JVM 垃圾回收算法和 CMS 垃圾回收器
本文核心主要是講述:JVM 中的幾種垃圾回收算法理論,以及多種垃圾收集器,并且詳細(xì)參數(shù) CMS 垃圾收集器的實(shí)現(xiàn)、優(yōu)缺點(diǎn)等,最后也會解釋一下三色標(biāo)記法與讀寫屏障。
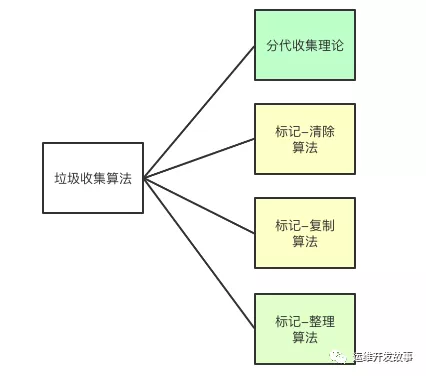
垃圾收集算法
收集算法.png
分代收集理論 (Generational Collection)
當(dāng)前商業(yè)虛擬機(jī)的垃圾收集都是采用 "分代收集" (Generational Collecting)算法,根據(jù)對象不同的存活周期將內(nèi)存劃分為多塊
一般是把 Java 堆分作新生代和老年代, 這樣就可以根據(jù)各個(gè)年代的特點(diǎn)采用最適當(dāng)?shù)氖占惴ǎ┤缧律看蜧C都有大批量對象死去,只有少量存活, 那就選用復(fù)制算法只需要付出少量存活對象的復(fù)制成本就可以完成收集。
綜合前面幾種GC算法的優(yōu)缺點(diǎn),針對不同生命周期的對象采用不同的GC算法
- 新生代采用 Copying
- 老年代采用 Mark-Sweep or Mark-Compact
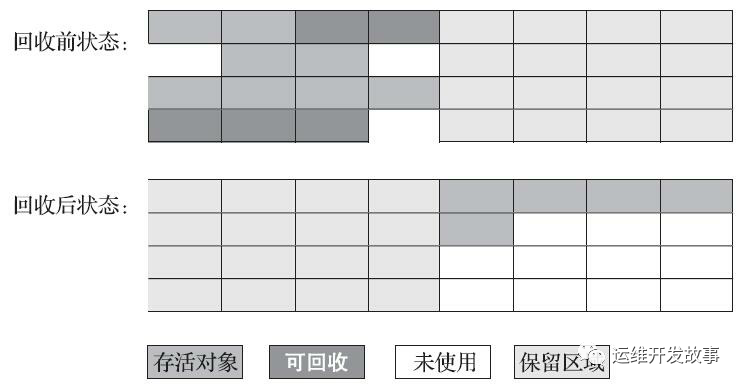
標(biāo)記-復(fù)制算法 (Copying)
為了解決效率問題,“復(fù)制” 收集算法出現(xiàn)了。他可以將內(nèi)存分為大小相同的兩塊,每次使用其中一塊。當(dāng)這塊的內(nèi)存使用完成后,就將存活的對象復(fù)制到另外一邊去,然后再把使用的空間一次清理掉。這樣就使每次的內(nèi)存回收都是對內(nèi)存區(qū)間的一半進(jìn)行回收。
 標(biāo)記復(fù)制算法.png
標(biāo)記復(fù)制算法.png
標(biāo)記-清除算法(Mark-Sweep)
算法分為 "標(biāo)記" 和 "清除" 兩階段,首先標(biāo)記出所有需要回收的對象,然后回收所有需要回收的對象
缺點(diǎn)
- 效率問題, 標(biāo)記和清理兩個(gè)過程效率都不高
- 空間問題, 標(biāo)記清理之后會產(chǎn)生大量不連續(xù)的內(nèi)存碎片,空間碎片太多可能會導(dǎo)致后續(xù)使用中無法找到足夠的連續(xù)內(nèi)存而提前觸發(fā)一次的垃圾收集動作。
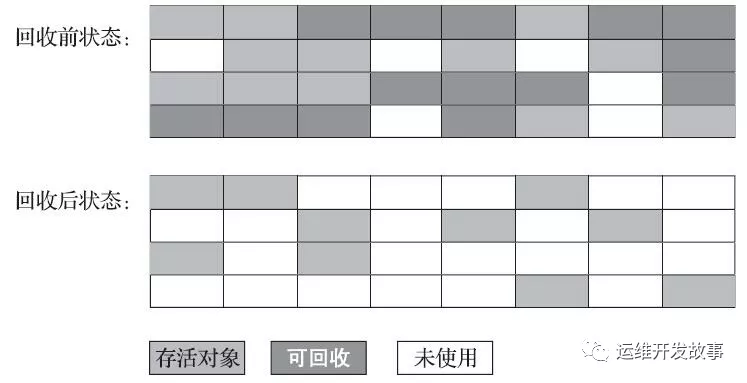
 標(biāo)記清除算法.png
標(biāo)記清除算法.png
標(biāo)記-整理算法 (Mark-Compact)
- 標(biāo)記過程仍然一樣,但后續(xù)步驟不是進(jìn)行直接清理,而是令所有存活的對象一端移動,然后直接清理掉這端邊界以外的內(nèi)存。
- 沒有內(nèi)存碎片
- 對 Mark-Sweep(標(biāo)記清除) 耗費(fèi)更多的時(shí)間進(jìn)行 compact(整理)
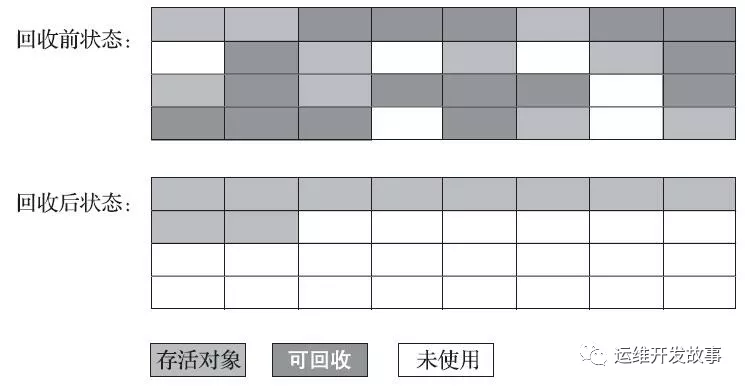
標(biāo)記整理算法.png
垃圾收集器
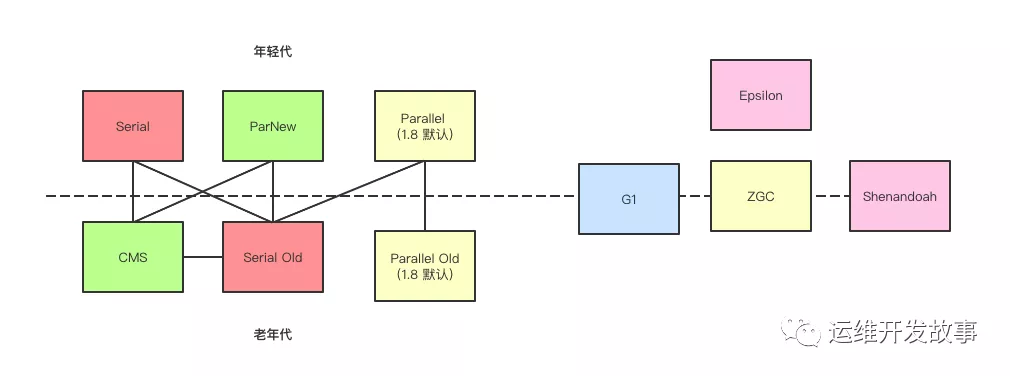
垃圾收集器.png
如果說垃圾收集算法是內(nèi)存回收的方法理論,那么垃圾收集器就是內(nèi)存回收的具體實(shí)現(xiàn)。
雖然我們對各收集器進(jìn)行比較,但并非為了挑選出一個(gè)最好的收集器,因?yàn)橹钡浆F(xiàn)在為止還沒有最好的垃圾收集器出現(xiàn), 更加沒有萬能的垃圾收集器,我們能做的就是根據(jù)具體應(yīng)用場景選擇適合自己的收集器,試想一下:如果有一個(gè)完美無暇的垃圾收集器適用于所有場景,那么我們 Java 虛擬機(jī)就不會去實(shí)現(xiàn)那么多的垃圾收集器了。
查詢當(dāng)前使用的 JVM 信息查詢命令 java -XX:+PrintCommandLineFlags -version
? ~ java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=134217728 -XX:MaxHeapSize=2147483648 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
java version "1.8.0_281"
Java(TM) SE Runtime Environment (build 1.8.0_281-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.281-b09, mixed mode)
Serial 收集器
單線程收集器,收集時(shí)會暫停所有工作線程(Stop The World, 簡稱 STW),使用復(fù)制收集算法,虛擬機(jī)運(yùn)行在 Client 模式的默認(rèn)新生代收集器
- 最早的收集器,單線程進(jìn)行GC
- New 和 Old Generation 都可以使用
- 在新生代, 采用復(fù)制算法; 在老年代,采用Mark-Compact算法
- 因?yàn)槭褂脝尉€程GC,沒有多線程切換的額外開銷,簡單實(shí)用。
- Hotspot Client 模式缺省的收集器
- Safepoint 安全點(diǎn)
JVM 參數(shù):-XX:+UseSerialGC -XX:+UseSerialOldGC
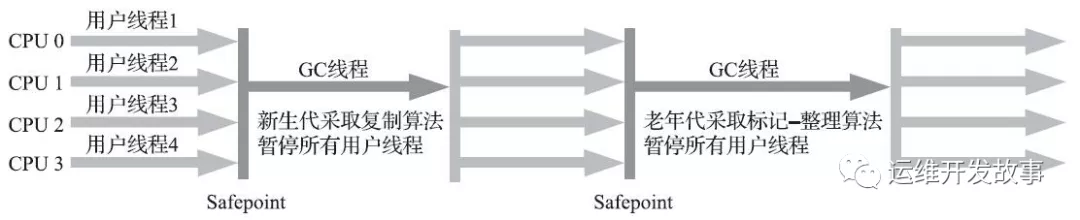
 Serial收集器.png
Serial收集器.png
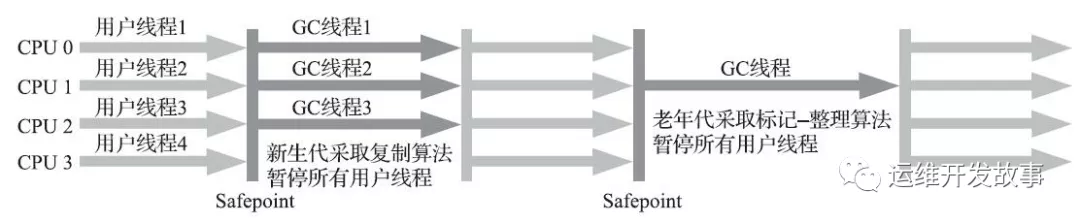
PerNew 收集器
ParNew 收集器就是 Serial 的多線程版本,除了使用多個(gè)收集線程外,其余行為包括算法、STW、對象分配規(guī)則、回收策略等都與Serial 收集器一模一樣
對應(yīng)的這種收集器是虛擬機(jī)運(yùn)行在 Server 模式的默認(rèn)新生代收集器,在單 CPU 的環(huán)境下,ParNew 收集器的效果并不會比Serial收集器有更好的效果
- Serial 收集器的在新生代的多線程版本
- 使用復(fù)制算法(因?yàn)獒槍π律?
- 只有在多CPU的環(huán)境下,效率才會比Serial收集器高
- 可以通過-XX:ParallelGCThreads來控制GC線程數(shù)的多少。需要結(jié)合CPU的個(gè)數(shù)
- Server模式下新生代的缺省收集器。
JVM 參數(shù):-XX:UseParNewGC
 ParNew收集器.png
ParNew收集器.png
Parallel Scavenge 收集器(1.8 默認(rèn))
- Parallel Scavenge 收集器也是一個(gè)多線程收集器,也是使用復(fù)制算法,但它的對象分配規(guī)則與收集策略都與ParNew收集器有所不同,它是以吞吐量最大化(即GC時(shí)間占總運(yùn)行時(shí)間最小)為目標(biāo)的收集器實(shí)現(xiàn),它允許較長的STW換取總吞吐量最大化。
- 默認(rèn)收集器線程數(shù)跟 CPU 核數(shù)相同,也可以通過參數(shù)指定
- JDK 1.8 默認(rèn)垃圾收集器
- JVM 參數(shù):`-XX:UseParallelGC(年輕代) -XX:UseParallelOldGC(老年代)
Serial Old 收集器
Serial Old收集器是單線程收集器,使用標(biāo)記-整理算法,是老年代的收集器


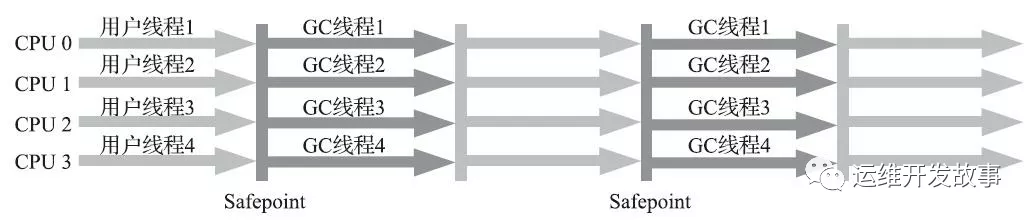
Parallel Old 收集器(1.8 默認(rèn))
老年代版本吞吐量優(yōu)先的收集器,使用多線程和標(biāo)記-整理算法,JVM 1.6提供,在此之前,新生代使用了PS收集器的話,老年代除Serial Old外別無選擇, 因?yàn)镻S無法與CMS收集器配合工作。
- Parallel Scavenge 在老年代的實(shí)現(xiàn)
- 在 JVM 1.6 才出現(xiàn) Parallel Old
- 采用多線程,Mark-Compact 算法
- 更注重吞吐量
- Parallel Scavenge + Parallel Old = 高吞吐量,但是GC停頓可能不理想
 Parallel Old收集器.png
Parallel Old收集器.png
CMS (Concurrent Mark Sweep) 收集器
CMS 是一種以最短停頓時(shí)間為目標(biāo)的收集器,使用CMS并不能達(dá)到GC效率最高(總體GC時(shí)間最小),但它能盡可能降低GC時(shí)服務(wù)的停頓時(shí)間, CMS收集器使用的是標(biāo)記-清除算法
 CMS 收集器.png
CMS 收集器.png
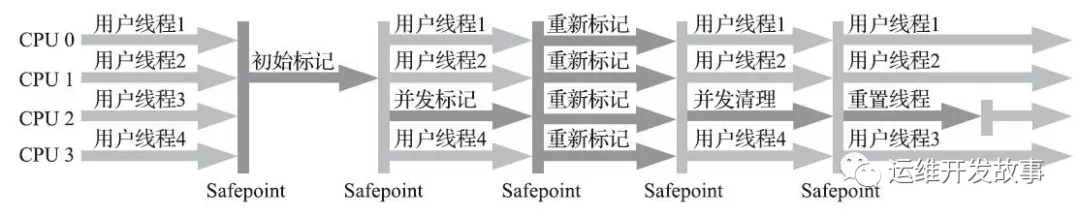
CMS 垃圾收集器步驟
CMS 收集器是基于標(biāo)記-清除算法實(shí)現(xiàn)的,它的運(yùn)作過程相對于前面幾種收集器來說要更復(fù)雜一些,整個(gè)過程分為四個(gè)步驟,包括:
1)初始標(biāo)記(CMS initial mark) 暫停所有的其他線程(STW)。記錄下 GC ROOT 直接引用對象,速度很快。
2)并發(fā)標(biāo)記(CMS concurrent mark) 并發(fā)標(biāo)記階段就是從 GC ROOT 行的直接關(guān)聯(lián)對象開始遍歷整個(gè)對象的過程,這個(gè)過程耗時(shí)比較長但是不需要停頓用戶線程,可以與垃圾收集器一起并發(fā)運(yùn)行。因此用戶程序繼續(xù)運(yùn)行,可能會導(dǎo)致已經(jīng)標(biāo)記過的對象狀態(tài)發(fā)生變化。
3)重新標(biāo)記(CMS remark) 重新標(biāo)記階段就是為了修正并發(fā)標(biāo)記期間,因?yàn)橛脩舫绦蚶^續(xù)運(yùn)行而導(dǎo)致標(biāo)記產(chǎn)生變動,的那一部分對象的標(biāo)記記錄。這個(gè)階段的停頓時(shí)間一般比初始標(biāo)記階段的時(shí)間稍長,遠(yuǎn)遠(yuǎn)比并發(fā)標(biāo)記階段時(shí)間短。主要是用到三色標(biāo)記里的增量更新算法
4)**并發(fā)清除(CMS concurrent sweep)**開啟用戶線程,同時(shí) GC 線程開始對未標(biāo)記的區(qū)域做清掃,這個(gè)階段如果有新增對象會被標(biāo)記為黑色不做任何處理(見下面三色標(biāo)記算法詳解)。
CMS 垃圾收集器優(yōu)缺點(diǎn)
從它的名字可以看出他是一款優(yōu)秀的垃圾收集器,主要優(yōu)點(diǎn):并發(fā)收集、低停頓 。但是它有以下幾個(gè)明顯的缺點(diǎn):
- 對于 CPU 資源敏感(會和服務(wù)搶資源);
- 無法處理 浮動垃圾(在并發(fā)標(biāo)記和并發(fā)清理階段又產(chǎn)生垃圾,這種浮動垃圾只能等到下次 gc 的時(shí)候在進(jìn)行清理了)
- 它使用的收集算法 “標(biāo)記-清除” 算法 會導(dǎo)致結(jié)束時(shí)候又大量空間碎片產(chǎn)生,當(dāng)然通過參數(shù) -XX:UseCMSCompactAtFullCollection 可以讓 JVM 在執(zhí)行標(biāo)記清除完成后再做整理。
- 執(zhí)行過程中的不確定性,會存在一次垃圾回收還沒有執(zhí)行完成,然后垃圾回收又被觸發(fā)的情況,特別是在并發(fā)標(biāo)記和并發(fā)清理階段出現(xiàn),一邊回收,系統(tǒng)一邊運(yùn)行,也許沒回收完成就再次觸發(fā) Full GC, 這就是 “concurrent mode failure” 此時(shí)會進(jìn)入 stop the world . 用 serial old 垃圾器來回收。
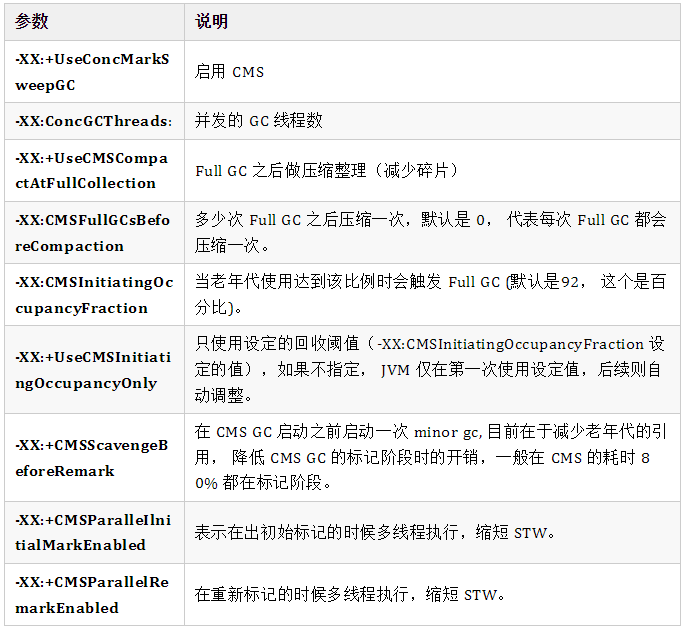
CMS 垃圾收集器的參數(shù)
三色標(biāo)記和讀寫屏障
三色標(biāo)記算法
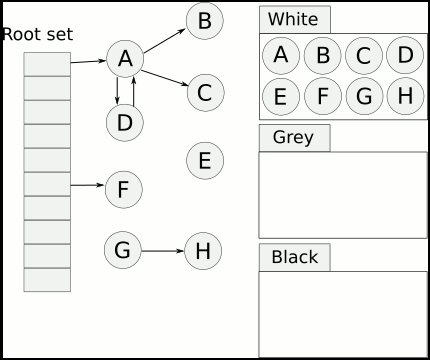
提到并發(fā)標(biāo)記,我們不得不了解并發(fā)標(biāo)記的三色標(biāo)記算法。它是描述追蹤式回收器的一種有效的方法,利用它可以推演回收器的正確性。
因?yàn)樵诓l(fā)標(biāo)記期間應(yīng)用線程還在繼續(xù)跑,對象間的引用可能發(fā)生變化,**多標(biāo) **和 漏標(biāo) 的情況還可能發(fā)生。
 三色標(biāo)記法.gif
三色標(biāo)記法.gif
我們將對象分為三種類型:
- 黑色:根對象,或者該對象與它的子對象都被掃描過(對象被標(biāo)記了,且它的所有field也被標(biāo)記完了)
- 灰色:對象本身被掃描,還沒有掃描完該對象中的子對象(它的field還沒有被標(biāo)記或標(biāo)記完)
- 白色:未被掃描對象,掃描完成所有對象之后,最終為白色的為不可達(dá)對象,即垃圾對象(對象沒有被標(biāo)記到)
三色標(biāo)記過程
- 第一步,三色標(biāo)記算法,如果將根對象設(shè)置為黑色,那么下級節(jié)點(diǎn)的為灰色,再下面的的為白色
- 第二步,灰色掃描完畢后,那么剩下的白色變?yōu)榛疑?/li>
- 第三步,灰色掃描完畢后,那么全部被標(biāo)記為黑色,不可達(dá)的還是為白色
三色標(biāo)記算法的對象丟失
但是如果在標(biāo)記過程中,應(yīng)用程序也進(jìn)行,那么對象的指針就有可能改變。這樣的話,我們就會遇到一個(gè)問題:對象丟失。
例子:
- A.c = C
- B.c = null
- 第一步,初始 Root(黑)-> A(黑) Root(黑)-> B(灰)-> C(白)
- 第二步,在當(dāng)前場景下執(zhí)行如下操作
Root(黑)-> A(黑)-> C(白) Root(黑)-> B(黑)
第三步,如果內(nèi)存回收的時(shí)候,就會將 C 回收掉,會導(dǎo)致 C 對象丟失。
SATB 原始快照(Snapshot-At-The-Beginning)
- SATB是維持并發(fā)GC的一種手段。G1并發(fā)的基礎(chǔ)就是SATB。SATB可以理解成在GC開始之前對堆內(nèi)存里的對象做一次快照,此時(shí)活的對象就認(rèn)為是活的,從而形成一個(gè)對象圖
- 在GC收集的時(shí)候,新生代的對象也認(rèn)為是活的對象,除此之外其他不可達(dá)的對象也認(rèn)為是垃圾對象。
- 如何找到在GC過程分配的對象呢?每個(gè)region記錄著兩個(gè)top-at-mark-start(TAMS) 指針,分別為prevTAMS 和nextTAMS。在TAMS以上的獨(dú)享就是新分配的,因而被視為隱式marked
- 通過這種方式我們就找到了再GC過程中新分配的對象,并把這些對象認(rèn)為是活的對象。
- 解決了對象在GC過程中分配的問題,呢么GC過程中引用頻繁變化的問題是怎么解決的呢?
- G1給出的解決辦法是通過Write Barrier. Write Barrier 就是堆引用字段進(jìn)行賦值做了額外處理。通過Write Barrier就可以了解到哪些引用對象發(fā)生了什么樣的變化
- mark 的過程就是遍歷heap標(biāo)記live object的過程,采用的三色標(biāo)記算法,這三種顏色為white(表示還未訪問到)、gray(訪問到但是它用到的引用還誒有完全掃描)、black (訪問到而且其用到的引用完全掃描完)
- 整個(gè)三色標(biāo)記算法就是從GC Roots出發(fā)遍歷heap,針對可達(dá)對象先標(biāo)記white為gray, 然后再標(biāo)記gray為black; 遍歷完成之后所有可達(dá)對象都是black的,所有white 都是可以回收的。
- SATB僅僅對于在marking開始階段進(jìn)行"snapshot"(marked all reachable at mark start), 但是concurrent 的時(shí)候并發(fā)修改可能造成對象漏標(biāo)記
為什 G1 采用 STAB?CMS 使用增量更新?
我的理解:STAB 相對增量更新效率會很高(當(dāng)然 STAB 可能造成更多的浮動垃圾),因?yàn)椴恍枰匦聵?biāo)記再次深度掃描被刪除引用對象,而 CMS 對增量引用的根對象會做深度掃描, G1 因?yàn)楹芏鄬ο蠖际俏挥诓煌?region ,CMS 是一塊老年代區(qū)域,重新深度掃描對象的話 G1 的代價(jià)會比 CMS 高, 所以 G1 選擇 STAB 不深度掃描對象,只是簡單標(biāo)記, 等到下一輪 GC 再深度掃描。
寫屏障(Write Barrier)
void oop_field_store(oop* field, oop new_value) {
*field = new_value; // 賦值操作
}所謂的寫屏障,其實(shí)就是指在賦值操作前后,加入一些處理(可以參考AOP的概念):
void oop_field_store(oop* field, oop new_value) {
pre_write_barrier(field); // 寫屏障-寫前操作
*field = new_value;
post_write_barrier(field, value); // 寫屏障-寫后操作
}寫屏障和SATB
當(dāng)對象E的成員變量的引用發(fā)生變化時(shí)(objE.fieldG = null;),我們可以利用寫屏障,將E原來成員變量的引用對象G記錄下來:
void pre_write_barrier(oop* field) {
oop old_value = *field; // 獲取舊值
remark_set.add(old_value); // 記錄 原來的引用對象
}這種做法的思路是:嘗試保留開始時(shí)的對象圖,即原始快照(Snapshot At The Beginning,SATB),當(dāng)某個(gè)時(shí)刻 的GC Roots確定=后,當(dāng)時(shí)的對象圖就已經(jīng)確定了。比如 當(dāng)時(shí) D是引用著G的,那后續(xù)的標(biāo)記也應(yīng)該是按照這個(gè)時(shí)刻的對象圖走(D引用著G)。如果期間發(fā)生變化,則可以記錄起來,保證標(biāo)記依然按照原本的視圖來。
值得一提的是,掃描所有GC Roots 這個(gè)操作(即初始標(biāo)記)通常是需要STW的,否則有可能永遠(yuǎn)都掃不完,因?yàn)椴l(fā)期間可能增加新的GC Roots。
一點(diǎn)小優(yōu)化:如果不是處于垃圾回收的并發(fā)標(biāo)記階段,或者已經(jīng)被標(biāo)記過了,其實(shí)是沒必要再記錄了,所以可以加個(gè)簡單的判斷:
void pre_write_barrier(oop* field) {
// 處于GC并發(fā)標(biāo)記階段 且 該對象沒有被標(biāo)記(訪問)過
if($gc_phase == GC_CONCURRENT_MARK && !isMarkd(field)) {
oop old_value = *field; // 獲取舊值
remark_set.add(old_value); // 記錄 原來的引用對象
}
}寫屏障和增量更新
當(dāng)對象D的成員變量的引用發(fā)生變化時(shí)(objD.fieldG = G;),我們可以利用寫屏障,將D新的成員變量引用對象G記錄下來:
void post_write_barrier(oop* field, oop new_value) {
if($gc_phase == GC_CONCURRENT_MARK && !isMarkd(field)) {
remark_set.add(new_value); // 記錄新引用的對象
}
}這種做法的思路是:不要求保留原始快照,而是針對新增的引用,將其記錄下來等待遍歷,即增量更新(Incremental Update)
讀屏障
oop oop_field_load(oop* field) {
pre_load_barrier(field); // 讀屏障-讀取前操作
return *field;
}讀屏障是直接針對第一步:var G = objE.fieldG;,當(dāng)讀取成員變量時(shí),一律記錄下來:
void pre_load_barrier(oop* field, oop old_value) {
if($gc_phase == GC_CONCURRENT_MARK && !isMarkd(field)) {
oop old_value = *field;
remark_set.add(old_value); // 記錄讀取到的對象
}
}現(xiàn)代追蹤式(可達(dá)性分析)的垃圾回收器幾乎都借鑒了三色標(biāo)記的算法思想,盡管實(shí)現(xiàn)的方式不盡相同:比如白色/黑色集合一般都不會出現(xiàn)(但是有其他體現(xiàn)顏色的地方)、灰色集合可以通過棧/隊(duì)列/緩存日志等方式進(jìn)行實(shí)現(xiàn)、遍歷方式可以是廣度/深度遍歷等等。
對于讀寫屏障,以Java HotSpot VM為例,其并發(fā)標(biāo)記時(shí)對漏標(biāo)的處理方案如下:
- CMS:寫屏障 + 增量更新
- G1:寫屏障 + SATB
- ZGC:讀屏障
漏標(biāo)-讀寫屏障
漏標(biāo)會導(dǎo)致被引用的對象被當(dāng)成垃圾誤刪除,這個(gè)是嚴(yán)重的 BUG ,有兩種處理方案:增量更新(Incremental Update)和原始快照(Snapshot At The Beginning, STAB)
增量更新 就是當(dāng)黑色對象插入新的指向白色對象的引用記錄下來,等并發(fā)掃描結(jié)束之后,再將這些記錄過的引用關(guān)系中的黑色對象為根,重新掃描一次。這個(gè)可以簡化理解為,黑色對象一旦新插入了指向白色對象的引用之后,它就變回灰色對象了。
原始快照 就當(dāng)灰色對象要刪除指向白色的對象,將白色對象直接標(biāo)記為黑色(目的就是讓這種對象在本輪 GC 清理中能夠存活下來,等待下一輪 GC 的時(shí)候重新掃描, 這個(gè)對象也可能就是浮動垃圾)
以上無論是引用關(guān)系記錄的插入還是刪除,虛擬機(jī)的記錄操作都是通過 寫屏障 實(shí)現(xiàn)的。
記憶集和卡表 (**Remember Set **& Cardtable)
在新生代做 GC Roots 可達(dá)性掃描過程中可能會碰到跨代引用的對象 ,這種如果又去對老年代再去掃描效率太低了。為此,在新生代可以引入記錄集 (Remember Set) 的數(shù)據(jù)結(jié)枃 (記錄從非收集區(qū)到收集區(qū)的指針集合) , 避免把整個(gè)老年代加入 GC Roots掃描范圍。事實(shí)上并不只是新生代、老年代之間才有跨代引用的問題,所有涉及部分區(qū)域收集( Partial GC)行為的垃圾收集器,典型的如G1、ZC和 Shenandoah 收集器,都會面臨相同的問題。
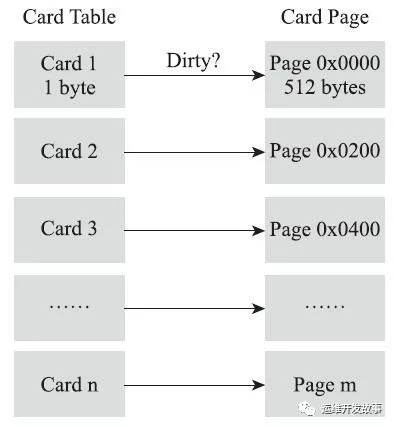
垃圾收集場景中, 收集器只需通過記憶集判斷岀某一塊非收集區(qū)域是否存在指向收集區(qū)域的指針即可, 無需了解跨代引用指針的全部細(xì)節(jié)hotspot使用一種叫做 "卡表"( Cardtable )的方式實(shí)現(xiàn)記憶集,也是目前最常用的一種方式。關(guān)于卡表與記憶集的關(guān)系,可以類比為Java語言中 Hashmap與Map的關(guān)系卡表是使用一個(gè)字節(jié)數(shù)組實(shí)現(xiàn): CARD TABLE[],每個(gè)元素對應(yīng)著其標(biāo)識的內(nèi)存區(qū)域一塊特定大小的內(nèi)存塊,稱為“卡頁”。hotspot使用的卡頁是2^9大小,即512字節(jié)
卡表與卡頁.png
一個(gè)卡頁中可以包含多個(gè)對象,只要有一個(gè)對象的字段存在跨代指針,其對應(yīng)的卡表的元素標(biāo)識就變成 1 ,表示該元素變臟, 否則為 0 , GC 時(shí), 只要篩選本收集區(qū)的卡表中變臟的元素加入 GCRoots 里。
卡表的維護(hù)
卡表變臟上面已經(jīng)說到了, 但是需要注意的是如何讓卡表變臟, 即發(fā)生了引用字段賦值時(shí),如何更新卡表對標(biāo)識為 Hotspot 使用 寫屏障 維護(hù)卡表狀態(tài)
參考資料
- 《深入理解 Java 虛擬機(jī)第三版》 周志明
- 三色標(biāo)記法與讀寫屏障 路過的豬