之前被問的 ConcurrentHashMap 面試題,我匯總一下!
本文轉載自微信公眾號「yes的練級攻略」,作者是Yes呀。轉載本文請聯系yes的練級攻略公眾號。
你好,我是yes。
上篇講了??集合類的相關面試點??已經包含 HashMap 了,這篇就來盤盤 ConcurrentHashMap。
我們都知道 HashMap 是非線程安全的,然后還有個 HashTable ,這玩意雖說是線程安全,但所有方法用的是同一把鎖,并發度太低,性能不好。
所以,如要在并發場景下使用 Map ,那就推薦用 ConcurrentHashMap。
而談到 ConcurrentHashMap,經常會被問到 JDK1.8 相對于 1.7 版本做哪些優化,所以我們先來看下 1.7 的是實現。
ConcurrentHashMap 1.7
其實大體的哈希表實現跟 HashMap 沒有本質的區別,都是經過 key 的 hash 定位到一個下標,然后獲取元素,如果沖突了就用鏈表相連。
差別就在于引入了一個 Segments 數組,我們來看下大致的結構。
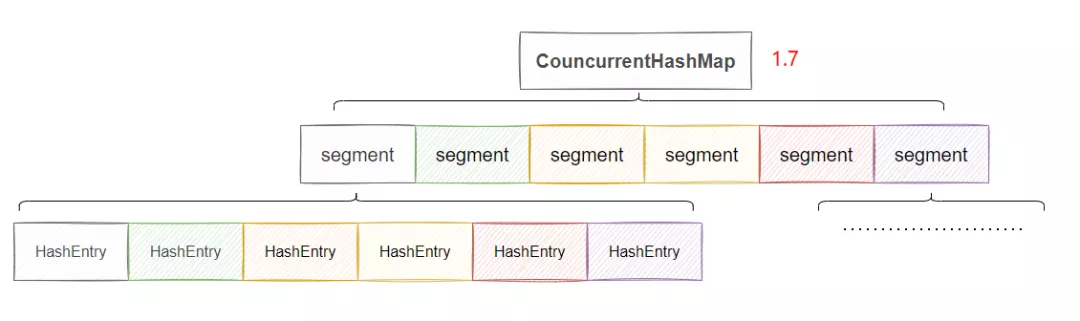
原理就是先通過 key 的 hash 判斷得到 Segment 數組的下標,然后將這個 Segment 上鎖,然后再次通過 key 的 hash 得到 Segment 里 HashEntry 數組的下標,下面這步其實就是 HashMap 一致了,所以我說差別就是引入了一個 Segments 數組。
因此可以簡化的這樣理解:每個 Segment 數組存放的就是一個單獨的 HashMap。
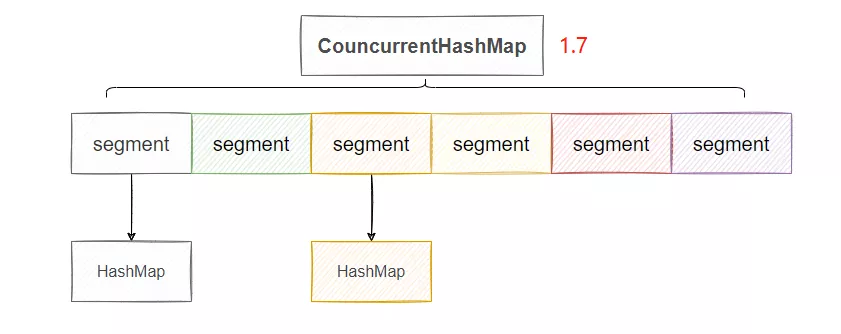
可以看到,圖上我們有 6 個 Segment ,那么等于有六把鎖,因此共可以有六個線程同時操作這個 ConcurrentHashMap,并發度就是 6,相比于直接將 put 方法上鎖,并發度就提高了,這就是分段鎖。
具體上鎖的方式來源于 Segment ,這個類實際繼承了 ReentrantLock,因此它自身具備加鎖的功能。
可以看出,1.7 的分段鎖已經有了細化鎖粒度的概念,它的一個缺陷是 Segment 數組一旦初始化了之后不會擴容,只有 HashEntry 數組會擴容,這就導致并發度過于死板,不能隨著數據的增加而提高并發度。
ConcurrentHashMap 1.8
1.8 ConcurrentHashMap 做了更細粒度的鎖控制,可以理解為 1.8 HashMap 的數組的每個位置都是一把鎖,這樣擴容了鎖也會變多,并發度也會增加。
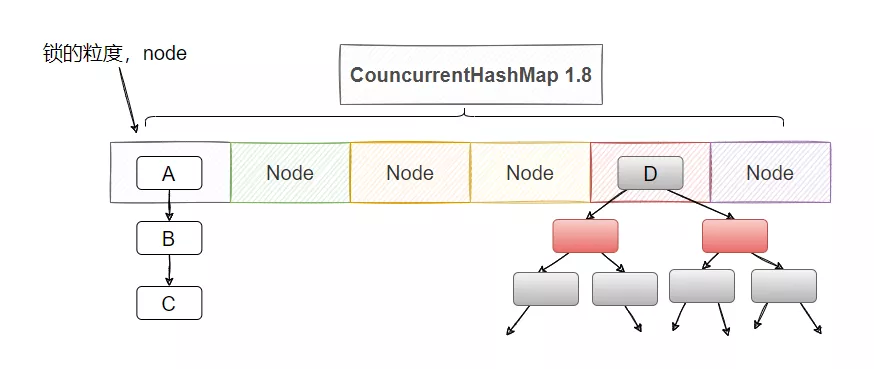
思想的轉變就是把粒度更加細化,我不分段了,我直接把 Node 數組的每個節點分別上一把鎖,這樣并發度不就更高了嗎?
并且 1.8 也不借助于 ReentrantLock 了,直接用 synchronized,這也側面證明,都 1.8 了 synchronized 優化后的速度已經不下于 ReentrantLock 了。
具體實現思路也簡單,當塞入一個值的時候,先計算 key 的 hash 后的下標,如果計算到的下標還未有 Node ,那么就通過 cas 塞入新的 Node。如果已經有 node 則通過 synchronized 將這個 node 上鎖,這樣別的線程就無法訪問這個 node 及其之后的所有節點。
然后判斷 key 是否相等,相等則是替換 value ,反之則是新增一個 node,這個操作和 HashMap 是一樣的。
1.8 的擴容也是有點意思的,它允許協助擴容,也就是多線程擴容。
當 put 的時候,發現當前 node hash 值是 -1,則表明當前的節點正在擴容,則會觸發協助擴容機制

這個要詳細說起來還真的有點麻煩,而且不太好說清,代碼有點大,我就說個大概。
其實大家大致理解下就夠了:
擴容無非就是搬遷 Node,假設當前數組長度為 32,那就可以分著搬遷,31-16 這幾個下標的 Node 都由線程A來搬遷,然后線程 B 來搬遷 15-0 這幾個下標的 Node。
簡單說就是會維護一個 transferIndex 變量,來的線程死循環 cas 爭搶下標,如果下標已經分配完了,那自然就不需要搬遷了,如果 cas 搶到了要搬運的下標,那就去幫忙搬就好了,就是這么個事兒。
還有 1.8 的 size 方法和 1.7 也不一樣1.7 有個嘗試的思想,當調用 size 方法的時候不會加鎖,而是先嘗試三次不加鎖獲取 sum。
如果三次總數一樣,說明當前數量沒有變化,那就直接返回了。如果總數不一樣,那說明此時有線程在增刪 map,于是加鎖計算,這時候其他線程就操作不了 map 了。
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
...再累加數量
而 1.8 不一樣,它就是直接計算返回結果,具體采用的是類似 LongAdder 的思想,累加不再是基于一個成員變量,而是搞了一個數組,每個線程在自己對應的下標地方進行累加,等最后的時候把數組里面的數據統一一下,就是最終的值了。
所以這是一個分解的思想,分而治之。
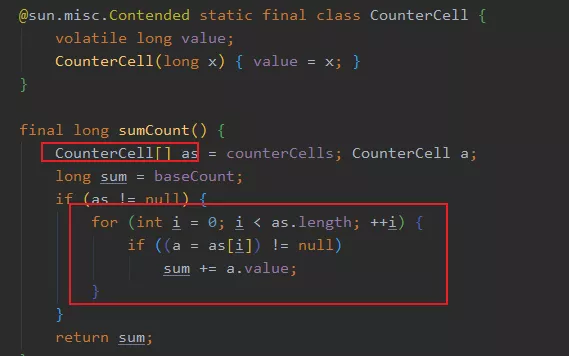
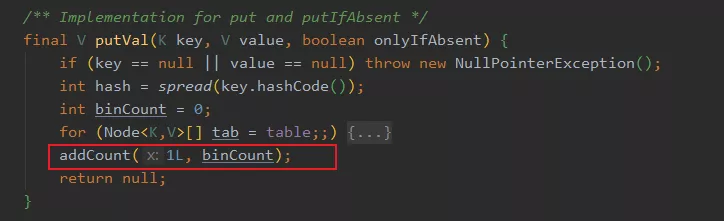
在 put 的時候,就會通過 addCount 方法維護 counterCells 的數量,當然 remove 的時候也會調用此方法。
總而言之,就是平日的操作會維護 map 里面的節點數量,會先通過 CAS 修改 baseCount ,如果成功就直接返回,如果失敗說明此時有線程在競爭,那么就通過 hash 選擇一個 CounterCell 對象就行修改,最終 size 的結果就是 baseCount + 所有 CounterCell 。
這種通過 counterCell 數組來減少并發下場景下對單個成員變量的競爭壓力,提高了并發度,提升了性能,這也就是 LongAdder 的思想。
這里還有個能問的就是 @sun.misc.Contended 注解了,這個和偽共享有關系,具體可以看看我之前寫的這篇文章:
ConcurrentHashMap#get需要加鎖嗎?不需要加鎖。
保證 put 的時候線程安全之后,get 的時候只需要保證可見性即可,而可見性不需要加鎖。
具體是通過Unsafe#getXXXVolatile 和用 volatile 來修飾節點的 val 和 next 指針來實現的。
為什么 ConcurrentHashMap 不支持 key 或者 value 為 null ?
首先, key 為什么也不能為 null ?我不知道,沒想明白,可能是作者 lea 佬不喜歡 null 值。
那 value 為什么不能為 null ?
因為在多線程情況下, null 值會產生二義性,因為你不清楚 map 里到底是不存在在這個 key ,還是說被put(key,null)。
這里可能有人會說,那 HashMap 不一樣有這個問題?HashMap 可以通過 containsKey 來判斷是否存在這個 key,而多線程使用的 ConcurrentHashMap 就不能夠。
比如你 get(key) 得到了null,此時map里面沒有這個 key 的,但是你不知道,所以你想調用 containsKey 看看,而恰巧在你調用之前,別的線程 put 了這個 key ,這樣你 containsKey 就發現有這個 key,這是不是就發生“誤會”了。
最后
對 ConcurrentHashMap 的了解到這份上差不多了,再多的可以看看源碼,里面還是有很多值得學習的地方。
集合類的面試題到這就差不多了,后面寫 Spring 的面試題。
還有我的面試倉庫,上面已經有很多面試題啦,求個 star!點擊閱讀原文,也可訪問~
??https://github.com/yessimida/interview-of-legends??
我是yes,我們下篇見~