故障分析自動化難在什么地方
2017年什么準備開發D-SMART這個產品的時候,是受到“知識自動化”這個理念的啟發,想通過運維知識圖譜積累運維經驗,再輔助以深度學習、人工智能的算法,實現復雜的數據庫運維問題的自動化。一晃這件事也做了四年了,雖然說摸到了一些門道,不過前面依然是漫漫長路,和剛上路不同的是,現在天已經蒙蒙亮了,不像我們剛剛出發的時候,只能看到前面黑沉沉的長路。這條路已經被證明是能走得通的,剩下來的是通過漫長的積累,逐步完善知識庫。
我們的知識庫是在不斷的實踐過程中慢慢的積累,隨著從案例中提取的知識的積累不斷地彌補整個知識網絡中的缺陷,讓知識更豐富,能發揮更大的作用。因此每個案例對我們來實都是十分珍貴的,必須從中挖掘出最大的價值才行。
可能有朋友要說了,這有什么難的,把以往的案例抽象出來,形成知識,下次再遇到類似的問題就可以處理了,框架已經打好了,剩下的只要積累不就行了。這實際上也是我最初的想法,不過做到今天,隨著我們不斷的拿到客戶現場的實際案例,我們發現實際上故障自動化分析并不是那么簡單的事情。
昨天有個客戶說他們的系統中有個業務比較慢,通過TOP EVENT發現存在大量的latch: row cache objects等待,有個業務相關的SQL執行的十分緩慢,要數秒鐘才能完成。客戶那邊處置這些問題的經驗也十分豐富,很快就找到了等待這些閂鎖的語句都是一條類似的語句,因為這條語句并沒有試用綁定變量,所以每次都是硬解析。這個問題大概率是和解析有關。從D-SMART的問題分析報告中也能夠找到出問題的這條SQL的情況。
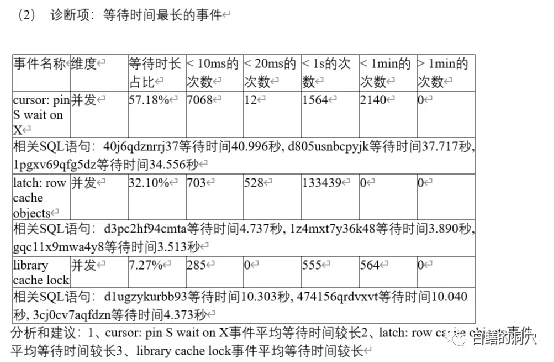
在這個分析里,我們的工具做的還不夠細致,只是列出了問題,并沒有做進一步的根因分析,這個案例也讓我們發現了工具的不足。不過從這些列出的情況也可以看出解析一定是出了什么問題。因為當時這個問題已經影響了一些交易,因此需要馬上先解決問題。客戶那邊分析后立即采取了一個措施,將cursor_sharing設置為similar,修改參數后,問題立即消失了,系統也恢復了正常。
事后我讓客戶把問題分析報告和當時的AWR報告發給了我,上班后,我們也會把這個案例的監控數據帶回來仔細分析分析。這種特殊的案例對于完善知識圖譜是十分關鍵的。這些年我們已經很少發現因為硬解析而引發的性能問題了。一般來說,以目前的PC服務器的硬件來說,因為CPU的核數較多,硬解析帶來的問題已經越來越少了,因為一次解析的時間也就是幾個毫秒到幾十毫秒,強大的硬件資源足以支撐十分高并發的解析。不過問題并不是那么簡單的,昨天的這個案例就是一個十分珍貴的特例的案例,具有十分高的價值。
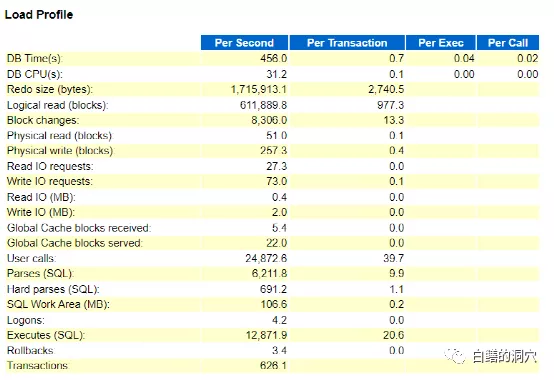
從load profile上看,系統負載還不算高,每秒600多的事務,12871的執行,數量只能算是中等。不過每秒6211次的解析說明無解析執行的比例很低,硬解析691,占11%多一點,解析數量很高,但是應該還不至于出現如此大的問題的。
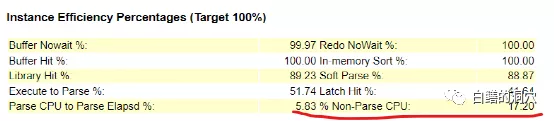
命中率指標有個十分大的疑點,那就是非解析CPU比例僅為17.2%,反過來看,就是解析占用的CPU資源高達83%左右,這是在以往的系統中很少會看到的現象。這是一臺4路14核28線程的服務器,整個服務器有56個核,112線程,從D-SMART的報告中可以看出,CPU的使用率大概是在30%左右。
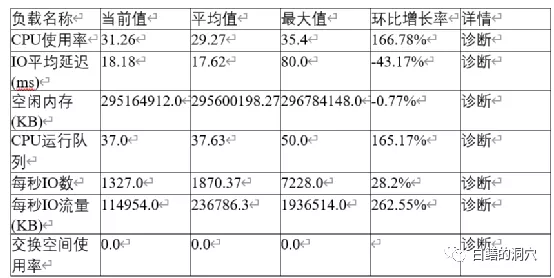
從操作系統層面上看,各種資源還是比較充足的,CPU的R隊列最大值也沒有超過CPU的線程數。按理說當前的硬件資源是足以支撐當時的并發解析的量的。實際上當時客戶電話里和我溝通這個問題的時候,我也猜測了latch:row cache objects等待比較嚴重可能存在的幾種問題,系統有HANG住的現象,SGA RESIZE,存在DDL操作,SGA設置太小等等。不過這些問題當時都查看過,而且也被一一排除了。
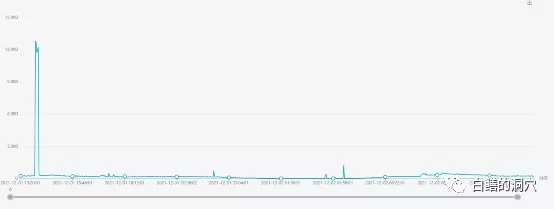
去年12月1日的歷史數據
我們實驗室正好有這套系統去年的歷史數據,從歷史數據上看,硬解析數量一直很高,甚至有時候高達12000+/秒,不過用戶那邊以前并沒有發現其中存在什么問題。
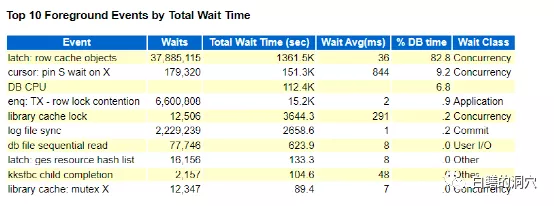
從TOP EVENT上看,latch:row cache objects的平均等待時間為36毫秒。似乎這個等待時間也不高,不過如果算上一個事務平均要等待10多次這個等待事件,對系統的影響就很大了。

平時這個等待時間的延時為0.13毫秒,偶爾會出現15多毫秒的點,不過一小時平均值36毫秒的情況還沒有出現過。一下子暴增200多倍,導致系統異常也就很正常了。不過latch:row cache objects的延時為什么會達到這么高?執行數量過大,解析數量過大,硬解析過大嗎?
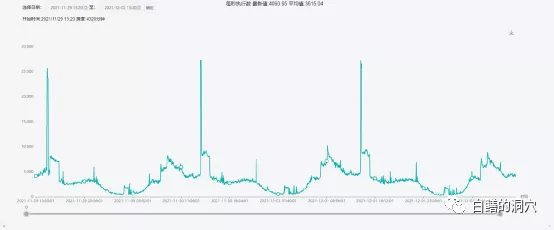
執行數量上看,這個系統每秒的執行數量平均值在3000-4000之間,出問題時段一小時平均值為1.2萬多,是平時的3倍左右。不過平時的高峰期經常會有超過2.5萬/秒的執行高峰,只是沒有持續很長時間而已。
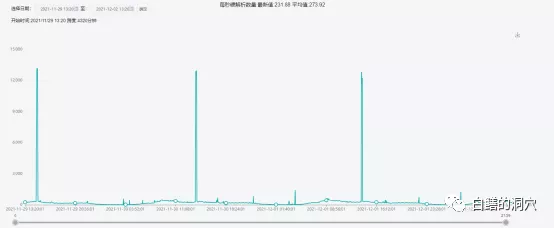
硬解析也是如此,平時的平均值大約略低于300,高峰期也會出現高達1.2萬+的高值,也低于出問題時段的一小時平均值690+。
從這個案例最終通過修改cursor_sharing參數就解決了問題的現象上看,確實是這條沒有試用綁定變量的SQL導致了問題,不過這個問題為什么會發生,其原因是十分復雜的。上面我們分析的持續的高峰是導致問題的一個十分重要的原因之一,不過這還不是所有的原因。
仔細分析和CURSOR解析相關的指標,我們發現每秒的session cache命中數量只有1700左右,和6000多的解析相比,命中率也很低,換算下來大概只有28%左右。而除了這條出問題的SQL以外的其他解析較高的SQL語句的解析數量占比大約是33%,根據這個情況我們檢查了一下session_cached_cursors參數,發現這個參數使用了缺省的50。不過在這個案例里,加大這個參數能夠發揮的作用可能還是有限的,不過在某些其他的案例里,類似情況可能會因為這個參數的設置不合理而加重SQL 解析的負擔。
實際上這個看似并不復雜的案例里包含了很多復雜的內容,只有十分深入的去分析它,才能發現更深層次的問題。雖然說當時現場很快通過cursor_sharing解決了這個問題,但是如果沒有把其中的問題分析清楚,今后遇到類似的問題,我們就無法提前預警,此類問題稍微發生一些變化,我們就無法正確的去處置。因為此類問題的表象上十分類似,而實際上深層次的內容上存在極大的不同。
這也是故障自動化分析比較難做的主要原因,同樣是硬解析,為什么有的系統每秒數千次都不會出問題,而這個系統才700就出問題了呢?這和這臺服務器的配置、CPU使用率、SQL涉及的表的數量,是不是存在分區數量極多的分區表等等,以及和昨天這個案例類似的是否存在持續時間很長的,針對同一張表的高并發解析,這些因素都有關系。如果在分析的時候要考慮到這些因素,那么我們需要更為準確的采集到相關的數據,并進行指標化處理,并通過指標來反映出這些問題的因素,在分析算法中也需要覆蓋這些指標。
這種自動化分析能力只能在一次次的不盡如人意的分析中不斷地迭代優化,才能獲得更為準確的自動化分析工具。就像今天我們討論的這個案例,雖然說好像現在看,問題已經分析的差不多了,而且當時發現問題和解決問題也很及時。不過我感覺我們還是沒有抓住問題的最根本的那個點,因此我們還需要通過在用戶現場更廣泛的采集數據,從而找到更深層次的問題原因。只有不斷地從這樣的案例中去不斷地挖掘知識,我們的知識圖譜才能變得更有價值。
本文轉載自微信公眾號「白鱔的洞穴」,可以通過以下二維碼關注。轉載本文請聯系白鱔的洞穴公眾號。