Flink on K8s 在京東的持續(xù)優(yōu)化實(shí)踐
一、基本介紹

K8s 是目前業(yè)內(nèi)非常流行的容器編排和管理平臺(tái),它可以非常簡單高效地管理云平臺(tái)中多個(gè)主機(jī)上的容器化應(yīng)用。在 2017 年左右,我們實(shí)時(shí)計(jì)算是多個(gè)引擎并存的,包括 Storm、Spark Streaming 以及正在引入的新一代計(jì)算引擎 Flink,其中 Storm 集群運(yùn)行在物理機(jī)上,Spark Streaming 運(yùn)行在 YARN 上,不同的運(yùn)行環(huán)境導(dǎo)致部署和運(yùn)營成本特別高,且資源利用有一定浪費(fèi),所以迫切需要一個(gè)統(tǒng)一的集群資源管理和調(diào)度系統(tǒng)來解決這個(gè)問題。
而 K8s 可以很好地解決這些問題:它可以很方便地管理成千上萬的容器化應(yīng)用,易于部署和運(yùn)維;很容易做到混合部署,將不同負(fù)載的服務(wù)比如在線服務(wù)、機(jī)器學(xué)習(xí)、流批計(jì)算等混合在一起,獲得更好的資源利用;此外,它還具有天然容器隔離、原生彈性自愈的能力,可以提供更好的隔離性與安全性。
經(jīng)過一系列的嘗試、優(yōu)化和性能對(duì)比后,我們選擇了 K8s。
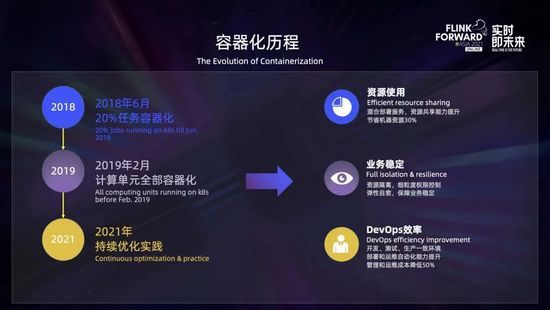
- 2018 年初,實(shí)時(shí)計(jì)算平臺(tái)開始全面容器化改造;
- 到 2018 年 6 月,已經(jīng)有 20% 的任務(wù)運(yùn)行在 K8s 上,從運(yùn)行結(jié)果看,無論是資源的共享能力、還是業(yè)務(wù)處理能力,以及敏捷性和效率方面都獲得了較大提升,初步達(dá)到了預(yù)期的效果;
- 到 2019 年 2 月實(shí)現(xiàn)了實(shí)時(shí)計(jì)算全部容器化;
- 之后直到現(xiàn)在,我們?cè)?K8s 的環(huán)境也一直在進(jìn)行優(yōu)化和實(shí)踐,比如進(jìn)行彈性伸縮、服務(wù)混部、任務(wù)快速恢復(fù)能力建設(shè)等方面的實(shí)踐。
全部 on K8s 后收益還是比較明顯的:
- 首先混合部署服務(wù)和資源共享能力獲得了提升,節(jié)省機(jī)器資源 30%;
- 其次,具有更好的資源隔離和彈性自愈能力,比較容易實(shí)現(xiàn)根據(jù)業(yè)務(wù)的負(fù)載進(jìn)行資源的彈性伸縮,保證了業(yè)務(wù)的穩(wěn)定性;
- 最后開發(fā)、測(cè)試、生產(chǎn)一致性的環(huán)境,避免環(huán)境給整個(gè)開發(fā)過程帶來問題,同時(shí)極大提升了部署和運(yùn)營自動(dòng)化的能力,降低了管理運(yùn)維的成本。

京東 Flink on K8s 的平臺(tái)架構(gòu)如上圖,最下面是物理機(jī)和云主機(jī),之上是 K8s,它采用京東自研的 JDOS 平臺(tái),基于標(biāo)準(zhǔn)的 K8s 進(jìn)行了許多定制優(yōu)化,使之更適應(yīng)我們生產(chǎn)環(huán)境的實(shí)際情況。JDOS 大部分運(yùn)行在物理機(jī)上,少部分是在云主機(jī)上。再往上是基于社區(qū)版 Flink 進(jìn)行深度定制化后的 Flink 引擎。
最上面就是京東的實(shí)時(shí)計(jì)算平臺(tái) JRC,支持 SQL 作業(yè)和 jar 包作業(yè),提供高吞吐、低延遲、高可用、彈性自愈易用的一站式海量流批數(shù)據(jù)計(jì)算能力,支持豐富的數(shù)據(jù)源和目標(biāo)源,具備完善的作業(yè)管理、配置、部署、日志監(jiān)控和自運(yùn)維的功能,提供備份回滾和一鍵遷移的功能。
我們的實(shí)時(shí)計(jì)算平臺(tái)服務(wù)于京東內(nèi)部非常多的業(yè)務(wù)線,主要應(yīng)用場(chǎng)景包括實(shí)時(shí)數(shù)倉,實(shí)時(shí)大屏、實(shí)時(shí)推薦、實(shí)時(shí)報(bào)表、實(shí)時(shí)風(fēng)控和實(shí)時(shí)監(jiān)控以及其他的應(yīng)用場(chǎng)景。目前我們的實(shí)時(shí) K8s 集群由 7000 多臺(tái)機(jī)器組成,線上 Flink 任務(wù)數(shù)有 5000 多,數(shù)據(jù)處理峰值可以達(dá)到每秒 10 億多條。
二、生產(chǎn)實(shí)踐
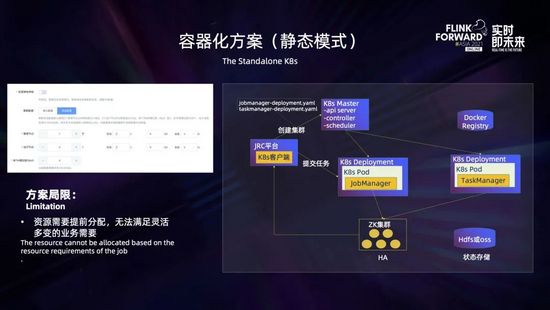
最開始容器化方案采用的是基于 K8s deployment 部署的 standalone session 集群,這是資源靜態(tài)分配的模式,如上圖所示,需要用戶在創(chuàng)建的時(shí)候就決定好所需要的管理節(jié)點(diǎn) Jobmanager 的個(gè)數(shù)和規(guī)格 (包括 CPU 的核數(shù)、內(nèi)存和磁盤的大小等)、運(yùn)行節(jié)點(diǎn) Taskmanager 的個(gè)數(shù)和規(guī)格 (包括 CPU、內(nèi)存和磁盤大小等),以及 Taskmanager 包含的 slot 個(gè)數(shù)。創(chuàng)建集群后,JRC 平臺(tái)通過 K8s 客戶端向 K8s master 發(fā)出請(qǐng)求,創(chuàng)建 Jobmanager 的 deployment,這里使用 ZK 保證高可用,使用 HDFS 和 OSS 進(jìn)行狀態(tài)存儲(chǔ),集群創(chuàng)建完成后就可以提交任務(wù)了。
但是在我們實(shí)踐的過程中發(fā)現(xiàn)該方案存在一些不足,它需要業(yè)務(wù)提前預(yù)估出所需要的資源,對(duì)業(yè)務(wù)不太友好,無法滿足靈活多變的業(yè)務(wù)場(chǎng)景。比如對(duì)一些復(fù)雜拓?fù)浠蛘咭粋€(gè)集群跑多個(gè)任務(wù)的場(chǎng)景,業(yè)務(wù)很難預(yù)先精準(zhǔn)確定出所需要資源,這時(shí)候一般都會(huì)先創(chuàng)建出一個(gè)較大的集群,這樣就會(huì)帶來一定的資源浪費(fèi)。在任務(wù)運(yùn)行的過程中,也沒有辦法根據(jù)任務(wù)的運(yùn)行情況,按需進(jìn)行資源的動(dòng)態(tài)伸縮。
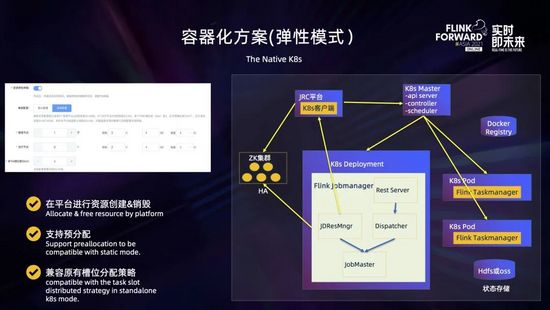
于是我們又對(duì)容器化方案進(jìn)行了升級(jí),支持彈性資源模式。這是采用資源按需分配的方式,如上圖所示,它需要用戶在創(chuàng)建時(shí)指定好所需要管理節(jié)點(diǎn) Jobmanager 的個(gè)數(shù)和規(guī)格,以及運(yùn)行節(jié)點(diǎn) Taskmanager 的規(guī)格,而 Taskmanager 的個(gè)數(shù)可以不指定。點(diǎn)擊創(chuàng)建集群后,JRC 平臺(tái)會(huì)通過 K8s 客戶端向 K8s master 發(fā)出請(qǐng)求,創(chuàng)建 Jobmanager 的 deployment 以及可選地預(yù)創(chuàng)建指定數(shù)量 Taskmanager 的 pod。
平臺(tái)提交任務(wù)后,由 JobMaster 通過 JDResourceManager 向 JRC 平臺(tái)發(fā)出申請(qǐng)資源的 rest 請(qǐng)求,然后平臺(tái)向 K8s master 動(dòng)態(tài)申請(qǐng)資源去創(chuàng)建運(yùn)行 Taskmanager 的 pod,在運(yùn)行過程中,如果發(fā)現(xiàn)某個(gè) Taskmanager 長時(shí)間空閑,可以根據(jù)配置動(dòng)態(tài)釋放資源。 這里通過平臺(tái)與 K8s 交互進(jìn)行資源的創(chuàng)建和銷毀,主要是為了保證計(jì)算平臺(tái)對(duì)資源的管控,同時(shí)避免了集群配置和邏輯變化對(duì)鏡像的影響;通過支持用戶配置 Taskmanager 個(gè)數(shù)進(jìn)行資源的預(yù)分配,可以做到與資源靜態(tài)分配同樣快速的任務(wù)提交速度;同時(shí)通過定制資源分配策略,可以做到兼容原有 slot 分散分布的均衡調(diào)度。
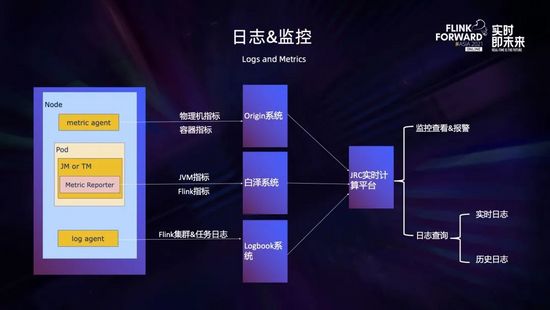
在 Flink on K8s 的環(huán)境中,日志和監(jiān)控指標(biāo)是非常重要的,它可以幫助我們觀察整個(gè)集群、容器、任務(wù)的運(yùn)行情況,根據(jù)日志和監(jiān)控快速定位問題并及時(shí)處理。
這里的監(jiān)控指標(biāo)包括物理機(jī)指標(biāo) (比如 CPU、內(nèi)存、負(fù)載、網(wǎng)絡(luò)、連通性、磁盤等指標(biāo))、容器指標(biāo) (比如 CPU、內(nèi)存、網(wǎng)絡(luò)等指標(biāo))、JVM 指標(biāo)和 Flink 指標(biāo) (集群指標(biāo)和任務(wù)指標(biāo))。其中物理機(jī)指標(biāo)和容器指標(biāo)是通過 metric agent 采集上報(bào)到 Origin 系統(tǒng),JVM 指標(biāo)和 Flink 指標(biāo)是通過 Jobmanager 和 Taskmanager 中定制的 metric reporter 上報(bào)到白澤系統(tǒng),之后統(tǒng)一在計(jì)算平臺(tái)進(jìn)行監(jiān)控的查看和告警。
日志采集采用京東的 Logbook 服務(wù),它的基本機(jī)制是在每個(gè) Node 上會(huì)運(yùn)行一個(gè) log agent,用于采集指定路徑的日志;然后 Jobmanager 或 Taskmanager 會(huì)按照指定規(guī)則輸出日志到指定目錄,之后日志就會(huì)被自動(dòng)采集到 Logbook 系統(tǒng);最后可以通過計(jì)算平臺(tái)進(jìn)行實(shí)時(shí)日志和歷史日志的檢索和查詢。
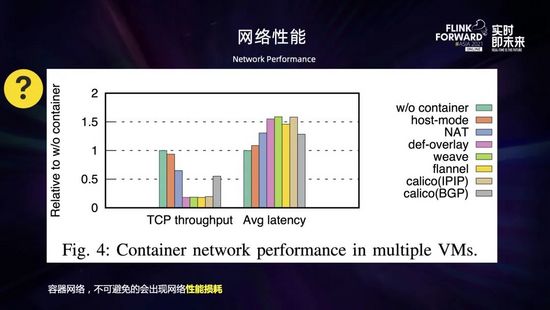
接下來是容器網(wǎng)絡(luò)的性能問題。一般來說虛擬化的東西都會(huì)帶來一定的性能損耗,容器網(wǎng)絡(luò)作為容器虛擬化的一個(gè)重要組件,相比物理機(jī)網(wǎng)絡(luò)來說,不可避免地會(huì)出現(xiàn)一些性能的損耗。性能的下降程度根據(jù)網(wǎng)絡(luò)插件的不同、協(xié)議類型和數(shù)據(jù)包的大小會(huì)有所不同。
如上圖所示,是對(duì)于跨主機(jī)容器網(wǎng)絡(luò)通信的性能測(cè)評(píng)。參考基線是 server 和 client 在同一主機(jī)上進(jìn)行通信。從圖中可以看到,host 模式取得了接近參考基線的吞吐量和延遲,NAT 和 Calico 有較大的性能損失,這是由于地址轉(zhuǎn)換和網(wǎng)絡(luò)包路由的開銷導(dǎo)致的;而所有 overlay 網(wǎng)絡(luò)都有非常大的性能損失。總的來說,網(wǎng)絡(luò)包的封裝和解封相比地址轉(zhuǎn)換和路由來說開銷更大,那么采用何種網(wǎng)絡(luò)就需要做一個(gè)權(quán)衡。比如 overlay 網(wǎng)絡(luò)由于網(wǎng)絡(luò)包的封裝和解封導(dǎo)致了很大的開銷,性能會(huì)比較差,但允許更靈活和安全的網(wǎng)絡(luò)管理;NAT 和主機(jī)模式的網(wǎng)絡(luò)比較容易取得好的性能,但是安全性較差;Routing 網(wǎng)絡(luò)性能也不錯(cuò)但需要額外的支持。
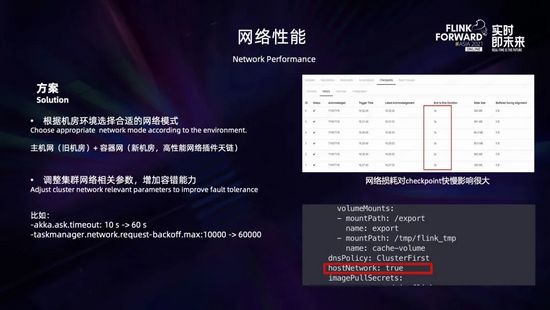
此外,網(wǎng)絡(luò)損耗對(duì)于 checkpoint 的快慢影響也很大。根據(jù)我們對(duì)比測(cè)試,網(wǎng)絡(luò)模式不同的情況下,同樣的環(huán)境下運(yùn)行同樣的任務(wù),采用容器網(wǎng)絡(luò)任務(wù)的 checkpoint 時(shí)長比使用主機(jī)網(wǎng)絡(luò)慢了一倍以上。那么怎么解決這個(gè)容器網(wǎng)絡(luò)的性能問題?
- 一是可以根據(jù)機(jī)房環(huán)境選擇合適的網(wǎng)絡(luò)模式:比如對(duì)于我們一些舊的機(jī)房,容器網(wǎng)絡(luò)性能下降特別明顯,而且網(wǎng)絡(luò)的架構(gòu)也不能升級(jí),采用了主機(jī)網(wǎng)絡(luò) (如上圖所示,在 pod yaml 文件中配置 hostNetwork=true) 來避免損耗的問題,雖說這不太符合 K8s 的風(fēng)格,但需要根據(jù)條件做個(gè)權(quán)衡;而對(duì)于新的機(jī)房,由于基礎(chǔ)網(wǎng)絡(luò)的性能提升以及采用了新的高性能網(wǎng)絡(luò)插件,性能損耗相比主機(jī)網(wǎng)非常小,就采用了容器網(wǎng);
- 二是盡量不要使用異構(gòu)網(wǎng)絡(luò)環(huán)境,避免 K8s 跨機(jī)房,同時(shí)適當(dāng)調(diào)整集群網(wǎng)絡(luò)的相關(guān)參數(shù),增加網(wǎng)絡(luò)的容錯(cuò)能力。比如可以適當(dāng)調(diào)大 akka.ask.timeout 和 taskmanager.network.request-backoff.max 兩個(gè)參數(shù)。

下面說一下磁盤的性能問題。容器中的存儲(chǔ)空間由兩部分組成,如上圖所示,底層是只讀的鏡像層,頂部是可讀寫的容器層。容器運(yùn)行的時(shí)候涉及到文件的寫操作都是在容器層中完成的,這里需要一個(gè)存儲(chǔ)驅(qū)動(dòng)提供聯(lián)合文件系統(tǒng)來管理。存儲(chǔ)驅(qū)動(dòng)一般來說為空間效率進(jìn)行了優(yōu)化,額外的抽象會(huì)帶來一定的性能損耗 (取決于具體存儲(chǔ)驅(qū)動(dòng)),寫入速度要低于本地文件系統(tǒng),特別是使用了寫時(shí)復(fù)制的存儲(chǔ)驅(qū)動(dòng)來說,損耗更大。這對(duì)于寫密集型的應(yīng)用來說,會(huì)有更大的性能影響。而在 Flink 中,很多地方都涉及到本地磁盤的讀寫,比如日志輸出、RocksDB 讀寫、批任務(wù) shuffle 等。那么該如何處理來減小影響?
- 一是可以考慮使用外掛的 Volume,使用本地存儲(chǔ)卷,直接寫數(shù)據(jù)到 host fileSystem 來提升性能;
- 此外也可以調(diào)優(yōu)磁盤 IO 相關(guān)參數(shù),比如調(diào)優(yōu) RocksDB 參數(shù),提升磁盤的訪問性能;
- 最后也可以考慮采用一些存儲(chǔ)計(jì)算分離的方案,比如使用 remote shuffle,提升本地 shuffle 的性能和穩(wěn)定性。
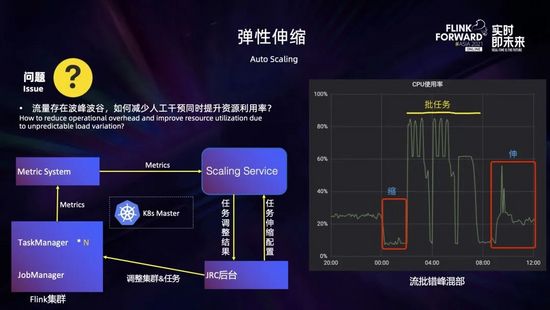
在實(shí)踐過程中經(jīng)常會(huì)發(fā)現(xiàn),很多業(yè)務(wù)的計(jì)算任務(wù)配置不合理,占用了過多的資源造成了資源浪費(fèi)。此外,流量存在波峰波谷,如何在洪峰時(shí)自動(dòng)擴(kuò)容,在波谷時(shí)自動(dòng)縮容,在減少人工干預(yù)、保證業(yè)務(wù)穩(wěn)定的同時(shí)提高資源利用率,這都涉及到資源彈性伸縮的問題。為此我們開發(fā)了彈性伸縮的服務(wù),根據(jù)作業(yè)運(yùn)行情況動(dòng)態(tài)調(diào)整任務(wù)的并行度以及 Taskmanager 的規(guī)格,來解決作業(yè)吞吐不足、資源浪費(fèi)等問題。
如上圖所示,大致的工作流程如下:首先在 JRC 平臺(tái)進(jìn)行任務(wù)的伸縮配置,主要包括運(yùn)行度調(diào)整的上下限以及一些伸縮策略的閾值,這些配置都會(huì)發(fā)送到伸縮服務(wù);伸縮服務(wù)運(yùn)行過程中會(huì)實(shí)時(shí)監(jiān)測(cè)集群和任務(wù)的運(yùn)行指標(biāo) (主要是一些 CPU 的使用率和算子的繁忙程度等),結(jié)合伸縮配置和調(diào)整策略生成任務(wù)調(diào)整結(jié)果,發(fā)送到 JRC 平臺(tái);最后 JRC 平臺(tái)根據(jù)調(diào)整結(jié)果,對(duì)集群和任務(wù)進(jìn)行調(diào)整。
目前通過該伸縮服務(wù),可以較好地解決一些場(chǎng)景的資源浪費(fèi)問題,以及任務(wù)吞吐與算子并行度呈線性關(guān)系條件下的性能問題。不過它還是存在一定的局限性,比如對(duì)于外部的系統(tǒng)瓶頸、數(shù)據(jù)傾斜以及任務(wù)本身的性能瓶頸還有無法通過擴(kuò)并行度提升的場(chǎng)景,不能很好地應(yīng)對(duì)解決。
此外,結(jié)合彈性伸縮,我們也進(jìn)行了一些實(shí)時(shí)流任務(wù)和離線批任務(wù)錯(cuò)峰混部的嘗試。如上圖右所示,在凌晨前后,流任務(wù)比較空閑,會(huì)縮容釋放出一些資源給批任務(wù);之后可以使用這些釋放的資源在夜間運(yùn)行批任務(wù);到了白天批任務(wù)運(yùn)行完釋放的資源又可以還給流任務(wù),用于擴(kuò)容以應(yīng)對(duì)流量洪峰,從而提高資源的整體利用率。
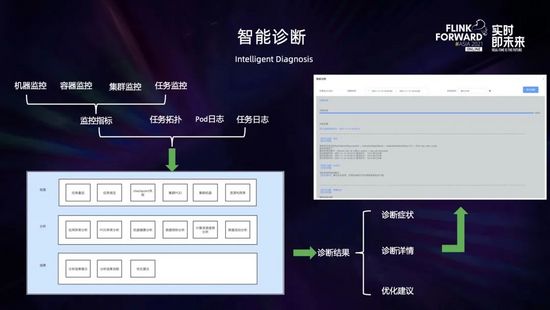
相比物理機(jī)或 YARN 環(huán)境,F(xiàn)link on K8s 出現(xiàn)問題以后的排查相對(duì)要更困難,因?yàn)檫@里面還涉及到 K8s 許多組件,比如容器網(wǎng)絡(luò)、DNS 解析、K8s 調(diào)度等各方面的問題,都存在一定的門檻。
為了解決這個(gè)問題,我們開發(fā)了智能診斷的服務(wù),將作業(yè)相關(guān)的各個(gè)維度的監(jiān)控指標(biāo) (包括物理機(jī)的、容器的、集群的和任務(wù)的指標(biāo)) 與任務(wù)拓?fù)浣Y(jié)合起來并與 K8s 打通,結(jié)合 pod 日志和任務(wù)日志聯(lián)合進(jìn)行分析,并將日常人工運(yùn)維的一些方法進(jìn)行歸納總結(jié)應(yīng)用到分析策略中,診斷出作業(yè)的問題并給出優(yōu)化建議。目前支持對(duì)任務(wù)重啟、任務(wù)背壓、checkpoint 失敗、集群資源利用率低等一些常見問題進(jìn)行診斷,后續(xù)會(huì)持續(xù)豐富和完善。
三、優(yōu)化改進(jìn)
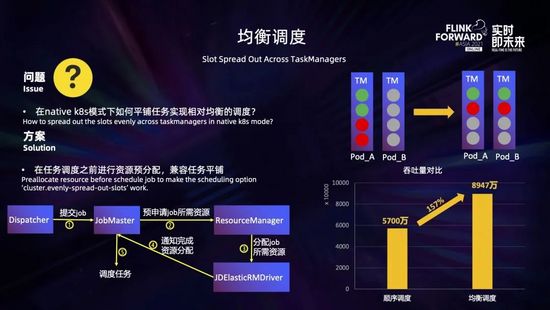
在實(shí)踐的過程中,采用資源靜態(tài)分配模式的時(shí)候,一般都會(huì)將 slot 按照 Taskmanager 打散,將耗費(fèi)資源的算子按照 Taskmanager 分散開來,實(shí)現(xiàn)作業(yè)的均衡調(diào)度,提高作業(yè)的性能。
如右上圖所示有 2 個(gè) Taskmanager,每個(gè) Taskmanager 有 4 個(gè) slot,1 個(gè)作業(yè)有 2 個(gè)算子 (分別用綠色和紅色表示),每個(gè)算子 2 個(gè)并行度。在使用默認(rèn)調(diào)度策略 (順序調(diào)度) 的情況下,這個(gè)作業(yè)的所有算子都會(huì)集中在一個(gè) Taskmanager;而如果使用均衡調(diào)度,這個(gè)作業(yè)的所有算子都會(huì)按照 Taskmanager 進(jìn)行橫向打散,每個(gè) Taskmanager 都會(huì)分到兩個(gè)算子的一個(gè)并行度 (綠色和紅色)。
而在采用資源動(dòng)態(tài)分配模式 (native K8s) 的時(shí)候,資源是一個(gè)個(gè) pod 單獨(dú)申請(qǐng)創(chuàng)建的,那么這個(gè)時(shí)候如何實(shí)現(xiàn)均衡調(diào)度呢?我們采用了在任務(wù)調(diào)度之前進(jìn)行資源預(yù)分配的方式來解決這個(gè)問題。具體過程如下:用戶提交作業(yè)后,如果開啟了資源預(yù)分配,JobMaster 不會(huì)立即調(diào)度任務(wù),而是會(huì)向 ResourceManager 一次性預(yù)申請(qǐng)作業(yè)所需的資源,在所需資源到位后,JobMaster 會(huì)得到通知,此時(shí)再調(diào)度任務(wù)就可以做到和靜態(tài)資源分配模式時(shí)同樣的均衡調(diào)度了。這里還可以給 JobMaster 配置一個(gè)超時(shí)時(shí)間,超時(shí)后就走正常任務(wù)調(diào)度流程,而不會(huì)無限地等待資源。
我們進(jìn)行了真實(shí)場(chǎng)景的性能對(duì)比,如上圖右所示,使用順序調(diào)度的時(shí)候作業(yè)吞吐量為 5700 萬/分鐘,而開啟了資源預(yù)分配和均衡調(diào)度后,作業(yè)吞吐量為 8947 萬/分鐘,性能提升了 57%,還是有比較明顯的效果的。
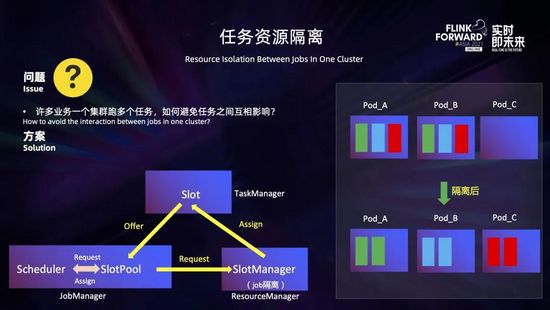
我們平臺(tái)有不少業(yè)務(wù)采用一個(gè)集群運(yùn)行多個(gè)任務(wù)的模式,這樣就會(huì)存在一個(gè) Taskmanager 分布了不同 job 的 Task,從而導(dǎo)致不同 job 之間相互影響。那么如何解決這個(gè)問題?
我們定制了 slot 的分配策略,在 Jobmanager 向 ResourceManager 請(qǐng)求 slot 時(shí),如果開啟了任務(wù)資源隔離,SlotManager 會(huì)把已經(jīng)分配 slot 的 Taskmanager 打上 job 的標(biāo)簽,之后該 Taskmanager 的空閑 slot 只能用于該 job 的 slot 請(qǐng)求。通過將 Taskmanager 按照 job 分組,實(shí)現(xiàn)了集群多任務(wù)的資源隔離。
如上圖右所示,一個(gè) Taskmanager 提供 3 個(gè) slot,有 3 個(gè) job,每個(gè) job 有一個(gè)算子,且并行度都為 3 (分別用綠色、藍(lán)色和紅色表示)。開啟 slot 平鋪分散,在隔離前,這三個(gè) job 會(huì)共享這三個(gè) Taskmanager,每個(gè) Taskmanager 上都分布了每個(gè) job 的一個(gè)并行度。而在開啟任務(wù)資源隔離后,每一個(gè) job 部將會(huì)獨(dú)占一個(gè) Taskmanager,不會(huì)相互影響。
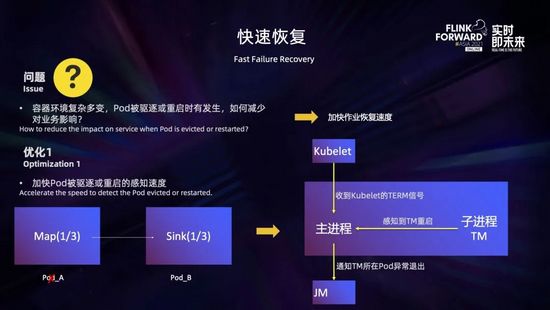
容器環(huán)境復(fù)雜多變,pod 被驅(qū)逐或重啟時(shí)有發(fā)生:比如機(jī)器發(fā)生硬件故障、docker 故障、節(jié)點(diǎn)負(fù)載較高等都會(huì)導(dǎo)致 pod 被驅(qū)逐;進(jìn)程不健康、進(jìn)程異常退出、docker 異常重啟等也都會(huì)導(dǎo)致 pod 重啟。此時(shí),會(huì)導(dǎo)致任務(wù)重啟恢復(fù),對(duì)業(yè)務(wù)造成影響。那么如何才能減少對(duì)業(yè)務(wù)的影響?
一個(gè)方面是針對(duì)容器環(huán)境,加快 pod 異常 (被驅(qū)逐或重啟) 的感知速度,迅速恢復(fù)作業(yè)。在官方的默認(rèn)實(shí)現(xiàn)中,如果 pod 發(fā)生異常,可能會(huì)從兩個(gè)路徑感知到:一個(gè)是故障 pod 下游算子可能會(huì)感知到網(wǎng)絡(luò)連接的斷開,從而引發(fā)異常觸發(fā) failover;一個(gè)是 Jobmanager 會(huì)首先感覺到 Taskmanager 心跳超時(shí),此時(shí)也會(huì)觸發(fā) failover。無論是通過哪個(gè)路徑,所需要的時(shí)長都會(huì)比超時(shí)要多一些,在我們默認(rèn)系統(tǒng)配置下,所需的時(shí)間是 60 多秒。
這里我們優(yōu)化了 pod 異常感知的速度。在 pod 異常被停止時(shí),默認(rèn)會(huì)有一個(gè) 30 秒的優(yōu)雅停止的時(shí)間,此時(shí)容器主進(jìn)程啟動(dòng)腳本會(huì)收到來自 K8s 的 TERM 信號(hào),除了做必要的清理動(dòng)作之外,我們?cè)黾恿送ㄖ?Jobmanager 異常 Taskmanager 的環(huán)節(jié);在容器內(nèi)工作進(jìn)程 Taskmanager 異常退出的時(shí)候,主進(jìn)程 (這里是啟動(dòng)腳本) 也會(huì)感知到,也會(huì)通知 Jobmanager 是哪個(gè) Taskmanager 發(fā)生了異常。這樣一來,Jobmanager 就可以在 pod 異常的時(shí)候第一時(shí)間得到通知,并及時(shí)進(jìn)行作業(yè)的故障恢復(fù)。
通過這項(xiàng)優(yōu)化,測(cè)試典型場(chǎng)景下,在集群有空余資源的情況下,任務(wù) failover 的時(shí)長從原來的 60 多秒縮短到幾秒;在集群中沒有空余資源需要等待 pod 重建的情況下,任務(wù) failover 的時(shí)長也縮短了 30 多秒,效果還是比較明顯的。
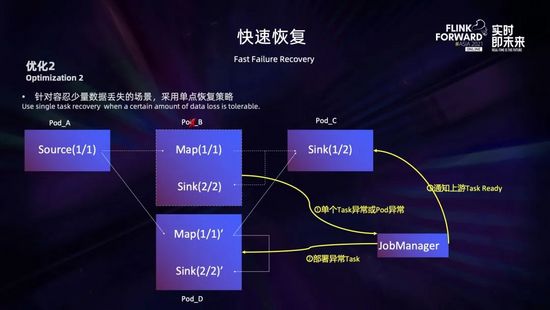
另外一個(gè)方面是減小 pod 異常對(duì)作業(yè)的影響范圍。雖說社區(qū)版在 1.9 之后,提供了基于 region 的局部恢復(fù)策略,在 Task 發(fā)生故障時(shí),只重啟故障 Task 關(guān)聯(lián) region 內(nèi)的 Task,在有的場(chǎng)景下可以減小影響。但是很多時(shí)候一個(gè)作業(yè)的算子之間都是 rebalance 或者 hash 等全連接的方式,region 策略也起不到太大作用。為此,我們?cè)?1.10 和 1.12 版本中,開發(fā)了基于故障 Task 的單點(diǎn)故障恢復(fù)策略,Task 發(fā)生故障時(shí)只恢復(fù)該故障 Task,非故障 Task 不受影響。
如上圖所示,這個(gè)作業(yè)有三個(gè)算子 source、map 和 sink。其中 source 和 map 都是 1 個(gè)并行度,sink 是 2 個(gè)并行度。map 的第一個(gè)并行度 map(1/1) 和 sink 的第二個(gè)并行度 sink(2/2) 分布在 pod_B 上,在 pod_B 被驅(qū)逐的時(shí)候,Jobmanager 會(huì)檢測(cè)到 pod_B 異常,之后會(huì)在新的 pod_D 上重新部署這兩個(gè) Task,記為 map(1/1)’ 和 sink(2/2)’;部署完成后,會(huì)通知故障 Task map(1/1) 的下游 sink(1/1) 新的上游 Task map(1/1)’ 已經(jīng) ready,然后 sink(1/1) 就會(huì)和上游 map(1/1)’ 重新建立連接,進(jìn)行通信。
在具體實(shí)現(xiàn)的時(shí)候有以下幾點(diǎn)需要注意:
- 一是故障恢復(fù)前,故障 Task 的上游對(duì)于待發(fā)送數(shù)據(jù)和下游對(duì)于接收的殘留數(shù)據(jù)如何進(jìn)行處理?這里我們會(huì)將上游輸出到故障Task數(shù)據(jù)直接丟棄掉,下游如果收集到不完整的數(shù)據(jù)也會(huì)丟棄掉;
- 二是上下游無法感知到對(duì)方異常時(shí),再恢復(fù)的時(shí)候如何進(jìn)行處理?這里可能需要一個(gè)強(qiáng)制的更新處理;
- 三是一個(gè) pod 上分布了多個(gè) Task 的情況,如果該 pod 異常,存在多個(gè)故障 Task,這些故障 Task 之間如果存在依賴關(guān)系,如何正確地進(jìn)行處理?這里需要按照依賴關(guān)系進(jìn)行順序的部署。
通過單點(diǎn)恢復(fù)策略,在線應(yīng)用取得了不錯(cuò)的效果,對(duì)作業(yè)的影響范圍大大減少 (取于具體的作業(yè),能夠減少為原來的幾十分之一到幾百分之一),避免了業(yè)務(wù)的斷流,同時(shí)恢復(fù)時(shí)長也大大降低 (從典型場(chǎng)景的一分多鐘降低到幾秒 - 幾十秒)。
當(dāng)然,這個(gè)策略也是有代價(jià)的,它在恢復(fù)的時(shí)候會(huì)帶來少量的丟數(shù),適用于對(duì)少量丟數(shù)不敏感的業(yè)務(wù)場(chǎng)景,比如流量業(yè)務(wù)。
四、未來規(guī)劃

未來我們會(huì)在以下幾方面繼續(xù)探索:
一個(gè)是 K8s 層面資源調(diào)度優(yōu)化,更高效地管理大數(shù)據(jù)的在線服務(wù)和離線作業(yè),提升 K8s 集群的利用率和運(yùn)行效率;
一個(gè)是 Flink 作業(yè)調(diào)度優(yōu)化,支持更豐富、更細(xì)粒度的調(diào)度策略,提升 Flink 作業(yè)資源的利用率和穩(wěn)定性,滿足不同的業(yè)務(wù)場(chǎng)景需要。
首先是調(diào)度優(yōu)化:
其次是服務(wù)混部:將不同負(fù)載的服務(wù)混部在一起,在保證服務(wù)穩(wěn)定的前提下盡量提升資源利用率,使服務(wù)器的價(jià)值最大化;
然后是智能運(yùn)維:支持對(duì)任務(wù)進(jìn)行智能診斷,并自適應(yīng)調(diào)整運(yùn)行參數(shù),實(shí)現(xiàn)作業(yè)的資質(zhì),降低用戶調(diào)優(yōu)和平臺(tái)運(yùn)維的成本;
最后是 Flink AI 的支持:人工智能應(yīng)用場(chǎng)景中,F(xiàn)link 在包括特征工程、在線學(xué)習(xí)、資源預(yù)測(cè)等方面都有一些獨(dú)特的優(yōu)勢(shì),后續(xù)我們也將在這些場(chǎng)景從平臺(tái)層面進(jìn)行探索和實(shí)踐。