作者 | 逸帆 家恒 崢少等
美團內部深度定制的TensorFlow版本,基于原生TensorFlow 1.x架構與接口,從大規模稀疏參數的支持、訓練模式、分布式通信優化、流水線優化、算子優化融合等多維度進行了深度優化。在推薦系統場景中,分布式擴展性提升10倍以上,單位算力性能也有顯著提升,并在美團內部業務中大量使用,本文介紹了相關的優化與實踐工作。
1 背景
TensorFlow(下文簡稱TF)是谷歌推出的一個開源深度學習框架,在美團推薦系統場景中得到了廣泛的使用。但TensorFlow官方版本對工業級場景的支持,目前做得并不是特別的完善。美團在大規模生產落地的過程中,遇到了以下幾方面的挑戰:
- 所有參數都是用Variable表達, 對于百億以上的稀疏參數開辟了大量的內存,造成了資源的浪費;
- 只支持百級別Worker的分布式擴展,對上千Worker的擴展性較差;
- 由于不支持大規模稀疏參數動態添加、刪除,增量導出,導致無法支持Online Learning;
- 大規模集群運行時,會遇到慢機和宕機;由于框架層不能處理,導會致任務運行異常。
以上這些問題,并不是TensorFlow設計的問題,更多是底層實現的問題。考慮到美團大量業務的使用習慣以及社區的兼容性,我們基于原生TensorFlow 1.x架構與接口,從大規模稀疏參數的支持、訓練模式、分布式通信優化、流水線優化、算子優化融合等多維度進行了深度定制,從而解決了該場景的核心痛點問題。首先新系統在支持能力層面,目前可以做到千億參數模型,上千Worker分布式訓練的近線性加速,全年樣本數據能夠1天內完成訓練,并支持Online Learning的能力。同時,新系統的各種架構和接口更加友好,美團內部包括美團外賣、美團優選、美團搜索、廣告平臺、大眾點評Feeds等業務部門都在使用。本文將重點介紹大規模分布式訓練優化的工作,希望對大家能夠有所幫助或啟發。
2 大規模訓練優化挑戰
2.1 業務迭代帶來的挑戰
隨著美團業務的發展,推薦系統模型的規模和復雜度也在快速增長,具體表現如下:
- 訓練數據:訓練樣本從到百億增長到千億,增長了近10倍。
- 稀疏參數:個數從幾百到幾千,也增長了近10倍;總參數量從幾億增長到百億,增長了10~20倍。
- 模型復雜度:越來越復雜,模型單步計算時間增長10倍以上。
對于大流量業務,一次訓練實驗,從幾個小時增長到了幾天,而此場景一次實驗保持在1天之內是基本的需求。
2.2 系統負載分析
2.2.1 問題分析工具鏈
TensorFlow是一個非常龐大的開源項目,代碼有幾百萬行之多,原生系統的監控指標太粗,且不支持全局的監控,如果要定位一些復雜的性能瓶頸點,就比較困難。我們基于美團已經開源的監控系統CAT[2],構建了TensorFlow的細粒度監控鏈路(如下圖1所示),可以精準定位到性能的瓶頸問題。
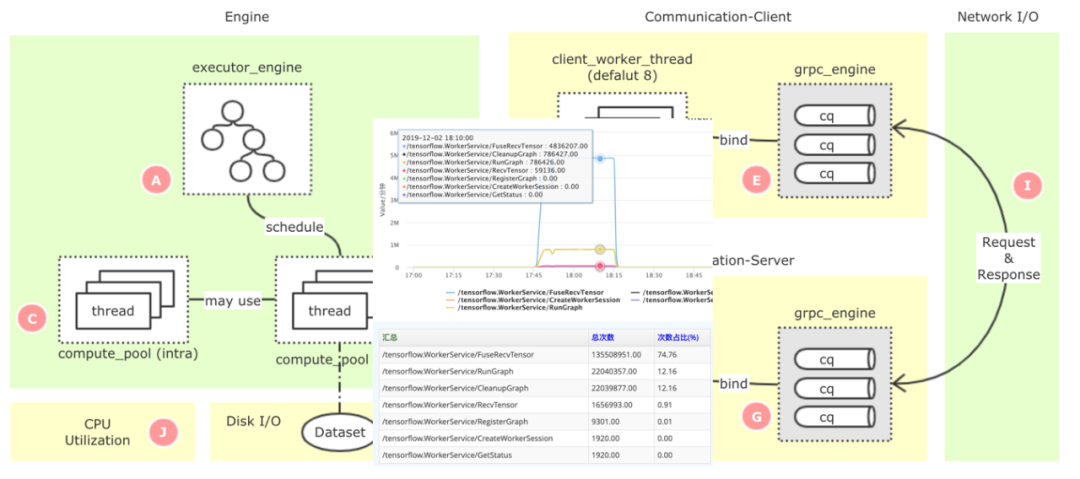
圖1 TensorFlow PS架構全鏈路監控同時,在性能優化的過程中,會涉及到大量的性能測試和結果分析,這也是一個非常耗費人力的工作。我們抽象了一套自動化的實驗框架(如下圖2所示),可以自動化、多輪次地進行實驗,并自動采集各類監控指標,然后生成報告。
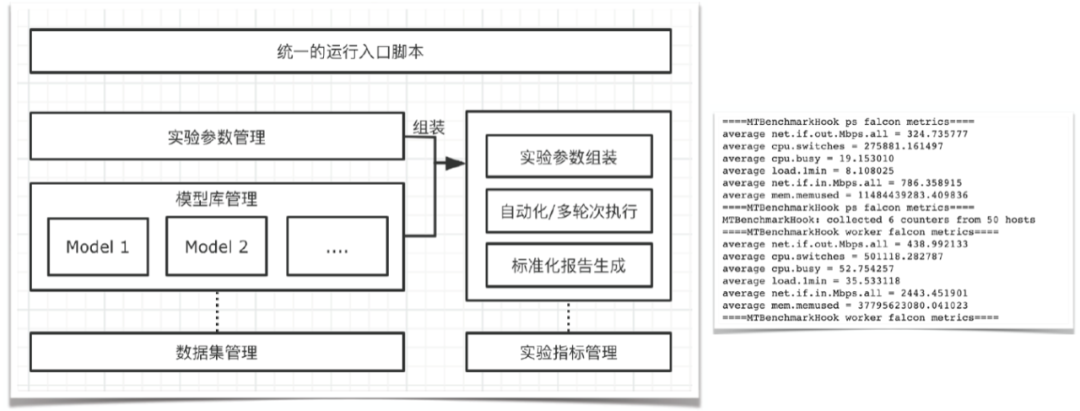
圖2 自動化實驗框架
2.2.2 業務視角的負載分析
在推薦系統場景中,我們使用了TensorFlow Parameter Server[3](簡稱PS)異步訓練模式來支持業務分布式訓練需求。對于這套架構,上述的業務變化會帶來什么樣的負載變化?如下圖3所示:
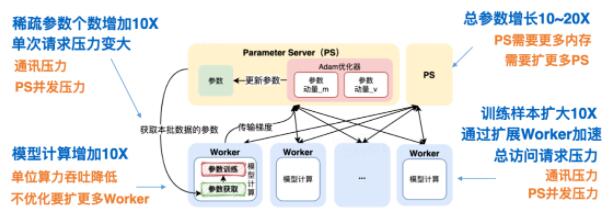

圖3 TensorFlow PS架構大規模訓練負載分析總結來看,主要包括通信壓力、PS并發壓力、Worker計算壓力。對于分布式系統來說,通常是通過橫向擴展來解決負載問題。雖然看來起可以解決問題,但從實驗結果來看,當PS擴展到一定數量后,單步訓練時間反而會增加,如下圖4所示:
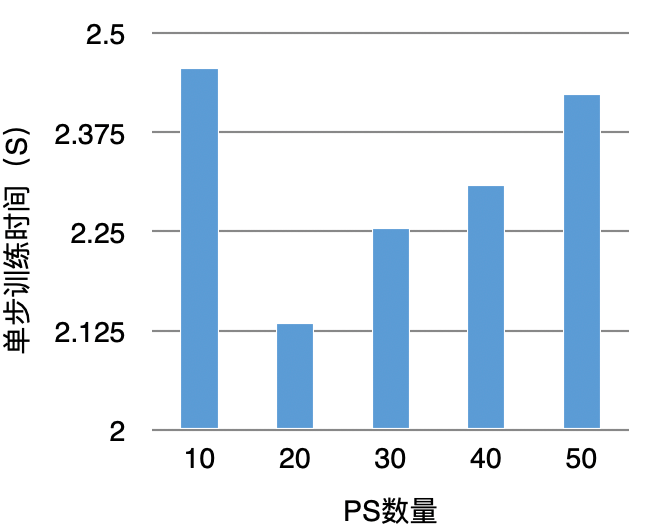
圖4 擴展PS提升訓練性能實驗
導致這種結果的核心原因是:Worker單步訓練需要和所有的PS通信同步完成,每增加1個PS要增加N條通信鏈路,這大大增加了鏈路延遲(如下圖5所示)。而一次訓練要執行上百萬、上千萬步訓練。最終導致鏈路延遲超過了加PS算力并發的收益。
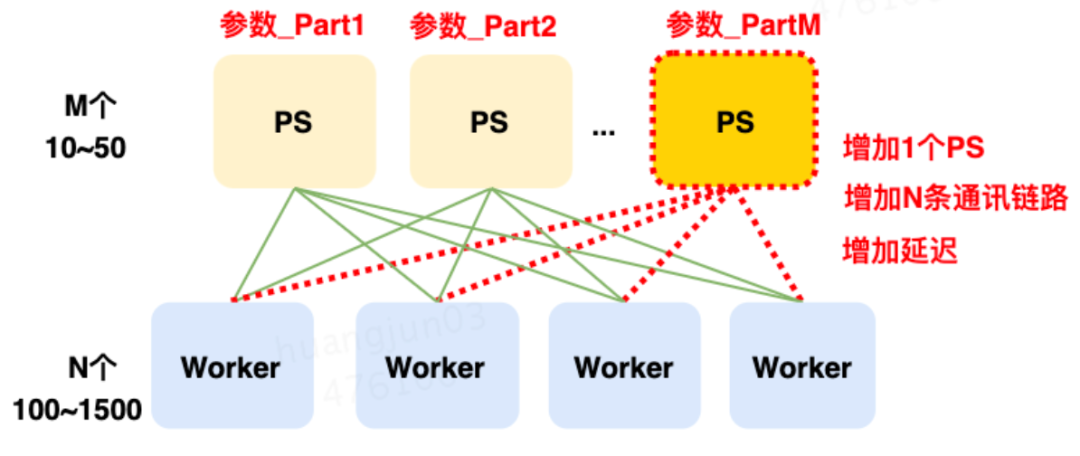
圖5 增加PS帶來的鏈路開銷而對于這個系統,優化的核心難點在于:如何在有限的PS實例下,進行分布式計算的優化。
3 優化實踐
3.1 大規模稀疏參數介紹
對于推薦系統模型,絕大多數參數都是稀疏參數,而對稀疏參數來說有一個非常重要的操作是Embedding,這個操作通常也是負載最重的,也是后續優化的重點。由于我們對稀疏參數進行了重新定義,后續的優化也基于此之上,所以我們先介紹一下這部分的工作。在原生的TensorFlow中構建Embedding模塊,用戶需要首先創建一個足夠裝得下所有稀疏參數的Variable,然后在這個Variable上進行Embedding的學習。然而,使用Variable來進行Embedding訓練存在很多弊端:
- Variable的大小必須提前設定好,對于百億千億的場景,該設定會帶來巨大的空間浪費;
- 訓練速度慢,無法針對稀疏模型進行定制優化。
我們首先解決了有無的問題,使用HashTable來替代Variable,將稀疏特征ID作為Key,Embedding向量作為Value。相比原生使用Variable進行Embedding的方式,具備以下的優勢:
- HashTable的大小可以在訓練過程中自動伸縮,避免了開辟冗余的存儲空間,同時用戶無需關注申請大小,從而降低了使用成本。
- 針對HashTable方案實施了一系列定制優化,訓練速度相比Variable有了很大的提高,可以進行千億規模模型的訓練,擴展性較好。
- 得益于稀疏參數的動態伸縮,我們在此基礎上支持了Online Learning。
- API設計上保持與社區版本兼容,在使用上幾乎與原生Variable一致,對接成本極低。
簡化版的基于PS架構的實現示意如下圖6所示:
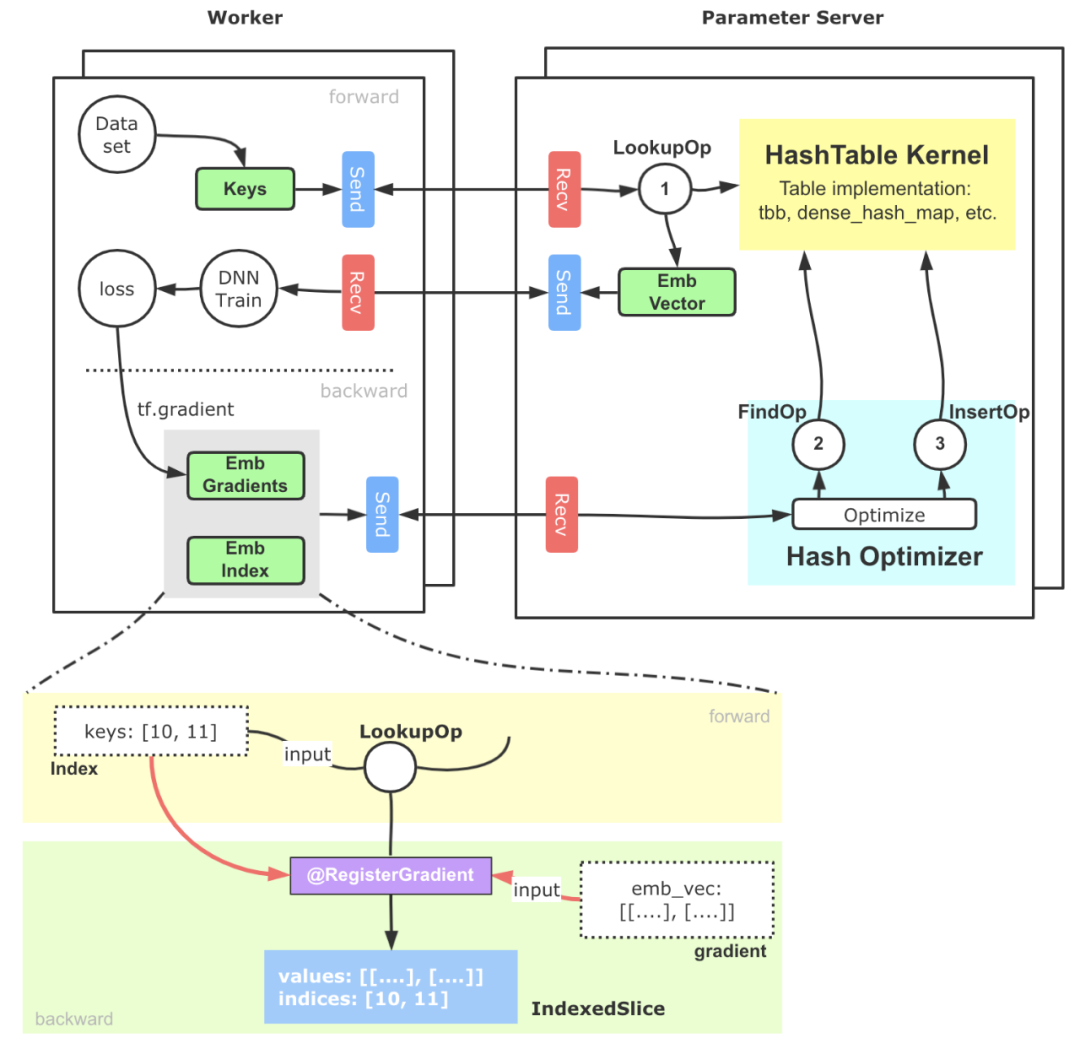
圖6 支撐大規模稀疏參數的HashTable方案核心流程大致可以分為以下幾步:
- 稀疏特征ID(通常我們會提前完成統一編碼的工作)進入Embedding模塊,借助TensorFlow搭建的Send-Recv機制,這些稀疏特征ID被拉取到PS端,PS端上的Lookup等算子會實際從底層HashTable中查詢并組裝Embedding向量。
- 上述Embedding向量被Worker拉回進行后續訓練,并通過反向傳播計算出這部分參數的梯度,這些梯度進一步被位于PS端的優化器拉回。
- PS端的優化器首先調用Find算子,從HashTable獲取到梯度對應的原始稀疏參數向量和相應的優化器參數,最終通過優化算法,完成對Embedding向量和優化器參數的更新計算,再通過Insert算子插入HashTable中。
3.2 分布式負載均衡優化
這部分優化,是分布式計算的經典優化方向。PS架構是一個典型的“水桶模型”,為了完成一步訓練,Worker端需要和所有PS完成交互,因此PS之間的平衡就顯得非常重要。但是在實踐中,我們發現多個PS的耗時并不均衡,其中的原因,既包括TensorFlow PS架構簡單的切圖邏輯(Round-Robin)帶來的負載不均衡,也有異構機器導致的不均衡。對于推薦模型來說,我們的主要優化策略是,把所有稀疏參數和大的稠密參數自動、均勻的切分到每個PS上,可以解決大多數這類問題。而在實踐過程中,我們也發現一個比較難排查的問題:原生Adam優化器,實現導致PS負載不均衡。下面會詳細介紹一下。在Adam優化器中,它的參數優化過程需要兩個β參與計算,在原生TensorFlow的實現中,這兩個β是所有需要此優化器進行優化的Variabl(或HashTable)所共享的,并且會與第一個Variable(名字字典序)落在同一個PS上面,這會帶來一個問題:每個優化器只擁有一個β和一個β,且僅位于某個PS上。因此,在參數優化的過程中,該PS會承受遠高于其他PS的請求,從而導致該PS成為性能瓶頸。
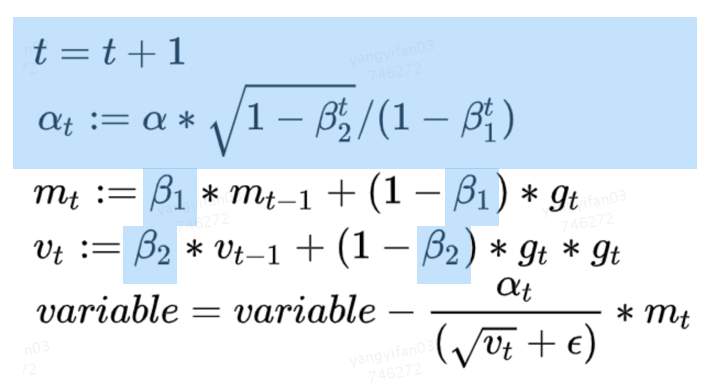
圖7 Adam優化算法但是通過觀察Adam的優化算法,我們可以看到β和β都是常量,且藍色高亮的部分都是相對獨立的計算過程,各個PS之間可以獨立完成。基于這樣的發現,優化的方法也就非常直觀了,我們為每一個PS上的Adam優化器冗余創建了β參數,并在本地計算t和alpha值,去除了因此負載不均導致的PS熱點問題。該優化所帶來的提升具備普適性且效果明顯,在美團內部某業務模型上,通過β熱點去除可以帶來9%左右的性能提升。此外,由于擺脫了對β的全局依賴,該優化還能提高PS架構的可擴展性,在擴增Worker數量的時候相比之前會帶來更好的加速比。
3.3 通信優化
通過2.2章節的分析可知,系統的通信壓力也非常大,我們主要基于RDMA做了通信優化的工作。首先簡單介紹一下RDMA,相比較于傳統基于套接字TCP/IP協議棧的通信過程,RDMA具有零拷貝、內核旁路的優勢,不僅降低了網絡的延遲,同時也降低了CPU的占用率,RDMA更適合深度學習模型的相關通信過程。RDMA主要包括三種協議Infiniband、RoCE(V1, V2)、iWARP。在美團內部的深度學習場景中,RDMA通信協議使用的是RoCE V2協議。目前在深度學習訓練領域,尤其是在稠密模型訓練場景(NLP、CV等),RDMA已經是大規模分布式訓練的標配。然而,在大規模稀疏模型的訓練中,開源系統對于RDMA的支持非常有限,TensorFlow Verbs[4]通信模塊已經很長時間沒有更新了,通信效果也并不理想,我們基于此之上進行了很多的改進工作。經過優化后的版本,在1TB Click Logs[5]公開數據集、DLRM[6]模型、100個Worker以上的訓練,性能提升了20%~40%。在美團的多個業務模型上,對比TensorFlow Seastar[7]改造的通信層實現也有10%~60%的速度提升。同時也把我們的工作回饋給了社區。
3.3.1 Memory Registration優化
RDMA有三種數據傳輸的方式SEND/RECV、WRITE、READ,其中WRITE、READ類似于數據發送方直接在遠程Memory進行讀寫,Receiver無法感知,WRITE和READ適用于批量數據傳輸。在TensorFlow內部,基于RDMA的數據傳輸方式使用的是WRITE單邊通信模式。
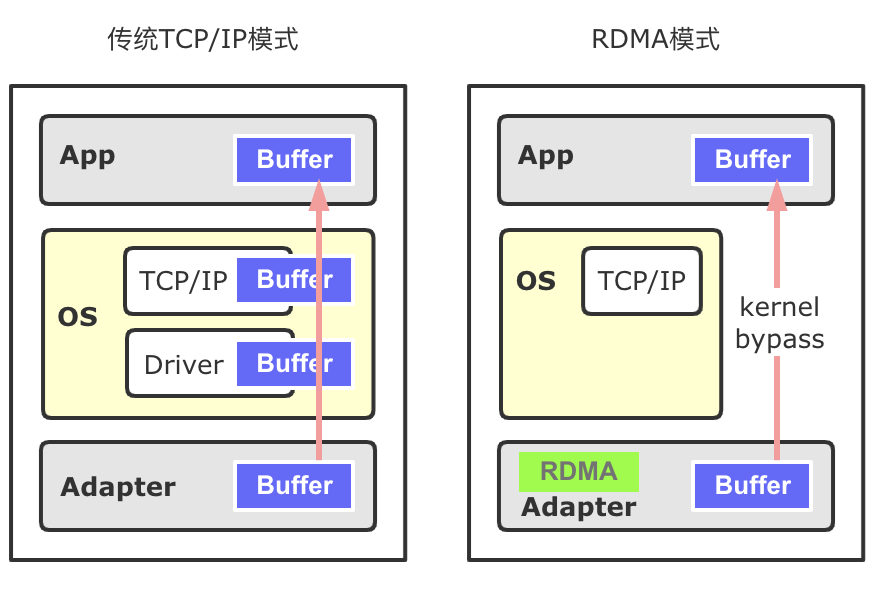
圖8 RDMA傳輸方式在RDMA傳輸數據時,需要提前開辟內存空間并將其注冊到網卡設備上(Memory Registration過程,下稱MR),使得這片空間可以被網卡直接操作。開辟新的內存并注冊到設備上,整個過程是比較耗時的。下圖9展示了不同大小的內存綁定到網卡設備上的耗時,可以看到隨著注冊內存的增大,綁定MR的耗時迅速增加。
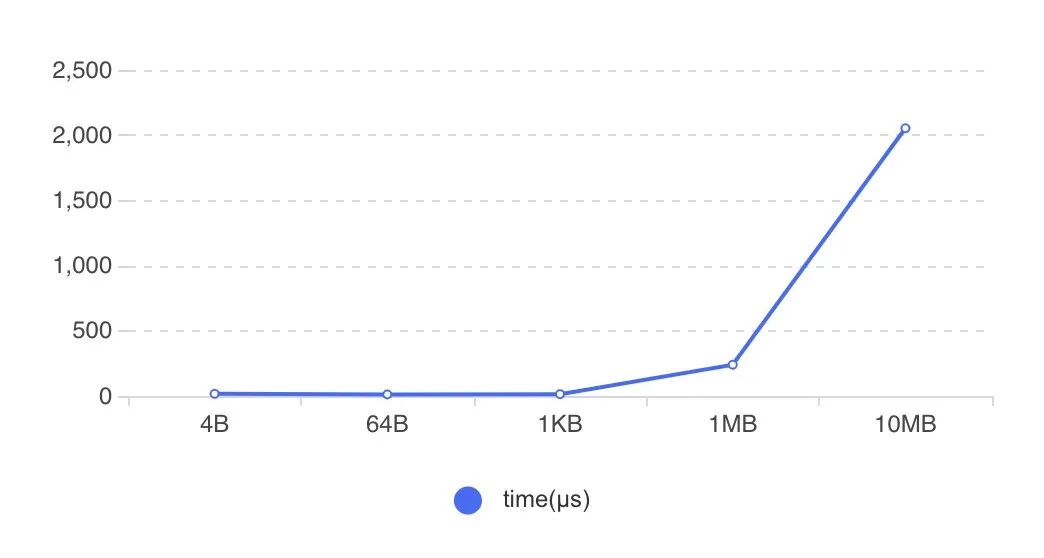
圖9 MR過程開銷社區版Tensorflow RDMA實現,Tensor創建依舊沿用了統一的BFC Allocator,并將所有創建的Tensor都注冊到MR上。正如上面所提到的,MR的注冊綁定具有性能開銷,高頻、大空間的MR注冊會帶來顯著的性能下降。而訓練過程中的Tensor,只有那些涉及到跨節點通信的Tensor有必要進行MR,其余Tensor并不需要注冊到MR。因此,優化的方法也就比較直接了,我們識別并管理那些通信Tensor,僅對這些跨節點通信的Tensor進行MR注冊就好了。
3.3.2 RDMA靜態分配器
RDMA靜態分配器是上一個MR注冊優化的延伸。通過Memory Registration優化,去除非傳輸Tensor的MR注冊,我們降低了MR注冊數量。但是在稀疏場景大規模的訓練下,并行訓練的Worker常有幾百上千個,這會帶來新的問題:
- PS架構中的PS和Worker互為Client-Server,這里以PS端為例,當Worker數目增加到上千個時,Worker數目的增多,造成PS端MR注冊頻次還是非常高,增加了內存分配注冊的耗時。
- 由于稀疏場景不同Step之間同一個算子輸出Tensor的形狀可能發生變化,導致了創建的MR可復用性較差,帶來了較高的內存碎片和重復注冊MR開銷。
針對上面的問題,我們引入了MR靜態分配器的策略。
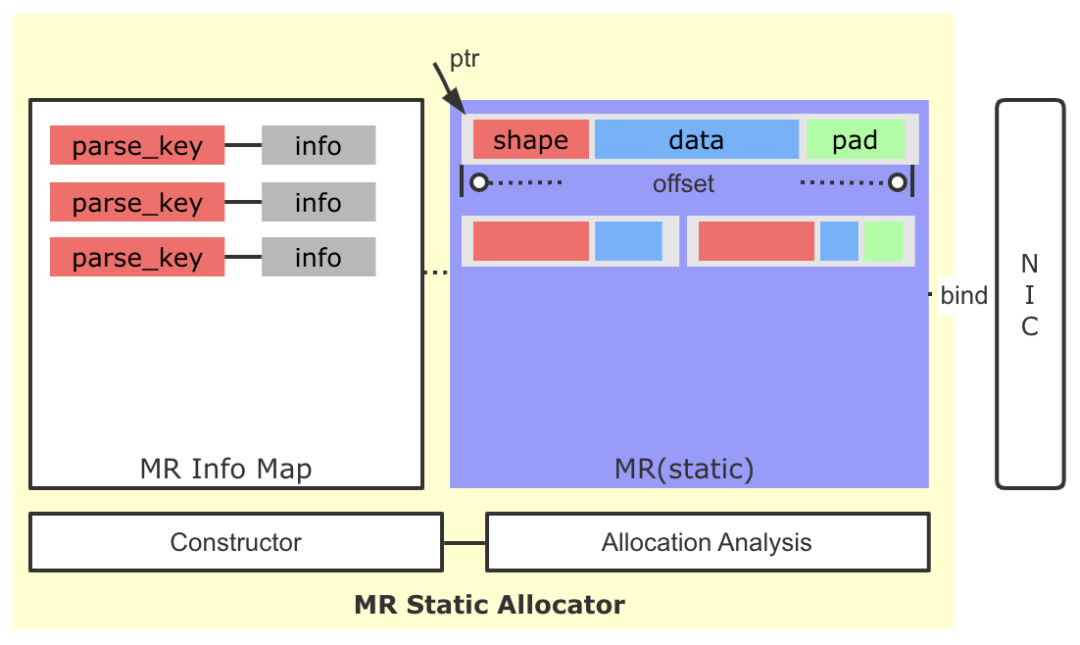
圖10 MR靜態分配器
這里核心的設計思路為:
- 雖然稀疏場景同一個算子輸出Tensor的Shape存在變化的可能,但是整體變化幅度可控,通過監控與分析,是可以找到一個較為穩定的內存大小,滿足多Step間Tensor的存儲需求。
- 基于上面的信息,我們修改了原有逐Tensor(Request)的MR申請策略,通過一次性預申請一塊較大的空間并注冊到網卡端,后續通過自己維護的分配策略進行空間的分配,大大降低了MR申請的頻率,絕大多數情況下,訓練全過程中只需要一次MR注冊申請即可。
- 我們引入了一種簡單的交換協議,將傳輸Tensor的Shape,Data打包到一起,寫到Client端。Client端根據協議,解析出Tensor大小,并最終讀取Data,避免了原生實現中因Tensor的Shape變化而產生的多次協商過程。

圖11 MR靜態分配器構造流程具體到實現中,我們引入了Allocation Analysis模塊,在訓練開始的一段時間,我們會對分配的歷史數據進行分析,以得到一個實際預開辟MR大小以及各個Tensor的預留空間大小。然后我們會暫停訓練的進程,啟動Allocator的構造過程,包括MR的創建以及通信雙端的信息同步。利用相關信息構造MR Info Map,這個Map的Key是傳輸Tensor的唯一標記(ParsedKey,計算圖切圖時確定),Info結構體中包含了本地地址指針、offset大小、ibv_send_wr相關信息等。然后恢復訓練,后續Tensor的傳輸就可以使用靜態開辟好的MR進行收發,也免去了因Shape變化而產生的多次協商過程。
3.3.3 Multi RequestBuffer與CQ負載均衡
TensorFlow社區版的RDMA通信過程,不僅僅包含上面Tensor數據的發送和接收過程,還包括傳輸相關的控制消息的發送和接收過程,控制消息的發送和接收過程同樣是使用了ibv_post_send和ibv_post_recv原語。原生的控制流實現存在一些瓶頸,在大規模訓練時會限制控制流的吞吐,進而影響數據收發的效率。具體體現在:
- 請求的發送通過同一片RequestBuffer內存進行寫出,多個Client的請求均依賴這一片Buffer,也就導致到控制流信息實際是串行發送的,只有等到對端的Ack信息后,才可以下一個Request的寫出,限制了請求的發送吞吐。
- 在Client端需要輪詢RDMA Completion Queue來獲得請求的到達,以及相關狀態的變更。原生實現僅有一個Completion Queue,單線程進行輪詢處理,在大規模分布式訓練中,限制了應答的效率。
針對上面的問題,我們采用了Multi RequestBuffer與CQ負載均衡優化,破除了在請求發送和請求應答環節可能存在的吞吐瓶頸。
3.3.4 Send-Driven & Rendezvous-Bypass
對于Tensorflow PS架構熟悉的同學會了解,一整張計算圖被切割為Worker端和PS端后,為了使兩張計算圖能夠彼此交換數據,建立了基于Rendezvous(匯合點)機制的異步數據交換模式。如下圖12所示:
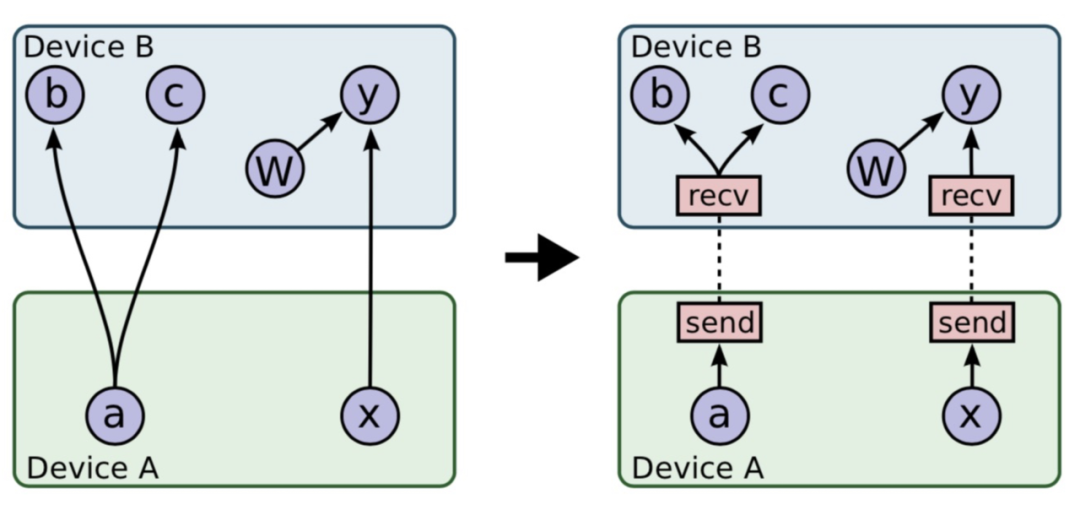
圖12 TensoFlow切圖之Send-Recv對添加基于上圖的切圖邏輯,Recv算子代表著這一側計算圖有Tensor的需求,而Tensor的生產者則位于與之配對的另一設備上的Send算子背后。在具體實現上,Tensorflow實現了Recv-Driven的數據交換模式,如上圖所示,位于DeviceA和DeviceB的兩張計算圖會異步并發的執行,位于DeviceB的Recv執行時會發起一條RPC請求發往DeviceA,DeviceA收到請求后,會將請求路由到Rendezvous中,如果在當中發現所需要的數據已經生產好,并被Send算子注冊了進來,那么就地獲取數據,返回給DeviceB;如果此時數據還沒有生產好,則將來自于DeviceB的Recv請求注冊在Rendezvous中,等待后續DeviceA生產好后,由Send算子發送過來,找到注冊的Recv,觸發回調,返回數據給DeviceB。我們看到,匯合點機制優雅地解決了生產者消費者節奏不同情況下數據交換的問題。不過Recv-Driven的模式也引入了兩個潛在的問題:
- 據我們的觀察,在實際業務模型中,在Rendezvous中Recv算子等待Send算子的比例和Send算子等待Recv算子的比例相當,也就是說對于Send等到Recv的數據,在Send準備好的那一剎那就可以發給對端,但是由于機制實現問題,還是等待Recv算子過來,才將數據拉取回去,通信過程耗時較長。
- Rendezvous作為一個數據交換的熱點,它內部的邏輯開銷并不低。
針對上面提到的問題,我們在RDMA上實現了另外一種數據交換的模式,叫做Send-Driven模式。與Recv-Driven模式相對,顧名思義就是有Send算子直接將數據寫到Recv端,Recv端接收數據并注冊到本地Rendezvous中,Recv算子直接從本地的Rendezvous中獲取數據。具體流程如下圖13所示:
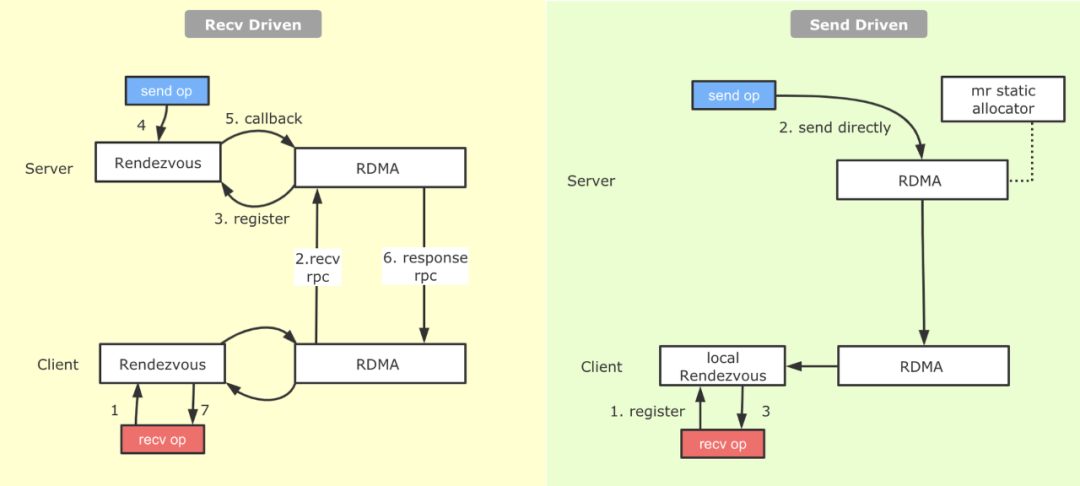
圖13 原生的Recv-Driven與補充的Send-Driven機制從圖中可以看到,相較于Recv-Driven模式,Send-Driven模式的通信流程得到了比較大的簡化,另外在數據ready后立即發送的特性,跳過了一側的Rendezvous,并且對于生產者先于消費者的情況,可以加快消費端數據獲取的速度。
3.4 延遲優化
這部分優化,也是分布式計算的經典優化方向。整個流程鏈路上那些可以精簡、合并、重疊需要不斷去挖掘。對于機器學習系統來說,相比其它的系統,還可以用一些近似的算法來做這部分工作,從而獲得較大的性能提升。下面介紹我們在兩個這方面做的一些優化實踐。
3.4.1 稀疏域參數聚合
在啟用HashTable存儲稀疏參數后,對應的,一些配套參數也需要替換為HashTable實現,這樣整個計算圖中會出現多張HashTable以及大量的相關算子。在實踐中,我們發現需要盡量降低Lookup/Insert等算子的個數,一方面降低PS的負載,一方面降低RPC QPS。因此,針對稀疏模型的常見用法,我們進行了相關的聚合工作。以Adam優化器為例,需要創建兩個slot,以保存優化中的動量信息,它的Shape與Embedding相同。在原生優化器中,這兩個Variable是單獨創建的,并在反向梯度更新的時候會去讀寫。同理,使用HashTable方案時,我們需要同時創建兩張單獨的HashTable用來訓練m、v參數。那么在前向,反向中需要分別對Embedding、 m、v進行一次Lookup和一次Insert,總共需要三次Lookup和三次Insert。這里一個優化點就是將Embedding、 m、v,以及低頻過濾的計數器(見下圖14的Counting HashTable)聚合到一起,作為HashTable的Value,這樣對稀疏參數的相關操作就可以聚合執行,大大減少了稀疏參數操作頻次,降低了PS的壓力。
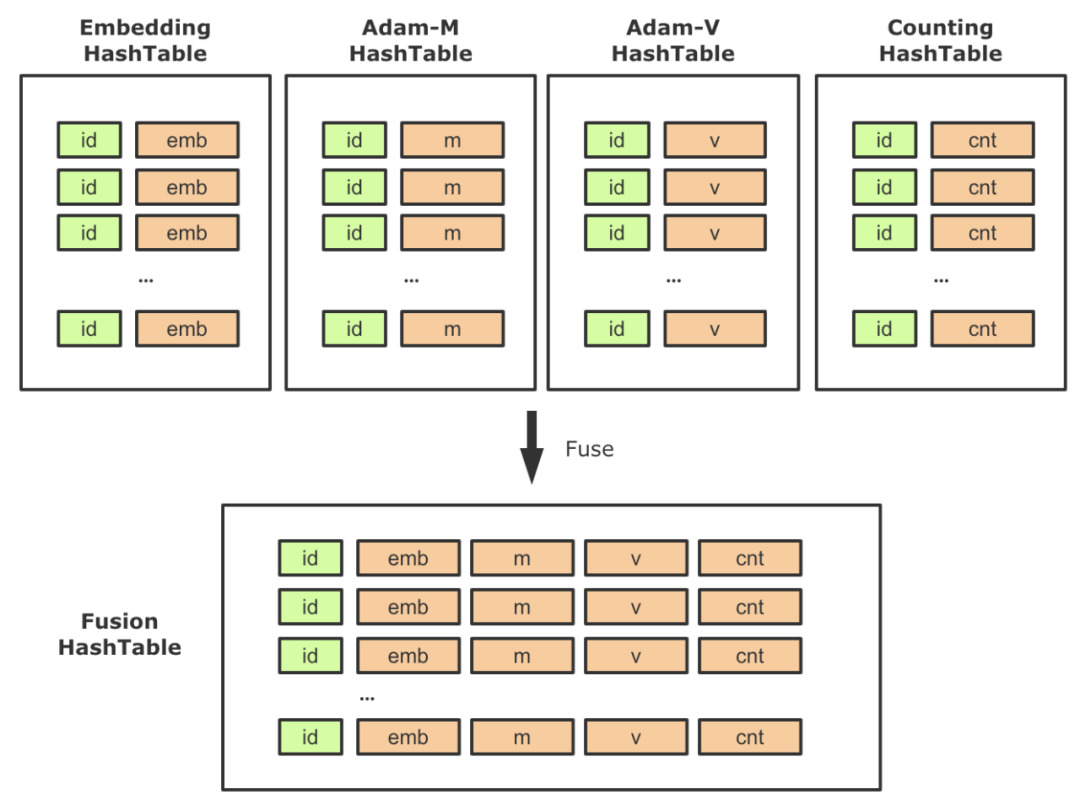
圖14 基于HashTable的參數融合策略該特性屬于一個普適型優化,開啟聚合功能后,訓練速度有了顯著的提高,性能提升幅度隨著模型和Worker規模的變化,效果總是正向的。在美團內部真實業務模型上,聚合之后性能相比非聚合方式能提升了45%左右。
3.4.2 Embedding流水線優化
流水線,在工業生產中,指每一個生產單位只專注處理某個片段的工作,以提高工作效率及產量的一種生產方式。在計算機領域內,更為大家熟知的是,流水線代表一種多任務之間Overlap執行的并行化技術。例如在典型的RISC處理器中,用戶的程序由大量指令構成,而一條指令的執行又可以大致分為:取指、譯碼、執行、訪存、寫回等環節。這些環節會利用到指令Cache、數據Cache、寄存器、ALU等多種不同的硬件單元,在每一個指令周期內,這5個環節的硬件單元會并行執行,得以更加充分的利用硬件能力,以此提高整個處理器的指令吞吐性能。處理器的指令流水線是一套復雜而系統的底層技術,但其中的思想在分布式深度學習框架中也被大量的使用,例如:
- 如果將分布式訓練簡單的抽象為計算和通信兩個過程,絕大多數主流的深度學習框架都支持在執行計算圖DAG時,通信和計算的Overlap。
- 如果將深度模型訓練簡單的分為前向和反向,在單步內,由于兩者的強依賴性,無法做到有效并行,字節BytePS[8]中引入的通信調度打破了step iteration間的屏障,上一輪的部分參數更新完畢后,即可提前開始下輪的前向計算,增強了整體視角下前反向的Overlap。
- 百度AIBox[9]為了解決CTR場景GPU訓練時,參數位于主存,但計算位于GPU的問題,巧妙調度不同硬件設備,搭建起了主要利用CPU/主存/網卡的參數預準備階段和主要利用GPU/NVLink的網絡計算階段,通過兩個階段的Overlap達到更高的訓練吞吐。
我們看到,在深度學習框架設計上,通過分析場景,可以從不同的視角發掘可并行的階段,來提高整體的訓練吞吐。對于大規模稀疏模型訓練時,核心模型流程是:先執行稀疏參數的Embedding,然后執行稠密部分子網絡。其中稀疏參數Embedding在遠端PS上執行,主要耗費網絡資源,而稠密部分子網絡在本地Worker執行,主要耗費計算資源。這兩部分占了整個流程的大部分時間,在美團某實際業務模型上分別耗時占比:40%+、50%+。那我們是否可以提前執行稀疏參數的Embedding,來做到通信和計算的Overlap,隱藏掉這部分時間呢?從系統實現上肯定是可行的,但從算法上講,這樣做會引入參數Staleness的問題,可能會導致模型精度受到影響。但在實際的生產場景中,大規模異步訓練時本身就會帶來幾十到幾百個步的滯后性問題。經過我們測試,提前獲取一兩步的稀疏參數,模型精度并未受到影響。在具體實現上,我們把整個計算圖拆分為Embedding Graph(EG)和Main Graph(MG)兩張子圖,兩者異步獨立執行,做到拆分流程的Overlap(整個拆分過程,可以做到對用戶透明)。EG主要覆蓋從樣本中抽取Embedding Key,查詢組裝Embedding向量,Embedding向量更新等環節。MG主要包含稠密部分子網絡計算、梯度計算、稠密參數部分更新等環節。
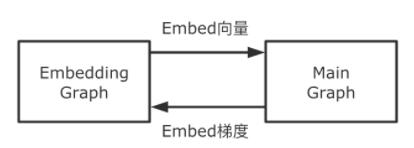

圖15 Embedding流水線模塊交互關系兩張子圖的交互關系為:EG向MG傳遞Embeding向量(從MG的視角看,是從一個稠密Variable讀取數值);MG向EG傳遞Embedding參數對應的梯度。上述兩個過程的表達都是TensorFlow的計算圖,我們利用兩個線程,兩個Session并發的執行兩張計算圖,使得兩個階段Overlap起來,以此到達了更大的訓練吞吐。
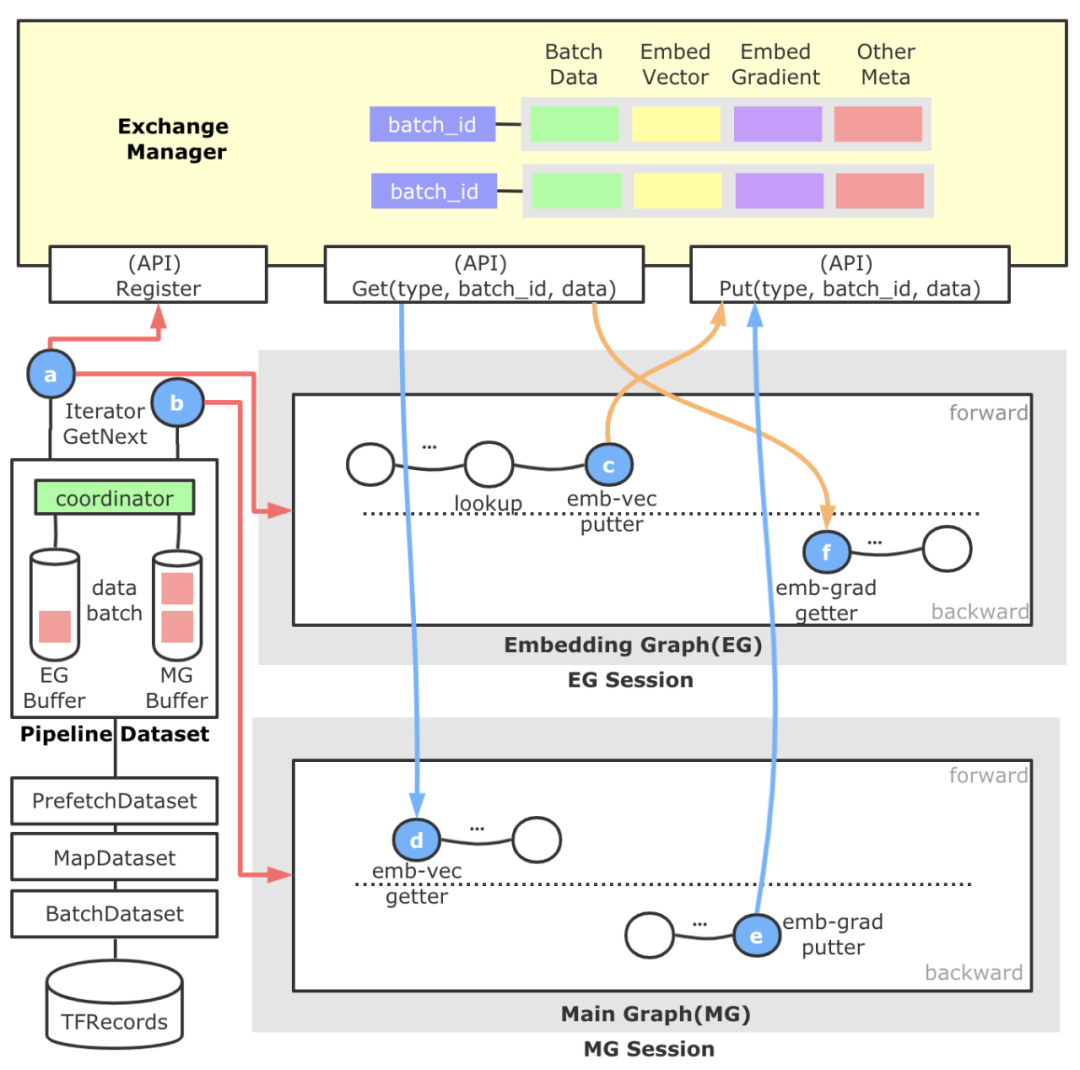
圖16 Embedding流水線架構流程圖上圖是Embedding流水線的架構流程圖。直觀來看分為左側的樣本分發模塊,頂部的跨Session數據交換模塊,以及自動圖切分得到的Embedding Graph和Main Graph,藍色的圓圈代表新增算子,橙色箭頭代表EG重點流程,藍色箭頭代表MG重點流程,紅色箭頭代表樣本數據重點流程。
- 以對用戶透明的形式引入了一層名為Pipeline Dataset的抽象層,這一層的產生是為了滿足EG/MG兩張計算圖以不同節奏運行的需求,支持自定義配置。另外,為了使得整個流水線中的數據做到彼此的配套,這里還會負責進行一個全局Batch ID的生成及注冊工作。Pipeline Dataset對外暴露兩種Iterator,一個供EG使用,一個供MG使用。Pipeline Dataset底部共享TensorFlow原生的各層Dataset。
- 頂部的ExchangeManager是一個靜態的,跨Session的數據交換媒介,對外暴露數據注冊和數據拉取的能力。抽象這個模塊的原因是,EG和MG原本歸屬于一張計算圖,因為流水線的原因拆解為拆為兩張圖,這樣我們需要建立一種跨Session的數據交換機制,并準確進行配套。它內部以全局Batch ID做Key,后面管理了樣本數據、Embeding向量、Embedding梯度、Unique后的Index等數據,并負責這些數據的生命周期管理。
- 中間的Embedding Graph由獨立的TF Session運行于一個獨立的線程中,通過a算子獲得樣本數據后,進行特征ID的抽取等動作,并進行基于HashTable方法的稀疏參數查詢,查詢結果通過c算子放置到ExchangeManager中。EG中還包含用于反向更新的f算子,它會從ExchangeManager中獲取Embedding梯度和與其配套的前向參數,然后執行梯度更新參數邏輯。
- 下面的Main Graph負責實際稠密子網絡的計算,我們繼承并實現一種可訓練的EmbeddingVariable,它的構建過程(d算子)會從ExchangeManager查找與自己配套的Embedding向量封裝成EmbeddingVariable,給稠密子網絡。此外,在EmbeddingVariable注冊的反向方法中,我們添加了e算子使得Embedding梯度得以添加到ExchangeManager中,供EG中的f算子消費。
通過上面的設計,我們就搭建起了一套可控的EG/MG并發流水線訓練模式。總體來看,Embedding流水線訓練模式的收益來源有:
- 經過我們對多個業務模型的Profiling分析發現,EG和MG在時間的比例上在3:7或4:6的左右,通過將這兩個階段并行起來,可以有效的隱藏Embedding階段,使得MG網絡計算部分幾乎總是可以立即開始,大大加速了整體模型的訓練吞吐。
- TensorFlow引擎中當使用多個優化器(稀疏與非稀疏)的時候,會出現重復構建反向計算圖的問題,一定程度增加了額外計算,通過兩張子圖的拆分,恰好避免了這個問題。
- 在實施過程中的ExchangeManager不僅負責了Embedding參數和梯度的交換,還承擔了元數據復用管理的職責。例如Unique等算子的結果保存,進一步降低了重復計算。
另外,在API設計上,我們做到了對用戶透明,僅需一行代碼即可開啟Embedding流水線功能,對用戶隱藏了EG/MG的切割過程。目前,在美團某業務訓練中,Embedding流水線功能在CPU PS架構下可以帶來20%~60%的性能提升(而且Worker并發規模越大,性能越好)。
3.5 單實例PS并發優化
經過2.2章節的分析可知,我們不能通過持續擴PS來提升分布式任務的吞吐,單實例PS的并發優化,也是非常重要的優化方向。我們主要的優化工作如下。
3.5.1 高性能的HashTable
PS架構下,大規模稀疏模型訓練對于HashTable的并發讀寫要求很高,因為每個PS都要承擔成百乃至上千個Worker的Embedding壓力,這里我們綜合速度和穩定性考慮,選用了tbb::concurrent_hash_map[10]作為底層HashTable表實現,并將其包裝成一個新的TBBConcurrentHashTable算子。經過測試,在千億規模下TBBConcurrentHashTable比原生MutableDenseHashTable訓練速度上快了3倍。
3.5.2 HashTable BucketPool
對于大規模稀疏模型訓練來說,Embedding HashTable會面對大量的并發操作,通過Profiling我們發現,頻繁動態的內存申請會帶來了較大性能開銷(即使TensorFlow的Tensor有專門的內存分配器)。我們基于內存池化的思路優化了HashTable的內存管理。我們在HashTable初始化時,會先為Key和Value分別創造兩個BucketPool,每個池子都會先Malloc較大一塊內存備用,考慮到可能會有對HashTable進行中的Key和Value進行Remove的場景(如Online Learning訓練時),需要對從HashTable中刪除的Key和Value所使用的內存進行回收,因此每個BucketPool還有一個ReuseQueue來負責維護回收的內存。每次向內部的哈希表數據結構中Insert Key和Value的時候,Key和Value內存和釋放分配都進行池化管理。用這種方式降低了大規模稀疏訓練中遇到稀疏內存分配開銷,整體端到端訓練性能提升了5%左右。
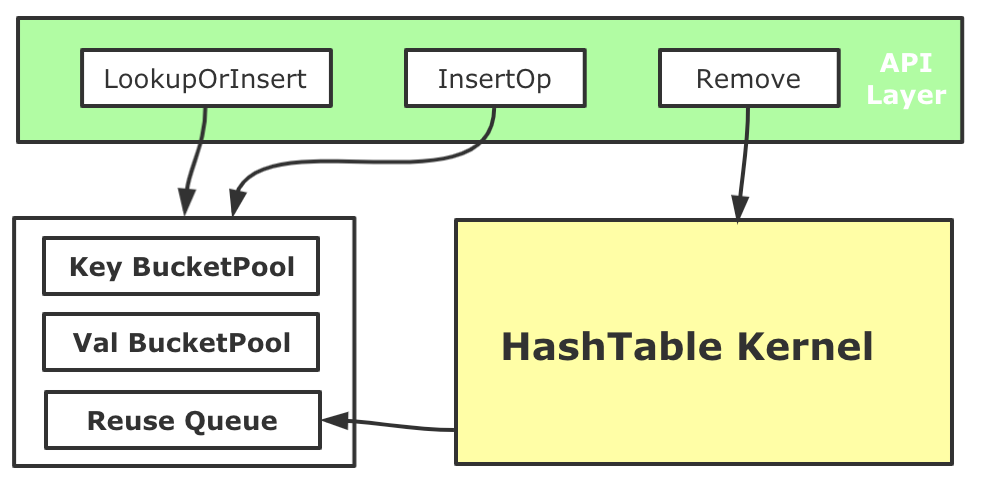
圖17 HashTable內存優化
3.6 單位算力吞吐優化
經過2.2章節的分析,Worker的計算壓力也非常大,如果不優化Worker,同時要保持吞吐,需要橫向擴展更多的Worker,給PS帶來更大的壓力。而對于用戶來說,如果能在有限的計算資源下帶來性能提升,對業務價值更高。我們通過CAT統計出了一些高頻算子,并進行了專項優化。這里選取Unique&DynamicPartition算子融合案例進行分享。在TensorFlow PS架構中,包括Embedding向量在內的共享參數都存儲在PS上,并通過網絡與Worker交互,在進行Embedding查詢過程中,往往會涉及如下兩個環節:
- 由于稀疏參數的性質,從樣本中抽取得到的待查詢Embedding ID,它的重復率往往高達70%~90%,如果不進行去重查詢,不論是對HashTable的查詢還是網絡的傳輸,都會帶來不小的壓力。因此,通常會在查詢前進行Unique操作。
- 在大規模稀疏場景中,為了存儲千億規模的參數,會有多個PS機器共同承載。而Worker端會負責對查詢請求按照設定的路由規則進行切分,這里通常會在查詢前進行DynamicPartition動作。
通常這兩個過程會利用TensorFlow既有的算子進行搭建,但在實際使用中,我們發現它并不是很高效,主要問題在于:
- Unique算子原生實現,它內部使用的內存分配策略較為低效。使用了兩倍輸入參數(Embedding ID)的大小進行內存分配,但由于輸入參數較大,而且重復率高,導致HashTable創建過大且非常稀疏。幾乎每次插入都會產生一次minor_page_fault,導致HashTable性能下降。我們使用Intel Vtune驗證了這一點(參見圖18)。
- Unique和Dynamic Partition算子存在冗余數據遍歷,這些操作其實可以在一次數據遍歷中全部做完,節省掉算子切換、冗余數據遍歷的耗時。

圖18 Unique算子內部出現DRAM Bound問題總結來說,HashTable開辟過大會導致大量的minor_page_fault,導致訪存的時間增加,HashTable過小又可能會導致擴容。我們采用了基于啟發式算法的內存自適應Unique算子實現,通過對訓練歷史重復率的統計,我們可以得到一個相對合理的HashTable大小,來提高訪存的性能;另外Unique算子內HashTable的具體選擇上,經過我們的多種測試,選擇了Robin HashTable替換了原生TF中的實現。進一步,我們對圍繞Embedding ID的Unique和Partition環節進行了算子合并,簡化了邏輯實現。經過上述的優化,Unique單算子可以取得51%的加速,在真實模型端到端上可以獲得10%左右的性能提升,算子總數量降低了4%。在整個關鍵算子優化的過程中,Intel公司的林立凡、張向澤、高明進行大量的技術支持,我們也復用了他們的部分優化工作,在此深表感謝!
4 大規模稀疏算法建模
大規模稀疏能力在業務落地的過程中,算法層面還需要從特征和模型結構上進行對應升級,才能拿到非常好的效果。其中外賣廣告從業務特點出發,引入大規模稀疏特征完成外賣場景下特征體系的升級,提供了更高維的特征空間和參數空間,增強了模型的擬合能力。重新設計了面向高維稀疏場景的特征編碼方案,解決了特征編碼過程中的特征沖突問題,同時編碼過程去掉了部分冗余的特征哈希操作,一定程度上簡化了特征處理邏輯,并降低了特征計算的耗時。在系統層面,面對百億參數、百億樣本以上量級的大規模稀疏模型的訓練,會帶來訓練迭代效率的大大降低,單次實驗從一天以內,增長到一周左右。美團機器學習平臺訓練引擎團隊,除了上述TensorFlow框架層面的優化、還針對業務模型進行了專項優化,整體吞吐優化了8到10倍(如果投入更多計算資源,可以進一步加速),大大提升業務的迭代效率,助力外賣廣告業務取得了較為明顯的提升。
5 總結與展望
TensorFlow在大規模推薦系統中被廣泛使用,但由于缺乏大規模稀疏的大規模分布式訓練能力,阻礙了業務的發展。美團基于TensorFlow原生架構,支持了大規模稀疏能力,并從多個角度進行了深度優化,做到千億參數、千億樣本高效的分布式訓練,并在美團內部進行了大規模的使用。對于這類關鍵能力的缺失,TensorFlow社區也引起了共鳴,社區官方在2020年創建了SIG Recommenders[11],通過社區共建的方式來解決此類問題,美團后續也會積極的參與到社區的貢獻當中去。美團推薦系統場景的模型訓練,目前主要運行在CPU上,但隨著業務的發展,有些模型變得越來越復雜,CPU上已經很難有優化空間(優化后的Worker CPU使用率在90%以上)。而近幾年,GPU的計算能力突飛猛進,新一代的NVIDIA A100 GPU,算力達到了156TFLOPS(TF32 Tensor Cores)、80G顯存、卡間帶寬600GB/s。對于這類復雜模型的Workload,我們基于A100 GPU架構,設計了下一代的分布式訓練架構,經過初步優化,在美團某大流量業務推薦模型上也拿到了較好的效果,目前還在進一步優化當中,后續我們會進行分享,敬請期待。
6 作者簡介
逸帆、家恒、崢少、鵬鵬、永宇、正陽、黃軍等,來自美團基礎研發平臺,機器學習平臺訓練引擎組,主要負責美團分布式機器學習訓練系統的性能優化與能力建設。
海濤,來自美團外賣廣告策略團隊,主要負責美團外賣廣告業務的算法探索和策略落地工作。