上海交大發布「人類行為理解引擎」:AI逐幀理解大片中每個動作
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
看圖看片,對現在的AI來說早已不是什么難事。
不過讓AI分析視頻中的人類動作時,傳統基于目標檢測的方法會碰到一個挑戰:
靜態物體的模式與行為動作的模式有很大不同,現有系統效果很不理想。
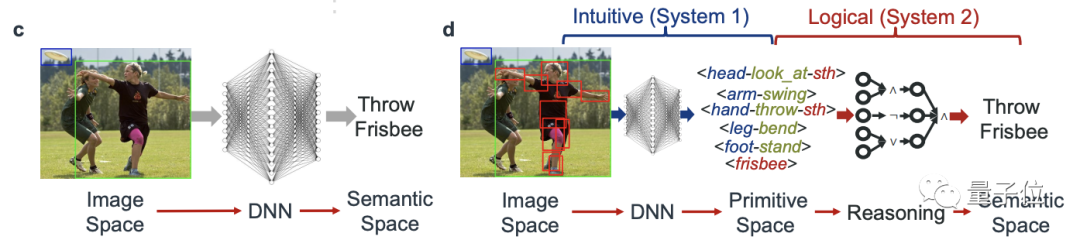
現在,來自上海交大的盧策吾團隊基于這一思路,將整個任務分為了兩個階段:
先將像素映射到一個“基元活動”組成的過度空間,然后再用可解釋的邏輯規則對檢測到的基元做推斷。
△
左:傳統方法,右:新方法
新方法讓AI真正看懂劇里的卷福手在舉杯(hold),右邊的人在伸手掏東西(reach for):

對于游戲中的多人場景也能準確分辨每一個角色的當前動作:

甚至連速度飛快的自行車運動員都能完美跟隨:

能夠像這樣真正理解視頻的AI,就能在醫療健康護理、指引、警戒等機器人領域應用。
這篇論文的一作為上海交大博士李永露,曾在CVPR 2020連中三篇論文。
目前相關代碼已開源。
知識驅動的行為理解
要讓AI學習人類,首先要看看人類是怎么識別活動的。
比如說,要分辨走路和跑步,我們肯定會優先關注腿部的運動狀態。
再比如,要分辨一個人是否是在“喝水”,那么他的手是否在握杯,隨后頭又是否接觸杯子,這些動作就成為了一個判斷標準。
這些原子性的,或者說共通的動作就可以被看作是一種“基元”(Primitive)。

我們正是將一個個的基元“組合”推理出整體的動作,這就是就是人類的活動感知。
那么AI是否也能基于發現這種基元的能力,將其進行組合,并編程為某個具有組合概括性的語義呢?
因此,盧策吾團隊便提出了一種知識驅動的人類行為知識引擎,HAKE(Human Activity Knowledge Engine)。
這是一個兩階段的系統:
- 將像素映射到由原子活動基元跨越的中間空間
- 用一個推理引擎將檢測到的基元編程為具有明確邏輯規則的語義,并在推理過程中更新規則。
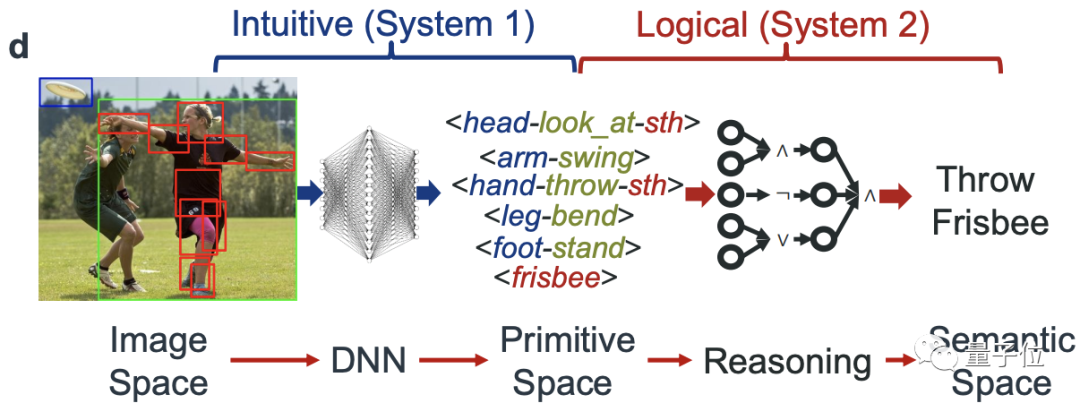
整體來說,上述兩個階段也可以分為兩個任務。
首先是建立一個包括了豐富的活動-基元標簽的知識庫,作為推理的“燃料”。
在于702位參與者合作之后,HAKE目前已有35.7萬的圖像/幀,67.3萬的人像,22萬的物體基元,以及2640萬的PaSta基元。

其次,是構建邏輯規則庫和推理引擎。
在檢測到基元后,研究團隊使用深度學習來提取視覺和語言表征,并以此來表示基元。
然后,再用可解釋的符號推理按照邏輯規則為基元編程,捕獲因果的原始活動關系。
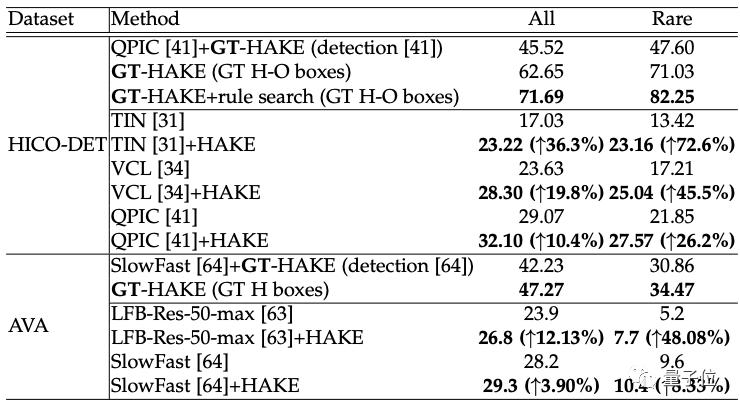
在實驗中,研究者選取了建立在HICO基礎上,包含4.7萬張圖片和600次互動的HICO-DET,以及包含430個帶有時空標簽的視頻的AVA,這兩個大規模的基準數據集。
在兩個數據集上進行實例級活動檢測:即同時定位活動的人/物并對活動進行分類。
結果,HAKE,在HICO-DET上大大提升了以前的實例級方法,特別是在稀有集上,比TIN提高了9.74mAP(全類平均精度),HAKE的上限GT-HAKE也優于最先進的方法。
在AVA上,HAKE也提高了相當多的活動的檢測性能,特別是20個稀有的活動。
通訊作者曾為李飛飛團隊成員
論文的通訊作者是上海交通大學的盧策吾,也是計算機科學的教授。
在加入上海交大之前,他在香港中文大學獲得了博士學位,并曾在斯坦福大學擔任研究員,在李飛飛團隊工作。
現在,他的主要研究領域為計算機視覺、深度學習、深度強化學習和機器人視覺。

一作李永露為上海交通大學的博士生,此前他曾在中國科學院自動化研究所工作。
在CVPR 2020他連中三篇論文,也都是圍繞知識驅動的行為理解(Human Activity Understanding)方面的工作。

論文:
https://arxiv.org/abs/2202.06851v1
開源鏈接:
https://github.com/DirtyHarryLYL/HAKE-Action-Torch/tree/Activity2Vec