













如果讓你來設計進程調度,你會怎么辦?
書接上回,上回書咱們說到,操作系統通過move_to_user_mode 方法,通過偽造一個中斷和中斷返回,巧妙地從內核態切換到了用戶態。
void main(void) {
...
move_to_user_mode();
if (!fork()) {
init();
}
for(;;) pause();
}
今天,本來應該再往下講 fork。
但這個是創建新進程的過程,是一個很能體現操作系統設計的地方。
所以我們先別急著看代碼,我們今天就頭腦風暴一下,就是如果讓你來設計整個進程調度,你會怎么搞? 別告訴我你先設計鎖、設計 volatile 啥的,這都不是進程調度本身需要關心的最根本問題。
進程調度本質是什么?很簡單,假如有三段代碼被加載到內存中。

進程調度就是讓 CPU 一會去程序 1 的位置處運行一段時間,一會去程序 2 的位置處運行一段時間。
嗯,就這么簡單,別反駁我,接著往下看。
整體流程設計
如何做到剛剛說的,一會去這運行,一會去那運行?
第一種辦法就是,程序 1 的代碼里,每隔幾行就寫一段代碼,主動放棄自己的執行權,跳轉到程序 2 的地方運行。然后程序 2 也是如此。
但這種依靠程序自己的辦法肯定不靠譜。 所以第二種辦法就是,由一個不受任何程序控制的,第三方的不可抗力,每隔一段時間就中斷一下 CPU 的運行,然后跳轉到一個特殊的程序那里,這個程序通過某種方式獲取到 CPU 下一個要運行的程序的地址,然后跳轉過去。 這個每隔一段時間就中斷 CPU 的不可抗力,就是由定時器觸發的時鐘中斷。
不知道你是否還記得,這個定時器和時鐘中斷,早在 第18回 | 大名鼎鼎的進程調度就是從這里開始的 里講的 sched_init 函數里就搞定了。
而那個特殊的程序,就是具體的進程調度函數了。 好了,整個流程就這樣處理完了,那么應該設計什么樣的數據結構,來支持這個流程呢?不妨假設這個結構叫 tast_struct。
struct task_struct {
?
}
換句話說,你總得有一個結構來記錄各個進程的信息,比如它上一次執行到哪里了,要不 CPU 就算決定好了要跳轉到你這個進程上運行,具體跳到哪一行運行,總得有個地方存吧?
我們一個個問題拋開來看。
上下文環境
每個程序最終的本質就是執行指令。這個過程會涉及寄存器,內存和外設端口。 內存還有可能設計成相互錯開的,互不干擾,比如進程 1 你就用 0~1K 的內存空間,進程 2 就用 1K~2K 的內存空間,咱誰也別影響誰。
雖然有點浪費空間,而且對程序員十分不友好,但起碼還是能實現的。
不過寄存器一共就那么點,肯定做不到互不干擾,可能一個進程就把寄存器全用上了,那其他進程咋整。
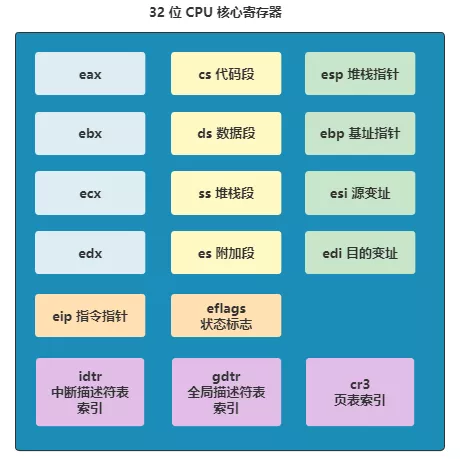
比如程序 1 剛剛往 eax 寫入一個值,準備用,這時切換到進程 2 了,又往 eax 里寫入了一個值。那么之后再切回進程 1 的時候,就出錯了。 所以最穩妥的做法就是,每次切換進程時,都把當前這些寄存器的值存到一個地方,以便之后切換回來的時候恢復。 Linux 0.11 就是這樣做的,每個進程的結構 task_struct 里面,有一個叫 tss 的結構,存儲的就是 CPU 這些寄存器的信息。
struct task_struct {
...
struct tss_struct tss;
}
struct tss_struct {
long back_link; /* 16 high bits zero */
long esp0;
long ss0; /* 16 high bits zero */
long esp1;
long ss1; /* 16 high bits zero */
long esp2;
long ss2; /* 16 high bits zero */
long cr3;
long eip;
long eflags;
long eax,ecx,edx,ebx;
long esp;
long ebp;
long esi;
long edi;
long es; /* 16 high bits zero */
long cs; /* 16 high bits zero */
long ss; /* 16 high bits zero */
long ds; /* 16 high bits zero */
long fs; /* 16 high bits zero */
long gs; /* 16 high bits zero */
long ldt; /* 16 high bits zero */
long trace_bitmap; /* bits: trace 0, bitmap 16-31 */
struct i387_struct i387;
};
這里提個細節。
你發現 tss 結構里還有個 cr3 不?它表示 cr3 寄存器里存的值,而 cr3 寄存器是指向頁目錄表首地址的。
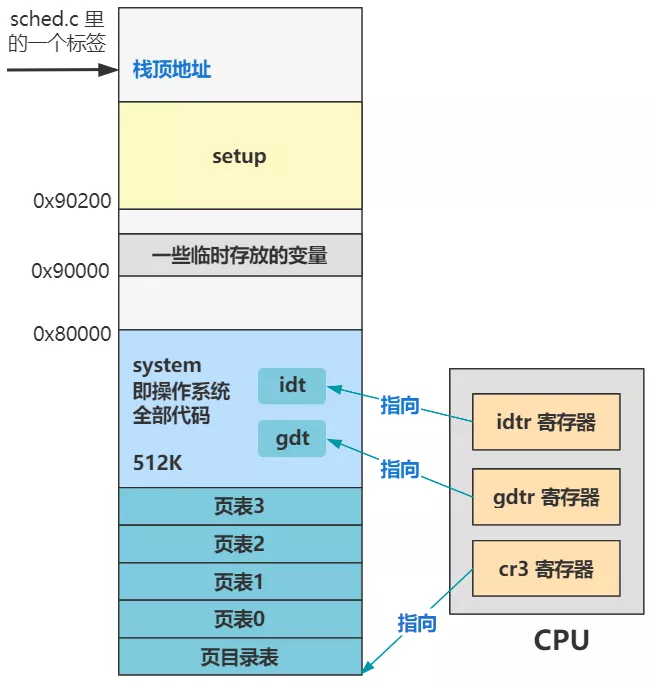
那么指向不同的頁目錄表,整個頁表結構就是完全不同的一套,那么邏輯地址到線性地址的映射關系就有能力做到不同。 也就是說,在我們剛剛假設的理想情況下,不同程序用不同的內存地址可以做到內存互不干擾。
但是有了這個 cr3 字段,就完全可以無需由各個進程自己保證不和其他進程使用的內存沖突,因為只要建立不同的映射關系即可,由操作系統來建立不同的頁目錄表并替換 cr3 寄存器即可。
這也可以理解為,保存了內存映射的上下文信息。
當然 Linux 0.11 并不是通過替換 cr3 寄存器來實現內存互不干擾的,它的實現更為簡單,這是后話了。
運行時間信息
如何判斷一個進程該讓出 CPU 了,切換到下一個進程呢? 總不能是每次時鐘中斷時都切換一次吧?一來這樣不靈活,二來這完全依賴時鐘中斷的頻率,有點危險。 所以一個好的辦法就是,給進程一個屬性,叫剩余時間片,每次時鐘中斷來了之后都 -1,如果減到 0 了,就觸發切換進程的操作。 在 Linux 0.11 里,這個屬性就是 counter。
struct task_struct {
...
long counter;
...
struct tss_struct tss;
}
而他的用法也非常簡單,就是每次中斷都判斷一下是否到 0 了。
void do_timer(long cpl) {
...
// 當前線程還有剩余時間片,直接返回
if ((--current->counter)>0) return;
// 若沒有剩余時間片,調度
schedule();
}
如果還沒到 0,就直接返回,相當于這次時鐘中斷什么也沒做,僅僅是給當前進程的時間片屬性做了 -1 操作。
如果已經到 0 了,就觸發進程調度,選擇下一個進程并使 CPU 跳轉到那里運行。
進程調度的邏輯就是在 schedule 函數里,怎么調,我們先不管。
優先級
上面那個 counter 一開始的時候該是多少呢?而且隨著 counter 不斷遞減,減到 0 時,下一輪回中這個 counter 應該賦予什么值呢? 其實這倆問題都是一個問題,就是 counter 的初始化問題,也需要有一個屬性來記錄這個值。 往宏觀想一下,這個值越大,那么 counter 就越大,那么每次輪到這個進程時,它在 CPU 中運行的時間就越長,也就是這個進程比其他進程得到了更多 CPU 運行的時間。 那我們可以把這個值稱為優先級,是不是很形象。
struct task_struct {
...
long counter;
long priority;
...
struct tss_struct tss;
}
每次一個進程初始化時,都把 counter 賦值為這個 priority,而且當 counter 減為 0 時,下一次分配時間片,也賦值為這個。
其實叫啥都行,反正就是這么用的,就叫優先級吧。
進程狀態
其實我們有了上面那三個信息,就已經可以完成進程的調度了。 甚至如果你的操作系統讓所有進程都得到同樣的運行時間,連 counter 和 priority 都不用記錄,就操作系統自己定一個固定值一直遞減,減到 0 了就隨機切一個新進程。
這樣就僅僅維護好寄存器的上下文信息 tss 就好了。 但我們總要不斷優化以適應不同場景的用戶需求的,那我們再優化一個細節。 很簡單的一個場景,一個進程中有一個讀取硬盤的操作,發起讀請求后,要等好久才能得到硬盤的中斷信號。 那這個時間其實該進程再占用著 CPU 也沒用,此時就可以選擇主動放棄 CPU 執行權,然后再把自己的狀態標記為等待中。
意思是告訴進程調度的代碼,先別調度我,因為我還在等硬盤的中斷,現在輪到我了也沒用,把機會給別人吧。 那這個狀態可以記錄一個屬性了,叫 state,記錄了此時進程的狀態。
struct task_struct {
long state;
long counter;
long priority;
...
struct tss_struct tss;
}
而這個進程的狀態在 Linux 0.11 里有這么五種。
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_ZOMBIE 3
#define TASK_STOPPED 4
好了,目前我們這幾個字段,就已經可以完成簡單的進程調度任務了。
有表示狀態的 state,表示剩余時間片的counter,表示優先級的 priority,和表示上下文信息的 tss。
其他字段我們需要用到的時候再說,今天只是頭腦風暴一下進程調度設計的思路。 我們看一下 Linux 0.11 中進程結構的全部,心里先有個數,具體干嘛的先別管,就記住我們剛剛頭腦風暴的那四個字段就行了。
struct task_struct {
/* these are hardcoded - don't touch */
long state; /* -1 unrunnable, 0 runnable, >0 stopped */
long counter;
long priority;
long signal;
struct sigaction sigaction[32];
long blocked; /* bitmap of masked signals */
/* various fields */
int exit_code;
unsigned long start_code,end_code,end_data,brk,start_stack;
long pid,father,pgrp,session,leader;
unsigned short uid,euid,suid;
unsigned short gid,egid,sgid;
long alarm;
long utime,stime,cutime,cstime,start_time;
unsigned short used_math;
/* file system info */
int tty; /* -1 if no tty, so it must be signed */
unsigned short umask;
struct m_inode * pwd;
struct m_inode * root;
struct m_inode * executable;
unsigned long close_on_exec;
struct file * filp[NR_OPEN];
/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */
struct desc_struct ldt[3];
/* tss for this task */
struct tss_struct tss;
};
看吧,其實也沒多少咯~
好了,今天我們完全由自己從零到有設計出了進程調度的大體流程,以及它需要的數據結構。
我們知道了進程調度的開始,要從一次定時器滴答來觸發,通過時鐘中斷處理函數走到進程調度函數,然后去進程的結構 task_struct 中取出所需的數據,進行策略計算,并挑選出下一個可以得到 CPU 運行的進程,跳轉過去。 那么下一講,我們從一次時鐘中斷出發,看看一次 Linux 0.11 的進程調度的全過程。有了這兩回做鋪墊,之后再看主流程中的 fork 代碼,將會非常清晰! 欲知后事如何,且聽下回分解。
本文轉載自微信公眾號「低并發編程」,可以通過以下二維碼關注。轉載本文請聯系低并發編程公眾號。





















