手把手教你搞定四類數據清洗操作
一、 缺失值清洗
相信大家都聽說過這樣一句話:廢料進、廢品出(Garbage in, Garbage out)。如果模型基于錯誤的、無意義的數據建立,那么這個模型也會出錯。因此,如果源數據帶有缺失值(NaN),就需要在數據預處理中進行清洗。缺失值是最常見的數據問題,有很多處理缺失值的方法,一般均按照以下四個步驟進行。
1. 確定缺失值范圍
具體代碼如下:
# 檢查數據缺失情況
def check_missing_data(df):
return df.isnull().sum().sort_values(ascending = False)
check_missing_data(rawdata)
Income 1
Age 1
Online Shopper 0
Region 0
dtype: int64
對每個字段都計算其缺失值比例后,按照缺失比例和字段重要性,分別制定相應的解決策略,可用圖3-6表示。
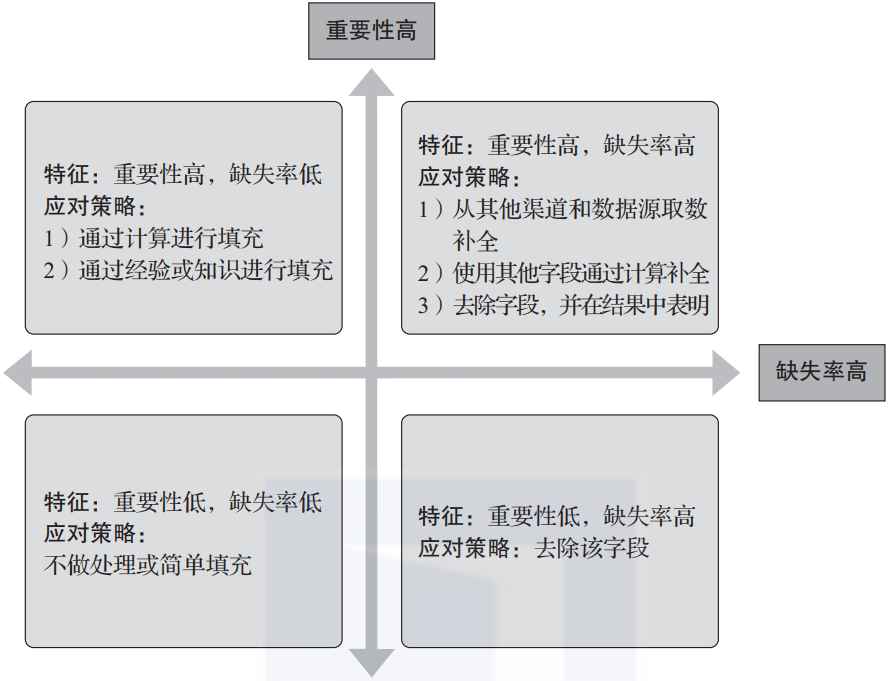
▲圖3-6 缺失值應對策略
圖3-6看似明確了不同情況的應對策略,但在實際應用中對特征的重要性判斷非常復雜,通常需要到模型中去判斷。對數據庫進行研究并對所需解決的問題進行分析,可確定哪些特征屬于重要特征,哪些特征可以省去或者刪掉。
比如我們很難對每個數據的ID(獨特編碼)進行補全,在有的情境下這些信息是必要信息,不能夠缺失,而在有的情境下卻根本不需要這類信息。
比如我們有一組網購記錄信息,其中包括每個用戶在不同時間段的操作。當我們希望對每個用戶進行分析的時候,用戶名(UserID)就是不可或缺的,那么缺失用戶名的數據很可能需要被清除。但如果我們不需要精確到對個人行為進行分析,那么用戶名就沒那么必要了。
所以在缺失值補全的操作前,探索數據和深入了解數據庫是必要的。我們必須清楚每個變量所代表的含義,以及分析的問題可能關聯的數據。在一個非常復雜的數據庫中,在解決某個實際問題時,通常不需要所有的變量參與運算。
2. 去除不需要的字段
本步驟將減少數據維度,剔除一些明顯與數據分析任務不匹配的數據,讓與任務相關的數據更為突出。注意,最好不要更改原始數據,只是在下一步處理前提取出用于分析的數據。
同時這一步需要考慮之前缺失值的情況,保留對于有些缺失值占比不大或者通過其他信息可以進行推斷的特征,去除缺失量太多的數據行或列。對于新手,強烈建議在清洗的過程中每做一步都備份一下,或者在小規模數據上試驗成功后再處理全量數據,節約時間,也充分留足撤銷操作的余地。
3. 填充缺失內容
具體代碼如下:
test1 = rawdata.copy()# 將更改前的數據進行備份
test1 = test1.head(3)# 提取前三行進行測試
test1 = test1.dropna()# 去除數據中有缺失值的行
print(test1)
test1
name toy born
0 Andy NaN NaN
1 Cindy Gun 1998-12-25
2 Wendy Gum NaN
test1 = test1.dropna(axis=0)# 去除數據中有缺失值的行
name toy born
1 Cindy Gun 1998-12-25
test1 = test1.dropna(axis='columns')# 去除數據中有缺失值的列
name
0 Andy
1 Cindy
2 Wendy
test1 = test1.dropna(how='all')# 去除數據完全缺失的行
test1 = test1.dropna(thresh=2)# 保留行中至少有兩個值的行
test1 = test1.dropna(how='any')# 去除數據中含有缺失值的行
test1 = test1.dropna(how='any',subset=['toy'])# 去除toy列中含有缺失值的行
test1.dropna(inplace=True)# 在這個變量名中直接保存結果
在實際應用中,第2步和第3步的操作通常協同進行,在判斷完維度相關性與重要性后,對想要保留的維度進行填充,最后對數據行進行必要的清洗,以避免可進行填充的有效字段在清洗時被剔除。
1)以同一指標的計算結果(均值、中位數、眾數等)填充缺失值。代碼如下:
test1 = test1.fillna(test1.mean())# 用均值填充缺失值
test1 = test1.fillna(test1.median())# 用中位數填充缺失值
test1 = test1.fillna(test1.mode())# 用眾數填充缺失值
2)通過找尋帶有缺失值的變量與其他數據完整的變量之間的關系進行建模,使用計算結果進行填充(這一方法較為復雜,而且結果質量可能參差不齊,可在后期習得數據建模技巧后進行嘗試)。
3)以其他變量的計算結果填充缺失值。舉個最簡單的例子:年齡字段缺失,但是有屏蔽后六位的身份證號信息,那么就可以輕松找出出生年月,算出目前年齡。
4)以業務知識或經驗推測填充缺失值。
4. 重新取數
如果某些變量非常重要同時缺失率高,那就需要和取數人員或業務人員進行溝通,了解是否有其他渠道可以取到相關數據。
繼續以Income_n_onlineshopping為例介紹,如圖3-7所示。
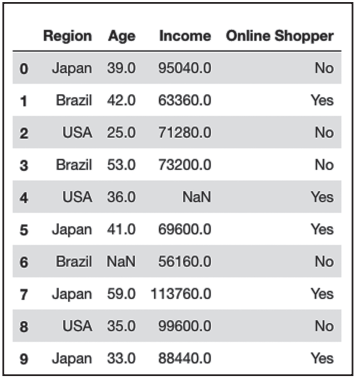
▲圖3-7 查看數據是否存在缺失值
統計各列的缺失值情況,結果如圖3-8所示。
dataset.isna().sum() # 統計各列缺失值情況
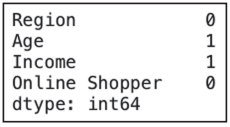
▲圖3-8 統計數據缺失值個數
從圖3-7可以看出,這10行數據中第4行和第6行的部分值顯示為NaN,也就是數據發生缺失。有時數據本身可能并不是在缺失值位置上留空,而是用0對空缺位置進行填充,根據對數據的理解我們也可以分辨出是否需要對0值數據進行統計和轉換。
由于數值缺失占比較少,我們可以通過計算填補空缺,這里我們采用平均值填充。
# 設定填充方式為平均值填充
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
# 選取目標列
imputer = imputer.fit(rawdata.iloc[:,1:3])
# 對計算結果進行填充
rawdata.iloc[:,1:3] = imputer.transform(rawdata.iloc[:,1:3])
# 調整數據
rawdata.iloc[:,1:3] = rawdata.iloc[:,1:3].round(0).astype(int)
二、 格式內容清洗
如果數據是由系統日志而來的,那么通常會在格式和內容方面與元數據的描述保持一致。而如果數據是由人工收集或用戶填寫而來的,則有很大可能會在格式和內容上存在問題。簡單來說,格式和內容的問題有以下幾類。
1. 時間、日期、數值、全半角等格式不一致
這種問題通常與輸入端有關,在整合多來源數據時也有可能遇到,將其處理成一致的格式即可。
2. 數據值含有“非法”字符
字段中的值通常是有范圍的,有些字符不適合出現在某些字段中,比如:
身份證號必須是數字+字母。
中國人姓名只能為漢字(李A、張C這種情況是少數)。
出現在頭、尾、中間的空格。
解決這類問題時,需要以半自動校驗半人工方式來找出可能存在的問題,并去除不合適的字符。
3. 數據值與該字段應有內容不符
例如,姓名欄填了性別、身份證號中寫了手機號等。這類問題的特殊性在于不能簡單地以刪除方式來處理,因為有可能是人工填寫錯誤,前端沒有校驗,或者導入數據時部分或全部存在列沒有對齊導致,需要具體識別問題類型后再有針對性地解決。
格式內容出錯是非常細節的問題,但很多分析失誤都是源于此問題。比如跨表關聯失敗,是因為多個空格導致關鍵字段進行交集運算時認為“劉翔”和“劉 翔”不是一個人;統計值不全,是因為數字里摻個字母在之后求和時發生問題;模型輸出失敗或效果不好,是因為數據對錯列了,把日期和年齡混了等。
因此,在進行這一步時,需要仔細檢查數據格式和內容,特別是當數據源自用戶手工填寫且校驗機制不完善時。
三 、邏輯錯誤清洗
這一步工作的目的是去掉一些使用簡單邏輯推理就可以直接發現問題的數據,防止由此導致分析結果偏差。邏輯錯誤清洗主要包含以下幾個步驟。
1. 去重
由于格式不同,原本重復的數據被認為并非重復而沒能成功剔除,比如由于空格導致算法認為“劉翔”和“劉 翔”不是一個人,去重失敗。由于重名的情況很常見,即使中間空格被去掉后兩條數據的值一致,也很難直接決定將第二條數據刪除,這時就需要比較其他字段的值。
還有由于關鍵字值輸入時發生錯誤導致原本一致的信息被重復錄入,也需要借助其他字段對內容進行查重。比如“ABC銀行”與“ABC銀行”,單看名字可以看出這兩條信息大概率是重復的,但只有對比其他信息才能確保去重的正確性,比如對比兩家公司的電話與地址是否完全相同。如果數據不是人工錄入的,那么簡單去重即可。
2. 去除不合理值
如果字段內取值超過合理范圍,比如“年齡:180歲;籍貫:火星”,則這種數據要么刪掉,要么按缺失值處理。當然最好的做法是在前期收集這種字段的數據時讓用戶在有限范圍內進行選取,以避免此情況出現。可以通過異常值查找去除不合理值。
3. 修正矛盾內容
有時我們擁有多個包含相同信息的維度特征,這時就可以進行交叉驗證,修復矛盾內容。比如一個隱去后六位的身份證號,100000199701XXXXXX,而年齡字段數據為18,這顯然是不合理的,由于身份證號可信度更高,所以我們應該對年齡字段進行修復。
更好的做法是通過脫敏的身份證號提取出生年月,直接建立新的出生日期字段并用此年齡字段替換用戶手動填寫的年齡字段。
在真實世界中獲取的數據常常會包含錯誤信息,有的是人為導致,有的是非人為導致,我們可以通過交叉驗證及時發現并修復矛盾內容,為后期建模提供更高質量的數據信息。
四 、維度相關性檢查
當數據庫中有多個變量時,我們需要考慮變量之間的相互聯系,而相關性就是用來表示定性變量或定量變量之間關系的。相關性研究可以幫助我們了解變量之間的關聯性。比如:
- 每日食品中卡路里攝入量跟體重很有可能有較大的相關性;
- 子女和父母血型之間具有高關聯性;
- 學習的時間長度和考試成績通常也有高關聯性。
1)檢查數據相關性:
rawdata.corr() # 相關性矩陣
結果如圖3-9所示。
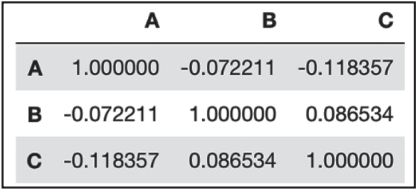
▲圖3-9 相關性矩陣
2)檢查數據協方差:
rawdata.cov() # 協方差矩陣
結果如圖3-10所示。
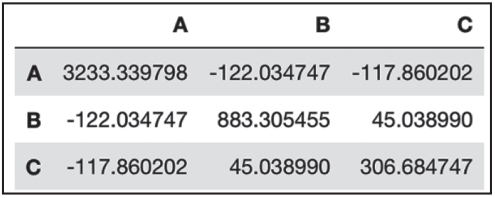
▲圖3-10 協方差矩陣
關于作者:劉鵬,教授,清華大學博士,云計算、大數據和人工智能領域的知名專家,南京云創大數據科技股份有限公司總裁、中國大數據應用聯盟人工智能專家委員會主任。中國電子學會云計算專家委員會云存儲組組長、工業和信息化部云計算研究中心專家。
高中強,人工智能與大數據領域技術專家,有非常深厚的積累,擅長機器學習和自然語言處理,尤其是深度學習,熟悉Tensorflow、PyTorch等深度學習開發框架。曾獲“2019年全國大學生數學建模優秀命題人獎”。參與鐘南山院士指導新型冠狀病毒人工智能預測系統研發項目,與鐘南山院士團隊共同發表學術論文。
本文摘編自《Python金融數據挖掘與分析實戰》,經出版方授權發布。(ISBN:9787111696506)