













如何利用迪米特法則實現“高內聚、低耦合”?
1.何為“高內聚、低耦合”?
“高內聚、低耦合”能有效地提高代碼可讀性、可維護性,縮小功能改動導致的代碼改動范圍。很多設計原則也都以實現代碼“高內聚、低耦合”為目的,比如:
- 單一職責原則
- 面向接口,而非面向實現來編程
“高內聚、低耦合”是個通用設計思想,可指導:
- 不同粒度代碼的設計與開發
如系統、模塊、類,甚至函數
- 不同開發場景
- 如微服務、框架、組件、類庫等
本文主要圍繞以“類”作為該設計思想的應用對象。
- “高內聚”,指導類本身的設計
- “低耦合”,指導類與類之間依賴關系的設計
二者并非完全獨立,高內聚有助于低耦合,低耦合又需要高內聚的支持。
1.1 高內聚
- 相近的功能,應放到同一個類
- 不相近的功能,不要放到同一個類
相近的功能往往會被同時修改,放到同一類中,修改會比較集中,代碼易維護。單一職責原則就是實現代碼高內聚非常有效的設計原則。
1.2 低耦合
在代碼中,類與類之間的依賴關系簡單清晰。
即使兩個類有依賴關系,一個類的代碼改動不會或很少會導致依賴類的代碼改動。依賴注入、接口隔離、面向接口編程及迪米特法則都是為實現低耦合。
1.3 “內聚”和“耦合”的關系
左邊代碼結構是“高內聚、低耦合”;右邊“低內聚、緊耦合”:
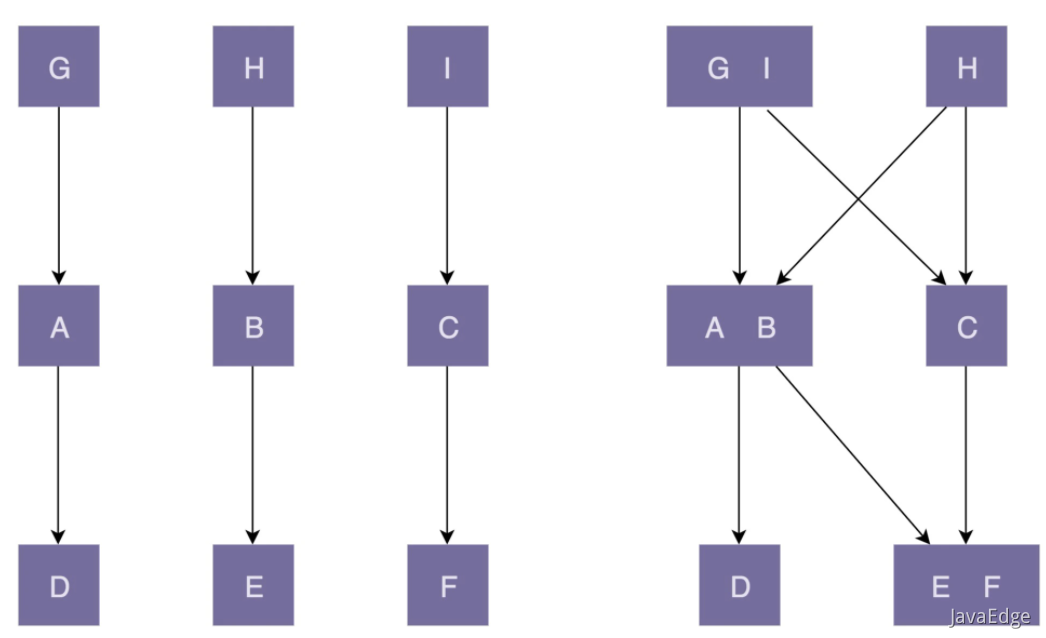
左邊的代碼設計:
類的粒度較小,每個類的職責都比較單一。相近功能都放到了一個類,不相近功能分割到多個類。這樣類更加獨立,代碼內聚性更好。
因為職責單一,所以每個類被依賴的類就會比較少,代碼低耦合。一個類的修改,只會影響到一個依賴類的代碼改動。只需要測試這一個依賴類是否還能正常工作即可。
右邊代碼設計:
類粒度比較大,低內聚,功能大而全,不相近的功能放到了一個類中。導致很多其他類都依賴該類。修改這個類的某功能代碼時,會影響依賴它的多個類。我們需要測試這三個依賴類,是否還能正常工作,“牽一發而動全身”。
2.迪米特法則
Law of Demeter,LOD,從名字看不出這是個啥。它還有另外一個名字:最小知識原則。
The Least Knowledge Principle:Each unit should have only limited knowledge about other units: only units “closely” related to the current unit. Or: Each unit should only talk to its friends; Don’t talk to strangers.
每個模塊都只應該了解那些與它關系密切的模塊(units: only units “closely” related to the current unit)的有限知識(knowledge)。或者說,每個模塊只和自己的朋友“說話”(talk),不和陌生人“說話”(tal?k)。
結合實際,定義描述中的“模塊”替換成“類”:
- 不該有直接依賴關系的類之間,不要有依賴
- 有依賴關系的類之間,盡量只依賴必要的接口(“有限知識”)
所以,迪米特法則其實包含兩部分,下面用兩個案例分別解讀。
3.案例
3.1 不該有直接依賴關系的類之間,不要有依賴
簡化的搜索引擎爬取網頁,包含如下主要類:
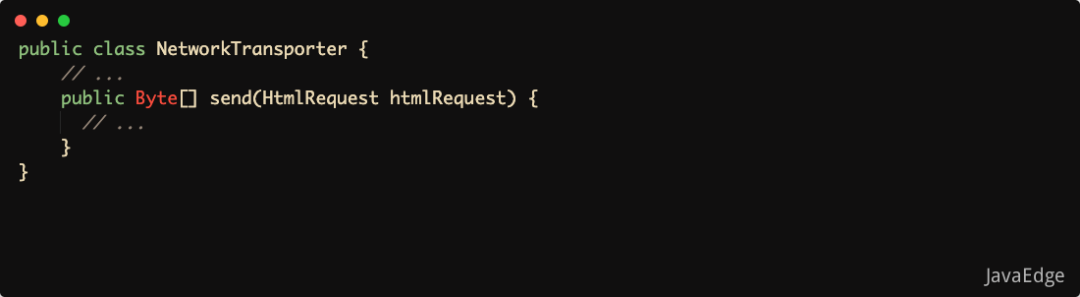
NetworkTransporter,負責底層網絡通信,根據請求獲取數據:
HtmlDownloader,通過URL獲取網頁:

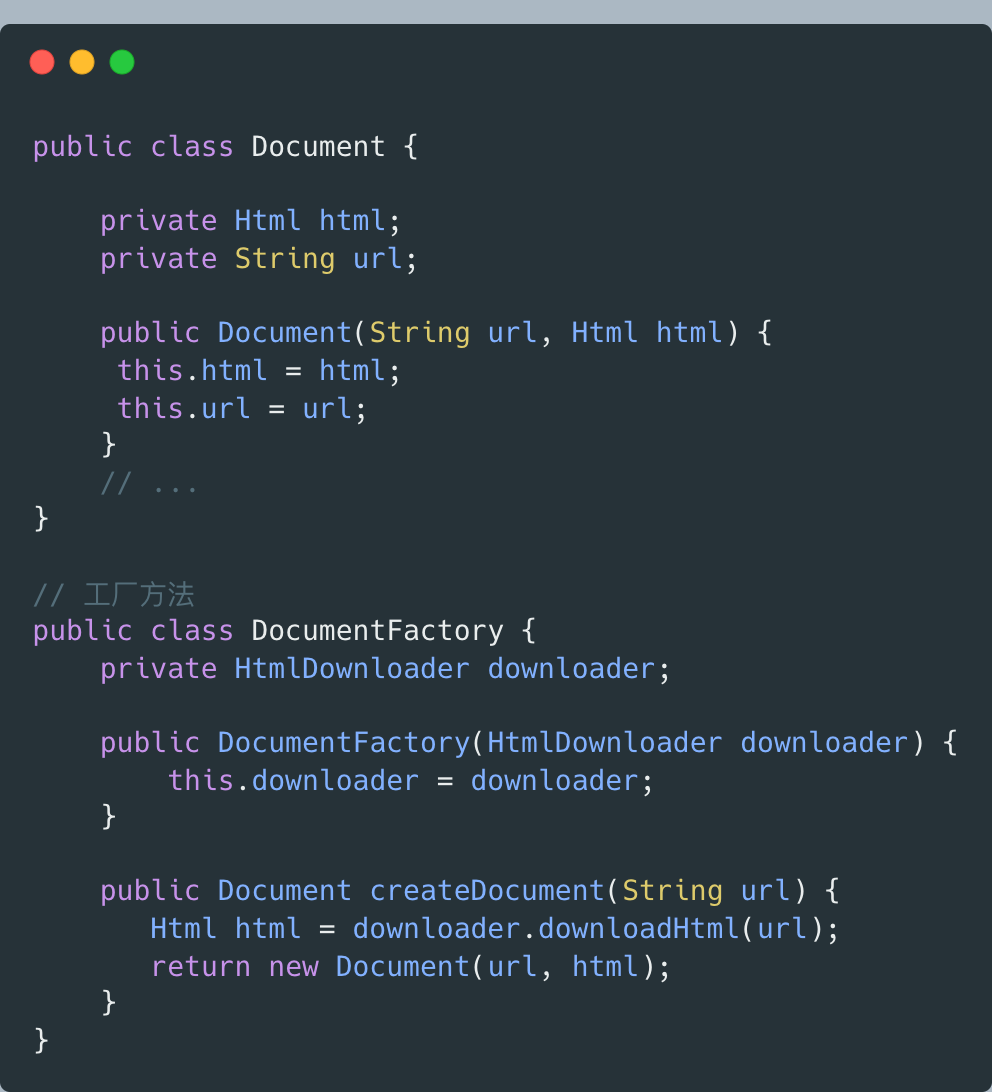
Document,表示網頁文檔,后續的網頁內容抽取、分詞、索引都是以此為處理對象:

如何重構?
這段代碼雖然“能用”,但不夠“好用”。
NetworkTransporter,作為一個底層網絡通信類,應該盡可能通用,而不是只能下載HTML。所以,不應該直接依賴太具體的發送對象HtmlRequest,其設計違背迪米特法則,依賴了不該有直接依賴關系的HtmlRequest類。
假如你現在要去買東西,你肯定不會直接把錢包給收銀員,讓收銀員自己從里面拿錢,而是你從錢包里把錢拿出來交給收銀員。HtmlRequest對象相當于錢包,HtmlRequest里的address和content對象就相當于錢。
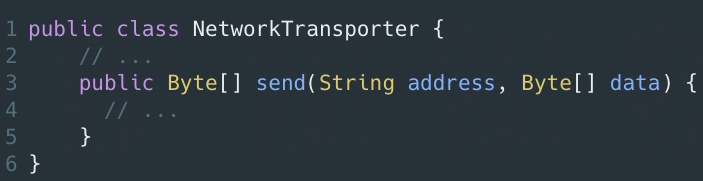
應將address和content交給NetworkTransporter,而非直接把HtmlRequest交給NetworkTransporter:
Document的問題:
- 構造器中的downloader.downloadHtml()邏輯復雜,耗時長,不應放到構造器,影響代碼可測試性
- HtmlDownloader對象在構造器通過new來創建,違反面向接口編程,也影響代碼可測試性
- 業務上說,Document網頁文檔沒必要依賴HtmlDownloader類,違背迪米特法則
問題雖多,但修改簡單:
3.2 有依賴關系的類之間,盡量只依賴必要的接口。
Serialization類負責對象的序列化和反序列化:
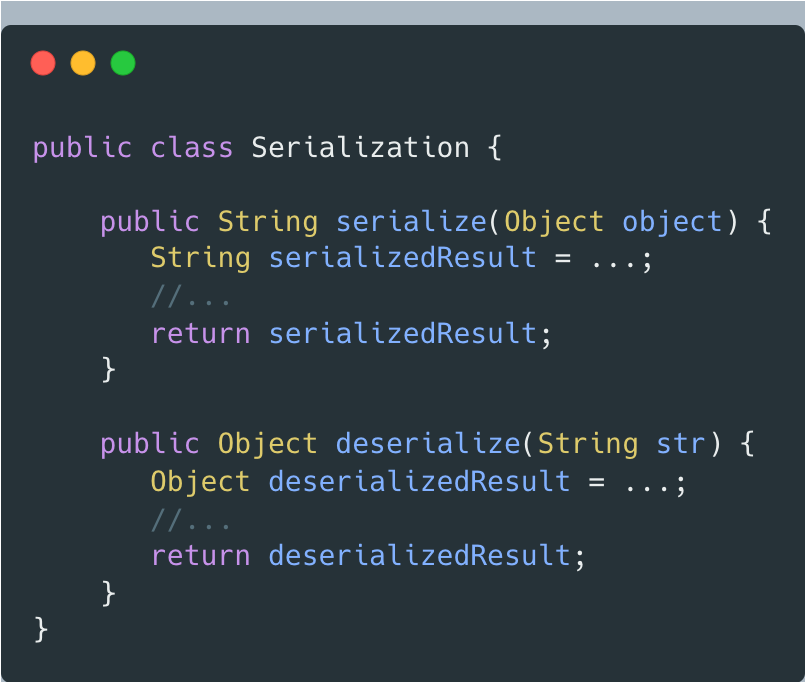
單看類的設計,沒問題。但若放到特定應用場景,假設項目中的有些類只用到序列化操作,而另一些類只用到反序列化。那么,基于 有依賴關系的類之間,盡量只依賴必要的接口:
- 只用到序列化操作的那部分類不應依賴反序列化接口
- 只用到反序列化操作的那部分類不應依賴序列化接口
據此,應將Serialization類
方案一:拆分為兩個更小粒度的類
- 只負責序列化(Serializer類)
- 只負責反序列化(Deserializer類)
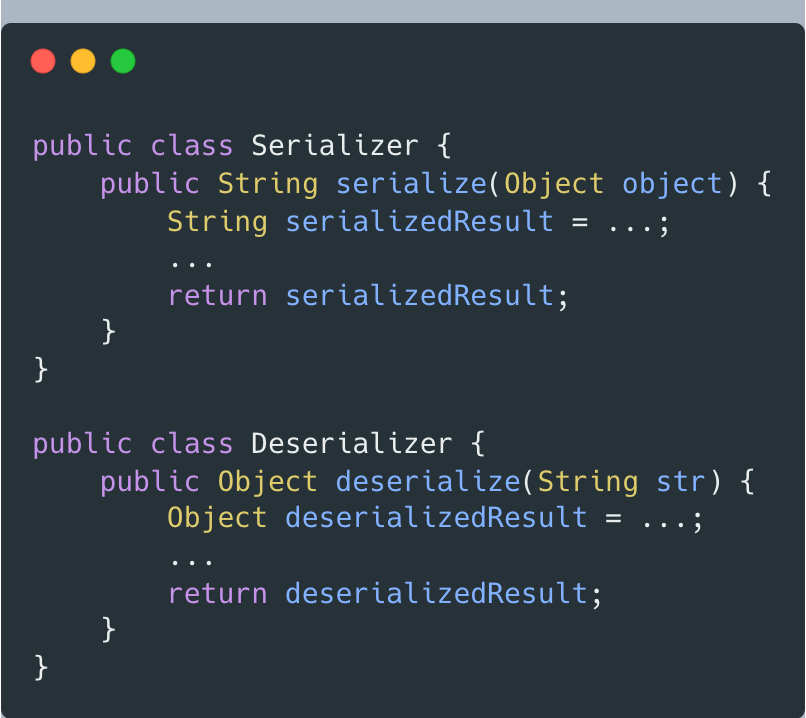
盡管拆分后的代碼更能滿足迪米特法則,但卻違背高內聚。高內聚要求相近功能放到同一類中,方便功能修改時,修改的地方不太散亂。
針對本案例,若業務要求修改序列化實現方式,從JSON換成XML,則反序列化實現邏輯也要一起改。未拆分前,只需修改一個類,拆分后,卻要修改兩個類!
既不想違背高內聚,也不想違背迪米特法則,怎么辦?
方案二:引入兩個接口
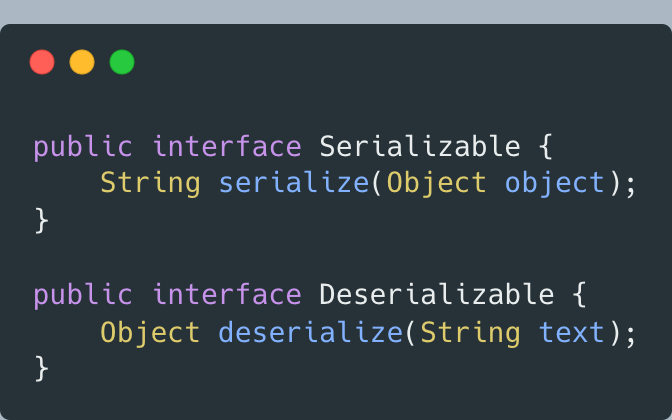
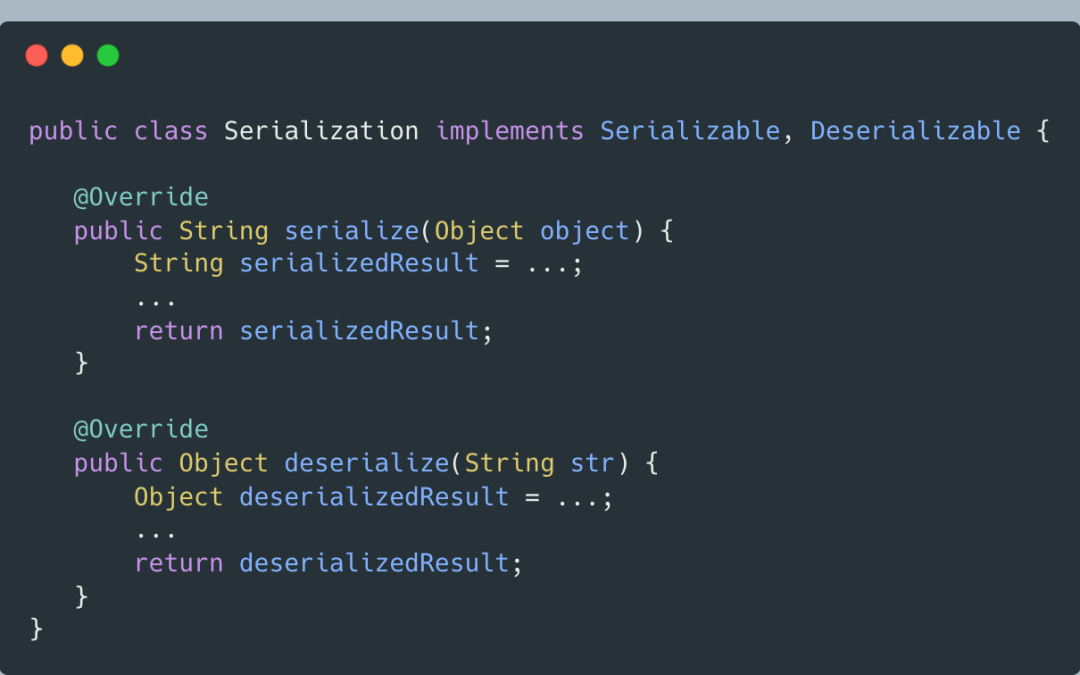
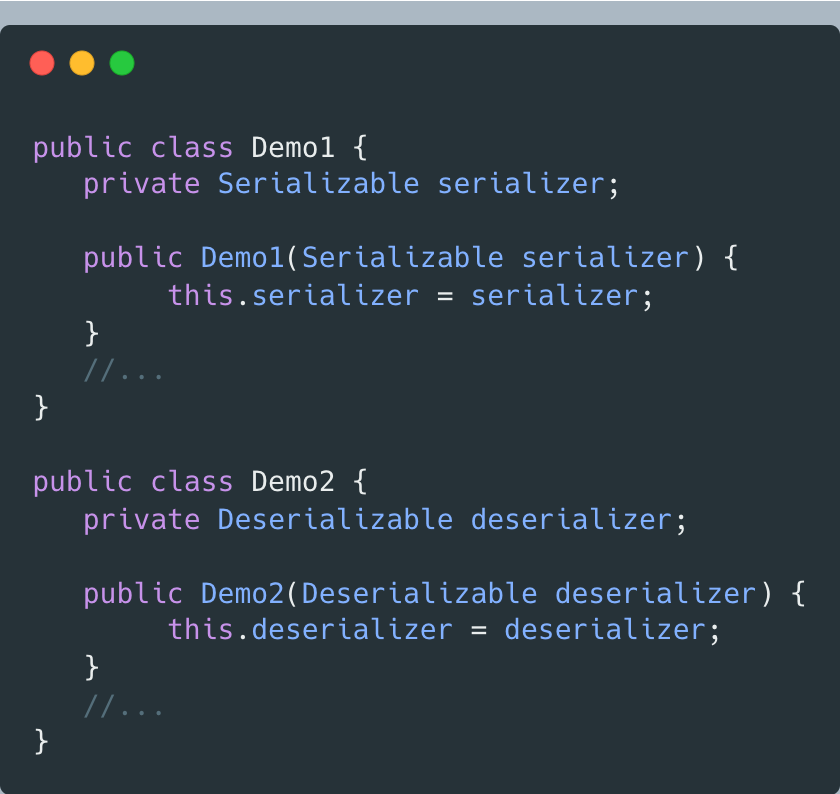
盡管還是要往Demo1的構造器傳入包含序列化和反序列化的Serialization實現類,但依賴的Serializable接口只包含序列化操作,Demo1無法使用Serialization類中的反序列化接口,對反序列化操作無感知,符合迪米特法則的“依賴有限接口”。
也體現了“面向接口編程”,結合迪米特法則,可總結出:“基于最小接口,而非最大實現來編程”。
多想一點點
本案例的重構方案,整個類只包含序列化、反序列化倆操作,只用到序列化操作的使用者,即便能夠感知到僅有的一個反序列化方法,問題也不大。為滿足迪米特法則,將一個簡單的類,拆出兩個接口,是過度設計嗎?設計原則本身無對錯,只有能否用對之說。不要為了用設計原則而用,應該具體問題具體分析。
Serialization類只包含兩個操作,確實沒啥必要拆成倆接口。但若對Serialization類添加更多功能,實現更多更好用的序列化、反序列化方法,重新考慮該問題:
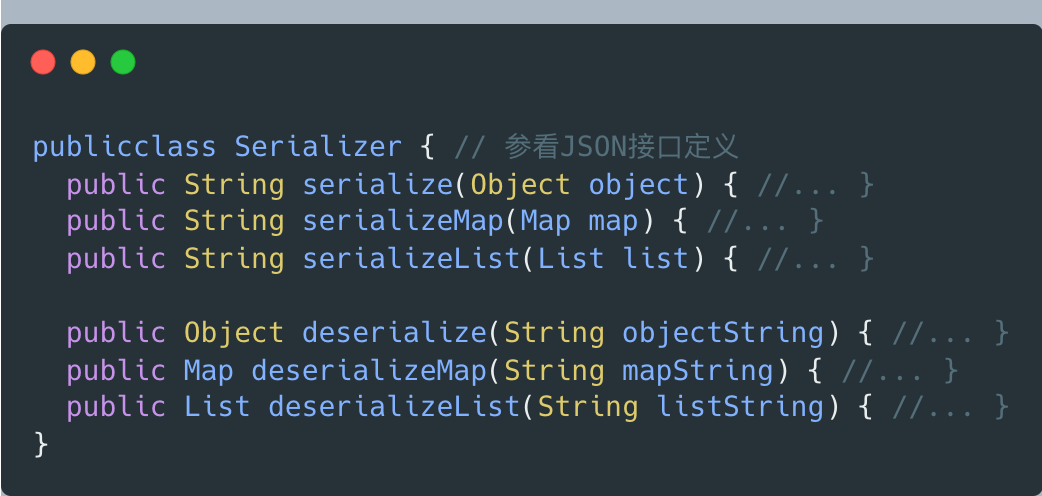
這種場景下,方案二設計更好。因為本案例的應用場景,大部分代碼只用到序列化功能,這些用戶無需了解反序列化,而修改后的Serialization類,反序列化的“知識”,從一個方法變成三個。一旦任一反序列化操作有代碼改動,都需要檢查、測試所有依賴Serialization類的代碼是否還能正常工作。
為減少耦合和降低測試的工作量,應按迪米特法則,隔離反序列化和序列化的功能。
4.總結
4.1 高內聚、低耦合
能有效提高代碼的可讀性和可維護性,縮小功能改動導致的代碼改動范圍:
- 高內聚,指導類本身的設計
就是指相近的功能應該放到同一個類中,不相近的功能不要放到同一類中。相近的功能往往會被同時修改,放到同一個類中,修改會比較集中
- 低耦合,指導類與類之間依賴關系的設計
在代碼中,類與類之間的依賴關系簡單清晰。即使兩個類有依賴關系,一個類的代碼改動也不會或者很少導致依賴類的代碼改動。
4.2 迪米特法則
不該有直接依賴關系的類之間,不要有依賴;有依賴關系的類之間,盡量只依賴必要的接口。迪米特法則希望減少類之間的耦合,讓類越獨立越好。每個類都應該少了解系統的其他部分。一旦發生變化,需要了解這一變化的類就會比較少。
參考:
[1]. 《重構》
[2]. 《代碼設計之丑》




















