一行代碼,AI模型推理速度提升十倍!Reddit技術(shù)分享被群嘲為「無恥的自我宣傳」
Reddit 論壇里經(jīng)常有各種 AI 技術(shù)的討論,最近有網(wǎng)友分享了一個(gè)開源庫,號(hào)稱只需要添加幾行代碼,模型的運(yùn)行速度可以提升 10 倍以上!
文章的標(biāo)題為「幾乎沒人知道的如何很容易地優(yōu)化 AI 模型」。

一切看著都很正常,一個(gè)簡(jiǎn)單的技術(shù)分享帖子,但網(wǎng)友卻不買賬,他們認(rèn)為這是無恥的「自我營銷」行為。
Reddit 網(wǎng)站甚至還給討論帖打上了「Shameless Self Promo」的標(biāo)簽。
所以,這到底是一場(chǎng)單純的技術(shù)分享,還是嘩眾取寵的營銷?
技術(shù)分享也有錯(cuò)?
樓主在帖子中寫道,現(xiàn)在只需要添加幾行代碼,你模型的運(yùn)行速度就可以提升 10 倍甚至更多,但你可能根本沒有意識(shí)到怎么做。
他總結(jié)了一下目前的 AI 研究情況:
人工智能應(yīng)用就像雨后春筍一樣快速增長,并且越來越多的人開始加入人工智能世界,樓主也是 AI 大軍中的一員。但問題是,開發(fā)人員只專注于 AI,清洗數(shù)據(jù)和訓(xùn)練模型。幾乎沒有人有硬件、編譯器、計(jì)算、云等方面的背景。結(jié)果就導(dǎo)致了開發(fā)人員花了很多時(shí)間來提高他們軟件的準(zhǔn)確性和性能,而他們所有努力的成果都有可能被錯(cuò)誤的軟硬件耦合選擇所抵消。
這個(gè)問題困擾了他很久,所以就和 Nebuly 的幾個(gè)哥們兒(都曾在麻省理工學(xué)院、ETH 和 EPFL 工作過),在一個(gè)名為 nebullvm 的開源庫中投入了大量精力,開發(fā)了一個(gè)讓任何開發(fā)者都能使用 DL 編譯器技術(shù),即使你對(duì)硬件一無所知。
它的工作流程就是通過測(cè)試多個(gè) DL 編譯器,并選擇最佳的編譯器將你的 AI 模型與你的機(jī)器(GPU、CPU 等)進(jìn)行最佳匹配,從而將你的 DL 模型的速度提高5-20 倍。所有這一切工作只需幾行代碼即可完成。
并且?guī)煲彩情_源的:https://github.com/nebuly-ai/nebullvm
在遭到網(wǎng)友大量的評(píng)價(jià)后,樓主又在帖子中貼出一段聲明。他表示,這個(gè)帖子完全是關(guān)于一個(gè)開源庫的,并且自推出以來在 GitHub 上一直很受歡迎(僅在第一天就有 250 多顆星)。不幸的是,這篇文章被貼上了「無恥的自我宣傳」的標(biāo)簽,而對(duì)技術(shù)問題的回答也被其他評(píng)論所掩蓋。
他懇請(qǐng)那些真正嘗試過這個(gè)庫的人再對(duì)這個(gè)帖子進(jìn)行評(píng)論。
網(wǎng)友評(píng)價(jià)
發(fā)帖人可能也沒想到,技術(shù)分享貼并沒有取到預(yù)期的效果,而是被廣大網(wǎng)友「罵」上了熱搜。
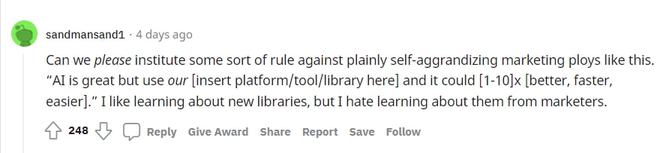
高贊網(wǎng)友表示,Reddit 能不能制定某種規(guī)則,反對(duì)像這樣明顯的自我吹噓的營銷伎倆。并且還舉了一個(gè)規(guī)則例子:
人工智能很好,但使用我們的[此處插入平臺(tái)/工具/庫],它可以[1-10]x[更好、更快、更容易]。
我雖然喜歡了解新的庫,但我討厭從營銷人員那里了解它們。
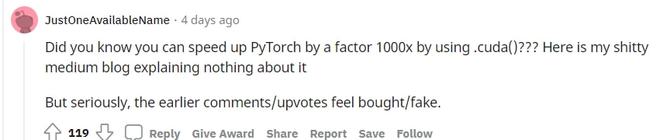
下面回復(fù)的一個(gè)網(wǎng)友也表示,太多科技媒體不懂技術(shù)了,他們可能都不知道在 PyTorch 里面使用 .cuda ()可以直接提升 1000 倍模型速度?
并懷疑早期的評(píng)論和點(diǎn)贊都是買的網(wǎng)絡(luò)水軍。
更直接的網(wǎng)友表示,這純屬垃圾信息,不知道這些天 reddit 發(fā)生了什么。
也有網(wǎng)友舉了最近的另一個(gè)帖子當(dāng)例子:雖然有 931 個(gè)點(diǎn)贊,但高贊評(píng)論幾乎都是負(fù)面評(píng)價(jià)。
整個(gè)項(xiàng)目只是「我的朋友/我的母親認(rèn)為我做了什么與我實(shí)際做了什么」的備忘錄。
對(duì)于管理層和投資者來說,這是一個(gè)漂亮的視覺效果。對(duì)于實(shí)際工作的人來說,這幾乎是毫無意義的。大多數(shù)開發(fā)者使用命令行和文本的原因是你要處理如此多的數(shù)據(jù),而視覺效果只是一個(gè)障礙而非幫助;
也有網(wǎng)友持不同意見:如果你考慮到有多高比例的潛水和這個(gè) subreddit 上的人實(shí)際上并不是以 ML 為職業(yè),也有很多學(xué)生和軟件工程師,或者對(duì)這個(gè)話題有切身興趣的人,他們只是想通過在這里盲目地支持一些東西來感覺自己是「社區(qū)」的一部分,盡管公平地說,他們也并不真正傾向于擁有必要的經(jīng)驗(yàn)來進(jìn)行批評(píng)。
還有網(wǎng)友表示,他知道這篇文章是一個(gè)廣告,有點(diǎn)像「他們用錯(cuò)誤的工具來告訴你有一個(gè)更好的方法」,但說實(shí)話,我沒有看到足夠的人做上述工作。我看到更多的是人們?cè)谒俣壬舷鹿Ψ颍蛘呷绾卧诖a上打補(bǔ)丁,盡管這對(duì) SLA 來說不是必要的。分析性能不需要很大工作量,主要是因?yàn)楹芏鄰臉I(yè)者來自軟件工程背景,他們認(rèn)為可以努力和取得進(jìn)展的內(nèi)容就是運(yùn)行速度。
也有網(wǎng)友討論技術(shù)內(nèi)核,認(rèn)為這只是通過 TensorRT(或其他現(xiàn)有的深度學(xué)習(xí)編譯器)運(yùn)行模型,這個(gè)項(xiàng)目實(shí)際上是「無事生非」。
惹民憤的庫
根據(jù) GitHub 庫的 Readme 文件中可以了解到,nebullvm 是一個(gè) All-in-one 的庫,用戶可以在一行代碼中測(cè)試多個(gè) DL 編譯器,并將 DL 模型的推理速度提高5-20 倍。
這個(gè)資源庫包含了開源的 nebullvm 包,這個(gè)開源項(xiàng)目旨在將所有的開源 AI 編譯器統(tǒng)一到同一個(gè)易于使用的界面下。
作者表示,他們?cè)O(shè)計(jì)的東西超級(jí)容易使用:你只需要輸入 DL 模型,就會(huì)自動(dòng)得到一個(gè)優(yōu)化的模型版本,用于對(duì)目標(biāo)硬件進(jìn)行優(yōu)化。
據(jù)作者所知,目前還沒有開源的庫來結(jié)合市場(chǎng)上的各種 DL 編譯器來找出最適合用戶模型的編譯器。他們相信,這個(gè)庫可以做出強(qiáng)有力的貢獻(xiàn),使人工智能開發(fā)者越來越容易使他們的模型更有效率,而不需要花費(fèi)過多的時(shí)間。
目前支持的框架包括 PyTorch 和 Tensorflow,支持的 DL 編譯器包括 OpenVINO(Intel 機(jī)器), TensorRT(Nvidia GPU)和 Apache TVM。
使用方法也很簡(jiǎn)單,首先使用 pip 安裝。
然后使用 nebullvm 導(dǎo)入 torch 或 tensorflow 的模型,以 pyTorch 為例,幾行代碼即可完成優(yōu)化。

根據(jù)作者提供的信息和 GitHub Stars 數(shù)量來看,這個(gè)庫還是靠譜的。
Reddit 網(wǎng)友可能是看了太多 AI 模型的夸張宣傳,都發(fā)泄在了作者身上,作者也表示很無辜。科學(xué)本就是「事實(shí)求是」,才能更好地發(fā)展。
你站庫作者還是 Reddit 網(wǎng)友?