阿里開源支持十萬億模型的自研分布式訓(xùn)練框架EPL(EasyParallelLibrary)
原創(chuàng)一、導(dǎo)讀
最近阿里云機(jī)器學(xué)習(xí)PAI平臺(tái)和達(dá)摩院智能計(jì)算實(shí)驗(yàn)室一起發(fā)布“低碳版”巨模型M6-10T,模型參數(shù)已經(jīng)從萬億躍遷到10萬億,規(guī)模遠(yuǎn)超業(yè)界此前發(fā)布的萬億級(jí)模型,成為當(dāng)前全球最大的AI預(yù)訓(xùn)練模型。同時(shí),做到了業(yè)內(nèi)極致的低碳高效,使用512 GPU在10天內(nèi)即訓(xùn)練出具有可用水平的10萬億模型。相比之前發(fā)布的大模型GPT-3,M6實(shí)現(xiàn)同等參數(shù)規(guī)模,能耗僅為其1%。
M6模型訓(xùn)練使用的正是阿里云機(jī)器學(xué)習(xí)PAI平臺(tái)自研的分布式訓(xùn)練框架EPL(Easy Parallel Library,原名whale)。EPL通過對(duì)不同并行化策略進(jìn)行統(tǒng)一抽象、封裝,在一套分布式訓(xùn)練框架中支持多種并行策略,并進(jìn)行顯存、計(jì)算、通信等全方位優(yōu)化來提供易用、高效的分布式訓(xùn)練框架。
EPL背后的技術(shù)框架是如何設(shè)計(jì)的?開發(fā)者可以怎么使用EPL?EPL未來有哪些規(guī)劃?今天一起來深入了解。
二、EPL是什么
EPL(Easy Parallel Library)是阿里巴巴最近開源的,統(tǒng)一了多種并行策略、靈活易用的自研分布式深度學(xué)習(xí)訓(xùn)練框架。
1.項(xiàng)目背景
近些年隨著深度學(xué)習(xí)的火爆,模型的參數(shù)規(guī)模也飛速增長,OpenAI數(shù)據(jù)顯示:
- 2012年以前,模型計(jì)算耗時(shí)每2年增長一倍,和摩爾定律保持一致;
- 2012年后,模型計(jì)算耗時(shí)每3.4個(gè)月翻一倍,遠(yuǎn)超硬件發(fā)展速度;
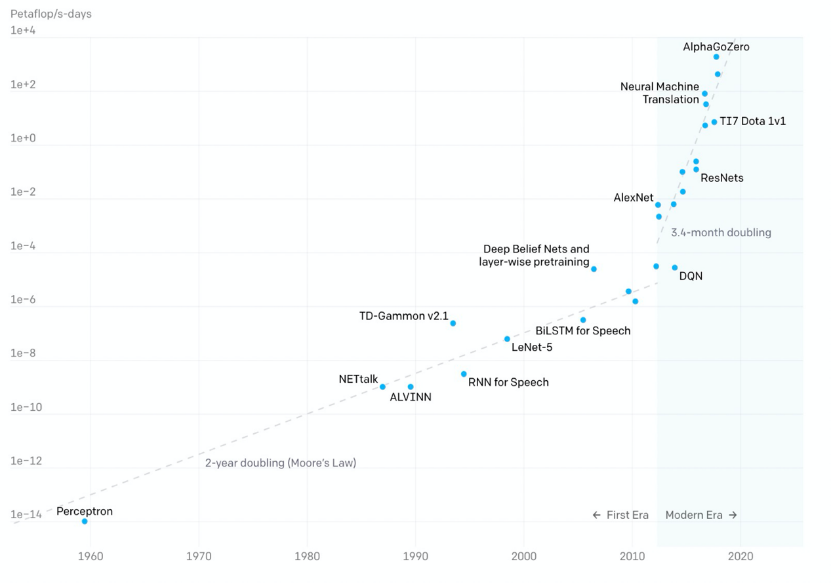
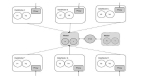
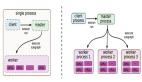
近一年來,百億、千億級(jí)的參數(shù)模型陸續(xù)面世,谷歌、英偉達(dá)、阿里、智源研究院更是發(fā)布了萬億參數(shù)模型。隨著模型參數(shù)規(guī)模的增大,模型效果逐步提高,但同時(shí)也為訓(xùn)練框架帶來更大的挑戰(zhàn)。當(dāng)前已經(jīng)有一些分布式訓(xùn)練框架Horovod、Tensorflow Estimator、PyTorch DDP等支持?jǐn)?shù)據(jù)并行,Gpipe、PipeDream、PipeMare等支持流水并行,Mesh Tensorflow、FlexFlow、OneFlow、MindSpore等支持算子拆分,但當(dāng)訓(xùn)練一個(gè)超大規(guī)模的模型時(shí)還是會(huì)面臨一些挑戰(zhàn):
- 如何簡潔易用:
接入門檻高:用戶實(shí)現(xiàn)模型分布式版本難度大、成本高,需要有領(lǐng)域?qū)<医?jīng)驗(yàn)才能實(shí)現(xiàn)高效的分布式并行策略;
最優(yōu)策略難:隨著研究人員設(shè)計(jì)出越來越靈活的模型以及越來越多的并行加速方法,如果沒有自動(dòng)并行策略探索支持,用戶很難找到最適合自身的并行策略;
遷移代價(jià)大:不同模型適合不同的混合并行策略,但切換并行策略時(shí)可能需要切換不同的框架,遷移成本高;
- 如何提高性價(jià)比:
業(yè)界訓(xùn)練萬億規(guī)模模型需要的資源:英偉達(dá) 3072 A100、谷歌 2048 TPU v3,資源成本非常高;
如何降本增效,組合使用各種技術(shù)和方法來減少需要的資源,提高訓(xùn)練的速度;
為了應(yīng)對(duì)當(dāng)前分布式訓(xùn)練的挑戰(zhàn),阿里云機(jī)器學(xué)習(xí)PAI團(tuán)隊(duì)自主研發(fā)了分布式訓(xùn)練框架EPL,將不同并行化策略進(jìn)行統(tǒng)一抽象、封裝,在一套分布式訓(xùn)練框架中支持多種并行策略。同時(shí),EPL提供簡潔易用的接口,用戶只需添加幾行annotation(注釋)即可完成并行策略的配置,不需要改動(dòng)模型代碼。EPL也可以在用戶無感的情況下,通過進(jìn)行顯存、計(jì)算、通信等全方位優(yōu)化,打造高效的分布式訓(xùn)練框架。
2.主要特性
- 多種并行策略統(tǒng)一:在一套分布式訓(xùn)練框架中支持多種并行策略(數(shù)據(jù)/流水/算子/專家并行)和其各種組合嵌套使用;
- 接口靈活易用:用戶只需添加幾行代碼就可以使用EPL豐富的分布式并行策略,模型代碼無需修改;
- 自動(dòng)并行策略探索:算子拆分時(shí)自動(dòng)探索拆分策略,流水并行時(shí)自動(dòng)探索模型切分策略;
- 分布式性能更優(yōu):提供了多維度的顯存優(yōu)化、計(jì)算優(yōu)化,同時(shí)結(jié)合模型結(jié)構(gòu)和網(wǎng)絡(luò)拓?fù)溥M(jìn)行調(diào)度和通信優(yōu)化,提供高效的分布式訓(xùn)練。
3.開源地址見文末
三、EPL主要技術(shù)特點(diǎn)
EPL通過豐富并行化策略、簡單易用的接口、多維度的顯存優(yōu)化技術(shù)和優(yōu)化的計(jì)算通信加速技術(shù),讓每一位算法工程師都能輕松訓(xùn)練分布式大模型任務(wù)。
- 豐富的并行化策略:EPL提供了多種并行化策略及其組合策略,包含數(shù)據(jù)并行、流水并行、算子拆分并行及并行策略的組合嵌套。豐富的策略選擇使得不同的模型結(jié)構(gòu)都能找到最適合自己的分布式訓(xùn)練方式。
- 易用性:用戶的模型編程接口和訓(xùn)練接口均基于TensorFlow,用戶只需在已有的單機(jī)單卡模型上做簡單的標(biāo)記,即可實(shí)現(xiàn)不同的分布式策略。EPL設(shè)計(jì)了兩種簡單的策略接口(replicate/split)來表達(dá)分布式策略及混合并行。分布式策略標(biāo)記的方式讓用戶無需學(xué)習(xí)新的模型編程接口,僅需幾行代碼即可實(shí)現(xiàn)和轉(zhuǎn)換分布式策略,極大降低了分布式框架的使用門檻。
- 顯存優(yōu)化:EPL提供了多維度的顯存優(yōu)化技術(shù),包含自動(dòng)重算技術(shù)(Gradient Checkpoint),ZeRO數(shù)據(jù)并行顯存優(yōu)化技術(shù),CPU Offload技術(shù)等,幫助用戶用更少的資源訓(xùn)練更大的模型。
- 通信優(yōu)化技術(shù):EPL深度優(yōu)化了分布式通信庫,包括硬件拓?fù)涓兄⑼ㄐ啪€程池、梯度分組融合、混合精度通信、梯度壓縮等技術(shù)。
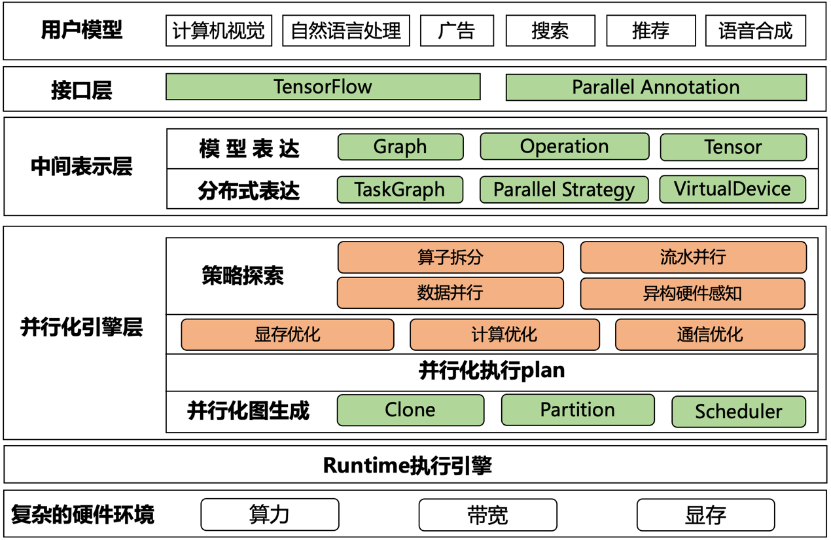
1.技術(shù)架構(gòu)
EPL框架如下圖所示,主要分為以下幾個(gè)模塊:
- 接口層:用戶的模型編程接口基于TensorFlow,同時(shí)EPL提供了易用的并行化策略表達(dá)接口,讓用戶可以組合使用各種混合并行策略;
- 中間表達(dá)層:將用戶模型和并行策略轉(zhuǎn)化成內(nèi)部表達(dá),通過TaskGraph、VirtualDevices和策略抽象來表達(dá)各種并行策略;
- 并行化引擎層:基于中間表達(dá),EPL會(huì)對(duì)計(jì)算圖做策略探索,進(jìn)行顯存/計(jì)算/通信優(yōu)化,并自動(dòng)生成分布式計(jì)算圖;
- Runtime執(zhí)行引擎:將分布式執(zhí)行圖轉(zhuǎn)成TFGraph,再調(diào)用TF 的Runtime來執(zhí)行;
2.并行化策略表達(dá)
EPL通過strategy annotation的方式將模型劃分為多個(gè)TaskGraph,并在此基礎(chǔ)上進(jìn)行并行化。EPL有兩類strategy:replicate 和 split。通過這兩種并行化接口,可以表達(dá)出各種不同的并行化策略,例如:
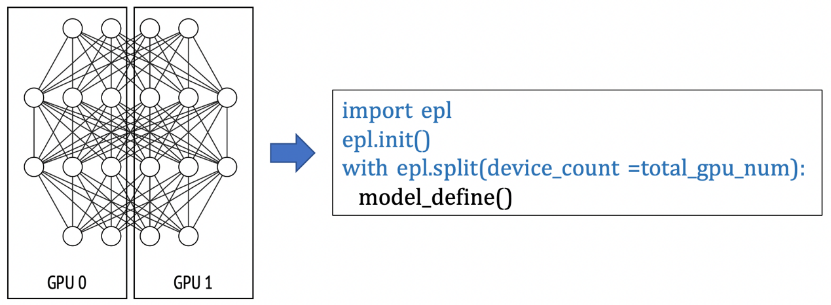
(1)數(shù)據(jù)并行: 下面這個(gè)例子是一個(gè)數(shù)據(jù)并行的例子,每個(gè)模型副本用一張卡來計(jì)算。如果用戶申請(qǐng)了8張卡,就是一個(gè)并行度為8的數(shù)據(jù)并行任務(wù)。
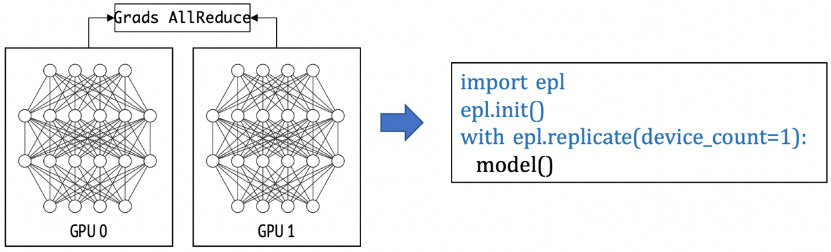
(2) 流水并行:在下面的例子里,模型被切分成2個(gè) TaskGraph, "stage0"和"stage1",用戶可以通過配置pipeline.num_micro_batch參數(shù)來設(shè)定pipeline的micro batch數(shù)量。在這個(gè)例子里,"stage_0"和"stage_1"組成一個(gè)模型副本,共需要2張GPU卡。如果用戶申請(qǐng)了8張卡,EPL會(huì)自動(dòng)在pipeline外嵌套一層并行度為4的數(shù)據(jù)并行(4個(gè)pipeline副本并行執(zhí)行)。
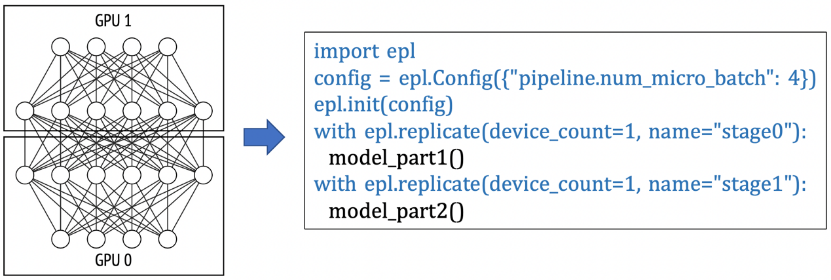
(3) 算子拆分并行:在以下例子中,EPL會(huì)對(duì)split scope下的模型定義做拆分,并放置在不同的GPU卡上做并行計(jì)算。
(4)同時(shí),EPL支持對(duì)上述并行策略進(jìn)行組合和嵌套,組成各種混合并行策略,更多示例可以參考開源代碼的文檔和示例。
3.顯存優(yōu)化
當(dāng)模型增長,GPU的顯存常常成為訓(xùn)練大模型的瓶頸。EPL提供了多維度的顯存優(yōu)化技術(shù),極大優(yōu)化了訓(xùn)練顯存消化。
- 重算 Recomputation (Gradient Checkpoint):正常的DNN前向過程中會(huì)生成activation,這部分activation會(huì)在后向過程中用于梯度計(jì)算。因此,在梯度生成之前,前向的activation會(huì)一直存留在顯存中。activation大小和模型結(jié)構(gòu)以及batch size相關(guān),通常占比都非常高。Gradient Checkpoint (GC) 通過保留前向傳播過程中的部分activation,在反向傳播中重算被釋放的activation,用時(shí)間換空間。GC中比較重要的一部分是如何選擇合適的checkpoint點(diǎn),在節(jié)省顯存、保證性能的同時(shí),又不影響收斂性。EPL提供了自動(dòng)GC功能,用戶可以一鍵開啟GC優(yōu)化功能。
- ZeRO:在數(shù)據(jù)并行的場景下,每個(gè)卡上會(huì)存放一個(gè)模型副本,optimizer state等,這些信息在每張卡上都是一樣,存在很大的冗余量。當(dāng)模型變大,很容易超出單卡的顯存限制。在分布式場景下,可以通過類似DeepSpeed ZeRO的思路,將optimizer state和gradient分片存在不同的卡上,從而減少單卡的persistent memory占用。
- 顯存優(yōu)化的AMP(Auto Mixed Precision):在常規(guī)的AMP里,需要維護(hù)一個(gè)FP16的weight buffer,對(duì)于參數(shù)量比較大的模型,也是不小的開銷。EPL提供了一個(gè)顯存優(yōu)化的AMP版本,F(xiàn)P16只有在用的時(shí)候才cast,從而節(jié)約顯存。
- Offload: Offload將訓(xùn)練的存儲(chǔ)空間從顯存擴(kuò)展到內(nèi)存甚至磁盤,可以用有限的資源訓(xùn)練大模型。
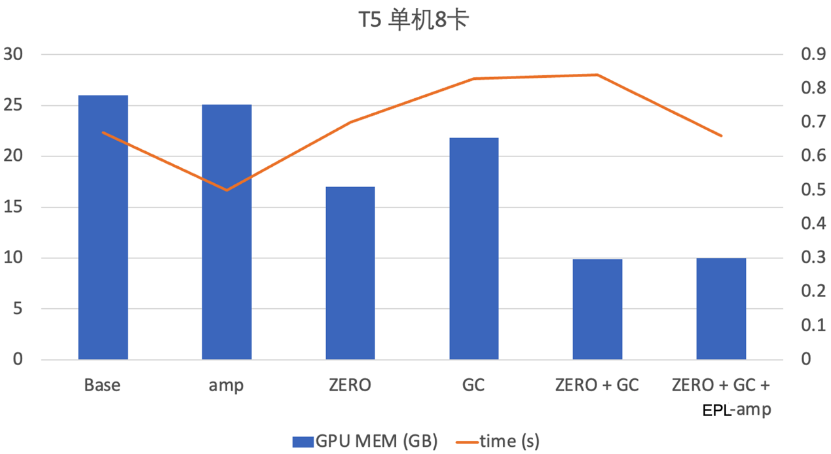
同時(shí),EPL支持各種顯存優(yōu)化技術(shù)的組合使用,達(dá)到顯存的極致優(yōu)化。阿里云機(jī)器學(xué)習(xí)PAI團(tuán)隊(duì)在T5模型上開啟了GC+ZeRO+顯存優(yōu)化的AMP技術(shù),在性能保持不變的情況下,顯存降低2.6倍。
四、應(yīng)用場景
EPL適合不同場景的模型,在阿里巴巴內(nèi)部已經(jīng)支持圖像、推薦、語音、視頻、自然語言、多模態(tài)等業(yè)務(wù)場景。同時(shí),EPL也支持不同規(guī)模的模型,最大完成了10萬億規(guī)模的M6模型訓(xùn)練,下面以M6和Bert模型為例進(jìn)行介紹。
1.萬億/10萬億 M6模型預(yù)訓(xùn)練
訓(xùn)練一個(gè)萬億/10萬億參數(shù)模型,算力需求非常大。為了降低算力需求,EPL中實(shí)現(xiàn)了MoE(Mixture-of-Experts)結(jié)構(gòu),MoE的主要特點(diǎn)是稀疏激活,使用Gating(Router)來為輸入選擇Top-k的expert進(jìn)行計(jì)算(k常用取值1、2),從而大大減少算力需求。
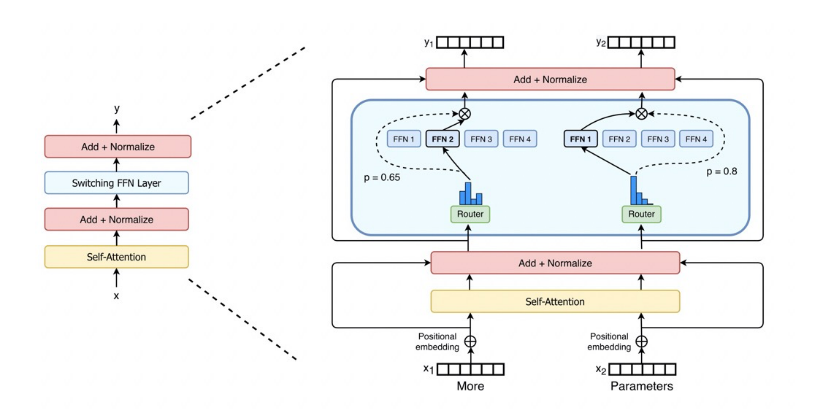
EPL支持專家并行(Expert Parallelism, EP),將experts拆分到多個(gè)devices上,降低單個(gè)device的顯存和算力需求。同時(shí),數(shù)據(jù)并行有利于提升訓(xùn)練的并發(fā)度,因此,采用數(shù)據(jù)并行+專家并行的混合并行策略來訓(xùn)練M6模型:MoE layer采用專家并行,其他layer采用數(shù)據(jù)并行。
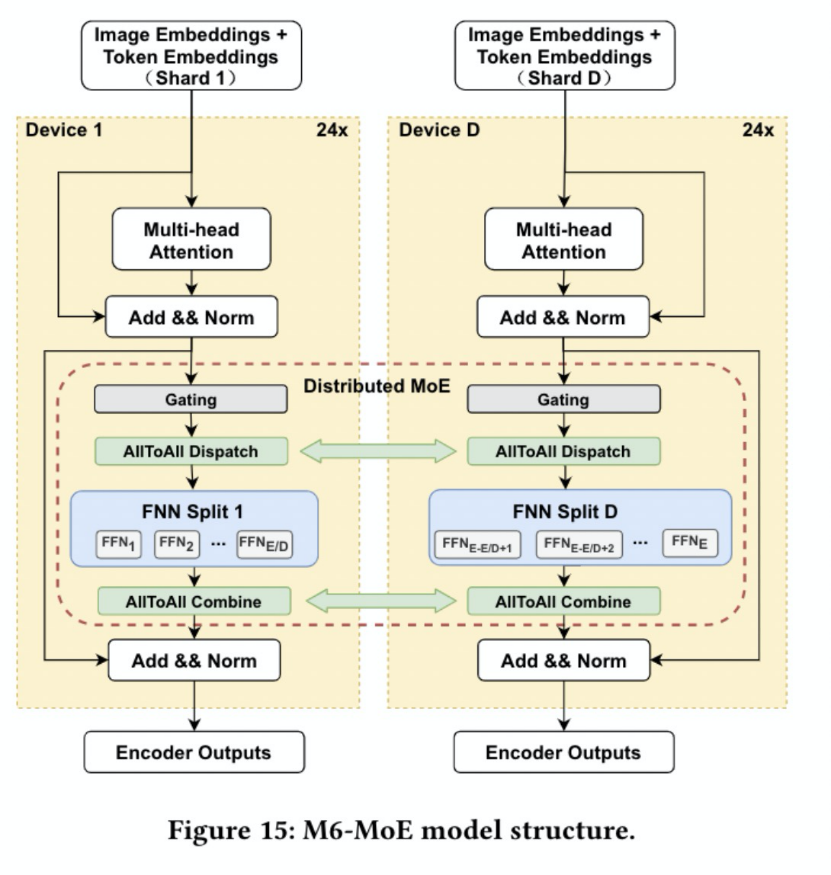
EPL中提供簡潔易用的接口來進(jìn)行模型的混合并行訓(xùn)練,只需要增加幾行annotation(注釋)來配置并行策略,不需要對(duì)模型本身做任何修改。例如,M6模型采用數(shù)據(jù)并行+專家并行的策略,只需要增加如下圖的annotation:

同時(shí),為了節(jié)約訓(xùn)練資源、提高訓(xùn)練效率,我們采用了EPL的顯存優(yōu)化技術(shù)和計(jì)算通信加速技術(shù),包含自動(dòng) Gradient Checkpointing節(jié)省activation顯存占用,CPU Offload技術(shù)用于優(yōu)化optimizer states和weight的顯存占用,采用DP+EP混合并行策略降低算力需求,結(jié)合混合精度、編譯優(yōu)化等技術(shù)提高訓(xùn)練效率等。 借助EPL框架,首次在480 V100 上,3天內(nèi)完成萬億M6模型的預(yù)訓(xùn)練。相比此前業(yè)界訓(xùn)練同等規(guī)模的模型,此次僅使用480張V100 32G GPU就成功訓(xùn)練出萬億模型M6,節(jié)省算力資源超80%,且訓(xùn)練效率提升近11倍。進(jìn)一步使用512 GPU在10天內(nèi)即訓(xùn)練出具有可用水平的10萬億模型。
2.流水并行加速Bert Large模型訓(xùn)練
對(duì)于Bert Large模型,結(jié)構(gòu)圖如下圖所示:
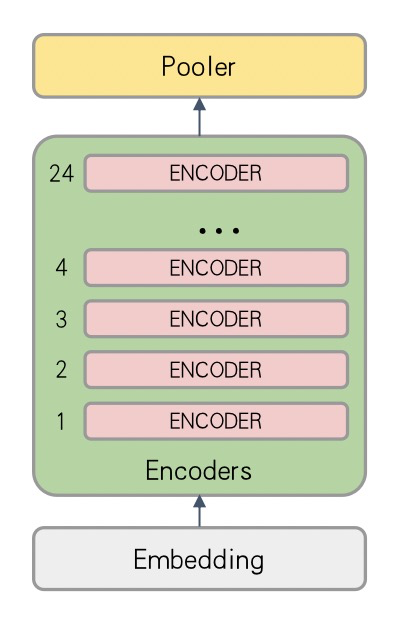
由于Bert Large模型對(duì)顯存消耗較大,Nvidia V100 16G顯卡上batch size常常只有2-8左右(具體值和Embedding大小、Sequence Length等有關(guān))。Batch size太小會(huì)導(dǎo)致算法收斂波動(dòng)大、收斂效果差的問題。同時(shí),通過數(shù)據(jù)并行模式訓(xùn)練,通信占比較高,分布式加速效果不理想。
分析Bert Large模型,由24層重復(fù)結(jié)構(gòu)的encoder組成,可以使用流水并行進(jìn)行加速。這里,我們將Bert Large中的Encoder Layer 1~8層、Encoder Layer 9~16層,Encoder Layer 17~24層分別放在不同的卡上進(jìn)行訓(xùn)練,并行化后的計(jì)算圖如下圖所示:
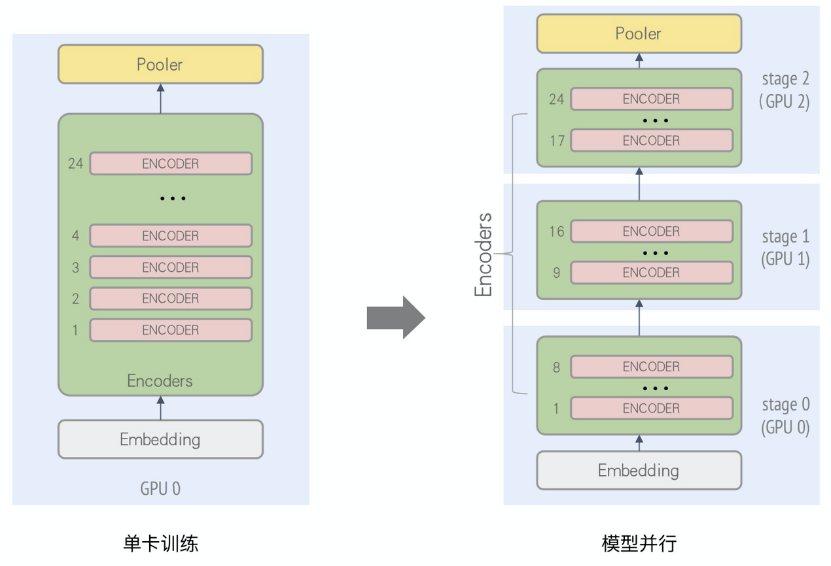
如此,每張卡訓(xùn)練時(shí)的顯存開銷會(huì)減少,從而可以增大batch size以提升收斂加速。另外,針對(duì)因模型過大、單卡顯存無法放下所導(dǎo)致的無法訓(xùn)練的場景,通過Layer間拆分的模型并行方式來進(jìn)行分布式訓(xùn)練。通過epl.replicate接口可以實(shí)現(xiàn)模型的stage劃分,同時(shí)通過流水并行的執(zhí)行調(diào)度來提升并行化性能,如下圖所示:

上述例子是一個(gè)流水micro batch mumber為5的情況。通過流水并行優(yōu)化后的時(shí)間軸可以看出,在同一個(gè)時(shí)間上,多張卡可以并行計(jì)算。當(dāng)5個(gè)micro batch結(jié)束后,每張卡會(huì)將梯度進(jìn)行本地的累計(jì)之后再進(jìn)行update。與單純的模型并行相比,通過流水的交替執(zhí)行,提高了GPU的利用率。EPL還通過采用Backward-Preferred調(diào)度優(yōu)化策略來提升流水并行性能,降低GPU空閑時(shí)間和顯存開銷。

為能夠獲得更高的水平擴(kuò)展,EPL還支持在流水并行外嵌套數(shù)據(jù)并行來提升訓(xùn)練吞吐。EPL會(huì)自動(dòng)推導(dǎo)嵌套的數(shù)據(jù)并行的并行度。最新測試結(jié)果顯示,在32卡GPU規(guī)模下,使用EPL的流水+數(shù)據(jù)并行對(duì)Bert Large模型進(jìn)行優(yōu)化,相比于數(shù)據(jù)并行,訓(xùn)練速度提升了66%。
五、Roadmap
我們決定建設(shè)開源生態(tài)主要有如下的考慮:
- EPL發(fā)源于阿里云內(nèi)部的業(yè)務(wù)需求,很好地支持了大規(guī)模、多樣性的業(yè)務(wù)場景,在服務(wù)內(nèi)部業(yè)務(wù)的過程中也積累了大量的經(jīng)驗(yàn),在EPL自身隨著業(yè)務(wù)需求的迭代逐漸完善的同時(shí),我們也希望能夠開源給社區(qū),將自身積累的經(jīng)驗(yàn)和理解回饋給社區(qū),希望和深度學(xué)習(xí)訓(xùn)練框架的開發(fā)者或深度學(xué)習(xí)從業(yè)者之間有更多更好的交流和共建,為這個(gè)行業(yè)貢獻(xiàn)我們的技術(shù)力量。
- 我們希望能夠借助開源的工作,收到更多真實(shí)業(yè)務(wù)場景下的用戶反饋,以幫助我們持續(xù)完善和迭代,并為后續(xù)的工作投入方向提供輸入。
- 同時(shí),我們希望借助開源的工作,能吸引一些志同道合的同學(xué)、公司或組織來參與共建,持續(xù)完善深度學(xué)習(xí)生態(tài)。
后續(xù),我們計(jì)劃以兩個(gè)月為單位發(fā)布Release版本。EPL近期的Roadmap如下:
- 持續(xù)的性能優(yōu)化和穩(wěn)定性改進(jìn);
- 通用算子拆分功能;
- 自動(dòng)拆分策略探索的基礎(chǔ)版;
- 自動(dòng)流水并行策略探索;
此外,在中長期,我們將在軟硬件一體優(yōu)化、全自動(dòng)策略探索等幾個(gè)探索性的方向上持續(xù)投入精力,也歡迎各種維度的反饋和改進(jìn)建議以及技術(shù)討論,同時(shí)我們十分歡迎和期待對(duì)開源社區(qū)建設(shè)感興趣的同行一起參與共建。
- 全自動(dòng)的模型并行策略探索;
- 高效的策略探索算法和精準(zhǔn)的CostModel評(píng)估;
- eager model下的并行策略探索;
- 更多新硬件的支持、適配和協(xié)同優(yōu)化;
- 高效的算子優(yōu)化和集成、極致的顯存優(yōu)化、軟硬一體的通信優(yōu)化;
EPL(Easy Parallel Library)的開源地址:https://github.com/alibaba/EasyParallelLibrary
我們同時(shí)提供了model zoo,歡迎大家試用:https://github.com/alibaba/FastNN