














譯者 | 朱先忠
審校 | 梁策 孫淑娟
項目簡介
相似圖像檢索是任何圖像相關的搜索,即“基于內容的圖像檢索系統”,簡稱 “CBIR”系統。
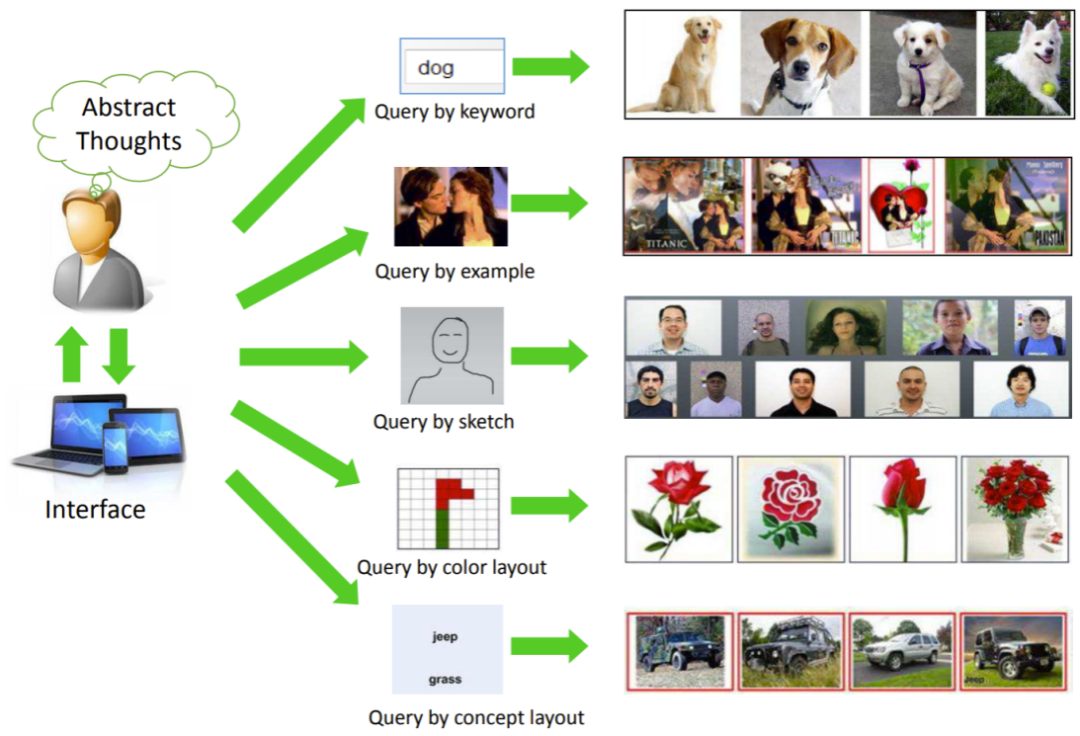
上述圖像來自文章《基于內容的圖像檢索:前沿文獻調查(2017年)》(https://arxiv.org/abs/1706.06064)
如今,圖片搜索的應用日益廣泛,尤其在電子商務服務(如AliExpress、Wildberries等)領域。“關鍵詞搜索”(包括圖像內容理解)早已在谷歌、Yandex等搜索引擎中站穩腳跟,但在市場和其他私人搜索引擎應用還較為有限。計算機視覺領域中連接文本與圖像的對比語言圖像預訓練CLIP(https://openai.com/blog/clip/)問世后便引發轟動,因而也將加速其全球化進程。
我們的團隊專門研究計算機視覺中的神經網絡,因此在本文中我將專注介紹通過圖像搜索的方法。
1、基本服務組件
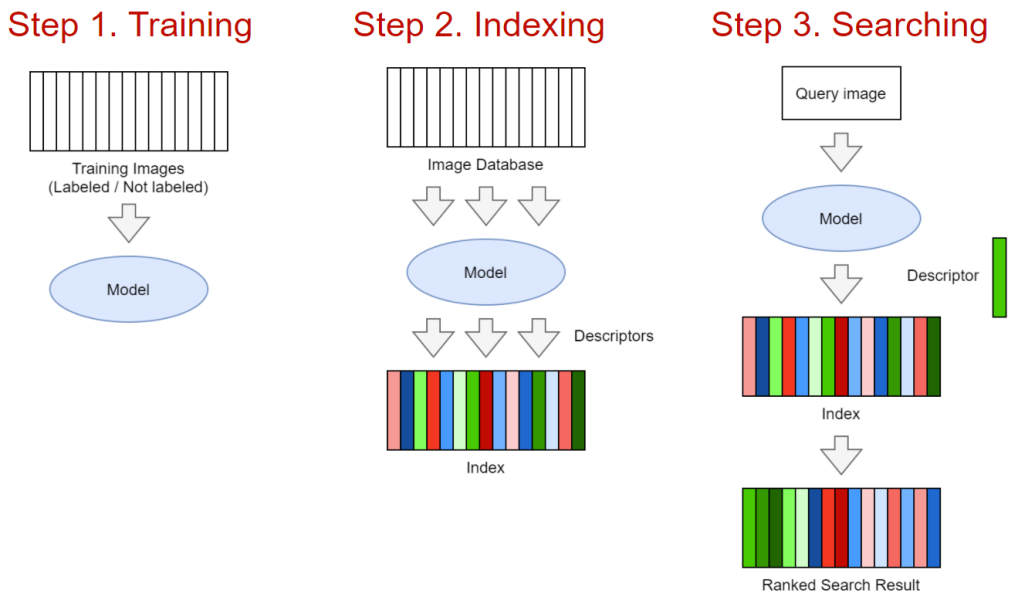
第一步:訓練模型。模型部分可以基于經典計算機視覺或神經網絡基礎來建立。模型輸入部分是一幅圖像,輸出部分則是一個D維描述符/嵌入層。在經典的實現方案中,可以采用SIFT(Scale-invariant feature transform, 尺度不變特征變換)描述符和BoW (bag-of-visual-words,視覺詞袋)算法相組合的策略。但是在神經網絡方案中,可以采用標準算法模型(如ResNet、EfficientNet等)結合復雜的池化層,再進一步結合出色的學習技術。如果數據夠多或者經過良好訓練,選擇神經網絡方案幾乎總會得到比較滿意的結果(有親測實例),所以本文中我們將重點關注這一方案。
第二步:索引圖像。這一步就是在所有圖像上運行訓練好的模型,并將嵌入內容寫入一個特殊的索引,以便快速搜索。
第三步:搜索。使用用戶上傳的圖像,運行模型,獲得嵌入層,并將嵌入層與數據庫中的其他嵌入層數據進行比較。最后的搜索結果按相關性排序。
2、神經網絡與度量學習
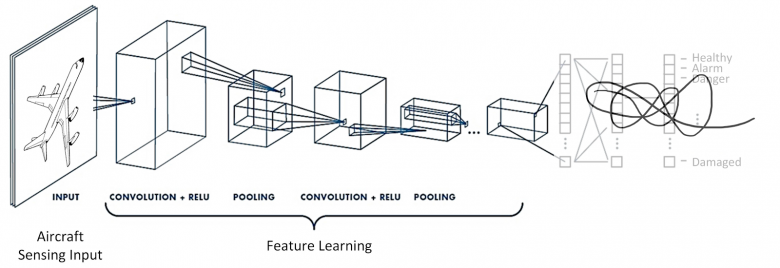
在尋找相似性的任務中,我們使用神經網絡作為特征提取器(主干網絡)。當然,主干網絡的選擇取決于數據的容量和復雜性——你可以根據自己的開發需求選擇從ReNET18殘差網絡模型到Visual Transformer模型的所有可選方案。
圖像檢索模型的第一個特征當屬神經網絡輸出部分的實現技術。在圖像檢索排行榜(https://kobiso.github.io/Computer-Vision-Leaderboard/cars.html)上,不同的圖像檢索算法都是為了構建出最理想的描述符——例如有使用并行池化層的組合全局描述符(Combined Global Descriptors)算法,還有為了在輸出功能上實現更均勻激活分布的批處理刪除塊算法。
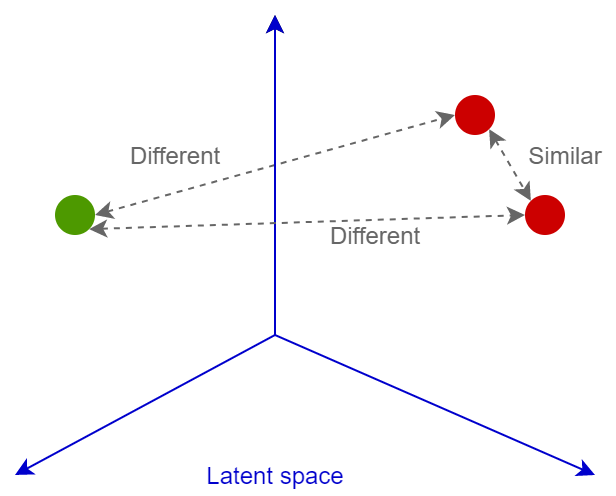
第二個主要特征是損失函數。目前人工智能領域已經有不少損失函數,比如僅在《深度圖像檢索調查》(https://arxiv.org/abs/2101.11282)一文中就提到了十幾種推薦的損失函數算法。同時,也存在數量相當的分類函數。所有這些損失函數的主要目標都是為了訓練神經網絡以便將圖像轉換為線性可分離的空間向量,從而進一步通過余弦或歐幾里德距離比較這些向量:相似的圖像會擁有相近的嵌入層,不相似的圖像則會擁有極為不同的嵌入層。接下來,讓我們對這些內容作進一步介紹。
損失函數
1、對比損失函數(Contrastive Loss)
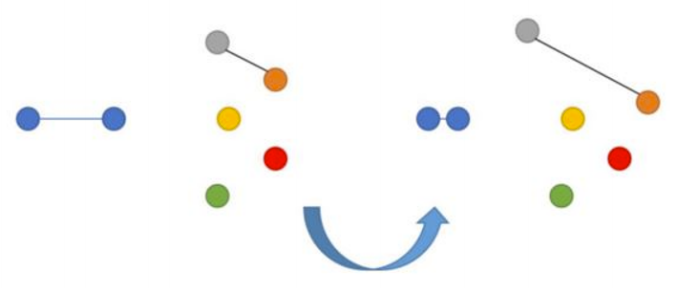
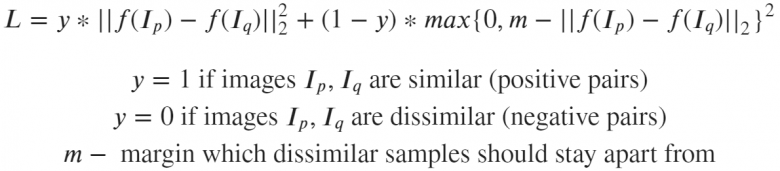
這種算法中存在一種雙重損失的情況,往往發生在比較彼此之間的距離的對象身上。
如果圖像p和q實際上是很相似的,那么神經網絡會因圖像p和q的嵌入層之間的距離而受到懲罰。類似地,因應用了嵌入層的接近性也會存在神經網絡懲罰的情況,因為事實上嵌入層的圖像實際上彼此是不同的。在后面這種情況下,我們可以設置一個邊界值m(例如賦值為0.5),目的是為了克服我們想當然地認為神經網絡已經處理了“分離”不相似圖像任務的想法。
2、三元組損失函數(Triplet Loss)
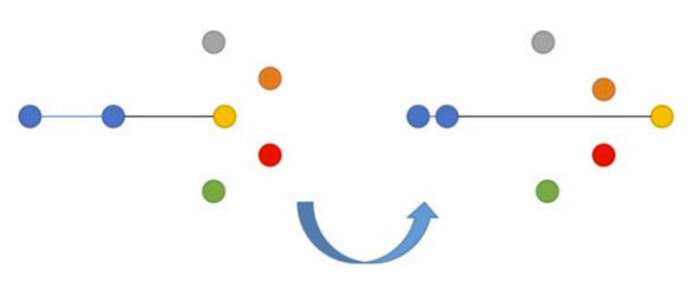

在這里,我們的目標是最小化錨點到正例的距離,而最大化錨點到負例的距離。三元組損失函數最早見于谷歌FaceNet模型關于人臉識別的文章中,長期以來一直是最先進的解決方案。
3、N元組損失函數(N-tupled)
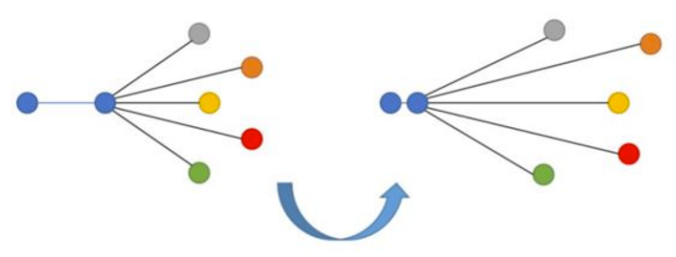

N元組損失函數是基于三元組損失函數進一步的研究成果,此函數也采用了錨點和正例概念,但使用的是多個而非單個負例技術。
4、加性角度間隔損失函數(Angular Additive Margin,也稱ArcFace)
配對損失函數的問題在于選擇正例、負例和錨點的組合方面——如果只是從數據集中均勻隨機選取它們,那么就會出現“輕配對”的問題。出現這種簡單的圖像配對時,損失為0。事實證明,此情況下網絡會很快收斂到一種狀態,在這種狀態下,批次中的大多數元素都極易處理,其損失將變成零——此時神經網絡將停止學習。為了避免這個問題,此算法的開發人員開始提出復雜的配對挖掘技術——硬負例挖掘和硬正例挖掘。有關問題可參見(https://gombru.github.io/2019/04/03/ranking_loss/),該文章比較了多種損失函數。此外PML庫(https://github.com/KevinMusgrave/pytorch-metric-learning)也實現了許多挖掘方法。值得注意的是,這個庫中包含了許多在PyTorch框架上度量學習任務的有用信息。
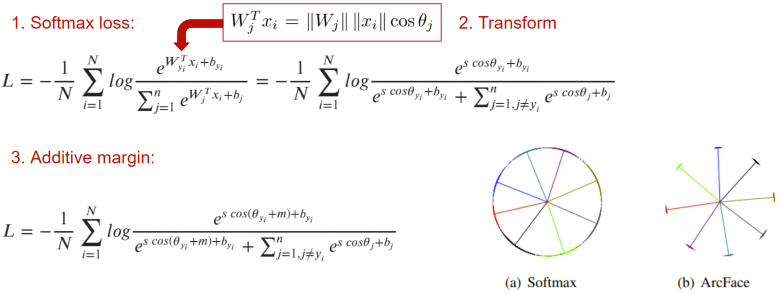
解決上述問題的另一種方案是使用分類損失函數。我們不妨回想三年前推出的面部識別算法ArcFace,它是當時最先進的,也導致了當時眾所周知的“缺陷”特征的存在。
該算法的主要思想是在通常的交叉熵的基礎上增加一個縮進m,該交叉熵將一類圖像的嵌入層分布在該類圖像的質心區域,以便它們都與其他類的嵌入層簇至少相隔一個角度m。
這看起來似乎是一個完美的損失函數解決方案,尤其是當針對MegaFace基準(https://paperswithcode.com/sota/face-verification-on-megaface)規模開發人工智能系統時。但需要記住,只有在存在分類標記的情況下,此算法才會起作用;否則,你將不得不面臨配對損失函數問題。
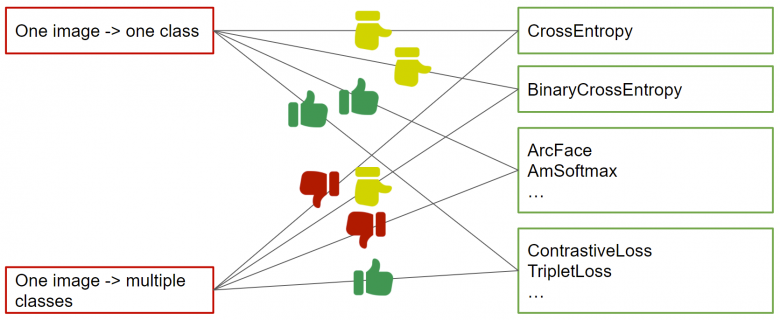
上圖中直觀地展示了使用單類標記和多類標記時,哪些損失函數最適合(可通過計算多標簽向量樣本之間的交集百分比,從多類標記中導出配對標記)。
池化
現在,讓我們回顧一下神經網絡體系結構,不妨考慮在執行圖像檢索任務中使用一對池化層的情形。
1、R-MAC池化
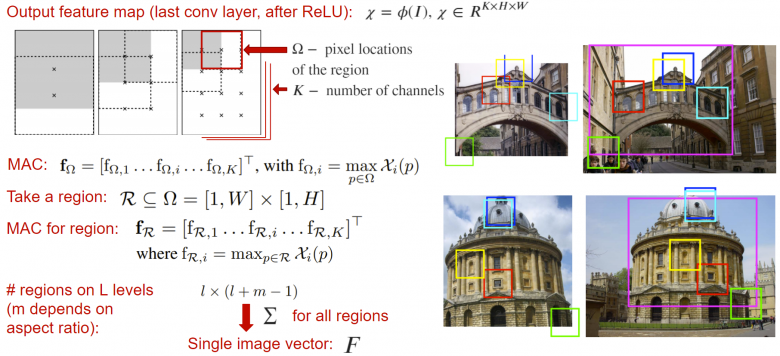
R-MAC(區域最大卷積激活)是一個池化層,它接受神經網絡的輸出映射(在全局池化層或分類層之前),并返回一個描述符向量,此向量為輸出圖中各個窗戶中的激活量之和。在這里,窗戶的激活量取為每個通道單獨獲取該窗戶的最大值。
這個結果描述符的計算過程中考慮了圖像在不同尺度下的局部特征,從而創建了一個內容豐富的特征描述。這個描述符本身可以是一個嵌入層,因此可以直接發送到損失函數。
2、GeM池化
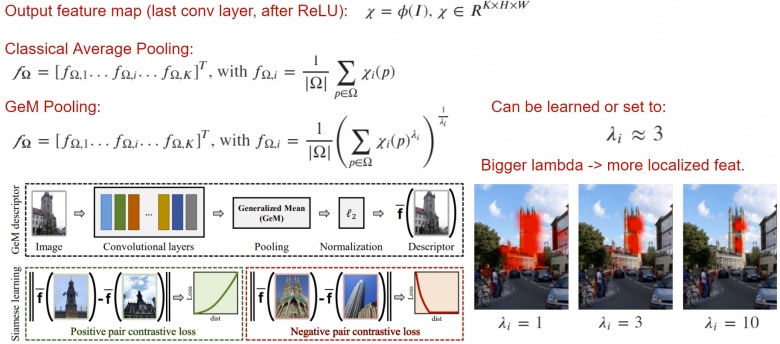
GeM(廣義平均池化)是一種簡單的池化算法,可以提高輸出描述符的質量。底線是,經典的平均池化可以推廣到lambda范數。通過增加lambda層,我們使神經網絡關注圖像的重要部分,這在某些任務中可能很重要。
測距
1、索引
高質量搜索相似圖像的關鍵是排名,即顯示給定查詢的最相關樣本。此過程的基本特征包括:建立描述符索引的速度、搜索的速度和占用的內存。
最簡單的方法是保持嵌入層“對著正面”并對其進行強力搜索,例如使用余弦距離實現。但是,這種方法在有大量嵌入層時會出現問題——數量可能是數百萬、數千萬甚至更多。而且,搜索速度顯著降低,占用的堆空間也會進一步增加。不過,還是存在積極的方面——使用現有的嵌入層即可實現完美的搜索質量。
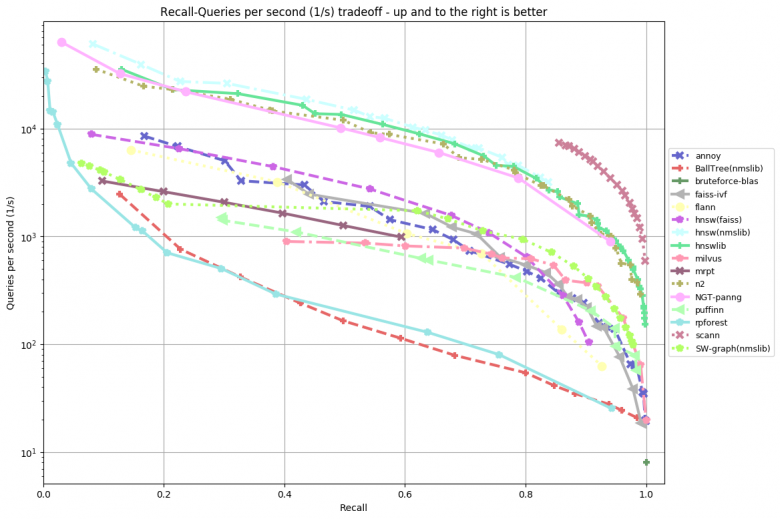
這幾個問題可以以犧牲質量為代價來解決——以壓縮(量化)而不是以原始形式存儲嵌入層。而且還要改變搜索策略——不是使用暴力搜索,而是嘗試進行最小比較次數以找到與給定查詢最接近的所需比較次數。目前已經存在大量有效的搜索框架可以近似搜索最接近的內容。為實現這一目的,一個特殊的基準測試已經創建——根據這個基準你可以觀測到每一種庫在不同數據集上的表現。
其中,最受歡迎的庫有:NMSLIB(非度量空間庫)、Spotify的Have庫、Facebook的Faiss庫以及Google的Scann庫等。此外,如果您想用REST API進行索引的話,可以考慮使用Jina應用程序(https://github.com/jina-ai/jina)。
2、重新排名
信息檢索領域的研究人員早就了解到,在收到原始搜索結果后,可以通過某種方式對項目重新排序來改進有序的搜索結果。
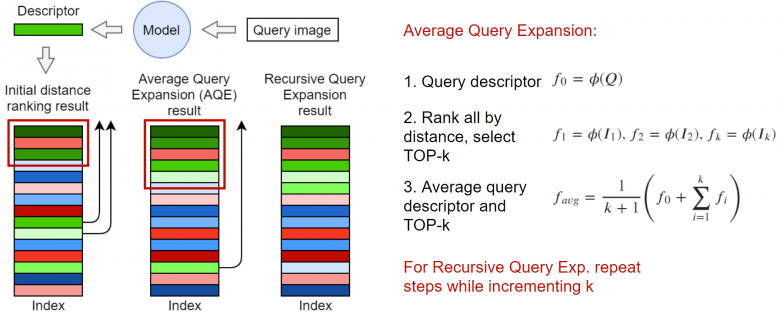
一種著名的算法是拓展查詢(Query Expansion)。該算法的核心思想是使用最接近元素集合中的前top-K個元素生成新的嵌入層。在最簡單的情況下,可以如上圖所示取平均向量。其實,你還可以根據問題中的距離或與請求的余弦距離對嵌入層進行加權操作。在《基于注意力的查詢擴展學習》(https://arxiv.org/abs/2007.08019)一文中有詳細提到了一個框架,或者你也可以通過遞歸方式來使用拓展查詢算法。
3、k近鄰算法

上圖是一個人物最近物體識別的應用程序截圖。其中,圖上部給出了查詢及其10個最近鄰數據,其中P1-P4為正例,NI-N6為負例。圖底部中的每兩列顯示樣本人物的10個最近鄰居。藍色和綠色框分別對應于樣本人物和正例。我們可以觀察到,樣本人物和正例相互之間有10個最近的鄰居。
k近鄰算法主要圍繞前top-k個元素展開,其中包括最接近請求本身的k個元素。
在這個集合的基礎上,建立了對結果重新排序的過程,其中有一個過程在文章《基于k近鄰算法的人物再識別信息重排序研究》 (https://arxiv.org/abs/1701.08398)中給出了描述。根據定義,k近鄰算法(k-reciprocal)比k最近鄰算法(k-nearest neighbors)更接近查詢結果。因此,人們可以粗略地認為K近鄰算法集合中的元素是正例,并且可以進一步改變加權規則用于類似于拓展查詢這樣的算法。
在該文中,一種機制已開發出來,它可以使用top-k中元素本身的k-近鄰集合來重新計算距離。該文包含大量計算信息,暫時不在本文的討論范圍內,建議有興趣的讀者可以找來自行閱讀。
相似圖像搜索算法效果分析
接下來,我們來分析一下本文提出的相似圖像搜索算法的質量問題。值得注意的是,實現這項搜索任務過程中存在許多細節,而初學者在第一次開發圖像檢索項目時很可能不會注意到這些問題。
1、度量
本文將探討在圖像檢索領域普遍使用的一些流行度量算法,比如precision@k、recall@k、R- precision、mAP和nDCG等。
【譯者補充】一般來說,下述有關算法中的precision代表檢索出來的條目有多少是準確的,recall則代表所有準確的條目有多少被檢索出來。
(1)precision@R算法
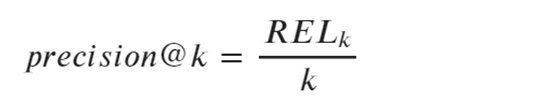
上述公式中,
參數RELk表示:top-k個結果中相關樣本的數目;
參數k表示:需要考慮的頂部位置的固定樣本數目。
優點:可以顯示top-k中相關樣本所占的百分比值。
缺點:
- 對給定查詢的相關樣本數量非常敏感,這就導致無法對搜索質量進行客觀評估,因為不同查詢的相關樣本數量不同。
- 只有當所有查詢中的相關樣本數量大于或者等于k時,才能達到值1。
(2)R-precision(精確率)算法
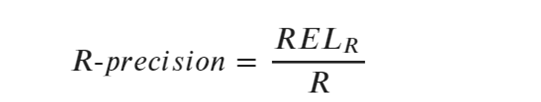
上述公式中,參數RELR表示:top-R個結果中相關樣本的數目;
參數R表示:給定查詢中所有相關樣本項的數目。
與算法precision@k相同,參數k也被設置為相關查詢樣本的數目。
優點:不像precision@k中數字k的那樣敏感,度量變得穩定。
缺點:必須事先知道與請求相關的樣本的總數目(如果不把所有相關的數字都先標記出來,可能導致問題)。
(3)Recall@k(召回率)算法
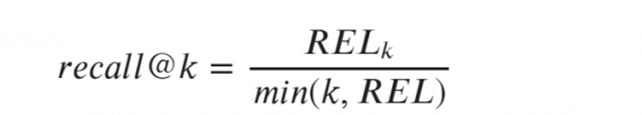
上述公式中,參數RELk表示:top-k個結果中相關樣本的數目;
參數k表示:需要考慮的頂部位置中樣本的固定數目;
參數REL表示:給定查詢中所有相關樣本項的數目。
這個算法能夠顯示top-k中發現的相關樣本項的比例。
優點:
- 回答了在top-k中原則上是否相關的問題
- 穩定且平均超過請求
(4)mAP (均值平均精確率)算法
本算法能夠顯示出搜索結果頂部相關樣本的密度。你可以將其視為搜索引擎用戶收到的信息量,此時搜索引擎讀取的頁面數最少。因此,信息量與讀取的頁數之比越大,度量就越高。
優點:
- 對搜索質量進行客觀穩定的評估
- 精確召回曲線的一位數表示,其本身攜帶有豐富的分析信息
缺點:
- 必須知道與請求相關的總樣本數量(如果不先把所有相關的樣本都標記出來可能有問題)
【提示】可從https://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-ranked-retrieval-results-1.html一文了解到更多關于mAP算法輸出的信息。
(4)nDCG(歸一化累積增益)算法
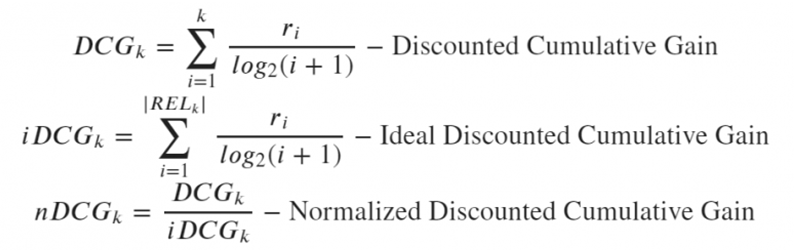
上述公式中,
參數RELk表示:位置k之前的相關樣本項列表(按相關性排序);參數ri表示:
檢索結果中第i項的四舍五入真值相關性得分。
這個度量算法顯示了top-k中的元素在它們之間排序的正確程度。由于這是上面這些方法中唯一考慮元素順序的度量算法,我們就不詳述它的優缺點了。不過,有研究表明,當需要考慮順序時,該度量算法相當穩定并且在大多數情況下適用。
2、算法整體估計
(1)宏觀方面:為每個請求計算一個度量,并且對所有請求計算平均值。
- 優點:與此查詢相關的不同數量的數據沒有顯著波動。
- 缺點:所有查詢都被認為等同,盡管有些查詢比其他查詢相關性更強。
(2)微觀方面:在所有查詢中,標記相關和單獨成功找到相關的數量進行求和,然后都參與到相應度量的計算中。
- 優點:對查詢進行評估時,會考慮與每個查詢相關的標記數量。
- 缺點:如果某個請求中有很多標記的相關度量,并且系統沒有成功或者成功地將它們帶到頂部,那么度量的計算結果可能變得非常低或者非常高。
3、系統驗證
建議讀者對本文算法采取以下兩種驗證方案:
(1)基于一組查詢和選定的相關查詢進行驗證
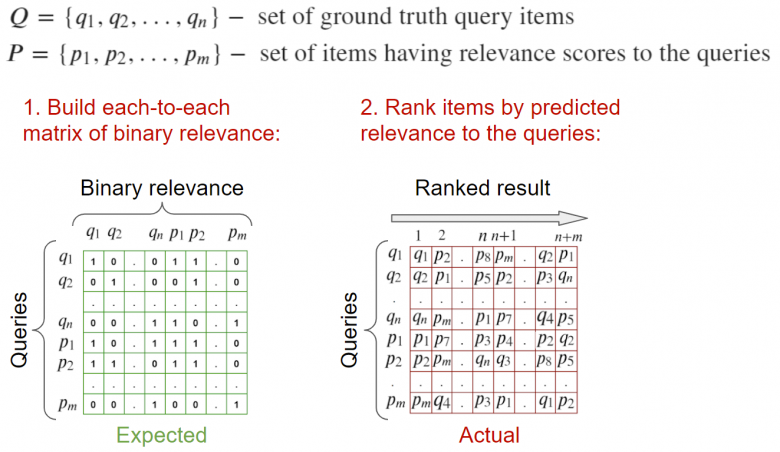
輸入:圖像請求和與之相關的圖像,并且存在與此查詢相關的列表形式的標記。為了計算度量,可以計算每個元素的相關性矩陣,并根據元素相關性的二進制信息來進行計算。
(2)全基驗證
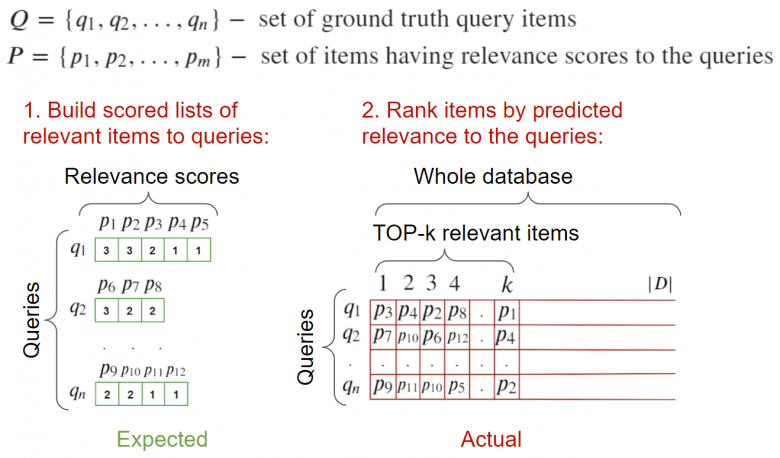
此算法的輸入部分包括:圖像請求以及與之相關的圖像,還應有一個圖像驗證數據庫——理想情況下,所有相關的查詢都會在其中進行標記。此外,該數據庫中不應該包含查詢圖像;否則,將不得不在搜索階段清理該類圖像,以便它們不會阻塞于top-1層上。此外還提供了一組負例作為驗證基——我們的任務是找出與之相關的東西。
為了計算度量,你可以遍歷所有請求,計算到所有元素(包括相關元素)的距離,然后將它們發送到度量計算函數。
已完成項目示例

在某家公司應不應該使用另一家品牌圖案元素的問題上,公司間經常出現糾紛。在這種情況下,實力較弱的制造商試圖寄生于一家成功的大品牌,用類似符號展示自家產品和服務。但是,消費者也會因此受到影響——你可能想從你信任的制造商那里購買奶酪,但卻沒有仔細閱讀標簽,于是錯誤地從假冒的制造商那里購買了偽劣產品。最近有個案例是蘋果公司試圖阻止Prepear公司的標志商標使用(https://www.pcmag.com/news/apple-is-attempting-to-block-a-pear-logo-trademark)。
于是,有一些專業政府組織或私人公司來打擊非法移植。他們持有注冊商標的登記簿,通過該登記簿可以對即將引入的商標進行比對,最終決定批準還是拒絕商標注冊申請。以上是使用WIPO(https://www3.wipo.int/branddb/en/)系統接口的一個典型示例,在這樣的系統中,搜索相似的圖像功能將為其提供極大便利,幫助有關專家更快地搜索到類似圖像。
1、系統應用舉例
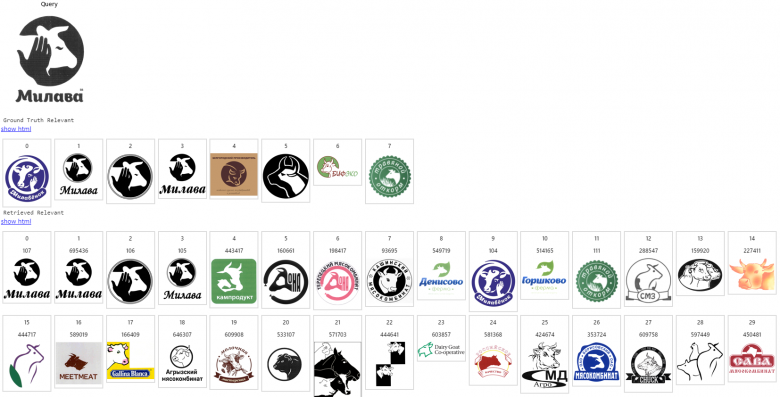
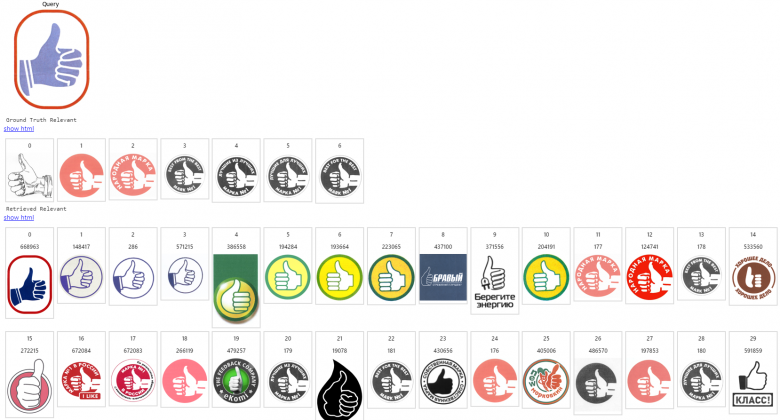
在我們開發的系統中,經索引的圖像數據庫中擁有數百萬個商標。下面給出的第一張圖片是一個查詢結果展示,下一行(第二張圖片)給出一個預期的相關圖片列表,后面其余幾行中的圖片則是搜索引擎按照相關性降低的順序給出的搜索結果。



譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。早期專注各種微軟技術(編著成ASP.NET AJX、Cocos 2d-X相關三本技術圖書),近十多年投身于開源世界(熟悉流行全棧Web開發技術),了解基于OneNet/AliOS+Arduino/ESP32/樹莓派等物聯網開發技術與 Scala+Hadoop+Spark+Flink等大數據開發技術。
原文標題:??How to Build an Image Search Engine to Find Similar Images??,作者:EORA?
















