這篇監(jiān)控系統(tǒng)的建設思路,讓你徹底找出性能瓶頸
一、起始
在實際的性能分析中,一個很常見的現(xiàn)象是,明明發(fā)生了性能瓶頸,但當你登錄到服務器中想要排查的時候,卻發(fā)現(xiàn)瓶頸已經(jīng)消失了。或者說,性能問題總是時不時地發(fā)生,但卻很難找出發(fā)生規(guī)律,也很難重現(xiàn)。而要解決這個問題,就要搭建監(jiān)控系統(tǒng),把系統(tǒng)和應用程序的運行狀況監(jiān)控起來,并定義一系列的策略,在發(fā)生問題時第一時間告警通知。一個好的監(jiān)控系統(tǒng),不僅可以實時暴露系統(tǒng)的各種問題,更可以根據(jù)這些監(jiān)控到的狀態(tài),自動分析和定位大致的瓶頸來源,從而更精確地把問題匯報給相關團隊處理。要做好監(jiān)控,最核心的就是全面的、可量化的指標,這包括系統(tǒng)和應用兩個方面。從系統(tǒng)來說,監(jiān)控系統(tǒng)要涵蓋系統(tǒng)的整體資源使用情況,比如我們前面講過的 CPU、內(nèi)存、磁盤和文件系統(tǒng)、網(wǎng)絡等各種系統(tǒng)資源。而從應用程序來說,監(jiān)控系統(tǒng)要涵蓋應用程序內(nèi)部的運行狀態(tài),這既包括進程的 CPU、磁盤 I/O 等整體運行狀況,更需要包括諸如接口調(diào)用耗時、執(zhí)行過程中的錯誤、內(nèi)部對象的內(nèi)存使用等應用程序內(nèi)部的運行狀況。
二、系統(tǒng)監(jiān)控
1、USE 法
在開始監(jiān)控系統(tǒng)之前,你肯定最想知道,怎么才能用簡潔的方法,來描述系統(tǒng)資源的使用情況。你當然可以使用專欄中學到的各種性能工具,來分別收集各種資源的使用情況。不過不要忘記,每種資源的性能指標可都有很多,使用過多指標本身耗時耗力不說,也不容易為你建立起系統(tǒng)整體的運行狀況。在這里,我為你介紹一種專門用于性能監(jiān)控的 USE(Utilization Saturation and Errors)法。USE 法把系統(tǒng)資源的性能指標,簡化成了三個類別,即使用率、飽和度以及錯誤數(shù)。
- 使用率,表示資源用于服務的時間或容量百分比。100% 的使用率,表示容量已經(jīng)用盡或者全部時間都用于服務。
- 飽和度,表示資源的繁忙程度,通常與等待隊列的長度相關。100% 的飽和度,表示資源無法接受更多的請求。
- 錯誤數(shù)表示發(fā)生錯誤的事件個數(shù)。錯誤數(shù)越多,表明系統(tǒng)的問題越嚴重。
這三個類別的指標,涵蓋了系統(tǒng)資源的常見性能瓶頸,所以常被用來快速定位系統(tǒng)資源的性能瓶頸。這樣,無論是對 CPU、內(nèi)存、磁盤和文件系統(tǒng)、網(wǎng)絡等硬件資源,還是對文件描述符數(shù)、連接數(shù)、連接跟蹤數(shù)等軟件資源,USE 方法都可以幫你快速定位出,是哪一種系統(tǒng)資源出現(xiàn)了性能瓶頸。
2、性能指標
那么,對于每一種系統(tǒng)資源,又有哪些常見的性能指標呢?回憶一下我們講過的各種系統(tǒng)資源原理,并不難想到相關的性能指標。這里,我把常見的性能指標畫了一張表格,方便你在需要時查看。
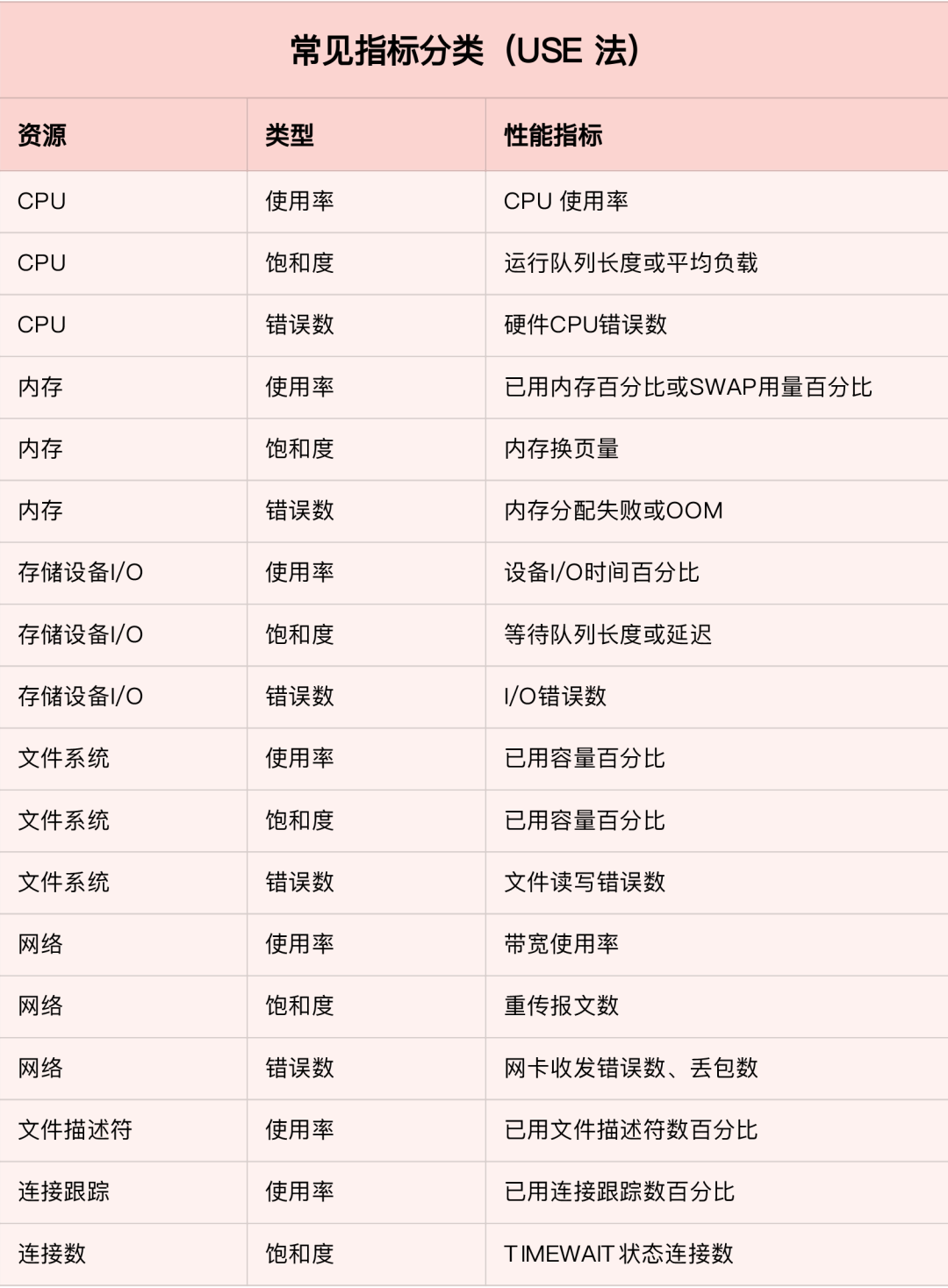
不過,需要注意的是,USE 方法只關注能體現(xiàn)系統(tǒng)資源性能瓶頸的核心指標,但這并不是說其他指標不重要。諸如系統(tǒng)日志、進程資源使用量、緩存使用量等其他各類指標,也都需要我們監(jiān)控起來。只不過,它們通常用作輔助性能分析,而 USE 方法的指標,則直接表明了系統(tǒng)的資源瓶頸。
3、監(jiān)控系統(tǒng)
掌握 USE 方法以及需要監(jiān)控的性能指標后,接下來要做的,就是建立監(jiān)控系統(tǒng),把這些指標保存下來;然后,根據(jù)這些監(jiān)控到的狀態(tài),自動分析和定位大致的瓶頸來源;最后,再通過告警系統(tǒng),把問題及時匯報給相關團隊處理。可以看出,一個完整的監(jiān)控系統(tǒng)通常由數(shù)據(jù)采集、數(shù)據(jù)存儲、數(shù)據(jù)查詢和處理、告警以及可視化展示等多個模塊組成。所以,要從頭搭建一個監(jiān)控系統(tǒng),其實也是一個很大的系統(tǒng)工程。不過,幸運的是,現(xiàn)在已經(jīng)有很多開源的監(jiān)控工具可以直接使用,比如最常見的 Zabbix、Nagios、Prometheus 等等。下面,我就以 Prometheus 為例,為你介紹這幾個組件的基本原理。如下圖所示,就是 Prometheus 的基本架構:
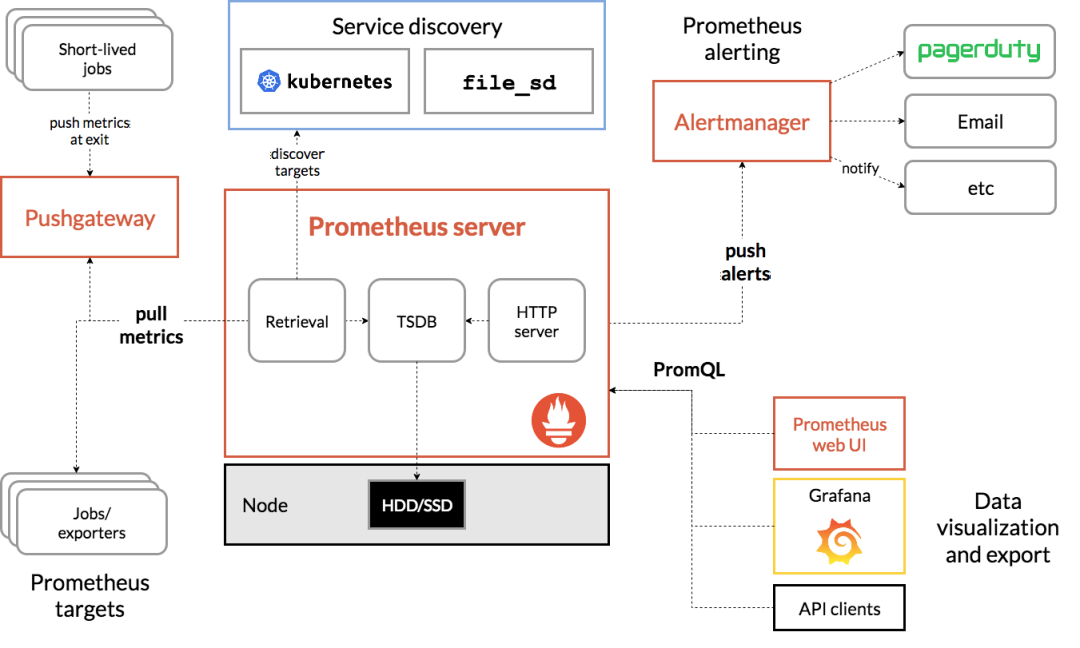
先看數(shù)據(jù)采集模塊。最左邊的 Prometheus targets 就是數(shù)據(jù)采集的對象,而 Retrieval 則負責采集這些數(shù)據(jù)。從圖中你也可以看到,Prometheus 同時支持 Push 和 Pull 兩種數(shù)據(jù)采集模式。Pull 模式,由服務器端的采集模塊來觸發(fā)采集。只要采集目標提供了 HTTP 接口,就可以自由接入(這也是最常用的采集模式)。Push 模式,則是由各個采集目標主動向 Push Gateway(用于防止數(shù)據(jù)丟失)推送指標,再由服務器端從 Gateway 中拉取過去(這是移動應用中最常用的采集模式)。第二個是數(shù)據(jù)存儲模塊。為了保持監(jiān)控數(shù)據(jù)的持久化,圖中的 TSDB(Time series database)模塊,負責將采集到的數(shù)據(jù)持久化到 SSD 等磁盤設備中。TSDB 是專門為時間序列數(shù)據(jù)設計的一種數(shù)據(jù)庫,特點是以時間為索引、數(shù)據(jù)量大并且以追加的方式寫入。第三個是數(shù)據(jù)查詢和處理模塊。剛才提到的 TSDB,在存儲數(shù)據(jù)的同時,其實還提供了數(shù)據(jù)查詢和基本的數(shù)據(jù)處理功能,而這也就是 PromQL 語言。PromQL 提供了簡潔的查詢、過濾功能,并且支持基本的數(shù)據(jù)處理方法,是告警系統(tǒng)和可視化展示的基礎。第四個是告警模塊。右上角的 AlertManager 提供了告警的功能,包括基于 PromQL 語言的觸發(fā)條件、告警規(guī)則的配置管理以及告警的發(fā)送等。不過,雖然告警是必要的,但過于頻繁的告警顯然也不可取。所以,AlertManager 還支持通過分組、抑制或者靜默等多種方式來聚合同類告警,并減少告警數(shù)量。最后一個是可視化展示模塊。Prometheus 的 web UI 提供了簡單的可視化界面,用于執(zhí)行 PromQL 查詢語句,但結果的展示比較單調(diào)。不過,一旦配合 Grafana,就可以構建非常強大的圖形界面了。介紹完了這些組件,想必你對每個模塊都有了比較清晰的認識。接下來,我們再來繼續(xù)深入了解這些組件結合起來的整體功能。比如,以剛才提到的 USE 方法為例,我使用 Prometheus,可以收集 Linux 服務器的 CPU、內(nèi)存、磁盤、網(wǎng)絡等各類資源的使用率、飽和度和錯誤數(shù)指標。然后,通過 Grafana 以及 PromQL 查詢語句,就可以把它們以圖形界面的方式直觀展示出來。
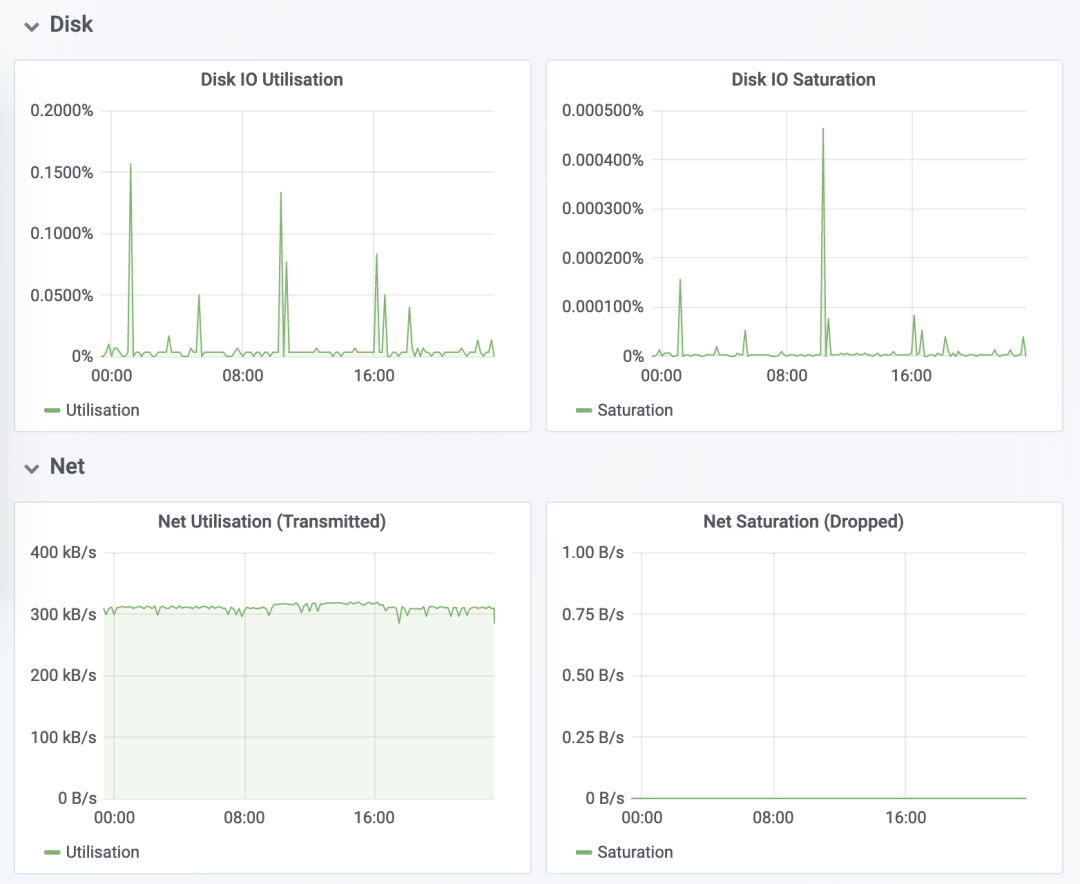
4、最后總結
系統(tǒng)監(jiān)控的核心是資源的使用情況,這既包括 CPU、內(nèi)存、磁盤、文件系統(tǒng)、網(wǎng)絡等硬件資源,也包括文件描述符數(shù)、連接數(shù)、連接跟蹤數(shù)等軟件資源。而要描述這些資源瓶頸,最簡單有效的方法就是 USE 法。USE 法把系統(tǒng)資源的性能指標,簡化為了三個類別:使用率、飽和度以及錯誤數(shù)。當這三者之中任一類別的指標過高時,都代表相對應的系統(tǒng)資源可能存在性能瓶頸。基于 USE 法建立性能指標后,我們還需要通過一套完整的監(jiān)控系統(tǒng),把這些指標從采集、存儲、查詢、處理,再到告警和可視化展示等貫穿起來。這樣,不僅可以將系統(tǒng)資源的瓶頸快速暴露出來,還可以借助監(jiān)控的歷史數(shù)據(jù),來追蹤定位性能問題的根源。
三、應用監(jiān)控
1、應用監(jiān)控指標
跟系統(tǒng)監(jiān)控一樣,在構建應用程序的監(jiān)控系統(tǒng)之前,首先也需要確定,到底需要監(jiān)控哪些指標。特別是要清楚,有哪些指標可以用來快速確認應用程序的性能問題。應用程序的核心指標,不再是資源的使用情況,而是請求數(shù)、錯誤率和響應時間。這些指標不僅直接關系到用戶的使用體驗,還反映應用整體的可用性和可靠性。有了請求數(shù)、錯誤率和響應時間這三個黃金指標之后,我們就可以快速知道,應用是否發(fā)生了性能問題。但是,只有這些指標顯然還是不夠的,因為發(fā)生性能問題后,我們還希望能夠快速定位“性能瓶頸區(qū)”。所以,在我看來,下面幾種指標,也是監(jiān)控應用程序時必不可少的。第一個,是應用進程的資源使用情況,比如進程占用的 CPU、內(nèi)存、磁盤 I/O、網(wǎng)絡等。使用過多的系統(tǒng)資源,導致應用程序響應緩慢或者錯誤數(shù)升高,是一個最常見的性能問題。第二個,是應用程序之間調(diào)用情況,比如調(diào)用頻率、錯誤數(shù)、延時等。由于應用程序并不是孤立的,如果其依賴的其他應用出現(xiàn)了性能問題,應用自身性能也會受到影響。第三個,是應用程序內(nèi)部核心邏輯的運行情況,比如關鍵環(huán)節(jié)的耗時以及執(zhí)行過程中的錯誤等。由于這是應用程序內(nèi)部的狀態(tài),從外部通常無法直接獲取到詳細的性能數(shù)據(jù)。所以,應用程序在設計和開發(fā)時,就應該把這些指標提供出來,以便監(jiān)控系統(tǒng)可以了解其內(nèi)部運行狀態(tài)。有了應用進程的資源使用指標,你就可以把系統(tǒng)資源的瓶頸跟應用程序關聯(lián)起來,從而迅速定位因系統(tǒng)資源不足而導致的性能問題;有了應用程序之間的調(diào)用指標,你可以迅速分析出一個請求處理的調(diào)用鏈中,到底哪個組件才是導致性能問題的罪魁禍首;而有了應用程序內(nèi)部核心邏輯的運行性能,你就可以更進一步,直接進入應用程序的內(nèi)部,定位到底是哪個處理環(huán)節(jié)的函數(shù)導致了性能問題。基于這些思路,我相信你就可以構建出,描述應用程序運行狀態(tài)的性能指標。再將這些指標納入我們上一期提到的監(jiān)控系統(tǒng)(比如 Prometheus + Grafana)中,就可以跟系統(tǒng)監(jiān)控一樣,一方面通過告警系統(tǒng),把問題及時匯報給相關團隊處理;另一方面,通過直觀的圖形界面,動態(tài)展示應用程序的整體性能。
2、全鏈路監(jiān)控
業(yè)務系統(tǒng)通常會涉及到一連串的多個服務,形成一個復雜的分布式調(diào)用鏈。為了迅速定位這類跨應用的性能瓶頸,你還可以使用 Zipkin、Jaeger、Pinpoint 等各類開源工具,來構建全鏈路跟蹤系統(tǒng)。比如,下圖就是一個 Jaeger 調(diào)用鏈跟蹤的示例。
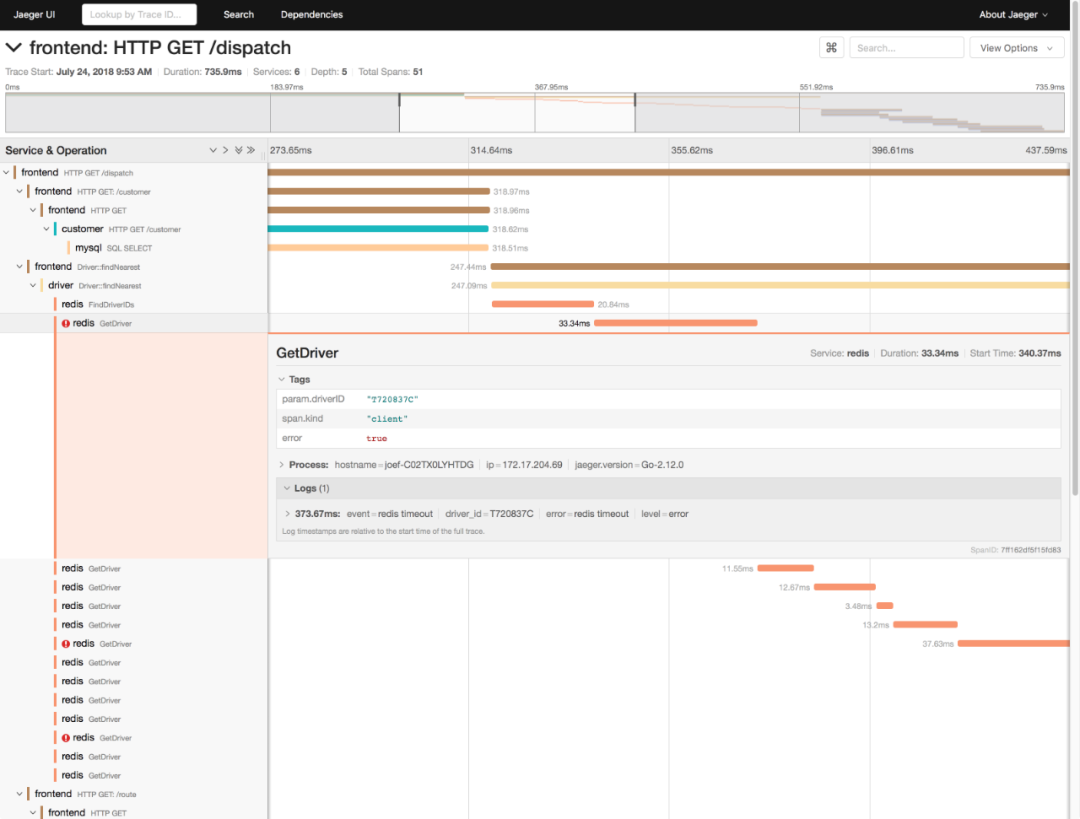
全鏈路跟蹤可以幫你迅速定位出,在一個請求處理過程中,哪個環(huán)節(jié)才是問題根源。比如,從上圖中,你就可以很容易看到,這是 Redis 超時導致的問題。全鏈路跟蹤除了可以幫你快速定位跨應用的性能問題外,還可以幫你生成線上系統(tǒng)的調(diào)用拓撲圖。這些直觀的拓撲圖,在分析復雜系統(tǒng)(比如微服務)時尤其有效。
3、日志監(jiān)控
性能指標的監(jiān)控,可以讓你迅速定位發(fā)生瓶頸的位置,不過只有指標的話往往還不夠。比如,同樣的一個接口,當請求傳入的參數(shù)不同時,就可能會導致完全不同的性能問題。所以,除了指標外,我們還需要對這些指標的上下文信息進行監(jiān)控,而日志正是這些上下文的最佳來源。對比來看,指標是特定時間段的數(shù)值型測量數(shù)據(jù),通常以時間序列的方式處理,適合于實時監(jiān)控。而日志則完全不同,日志都是某個時間點的字符串消息,通常需要對搜索引擎進行索引后,才能進行查詢和匯總分析。對日志監(jiān)控來說,最經(jīng)典的方法,就是使用 ELK 技術棧,即使用 Elasticsearch、Logstash 和 Kibana 這三個組件的組合。如下圖所示,就是一個經(jīng)典的 ELK 架構圖:
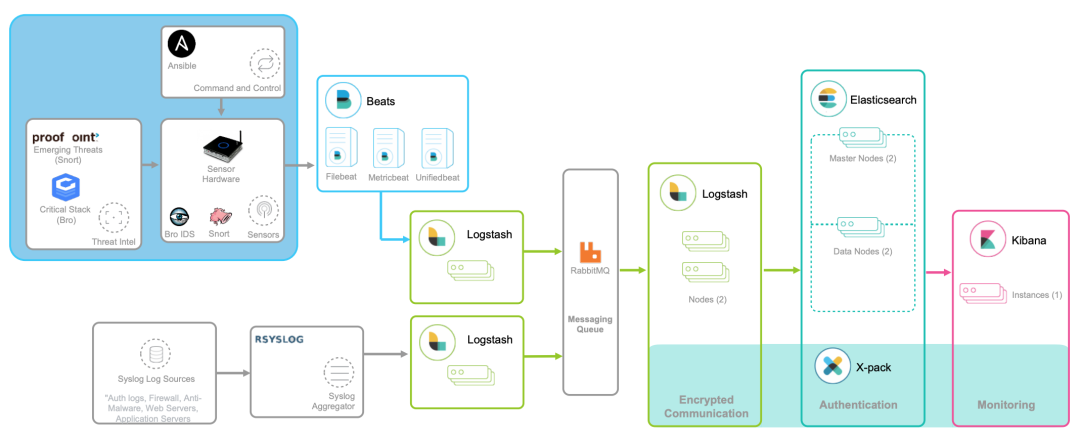
Logstash 負責對從各個日志源采集日志,然后進行預處理,最后再把初步處理過的日志,發(fā)送給 Elasticsearch 進行索引。Elasticsearch 負責對日志進行索引,并提供了一個完整的全文搜索引擎,這樣就可以方便你從日志中檢索需要的數(shù)據(jù)。Kibana 則負責對日志進行可視化分析,包括日志搜索、處理以及絢麗的儀表板展示等。下面這張圖,就是一個 Kibana 儀表板的示例,它直觀展示了 Apache 的訪問概況。
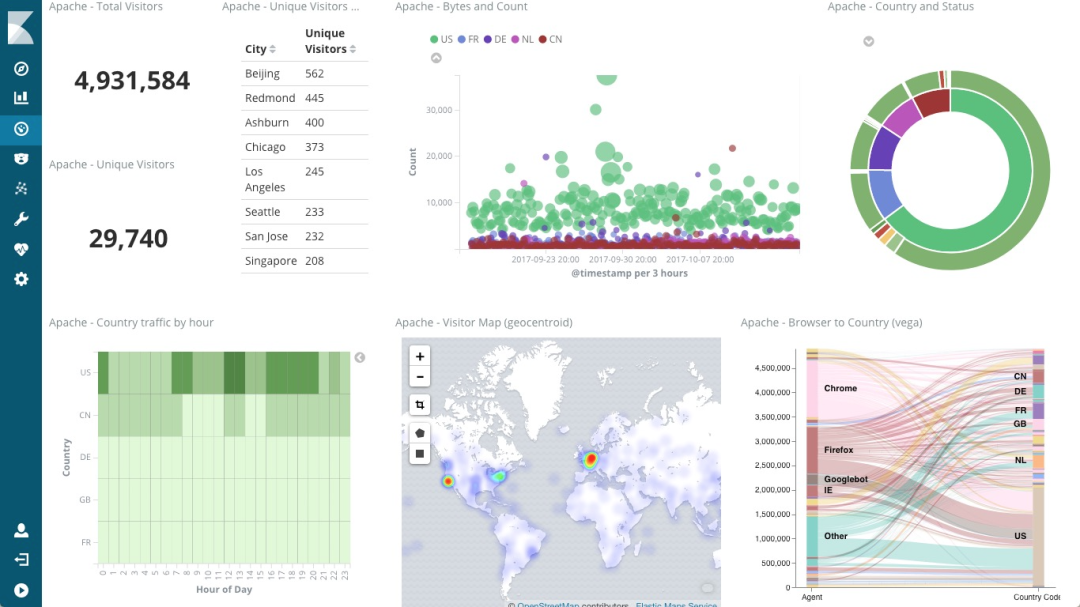
值得注意的是,ELK 技術棧中的 Logstash 資源消耗比較大。所以,在資源緊張的環(huán)境中,我們往往使用資源消耗更低的 Fluentd,來替代 Logstash(也就是所謂的 EFK 技術棧)。
4、最后總結
應用程序的監(jiān)控,可以分為指標監(jiān)控和日志監(jiān)控兩大部分:指標監(jiān)控主要是對一定時間段內(nèi)性能指標進行測量,然后再通過時間序列的方式,進行處理、存儲和告警。日志監(jiān)控則可以提供更詳細的上下文信息,通常通過 ELK 技術棧來進行收集、索引和圖形化展示。在跨多個不同應用的復雜業(yè)務場景中,你還可以構建全鏈路跟蹤系統(tǒng)。這樣可以動態(tài)跟蹤調(diào)用鏈中各個組件的性能,生成整個流程的調(diào)用拓撲圖,從而加快定位復雜應用的性能問題。