













我們一起聊聊關(guān)于運(yùn)維監(jiān)控中告警收斂問題
昨天一個朋友在微信群中問我數(shù)據(jù)庫的指標(biāo)告警的故障收斂怎么做才能真正落地。說實(shí)在的,雖然現(xiàn)在很多做智能化運(yùn)維的企業(yè)都號稱能實(shí)現(xiàn)很好的故障告警收斂,不過都是場景受限的。大多數(shù)情況下是在一套系統(tǒng)中,針對系統(tǒng)中多個IT組件的故障根據(jù)時間、先后順序、以及波動曲線以及相關(guān)性要素等,通過算法進(jìn)行收斂。這種收斂在有些場景下是有效的,不過也存在一定的誤判和遺漏,不過總體來說還是可用的,是具有一定的實(shí)戰(zhàn)作用的。
網(wǎng)友的問題并不是在一個系統(tǒng)中如何歸并各個IT組件對于同一個問題的告警,而是針對某一個具體的運(yùn)維對象,他特指的是數(shù)據(jù)庫。如果把這個問題放到一個具體的運(yùn)維對象上去看,比如DBA面對的數(shù)據(jù)庫系統(tǒng),那么這個問題就完全不是一碼事了。當(dāng)時那個朋友舉例說系統(tǒng)中CPU 使用率98%,表空間使用率99%,應(yīng)用響應(yīng)時間異常,這個情況如何進(jìn)行告警收斂呢?
在我們的實(shí)際生產(chǎn)環(huán)境中,可能問題更為復(fù)雜,因?yàn)榻^大多數(shù)IT系統(tǒng)都是帶病工作的,我們稱之為亞健康狀態(tài)。系統(tǒng)的亞健康狀態(tài)往往在實(shí)際生產(chǎn)環(huán)境中是常態(tài),只是這些小毛病并不會掀起大浪,因此我們也不去關(guān)注,甚至無法感知,也不一定需要立即去做閉環(huán)解決。
不過就像大量的無癥狀新冠感染者隱藏在人群中一樣,因?yàn)樽陨頉]有發(fā)病,并沒有引起社區(qū)或者社會的關(guān)注,如果我們不去做全員核酸檢測,那么這些可能釀成重大傳播危險的潛在威脅我們是感知不到的,只有檢測或者出現(xiàn)了有癥狀的患者,周邊才能感知到。
不過系統(tǒng)的監(jiān)控與運(yùn)維是一個十分復(fù)雜的東西,除了管理規(guī)程,還有成本問題。因此我們總是會把主要的成本放在急需解決的問題上,對于不是特別重要的告警信息,大多數(shù)企業(yè)已經(jīng)沒有能力去做閉環(huán)管理了。想象一下,如果一個人管理數(shù)十個甚至上百個數(shù)據(jù)庫系統(tǒng),你能不能對每天產(chǎn)生的數(shù)千個甚至上萬個告警信息去做閉環(huán)管理?
實(shí)際上在實(shí)際生產(chǎn)環(huán)境,即使是已經(jīng)暴露出來的一些問題,比如說CPU 使用率98%,就一定說明系統(tǒng)有問題嗎?表空間使用率99%,也不意味著一定就有問題,如果某個表空間放置的是靜態(tài)數(shù)據(jù),或者說數(shù)據(jù)文件是自動擴(kuò)展的,那么表空間使用率100%也不是什么大問題。
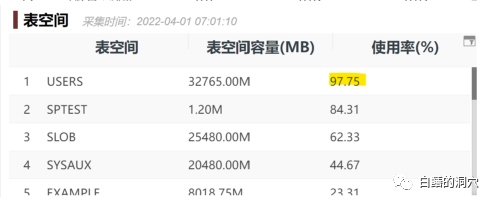
我們來看上面的例子,USERS表空間的使用率是97.75,容量是32GB,實(shí)際上如果從Oracle的dba_free_space來看,這個表空間已經(jīng)是100%了,只是因?yàn)檫@個數(shù)據(jù)文件是自動擴(kuò)展的,監(jiān)控系統(tǒng)自動根據(jù)ASM磁盤組的容量給這個表空間賦予了32GB的動態(tài)容量,同時自動將表空間使用率調(diào)整為97.75。
從這個動態(tài)調(diào)整來看,首先我們要關(guān)注的是指標(biāo)的準(zhǔn)確性和有效性。因?yàn)锳UTOEXTEND功能的存在,以及ASM磁盤組對文件EXTEND的限制,如何計算準(zhǔn)使用率是十分關(guān)鍵的。這個指標(biāo)不準(zhǔn)確,那么后面的監(jiān)控報警都成為十分虛幻的事情了。
除了指標(biāo)的準(zhǔn)確性,我們還需要關(guān)注什么呢?實(shí)際上很多指標(biāo)并不能很好的指示風(fēng)險,比如說表空間使用率的問題。我們再來看看下面的例子。
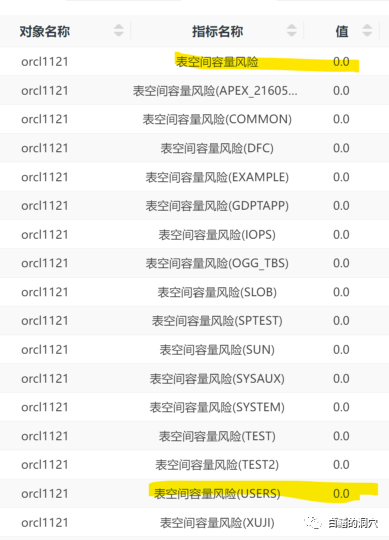
我們可以看到,我們引入了一個“表空間容量風(fēng)險”這個評估指標(biāo),并通過這個指標(biāo)來給表空間使用風(fēng)險報警,這個指標(biāo)比表空間使用率具有更高的準(zhǔn)確性。整個系統(tǒng)的表空間使用率風(fēng)險是0,這是最低的等級,表明沒有任何風(fēng)險,剛才我們看到的97.75%使用率的USERS表空間的風(fēng)險等級也是如此。
為什么會這樣呢?USERS表空間中存儲的大多數(shù)是只讀數(shù)據(jù),增長率極低,每次增長的數(shù)量也很小,當(dāng)前不擴(kuò)容還可以用很長時間,那么這時候就沒必要馬上報警了。這種評估可以大幅度減少誤報,不過也可能會帶來新的問題,那就是如果有人想往USERS表空間里導(dǎo)入大量的數(shù)據(jù),那么馬上就會報錯。因此這種表空間使用率較高的情況,也不能完全忽略。我們會在日檢、周報和月報里指出這個問題,而不是在日常的告警中不斷的去告警,這樣也能夠起到提醒運(yùn)維人員的作用,而不需要半夜發(fā)個短信讓人虛驚一場。
從上面的例子可以看出,準(zhǔn)確而有效的指標(biāo)體系是實(shí)現(xiàn)故障報警收斂的最基礎(chǔ)的工作,實(shí)際上指標(biāo)準(zhǔn)確性也可以大大提高告警準(zhǔn)確性,從而減少運(yùn)維成本。有了這一步之后,后面該怎么走呢?我們再回到前面說的例子。應(yīng)用變慢,是正常的慢還是不正常的慢?這三個指標(biāo)異常之間存在關(guān)聯(lián)嗎?存在什么樣的關(guān)聯(lián)呢?
實(shí)際上,如果要針對這個場景去做告警收斂,還是脫離不了專家經(jīng)驗(yàn)和實(shí)際運(yùn)行環(huán)境中的系統(tǒng)運(yùn)行特征。對于數(shù)據(jù)庫來說,如果表空間滿了無法寫入數(shù)據(jù),那么應(yīng)用會報錯,同時系統(tǒng)負(fù)載是會下降的,數(shù)據(jù)庫的并發(fā)負(fù)載會下降,甚至CPU使用率可能會出現(xiàn)斷崖式的下降。某些系統(tǒng)一旦出現(xiàn)無法寫入數(shù)據(jù),則會話會重新啟動,那么數(shù)據(jù)庫的新建連接數(shù)會增加,因?yàn)閿?shù)據(jù)庫無法寫入,因此新建連接會全部失敗,連接失敗率會出現(xiàn)急劇上升,而只讀應(yīng)用依然會正常。
如果我們能夠梳理出這種場景,那么我們就肯定能夠把此類場景的十幾個指標(biāo)異常進(jìn)行很好的歸類,收斂成一個告警,并直接告知故障根因。如果再加上這些指標(biāo)的異常檢測,能夠根據(jù)這些指標(biāo)的時間序列進(jìn)行再分類,那么就能夠更加精準(zhǔn)的收斂故障場景,其告警準(zhǔn)確性又可以上一個臺階。這種運(yùn)行特征的梳理可以采用專家根據(jù)以往的故障案例或者經(jīng)驗(yàn)進(jìn)行梳理,也可以通過算法自動對場景進(jìn)行分類抽象。
再回到CPU使用率高的問題上,如果CPU使用率在某個工作窗口上的某一次或者幾次突然升高,并不一定是數(shù)據(jù)庫系統(tǒng)或者應(yīng)用出現(xiàn)了必須由運(yùn)維人員干預(yù)的問題,不過如果CPU使用率持續(xù)高于平時的情況,或者突然CPU使用率遠(yuǎn)遠(yuǎn)低于某個基準(zhǔn),這時候意味著系統(tǒng)出現(xiàn)問題的機(jī)會遠(yuǎn)遠(yuǎn)高于某個或者某幾個采樣點(diǎn)出現(xiàn)高值。
因此我們就不應(yīng)該直接使用CPU使用率這個指標(biāo)來進(jìn)行告警,而是通過實(shí)時計算,生成一個CPU使用率過高風(fēng)險或者CPU使用率異常風(fēng)險這樣的指標(biāo)來進(jìn)行預(yù)警,這樣會有更好的效果。當(dāng)然,在實(shí)際的實(shí)現(xiàn)中,可以構(gòu)建出一系列的規(guī)則模型或者專家模型,通過這些模型來描述一個場景,比把每個場景都做成指標(biāo)成本要低得多。
一些通用型的故障場景,往往可以做成獨(dú)立的指標(biāo),從而降低分析的復(fù)雜性。
而對于一些非通用的,和系統(tǒng)有關(guān)的,或者用戶私有的故障模型,則可以通過其他的方式去構(gòu)建。一旦這些故障模型被構(gòu)建起來之后,我們就可以不去關(guān)注指標(biāo)和基線的預(yù)警了。運(yùn)維人員只需要面對故障模型的預(yù)警去做閉環(huán)管理,這樣也是實(shí)現(xiàn)故障告警收斂的一種實(shí)現(xiàn)方法。在一個實(shí)際的案例中,一個具有100多套系統(tǒng),數(shù)百個數(shù)據(jù)庫、中間件的運(yùn)行環(huán)境中,每天只會收到數(shù)十個告警,其中需要立即閉環(huán)處理的事件基本上是個位數(shù)。
當(dāng)然這種方法也存在缺陷,那就是會遺漏一些未知的風(fēng)險。我們采取了健康模型告警的方式來做彌補(bǔ)。當(dāng)系統(tǒng)的健康度急劇下降的時候,會產(chǎn)生一種模糊狀態(tài)報警。這種報警需要運(yùn)維人員去做狀態(tài)巡檢,從而定位問題。如果定位出了明確的問題,那么就可以再次抽象成新的故障模型。通過這樣不斷的迭代,讓我們的運(yùn)維告警越來越精準(zhǔn)。




























