MySQL 主備延遲有哪些坑?主備切換策略
大家好,我是Tom哥!
作為一名開發同學,大家對 MySQL 一定不陌生,像常見的 事務特性、隔離級別 、索引等也都是老生常談。
今天,我們就來聊個深度話題,關于 MySQL 的 高可用。
一、什么是高可用?
維基百科定義:
高可用性(high availability,縮寫 HA),指系統無中斷地執行其功能的能力,代表系統的可用性程度。高可用性通常通過提高系統的容錯能力來實現。
MySQL 的高可用是如何實現的呢?
首先,我們來看張圖:
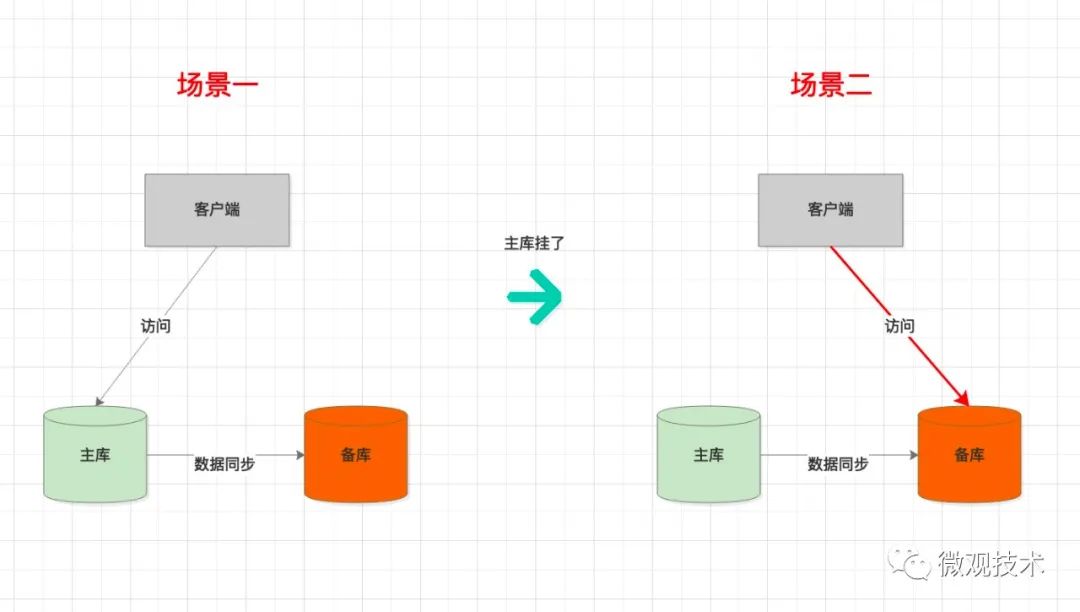
過程:
- 開始時,處理流程主要是 場景一;
- 客戶端讀、寫,訪問的是主庫;
- 主庫通過某種機制,將數據實時同步給備庫;
- 當主庫突然發生故障(如:磁盤損壞等),無法正常響應客戶端的請求。此時會自動主備切換,進入 場景二;
- 客戶端讀寫,訪問的是備庫(此時備庫升級為新主庫);
看似天衣無縫,那是不是可以高枕無憂了呢???兄弟,想多了。
主備切換,確實能滿足高可用。但有個前提,主備庫的數據要同步。
不過,數據同步是個異步操作,不可能做到實時,所以說主備延遲是一定存在的。
二、什么是主備延遲?
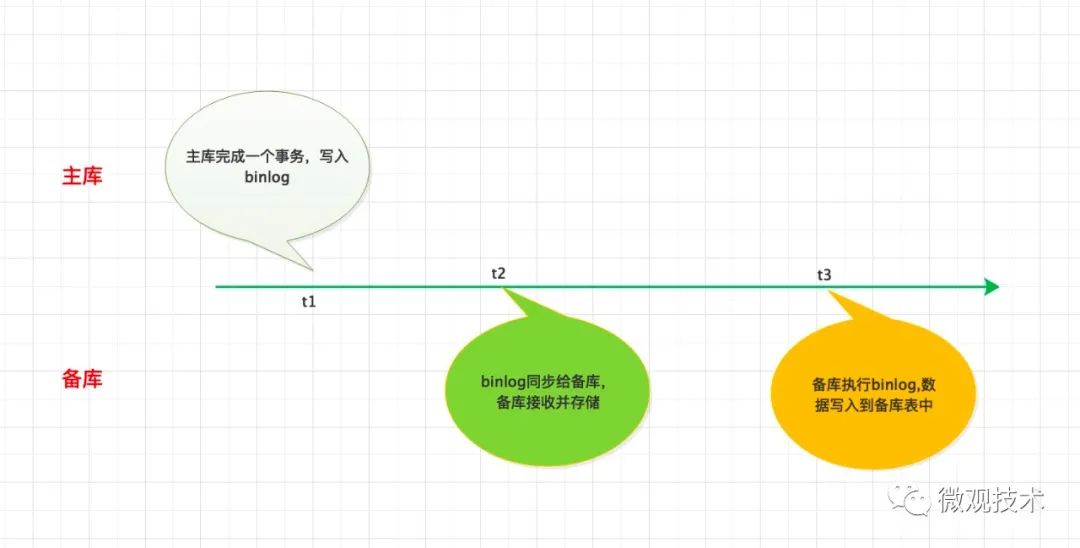
主庫完成一個事務,寫入binlog。binlog 中有一個時間字段,用于記錄主庫寫入的時間【時刻 t1】;
- binlog 同步給備庫,備庫接收并存儲到中繼日志 【時刻 t2】;
- 備庫SQL執行線程執行binlog,數據寫入到備庫表中 【時刻 t3】;
主備延遲時間計算公式:t3 - t1
有沒有簡單命令,直接查看。在備庫執行 show slave status 命令。
seconds_behind_master,表示當前備庫延遲了多少秒。
心細的同學會有疑問了, t3 和 t1 分屬于兩臺機器,如果時鐘不一致怎么辦?
初始化時,備庫連接到主庫,會執行 SELECT UNIX_TIMESTAMP() 來獲得當前主庫的系統時間。
如果發現主庫的系統時間與備庫不一致,備庫在計算 seconds_behind_master 會自動減掉這個差值。
注意:
binlog 數據傳輸的時間(t2 - t1)非常短,可以忽略。主要延遲花費在備庫執行binlog日志。
三、主備延遲常見原因
1.備庫機器配置差
這個不難理解,“門當戶對”、“志同道合”,如果主備機器的性能差別大,直接導致備庫的同步速度跟不上主庫的生產節奏。
就像跑步一樣,落后差距會越來越大。
解決方案:升級備庫的機器配置
2.備庫干私活
備庫除了服務于正常的讀業務外,是否有被其他特殊業務征用,如:運營數據統計等,這類操作非常消耗系統資源,也會影響數據同步速度。
解決方案:可以借助大數據平臺,數據異構,滿足各種這些特殊的統計類查詢。
3.大事務
我們知道 binglog 是在事務提交時才生成的。
如果是處理大事務,執行時間比較長(比如 5分鐘)。雖然備庫很快拿到 binlog,但是在備庫回放執行也要花費差不多的時間,也要 5分鐘 (備庫中,只有這個事務執行完提交,備庫才真正對外可見),從而導致主備延遲很大。
比如 delete 操作,慎用 delete from 表名,建議采用分批刪除,減少大事務。
四、主庫不可用,主備切換有哪些策略?
1.可靠優先
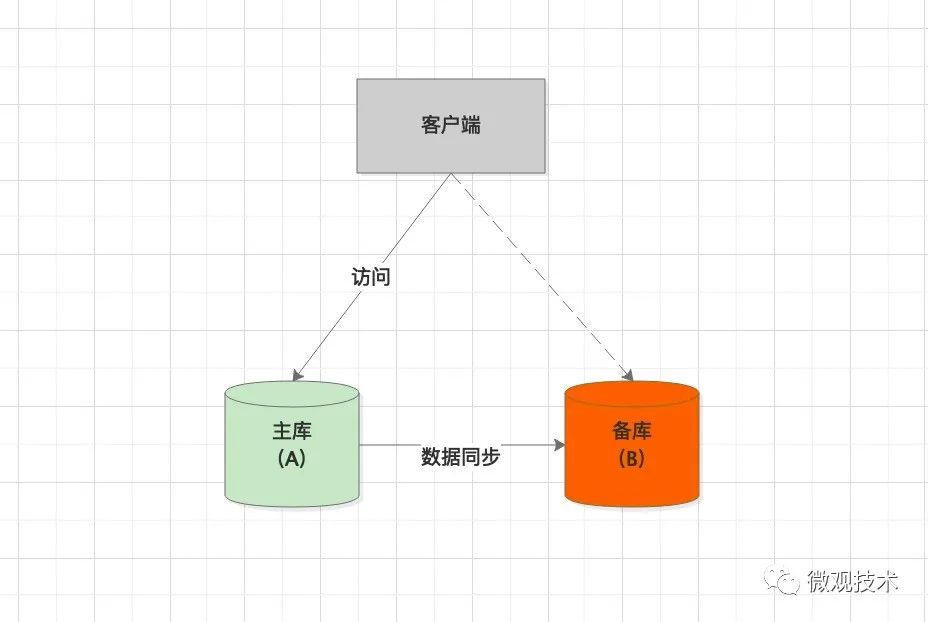
當主庫A 發生故障不可用時,開始進入主備切換。
- 首先,判斷 B庫 seconds_behind_master 是否小于設定的閾值(比如 4 秒),如果滿足條件
- 將 A庫 改為只讀狀態,將 readonly 設置為 true。斷掉 A 庫的寫入操作,保證不會有新的寫流量進來
- 判斷 B庫的 seconds_behind_master ,直到為 0
- 修改 B庫 為 讀、寫狀態
- 客戶端的請求打到 B庫
此時,主備切換完成。
優點:
數據不會丟失,所以我們稱為可靠性高。
缺點:
中間有個階段,A庫和B庫都是只讀狀態,此時系統對外不能提供寫服務。
2.可用優先
當然我們也可以不用等主備數據同步完成,在一開始時就直接將流量切到備庫。
這樣備庫的流量就可能有兩個來源:
- 主庫之前的剩余流量 binlog;
- 客戶端新請求進來的流量。
兩部分流量沖擊,會對 數據一致性 造成一些影響。
我們來做個實驗:
首次創建一個用戶表:
CREATE TABLE `person` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(32) ,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
插入2條記錄:
insert into person(name) values ("tom");
insert into person(name) values ("jerry");
實驗一:
將 binlog 的格式設為 binlog_format=row;
說明:row 模式,寫 binlog 時會記錄所有字段的值;
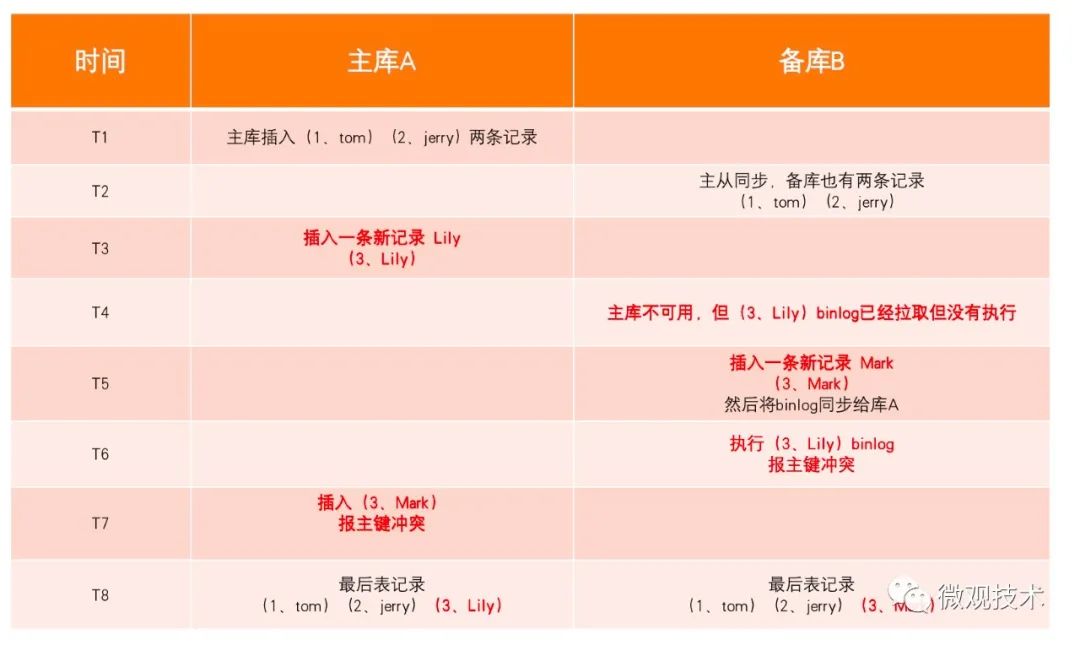
庫A 、庫B 在做數據同步時,都會報主鍵沖突,最后只有一行數據不一致,但是會丟數據。
優點:同步過程中,出現問題能夠及時發現。
實驗二:
將 binlog 格式設置為 statement 或者 mixed;
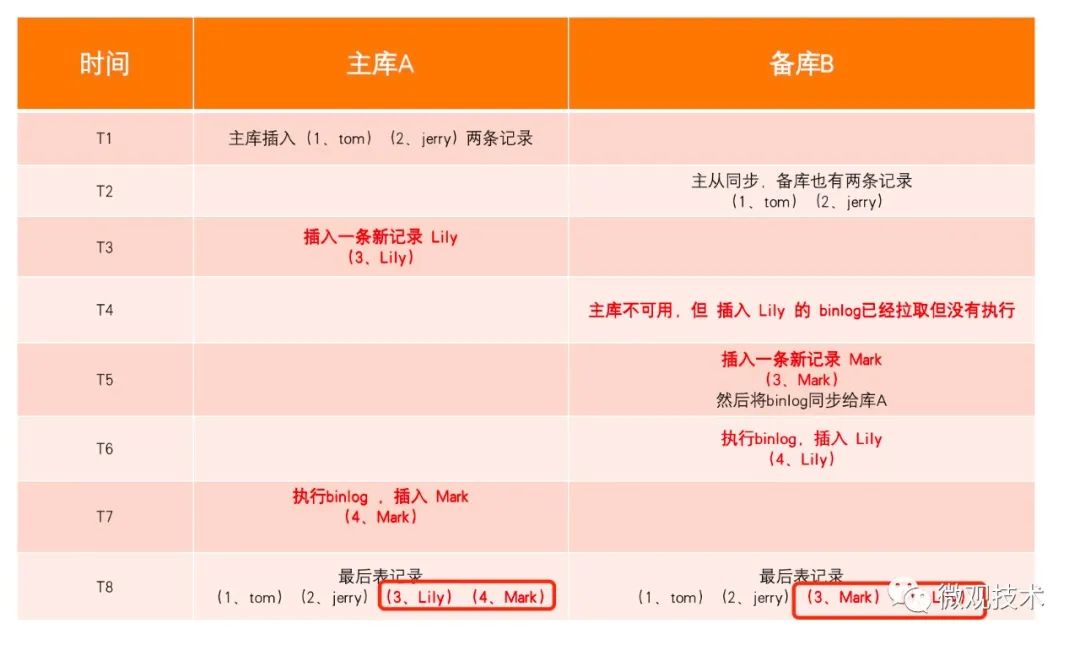
按照 SQL 原始語句同步 binlog,可以看到,數據條數不會少,但是主鍵id會出現混亂。
3.結論
本著 "攘外必先安內" ,保證內部的數據的正確性是我們的首選。所以,一般建議大家選擇 可靠優先。
但是可靠優先可能會導致一定時間內,數據庫不可用。這個時間值取決于主備延遲的時間大小。
所以,我們應盡可能縮短主備庫的延遲時間大小,這樣一旦主庫發生故障,備庫才會更快的同步完數據,主備切換才能完成,服務才能更快恢復。