用 NumPy 在 Python 中處理數字
這篇文章討論了安裝 NumPy,然后創建、讀取和排序 NumPy 數組。

NumPy(即 Numerical Python)是一個庫,它使得在 Python 中對線性數列和矩陣進行統計和集合操作變得容易。我在 Python 數據類型的筆記中介紹過,它比 Python 的列表快幾個數量級。NumPy 在數據分析和科學計算中使用得相當頻繁。
我將介紹安裝 NumPy,然后創建、讀取和排序 NumPy 數組。NumPy 數組也被稱為 ndarray,即 N 維數組的縮寫。
安裝 NumPy
使用 pip 安裝 NumPy 包非常簡單,可以像安裝其他軟件包一樣進行安裝:
pip install numpy
安裝了 NumPy 包后,只需將其導入你的 Python 文件中:
import numpy as np
將 numpy 以 np 之名導入是一個標準的慣例,但你可以不使用 np,而是使用你想要的任何其他別名。
為什么使用 NumPy? 因為它比 Python 列表要快好幾個數量級
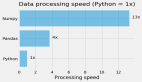
當涉及到處理大量的數值時,NumPy 比普通的 Python 列表快幾個數量級。為了看看它到底有多快,我首先測量在普通 Python 列表上進行 min() 和 max() 操作的時間。
我將首先創建一個具有 999,999,999 項的 Python 列表:
>>> my_list = range(1, 1000000000)>>> len(my_list)999999999
現在我將測量在這個列表中找到最小值的時間:
>>> start = time.time()>>> min(my_list)1>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))Time elapsed in milliseconds: 27007.00879096985
這花了大約 27,007 毫秒,也就是大約 27 秒。這是個很長的時間。現在我試著找出尋找最大值的時間:
>>> start = time.time()>>> max(my_list)999999999>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))Time elapsed in milliseconds: 28111.071348190308
這花了大約 28,111 毫秒,也就是大約 28 秒。
現在我試試用 NumPy 找到最小值和最大值的時間:
>>> my_list = np.arange(1, 1000000000)>>> len(my_list)999999999>>> start = time.time()>>> my_list.min()1>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))Time elapsed in milliseconds: 1151.1778831481934>>>>>> start = time.time()>>> my_list.max()999999999>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))Time elapsed in milliseconds: 1114.8970127105713
找到最小值花了大約 1151 毫秒,找到最大值 1114 毫秒。這大約是 1 秒。
正如你所看到的,使用 NumPy 可以將尋找一個大約有 10 億個值的列表的最小值和最大值的時間 從大約 28 秒減少到 1 秒。這就是 NumPy 的強大之處。
使用 Python 列表創建 ndarray
有幾種方法可以在 NumPy 中創建 ndarray。
你可以通過使用元素列表來創建一個 ndarray:
>>> my_ndarray = np.array([1, 2, 3, 4, 5])>>> print(my_ndarray)[1 2 3 4 5]
有了上面的 ndarray 定義,我將檢查幾件事。首先,上面定義的變量的類型是 numpy.ndarray。這是所有 NumPy ndarray 的類型:
>>> type(my_ndarray)<class 'numpy.ndarray'>
這里要注意的另一件事是 “形狀”。ndarray 的形狀是 ndarray 的每個維度的長度。你可以看到,my_ndarray 的形狀是 (5,)。這意味著 my_ndarray 包含一個有 5 個元素的維度(軸)。
>>> np.shape(my_ndarray)(5,)
數組中的維數被稱為它的 “秩”。所以上面的 ndarray 的秩是 1。
我將定義另一個 ndarray my_ndarray2 作為一個多維 ndarray。那么它的形狀會是什么呢?請看下面:
>>> my_ndarray2 = np.array([(1, 2, 3), (4, 5, 6)])>>> np.shape(my_ndarray2)(2, 3)
這是一個秩為 2 的 ndarray。另一個要檢查的屬性是 dtype,也就是數據類型。檢查我們的 ndarray 的 dtype 可以得到以下結果:
>>> my_ndarray.dtypedtype('int64')
int64 意味著我們的 ndarray 是由 64 位整數組成的。NumPy 不能創建混合類型的 ndarray,必須只包含一種類型的元素。如果你定義了一個包含混合元素類型的 ndarray,NumPy 會自動將所有的元素類型轉換為可以包含所有元素的最高元素類型。
例如,創建一個 int 和 float 的混合序列將創建一個 float64 的 ndarray:
>>> my_ndarray2 = np.array([1, 2.0, 3])>>> print(my_ndarray2)[1. 2. 3.]>>> my_ndarray2.dtypedtype('float64')
另外,將其中一個元素設置為 string 將創建 dtype 等于 <U21 的字符串 ndarray,意味著我們的 ndarray 包含 unicode 字符串:
>>> my_ndarray2 = np.array([1, '2', 3])>>> print(my_ndarray2)['1' '2' '3']>>> my_ndarray2.dtypedtype('<U21')
size 屬性將顯示我們的 ndarray 中存在的元素總數:
>>> my_ndarray = np.array([1, 2, 3, 4, 5])>>> my_ndarray.size5
使用 NumPy 方法創建 ndarray
如果你不想直接使用列表來創建 ndarray,還有幾種可以用來創建它的 NumPy 方法。
你可以使用 np.zeros() 來創建一個填滿 0 的 ndarray。它需要一個“形狀”作為參數,這是一個包含行數和列數的列表。它還可以接受一個可選的 dtype 參數,這是 ndarray 的數據類型:
>>> my_ndarray = np.zeros([2,3], dtype=int)>>> print(my_ndarray)[[0 0 0][0 0 0]]
你可以使用 np. ones() 來創建一個填滿 1 的 ndarray:
>>> my_ndarray = np.ones([2,3], dtype=int)>>> print(my_ndarray)[[1 1 1][1 1 1]]
你可以使用 np.full() 來給 ndarray 填充一個特定的值:
>>> my_ndarray = np.full([2,3], 10, dtype=int)>>> print(my_ndarray)[[10 10 10][10 10 10]]
你可以使用 np.eye() 來創建一個單位矩陣 / ndarray,這是一個沿主對角線都是 1 的正方形矩陣。正方形矩陣是一個行數和列數相同的矩陣:
>>> my_ndarray = np.eye(3, dtype=int)>>> print(my_ndarray)[[1 0 0][0 1 0][0 0 1]]
你可以使用 np.diag() 來創建一個沿對角線有指定數值的矩陣,而在矩陣的其他部分為 0:
>>> my_ndarray = np.diag([10, 20, 30, 40, 50])>>> print(my_ndarray)[[10 0 0 0 0][ 0 20 0 0 0][ 0 0 30 0 0][ 0 0 0 40 0][ 0 0 0 0 50]]
你可以使用 np.range() 來創建一個具有特定數值范圍的 ndarray。它是通過指定一個整數的開始和結束(不包括)范圍以及一個步長來創建的:
>>> my_ndarray = np.arange(1, 20, 3)>>> print(my_ndarray)[ 1 4 7 10 13 16 19]
讀取 ndarray
ndarray 的值可以使用索引、分片或布爾索引來讀取。
使用索引讀取 ndarray 的值
在索引中,你可以使用 ndarray 的元素的整數索引來讀取數值,就像你讀取 Python 列表一樣。就像 Python 列表一樣,索引從 0 開始。
例如,在定義如下的 ndarray 中:
>>> my_ndarray = np.arange(1, 20, 3)
第四個值將是 my_ndarray[3],即 10。最后一個值是 my_ndarray[-1],即 19:
>>> my_ndarray = np.arange(1, 20, 3)>>> print(my_ndarray[0])1>>> print(my_ndarray[3])10>>> print(my_ndarray[-1])19>>> print(my_ndarray[5])16>>> print(my_ndarray[6])19
使用分片讀取 ndarray
你也可以使用分片來讀取 ndarray 的塊。分片的工作方式是用冒號(:)操作符指定一個開始索引和一個結束索引。然后,Python 將獲取該開始和結束索引之間的 ndarray 片斷:
>>> print(my_ndarray[:])[ 1 4 7 10 13 16 19]>>> print(my_ndarray[2:4])[ 7 10]>>> print(my_ndarray[5:6])[16]>>> print(my_ndarray[6:7])[19]>>> print(my_ndarray[:-1])[ 1 4 7 10 13 16]>>> print(my_ndarray[-1:])[19]
分片創建了一個 ndarray 的引用(或視圖)。這意味著,修改分片中的值也會改變原始 ndarray 的值。
比如說:
>>> my_ndarray[-1:] = 100>>> print(my_ndarray)[ 1 4 7 10 13 16 100]
對于秩超過 1 的 ndarray 的分片,可以使用 [行開始索引:行結束索引, 列開始索引:列結束索引] 語法:
>>> my_ndarray2 = np.array([(1, 2, 3), (4, 5, 6)])>>> print(my_ndarray2)[[1 2 3][4 5 6]]>>> print(my_ndarray2[0:2,1:3])[[2 3][5 6]]
使用布爾索引讀取 ndarray 的方法
讀取 ndarray 的另一種方法是使用布爾索引。在這種方法中,你在方括號內指定一個過濾條件,然后返回符合該條件的 ndarray 的一個部分。
例如,為了獲得一個 ndarray 中所有大于 5 的值,你可以指定布爾索引操作 my_ndarray[my_ndarray > 5]。這個操作將返回一個包含所有大于 5 的值的 ndarray:
>>> my_ndarray = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])>>> my_ndarray2 = my_ndarray[my_ndarray > 5]>>> print(my_ndarray2)[ 6 7 8 9 10]
例如,為了獲得一個 ndarray 中的所有偶數值,你可以使用如下的布爾索引操作:
>>> my_ndarray2 = my_ndarray[my_ndarray % 2 == 0]>>> print(my_ndarray2)[ 2 4 6 8 10]
而要得到所有的奇數值,你可以用這個方法:
>>> my_ndarray2 = my_ndarray[my_ndarray % 2 == 1]>>> print(my_ndarray2)[1 3 5 7 9]
ndarray 的矢量和標量算術
NumPy 的 ndarray 允許進行矢量和標量算術操作。在矢量算術中,在兩個 ndarray 之間進行一個元素的算術操作。在標量算術中,算術運算是在一個 ndarray 和一個常數標量值之間進行的。
如下的兩個 ndarray:
>>> my_ndarray = np.array([1, 2, 3, 4, 5])>>> my_ndarray2 = np.array([6, 7, 8, 9, 10])
如果你將上述兩個 ndarray 相加,就會產生一個兩個 ndarray 的元素相加的新的 ndarray。例如,產生的 ndarray 的第一個元素將是原始 ndarray 的第一個元素相加的結果,以此類推:
>>> print(my_ndarray2 + my_ndarray)[ 7 9 11 13 15]
這里,7 是 1 和 6 的和,這是我相加的 ndarray 中的前兩個元素。同樣,15 是 5 和10 之和,是最后一個元素。
請看以下算術運算:
>>> print(my_ndarray2 - my_ndarray)[5 5 5 5 5]>>>>>> print(my_ndarray2 * my_ndarray)[ 6 14 24 36 50]>>>>>> print(my_ndarray2 / my_ndarray)[6. 3.5 2.66666667 2.25 2. ]
在 ndarray 中加一個標量值也有類似的效果,標量值被添加到 ndarray 的所有元素中。這被稱為“廣播”:
>>> print(my_ndarray + 10)[11 12 13 14 15]>>>>>> print(my_ndarray - 10)[-9 -8 -7 -6 -5]>>>>>> print(my_ndarray * 10)[10 20 30 40 50]>>>>>> print(my_ndarray / 10)[0.1 0.2 0.3 0.4 0.5]
ndarray 的排序
有兩種方法可以對 ndarray 進行原地或非原地排序。原地排序會對原始 ndarray 進行排序和修改,而非原地排序會返回排序后的 ndarray,但不會修改原始 ndarray。我將嘗試這兩個例子:
>>> my_ndarray = np.array([3, 1, 2, 5, 4])>>> my_ndarray.sort()>>> print(my_ndarray)[1 2 3 4 5]
正如你所看到的,sort() 方法對 ndarray 進行原地排序,并修改了原數組。
還有一個方法叫 np.sort(),它對數組進行非原地排序:
>>> my_ndarray = np.array([3, 1, 2, 5, 4])>>> print(np.sort(my_ndarray))[1 2 3 4 5]>>> print(my_ndarray)[3 1 2 5 4]
正如你所看到的,np.sort() 方法返回一個已排序的 ndarray,但沒有修改它。
總結
我已經介紹了很多關于 NumPy 和 ndarray 的內容。我談到了創建 ndarray,讀取它們的不同方法,基本的向量和標量算術,以及排序。NumPy 還有很多東西可以探索,包括像 union() 和 intersection()這樣的集合操作,像 min() 和 max() 這樣的統計操作,等等。
我希望我上面演示的例子是有用的。祝你在探索 NumPy 時愉快。