













普通索引 PK 唯一性索引,用哪個好?
我們建索引的時候,有全文索引、主鍵索引、唯一性索引、普通索引等,前面兩個好理解好區分,大家都知道啥時候用,后面兩個該如何區分呢?唯一性索引和普通索引該如何選擇呢?今天我們就來聊聊這個話題。
1. 準備工作
假設我有如下表:
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`address` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`age` int(4) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `username` (`username`),
KEY `address` (`address`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
這表中有 10 萬條模擬數據,10 萬條模擬數據大家自行創建我就不啰嗦了。
看表結構,有一個 username 索引,這個索引是一個唯一性索引;還有一個 address 索引,這是一個普通索引。
2. 查詢
2.1 普通索引查詢
我們先來看看普通索引的查詢。
我們來做一個簡單的查詢:
select * from user where address='1';
根據我們前面的講解(索引下推,yyds!),我們來梳理下這里的查詢步驟:
- MySQL 的 server 層首先調用存儲引擎定位到第一個值為 1 的 address。
- 由于 address 是二級索引,二級索引的葉子結點中保存著主鍵值,所以還需要根據主鍵值去主鍵索引上找到完整的數據行,其實就是回表(什么是 MySQL 的“回表”?)。
- 存儲引擎將讀取到的數據行返回給 server 層。
- 由于 address 是普通索引,不是唯一性索引,所以 address 為 1 的記錄可能不止一條,所以還需在第一次查詢的基礎上,沿著葉子結點內部的單向鏈表繼續向后掃描,掃描到新的數據后,重復 2、3 步。
- 當掃到 address 不為 1 的記錄時,停止掃描。
上面是我們的分析,我們來看下執行計劃:
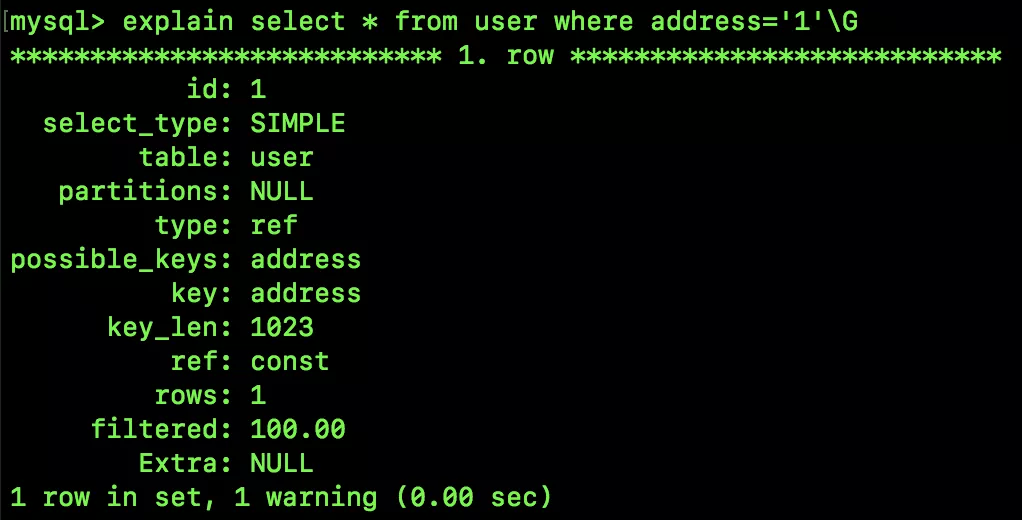
執行計劃中的 type 為 ref,就說明了我們的分析是沒問題的。
2.2 唯一性索引查詢
我們再來看看唯一性索引查詢。
先來看看一個 SQL:
select * from user where username='1';
對于唯一性索引來說,username 這一列的值是唯一的,所以在查詢的過程中,找到第一條username='1' 的記錄后,就不需要再找了,對比普通索引的查詢步驟,相當于少了第 4、5 步。
我們來看看查詢計劃:
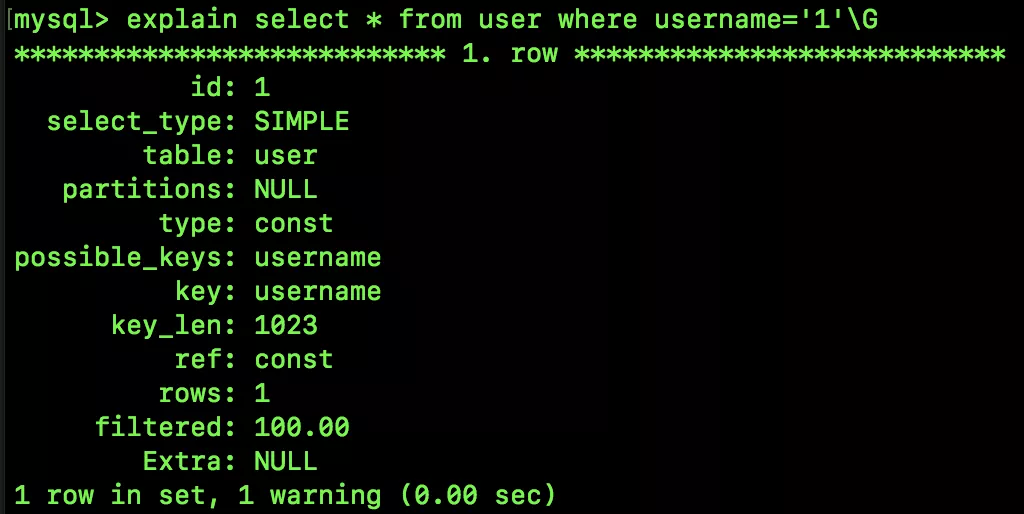
和前面普通索引的查詢計劃相比,這里的查詢計劃 type 為 const,也側面印證了我們的說法。
2.3 PK
那么從上面的描述中我們可以看出來,似乎唯一性索引在查詢的時候表現更優秀?真是情況到底如何,我們再來分析下。
首先,理論上來說,唯一性索引在查詢的時候確實更優秀一些,原因很簡單:唯一性索引找到滿足條件的記錄后就不需要再找了;而普通索引找到滿足條件的記錄后,還需要繼續向后查找,直到遇到不滿足條件的記錄(address 不為 1 的記錄)才停止搜索,這么看來,確實唯一性索引更勝一籌!那么這種差異很明顯嗎?老實說,這個優勢可以忽略不計!
為什么呢?
- 對于普通索引而言,雖然找到第一條記錄之后,還需要繼續找后面的,但是因為滿足條件的記錄是連續的,索引只需要順著記錄之間的單向鏈表繼續向后讀就行了,速度快。
- 由于 InnoDB 引擎讀數據的時候,不是一條一條的讀,而是一頁一頁的讀(默認每頁 16KB,在什么是 MySQL 的“回表”?一文中,我有大致介紹 16KB 的問題),所以,即使繼續向后讀,也是內存操作,速度很快。
- 也不排除個別情況,例如滿足條件的記錄剛好是在當前頁的最后一條,此時就需要加載新的一頁數據,但是這種概率比較小,可以忽略之。
綜上所述,唯一性索引和普通索引對搜索效率的影響可以忽略不計。
3 插入/修改
3.1 準備知識
3.1.1 buffer pool
有一個 buffer pool 需要大家了解。
小伙伴們知道,InnoDB 引擎存儲數據的時候,是以頁為單位的,每個數據頁的大小默認是 16KB,我們可以通過如下命令來查看頁的大小:
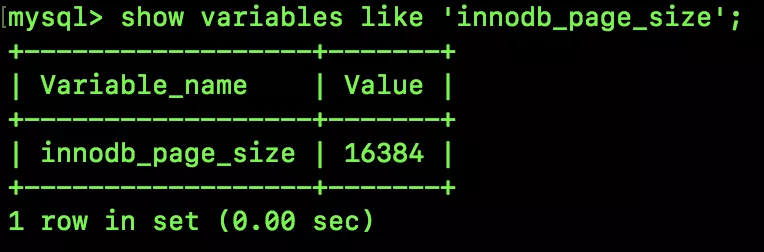
16384/1024=16
剛好是 16KB。
計算機在存儲數據的時候,最小存儲單元是扇區,一個扇區的大小是 512 字節,而文件系統(例如 XFS/EXT4)最小單元是塊,一個塊的大小是 4KB,也就是四個塊組成一個 InnoDB 中的頁。我們在 MySQL 中針對數據庫的增刪改查操作,都是操作數據頁,說白了,就是操作磁盤。
但是大家想想,如果每一次操作都操作磁盤,那么就會產生海量的磁盤 IO 操作,如果是傳統的機械硬盤,還會涉及到很多隨機 IO 操作,效率低的令人發指。這嚴重影響了 MySQL 的性能。
為了解決這一問題,MySQL 引入了 buffer pool,也就是我們常說的緩沖池。
buffer pool 的主要作用就是緩存索引和表數據,以避免每一次操作都要進行磁盤 IO,通過 buffer pool 可以提高數據的訪問速度。
通過如下命令可以查看 buffer pool 的默認大小:
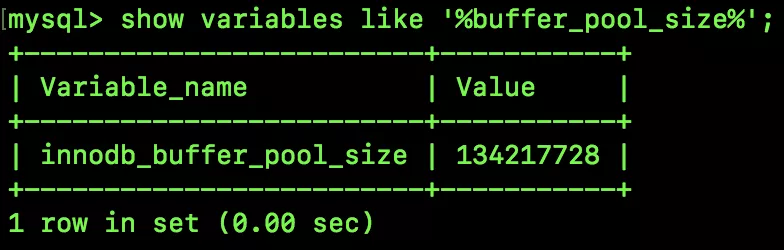
134217728/1024/1024=128
默認大小是 128MB,因為松哥這里的 MySQL 是安裝在 Docker 中,所以這個分配的小一些。一般來說,如果一個服務器只是運行了一個 MySQL 服務,我們可以設置 buffer pool 的大小為服務器內存大小的 75%~80%。
3.1.2 change buffer
還有一個 change buffer 需要大家了解。
前面我們說的 buffer pool 雖然提高了訪問速度,但是增刪改的效率并沒有因此提升,當涉及到增刪改的時候,還是需要磁盤 IO,那么效率一樣低的令人發指。
為了解決這個問題,MySQL 中引入了 change buffer。change buffer 以前并不叫這個名字,以前叫 insert buffer,即只針對 insert 操作有效,現在改名叫 change buffer 了,不僅僅針對 insert 有效,對 delete 和 update 操作也是有效的,change buffer 主要是對非唯一的索引有效,如果字段是唯一性索引,那么更新的時候要去檢查唯一性,依然無法避免磁盤 IO。
change buffer 就是說,當我們需要更改數據庫中的數據的時候,我們把更改記錄到內存中,等到將來數據被讀取的時候,再將內存中的數據 merge 到 buffer pool,此時 buffer pool 中的數據和磁盤中的數據就會有差異,有差異的數據我們稱之為臟頁,在滿足條件的時候(redo log 寫滿了、內存寫滿了、其他空閑時候),InnoDB 會把臟頁刷新回磁盤。這種方式可以有效降低寫操作的磁盤 IO,提升數據庫的性能。
通過如下命令我們可以查看 change buffer 的大小以及哪些操作會涉及到 change buffer:
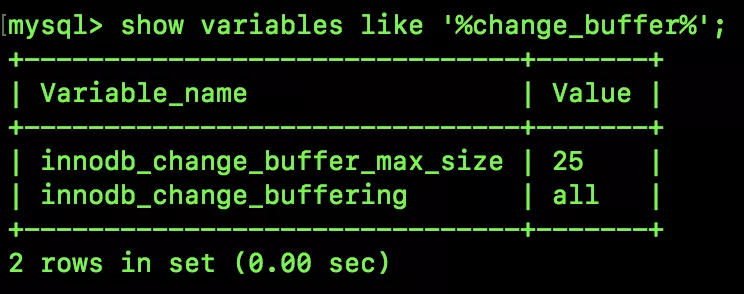
- innodb_change_buffer_max_size:這個配置表示 change buffer 的大小占整個緩沖池的比例,默認值是 25%,最大值是 50%。
- innodb_change_buffering:這個操作表示哪些寫操作會用到 change buffer,默認的 all 表示所有寫操作,我們也可以自己設置為none/inserts/deletes/changes/purges 等。
不過 change buffer 和 buffer pool 都涉及到內存操作,數據不能持久化,那么,當存在臟頁的時候,MySQL 如果突然掛了,就有可能造成數據丟失(因為內存中的數據還沒寫到磁盤上),但是我們在實際使用 MySQL 的時候,其實并不會有這個問題,那么問題是怎么解決的?那就得靠 redo log 了,這個松哥以后再寫文章和大家介紹 redo log。
3.2 PK
看了上面 change buffer 的介紹,大家應該已經明白了:
- 對于非唯一性索引,插入時候直接將數據存儲到 change buffer 中就行了,這是一個內存操作,很快。
- 對于唯一性索引,插入的時候,必須要將數據頁讀入到內存中(這一步涉及到大量的隨機 IO,效率低),檢查沒有沖突,然后插入。
所以,很明顯,在插入的時候,非唯一性索引更有優勢。
4. 小結
那么對于一個需要全局唯一的字段,到底是用普通索引還是唯一性索引呢?這個我覺得很難給大家一個放之四海而皆準的建議,因為數據庫優化很多時候不是絕對的,要結合自己的實際業務來,所以,無論何時何地,先滿足業務需求,在此基礎上,再去討論數據庫優化。
如果你能從業務上確保該字段唯一,那么可以使用普通索引,這樣可以提高插入/更新速度。
然而,根據墨菲定律,你要是不用唯一索引,該字段中將來大概率會出現臟值,所以你也要考慮業務上對于臟值的容忍程度。





















