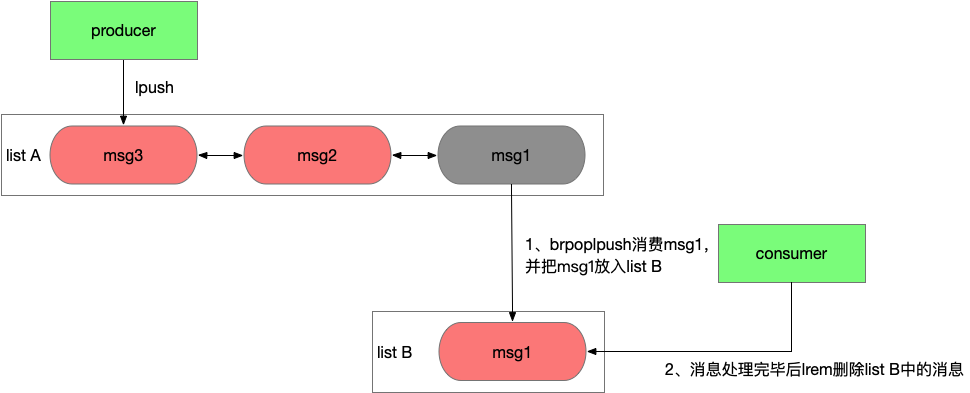
使用rpop或brpop這樣接口消費消息會先從隊列中刪除消息,然后再由應用消費,如果應用應用在處理消息前異常宕機了,消息就丟失了。但如果使用lindex這樣的只讀命令先讀取消息處理完畢后在刪除,又需要額外的機制來保證一條消息不會被其他消費者重復讀到。好在list有rpoplpush或brpoplpush這樣的接口,可以原子性的從一個list中移除一個消息并加入另一個list。
應用程序可以通過2個list組和來完成消息的消費和確認功能,使用rpoplpush從list A中消費消息并移入list B,等消息處理完畢后在從list B中刪除消息,如果在處理消息過程中應用異常宕機,恢復后應用可以重新從list B中讀取未處理的消息并處理。這種方式為消息的消費增加了ack機制。
#基于2個list完成消息消費和確認
#從listA中讀取消息并寫入listB
rpoplpush listA listB
"msg1"
#業務邏輯處理msg1完畢后,從listB中刪除msg1,完成消息的確認
lrem listB 1 msg1
(integer) 1
2.list的不足之處
通過Redis 1.0就引入的list結構我們就能實現一個分布式的消息隊列,滿足一些簡單的業務需求。但list結構作為消息隊列服務有一個很致命的問題,它沒有廣播功能,一個消息只能被消費一次。而在大型系統中,通常一個消息會被下游多個應用同時訂閱和消費,例如當用戶完成一個訂單的支付操作時,需要通知商家發貨,要更新物流狀態,可能還會提高用戶的積分和等級,這些都是不同的下游子系統,他們全部會訂閱支付完成的操作,而list一個消息只能被消費一次在這樣復雜的大型系統面前就捉襟見肘了。
可能你會說那弄多個list,生產者向每個list中都投遞消息,每個消費者處理自己的list不就行了嗎。這樣第一是性能不會太好,因為同一個消息需要被重復的投遞,第二是這樣的設計違反了生產者和消費者解耦的原則,這個設計下生產者需要知道下游有哪些消費者,如果業務發生變化,需要額外增加一個消費者,生產者的代碼也需要修改。
3.總結
優勢
模型簡單,和使用本地list基本相同,適配容易
通過brpop做到消息處理的實時性
通過rpoplpush來聯動2個list,可以做到消息先消費后確認,避免消費者應用異常情況下消息丟失
不足
消息只能被消費一次,缺乏廣播機制
二、Redis 2.0 pubsub
list作為消息隊列應用場景受到限制很重要的原因在于沒有廣播,所以Redis 2.0中引入了一個新的數據結構pubsub。pubsub雖然不能算作是list的替代品,但它確實能解決一些list不能解決的問題。
1.pubsub特性
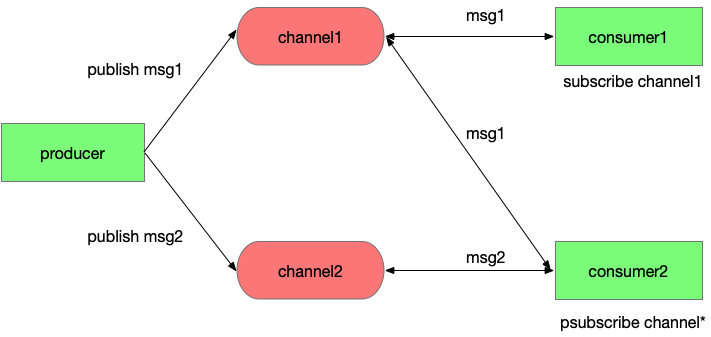
pubsub引入一個概念叫channel,生產者通過publish接口投遞消息時會指定channel,消費者通過subscribe接口訂閱它關心的channel,調用subscribe后這條連接會進入一個特殊的狀態,通常不能在發送其他請求,當有消息投遞到這個channel時Redis服務端會立刻通過該連接將消息推送到消費者。這里一個channel可以被多個應用訂閱,消息會同時投遞到每個訂閱者,做到了消息的廣播。
另一方面,消費者可以會訂閱一批channel,例如一個用戶訂閱了浙江的新聞的推送,但浙江新聞還會進行細分,例如“浙江杭州xx”、“浙江溫州xx”,這里訂閱者不需要獲取浙江的所有子類在挨個訂閱,只需要調用psubscribe“浙江*”就能訂閱所有以浙江開頭的新聞推送了,這里psubscribe傳入一個通配符表達的channel,Redis服務端按照規則推送所有匹配channel的消息給對應的客戶端。
#基于pubsub完成channel的匹配和消息的廣播
#消費者1訂閱channel1
subscribe channel1
1) "subscribe"
2) "channel1"
3) (integer) 1
#收到消息推送
1) "message"
2) "channel1"
3) "msg1"
#消費者2訂閱channel*
psubscribe channel*
1) "psubscribe"
2) "channel*"
3) (integer) 1
#收到消息推送
1) "pmessage"
2) "channel*"
3) "channel1"
4) "msg1"
1) "pmessage"
2) "channel*"
3) "channel2"
4) "msg2"
#生產者發布消息msg1和msg2
publish channel1 msg1
(integer) 2
publish channel2 msg2
(integer) 1
在Redfis 2.8時加入了keyspace notifications功能,此時pubsub除了通知用戶自定義消息,也可以通知系統內部消息。keyspace notifications引入了2個特殊的channel分別是__keyevent@__:和__keyspace@__:,通過訂閱__keyevent客戶端可以收到某個具體命令調用的回調通知,通過訂閱__keyspace客戶端可以收到目標key的增刪改操作以及過期事件。使用這個功能還需要開啟配置notify-keyspace-events。
#通過keyspace notifications功能獲取系統事件
#寫入請求
set testkey v EX 1
#訂閱key級別的事件
psubscribe __keyspace@0__:testkey
1) "psubscribe"
2) "__keyspace@0__:testkey"
3) (integer) 1
#收到通知
1) "pmessage"
2) "__keyspace@0__:testkey"
3) "__keyspace@0__:testkey"
4) "set"
1) "pmessage"
2) "__keyspace@0__:testkey"
3) "__keyspace@0__:testkey"
4) "expire"
1) "pmessage"
2) "__keyspace@0__:testkey"
3) "__keyspace@0__:testkey"
4) "expired"
#訂閱所有的命令事件
psubscribe __keyevent@0__:*
1) "psubscribe"
2) "__keyevent@0__:*"
3) (integer) 1
#收到通知
1) "pmessage"
2) "__keyevent@0__:*"
3) "__keyevent@0__:set"
4) "testkey"
1) "pmessage"
2) "__keyevent@0__:*"
3) "__keyevent@0__:expire"
4) "testkey"
1) "pmessage"
2) "__keyevent@0__:*"
3) "__keyevent@0__:expired"
4) "testkey"
2.pubsub的不足之處
pubsub既能單播又能廣播,還支持channel的簡單正則匹配,功能上已經能滿足大部分業務的需求,而且這個接口發布的時間很早,在2011年Redis 2.0發布時就已經具備,用戶基礎很廣泛,所以現在很多業務都有用到這個功能。但你要深入了解pubsub的原理后,是肯定不敢把它作為一個一致性要求較高,數據量較大系統的消息服務的。
首先,pubsub的消息數據是瞬時的,它在Redis服務端不做保存,publish發送到Redis的消息會立刻推送到所有當時subscribe連接的客戶端,如果當時客戶端因為網絡問題斷連,那么就會錯過這條消息,當客戶端重連后,它沒法重新獲取之前那條消息,甚至無法判斷是否有消息丟失。
其次,pubsub中消費者獲取消息是一個推送模型,這意味著Redis會按消息生產的速度給所有的消費者推送消息,不管消費者處理能力如何,如果消費者應用處理能力不足,消息就會在Redis的client buf中堆積,當堆積數據超過一個閾值后會斷開這條連接,這意味著這些消息全部丟失了,在也找不回來了。如果同時有多個消費者的client buf堆積數據但又還沒達到斷開連接的閾值,那么Redis服務端的內存會膨脹,進程可能因為oom而被殺掉,這導致了整個服務中斷。
3.總結
優勢
- 消息具備廣播能力
- psubscribe能按字符串通配符匹配,給予了業務邏輯的靈活性
- 能訂閱特定key或特定命令的系統消息
不足
- Redis異常、客戶端斷連都會導致消息丟失
- 消息缺乏堆積能力,不能削峰填谷。推送的方式缺乏背壓機制,沒有考慮消費者處理能力,推送的消息超過消費者處理能力后可能導致消息丟失或服務異常
三、Redis 5.0 stream
消息丟失、消息服務不穩定的問題嚴重限制了pubsub的應用場景,所以Redis需要重新設計一套機制,來解決這些問題,這就有了后來的stream結構。
1.stream特性
一個穩定的消息服務需要具備幾個要點,要保證消息不會丟失,至少被消費一次,要具備削峰填谷的能力,來匹配生產者和消費者吞吐的差異。在2018年Redis 5.0加入了stream結構,這次考慮了list、pubsub在應用場景下的缺陷,對標kafka的模型重新設計全內存消息隊列結構,從這時開始Redis消息隊列功能算是能和主流消息隊列產品pk一把了。
stream的改進分為多個方面
成本:
- 存儲message數據使用了listpack結構,這是一個緊湊型的數據結構,不同于list的雙向鏈表每個節點都要額外占用2個指針的存儲空間,這使得小msg情況下stream的空間利用率更高。
功能:
- stream引入了消費者組的概念,一個消費者組內可以有多個消費者,同一個組內的消費者共享一個消息位點(last_delivered_id),這使得消費者能夠水平的擴容,可以在一個組內加入多個消費者來線性的提升吞吐,對于一個消費者組,每條msg只會被其中一個消費者獲取和處理,這是pubsub的廣播模型不具備的。
- 不同消費者組之前是相互隔離的,他們各自維護自己的位點,這使得一條msg能被多個不同的消費者組重復消費,做到了消息廣播的能力。
- stream中消費者采用拉取的方式,并能設置timeout在沒有消息時阻塞,通過這種長輪詢機制保證了消息的實時性,而且消費速率是和消費者自身吞吐相匹配。
消息不丟失:
- stream的數據會存儲在aof和rdb文件中,這使Redis重啟后能夠恢復stream的數據。而pubsub的數據是瞬時的,Redis重啟意味著消息全部丟失。
- stream中每個消費者組會存儲一個last_delivered_id來標識已經讀取到的位點,客戶端連接斷開后重連還是能從該位點繼續讀取,消息不會丟失。
- stream引入了ack機制保證消息至少被處理一次。考慮一種場景,如果消費者應用已經讀取了消息,但還沒來得及處理應用就宕機了,對于這種已經讀取但沒有ack的消息,stream會標示這條消息的狀態為pending,等客戶端重連后通過xpending命令可以重新讀取到pengind狀態的消息,繼續處理。如果這個應用永久宕機了,那么該消費者組內的其他消費者應用也能讀取到這條消息,并通過xclaim命令將它歸屬到自己下面繼續處理。
#基于stream完成消息的生產和消費,并確保異常狀態下消息至少被消費一次
#創建mystream,并且創建一個consumergroup為mygroup
XGROUP CREATE mystream mygroup $ MKSTREAM
OK
#寫入一條消息,由redis自動生成消息id,消息的內容是一個kv數組,這里包含field1 value1 field2 value2
XADD mystream * field1 value1 field2 value2
"1645517760385-0"
#消費者組mygroup中的消費者consumer1從mystream讀取一條消息,>表示讀取一條該消費者組從未讀取過的消息
XREADGROUP GROUP mygroup consumer1 COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) "1645517760385-0"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
#消費完成后ack確認消息
xack mystream mygroup 1645517760385-0
(integer) 1
#如果消費者應用在ack前異常宕機,恢復后重新獲取未處理的消息id。
XPENDING mystream mygroup - + 10
1) 1) "1645517760385-0"
2) "consumer1"
3) (integer) 305356
4) (integer) 1
#如果consumer1永遠宕機,其他消費者可以把pending狀態的消息移動到自己名下后繼續消費
#將消息id 1645517760385-0移動到consumer2下
XCLAIM mystream mygroup consumer2 0 1645517760385-0
1) 1) "1645517760385-0"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
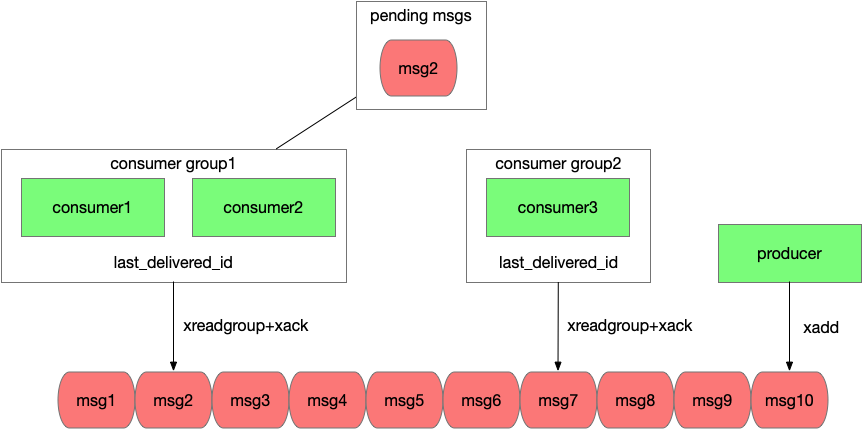
Redis stream保證了消息至少被處理一次,但如果想做到每條消息僅被處理一次還需要應用邏輯的介入。
消息被重復處理要么是生產者重復投遞,要么是消費者重復消費。
- 對于生產者重復投遞問題,Redis stream為每個消息都設置了一個唯一遞增的id,通過參數可以讓Redis自動生成id或者應用自己指定id,應用可以根據業務邏輯為每個msg生成id,當xadd超時后應用并不能確定消息是否投遞成功,可以通過xread查詢該id的消息是否存在,存在就說明已經投遞成功,不存在則重新投遞,而且stream限制了id必須遞增,這意味了已經存在的消息重復投遞會被拒絕。這套機制保證了每個消息可以僅被投遞一次。
- 對于消費者重復消費的問題,考慮一個場景,消費者讀取消息后業務處理完畢,但還沒來得及ack就發生了異常,應用恢復后對于這條沒有ack的消息進行了重復消費。這個問題因為ack和消費消息的業務邏輯發生在2個系統,沒法做到事務性,需要業務來改造,保證消息處理的冪等性。
2.stream的不足
stream的模型做到了消息的高效分發,而且保證了消息至少被處理一次,通過應用邏輯的改造能做到消息僅被處理一次,它的能力對標kafka,但吞吐高于kafka,在高吞吐場景下成本比kafka低,那它又有哪些不足了。
首先消息隊列很重要的一個功能就是削峰填谷,來匹配生產者和消費者吞吐的差異,生產者和消費者吞吐差異越大,持續時間越長,就意味著steam中需要堆積更多的消息,而Redis作為一個全內存的產品,數據堆積的成本比磁盤高。
其次stream通過ack機制保證了消息至少被消費一次,但這有個前提就是存儲在Redis中的消息本身不會丟失。Redis數據的持久化依賴aof和rdb文件,aof落盤方式有幾種,通過配置appendfsync決定,通常我們不會配置為always來讓每條命令執行完后都做一次fsync,線上配置一般為everysec,每秒做一次fsync,而rdb是全量備份時生成,這意味了宕機恢復可能會丟掉最近一秒的數據。另一方面線上生產環境的Redis都是高可用架構,當主節點宕機后通常不會走恢復邏輯,而是直接切換到備節點繼續提供服務,而Redis的同步方式是異步同步,這意味著主節點上新寫入的數據可能還沒同步到備節點,在切換后這部分數據就丟失了。所以在故障恢復中Redis中的數據可能會丟失一部分,在這樣的背景下無論stream的接口設計的多么完善,都不能保證消息至少被消費一次。
3.總結
優勢
- 在成本、功能上做了很多改進,支持了緊湊的存儲小消息、具備廣播能力、消費者能水平擴容、具備背壓機制
- 通過ack機制保證了Redis服務端正常情況下消息至少被處理一次的能力
不足
- 內存型消息隊列,數據堆積成本高
- Redis本身rpo>0,故障恢復可能會丟數據,所以stream在Redis發生故障恢復后也不能保證消息至少被消費一次。
四、Tair持久內存版 stream
Redis stream的不足也是內存型數據庫特性帶來的,它擁有高吞吐、低延時,但大容量下成本會比較高,而應用的場景也不完全是絕對的大容量低吞吐或小容量高吞吐,有時應用的場景會介于二者之間,需要平衡容量和吞吐的關系,所以需要一個產品它的存儲成本低于Redis stream,但它的性能又高于磁盤型消息隊列。
另一方面Redis stream在Redis故障場景下不能保證消息的不丟失,這導致業務需要自己實現一些復雜的機制來回補這段數據,同時也限制了它應用在一些對一致性要求較高的場景。為了讓業務邏輯更簡單,stream應用范圍更廣,需要保證故障場景下的消息持久化。
兼顧成本、性能、持久化,這就有了Tair持久內存版。
1.Tair持久內存版特性
更大空間,更低成本
Tair持久內存版引入了Intel傲騰持久內存(下面稱作AEP),它的性能略低于內存,但相同容量下成本低于內存。Tair持久內存版將主要數據存儲在AEP上,使得相同容量下,成本更低,這使同樣單價下stream能堆積更多的消息。
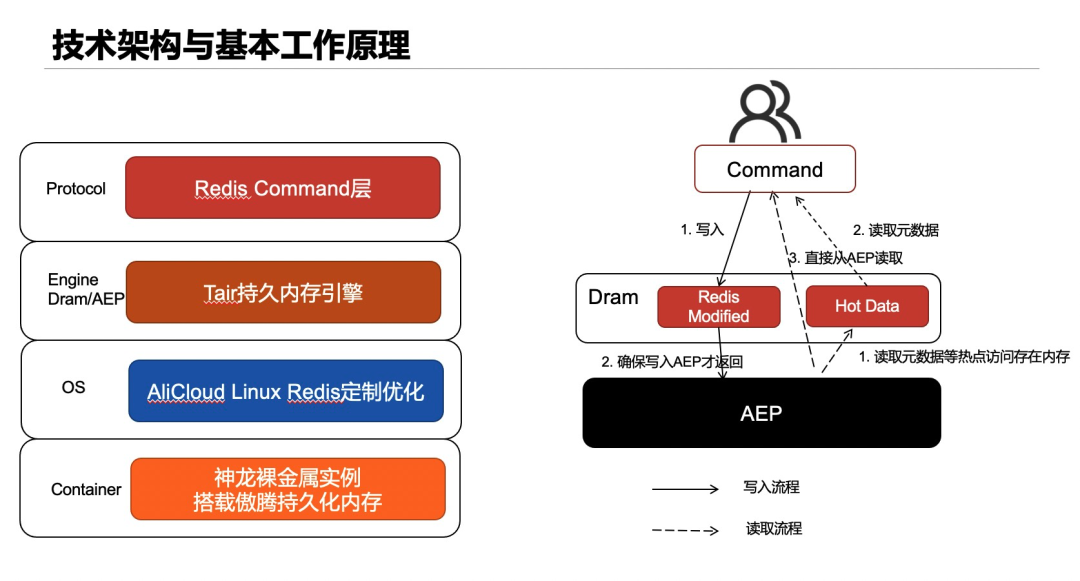
兼容社區版
Tair持久內存版兼容原生Redis絕大部分的數據結構和接口,對于stream相關接口做到了100%兼容,如果你之前使用了社區版stream,那么不需要修改任何代碼,只需要換一個連接地址就能切換到持久內存版。并且通過工具完成社區版和持久內存版數據的雙向遷移。
數據的實時持久化
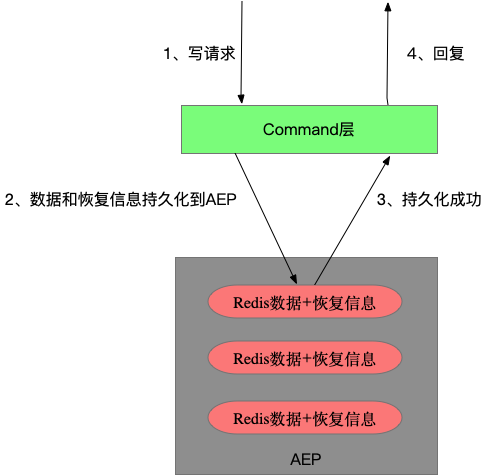
Tair持久內存版并不是簡單將Redis中的數據換了一個介質存儲,因為這樣僅能通過AEP降低成本,但沒用到AEP斷電數據不丟失的特性,對持久化能力沒有任何提升。
開源Redis通過在磁盤上記錄AppendOnlyLog來持久化數據,AppendOnlyLog記錄了所有的寫操作,相當于redolog,在宕機恢復時通過回放這些log恢復數據。但受限于磁盤介質的高延時和Redis內存數據庫使用場景下對低延時的要求,并不能在每次寫操作后fsync持久化log,最新寫入的數據可能并沒有持久化到磁盤,這也是數據可能丟失的根因。
Tair持久內存版的數據恢復沒有使用AppendOnlyLog來完成, 而是將將redis數據結構存儲在AEP上,這樣宕機后這些數據結構并不會丟失,并且對這些數據結構增加了一些額外的描述信息,宕機后在recovery時能夠讀到這些額外的描述信息,讓這些redis數據結構重新被識別和索引,將狀態恢復到宕機前的樣子。Tair通過將redis數據結構和描述信息實時寫入AEP,保證了寫入數據的實時持久化。
HA數據不丟失
Tair持久內存版保證了數據的持久化,但生產環境中都是高可用架構,多數情況下當主節點異常宕機后并不會等主節點重啟恢復,而是切換到備節點繼續提供服務,然后給新的主節點添加一個新的備節點。所以在故障發生時如果有數據還沒從主節點同步到備節點,這部分數據就會丟失。
Redis采用的異步同步,當客戶端寫入數據并返回成功時對Redis的修改可能還沒同步到備節點,如果此時主節點宕機數據就會丟失。為了避免在HA過程中數據丟失,Tair持久內存版引入了半同步機制,確保寫入請求返回成功前相關的修改已經同步到備節點。
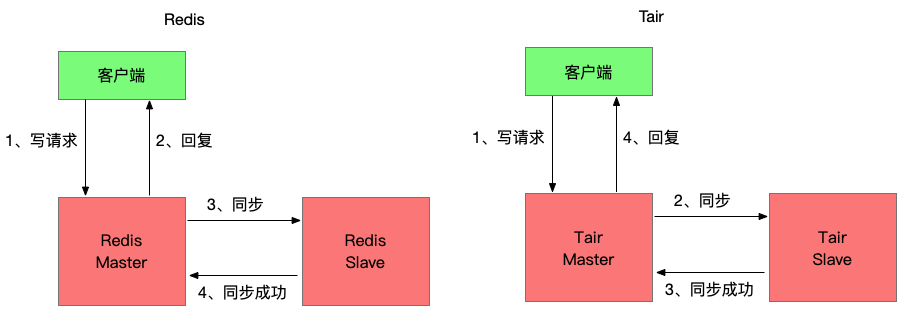
可以發現開啟半同步功能后寫入請求的RT會變高,多出主備同步的耗時,這部分耗時大概在幾十微秒。但通過一些異步化的技術,雖然寫請求的RT會變高,但對實例的最大寫吞吐影響很小。
當開啟半同步后生成者通過xadd投遞消息,如果返回成功,消息一定同步到備節點,此時發生HA,消費者也能在備節點上讀到這條消息。如果xadd請求超時,此時消息可能同步到備節點也可能沒有,生產者沒法確定,此時通過再次投遞消息,可以保證該消息至少被消費一次。如果要嚴格保證消息僅被消費一次,那么生產者可以通過xread接口查詢消息是否存在,對于不存在的場景重新投遞。
2.總結
優勢
- 引入了AEP作為存儲介質,目前Tair持久內存版價格是社區版的70%。
- 保證了數據的實時持久化,并且通過半同步技術保證了HA不丟數據,大多數情況下做到消息不丟失(備庫故障或主備網絡異常時會降級為異步同步,優先保障可用性),消息至少被消費一次或僅被消費一次。
五、未來
消息隊列主要是為了解決3類問題,應用模塊的解耦、消息的異步化、削峰填谷。目前主流的消息隊列都能滿足這些需求,所以在實際選型時還會考慮一些特殊的功能是否滿足,產品的性能如何,具體業務場景下的成本怎么樣,開發的復雜度等。
Redis的消息隊列功能并不是最全面的,它不希望做成一個大而全的產品,而是做一個小而美的產品,服務好一部分用戶在某些場景下的需求。目前用戶選型Redis作為消息隊列服務的原因,主要有Redis在相同成本下吞吐更高、Redis的延時更低、應用需要一個消息服務但又不想額外引入一堆依賴等。
未來Tair持久內存版會針對這些述求,把這些優勢繼續放大。
吞吐
通過優化持久內存版的持久化流程,讓吞吐接近內存版甚至超過內存版吞吐。
延時
通過rdma在多副本間同步數據,降低半同步下寫入數據的延時。

















