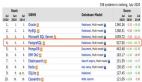
在開源數據庫上我們要關注SQL解析問題嗎
傳統的Oracle DBA都會把SQL解析問題看的很嚴重,這實際上是來自于早年的DBA對共享池問題的恐懼。實際上,我剛剛開始接觸數據庫的時候,SQL解析根本不是一個什么技術問題,因為那時候的服務器的性能有限,頂多兩顆CPU,幾十M的物理內存,雖然連接了幾十臺上百臺終端,實際上大多數時候都在處理前端顯示等緩慢的外設操作。真正訪問數據庫的并發量并不大,因此那時候的數據庫問題主要還是DB CACHE的命中率問題,只要保證DB CACHE命中率高于80%,大多數SQL都能跑的還可以。不過那時候的SQL也都比較簡單,碼農的素質也比較高,自己能用算法搞定的事情一般不會交給數據庫去做。
不過后來隨著C/S架構的發展,前端的并發量越來越大了,小型機服務器的處理能力也大了起來,95年,DEC公司推出了VLM和VLDB的概念,VLM就是VERY LARGE MEMORY,VLDB就是VERY LARGE DATABASE,這是因為64位的芯片誕生了,這個芯片就是ALPHA 21064,這個現在已經賣身成為申威的芯片是世界上第一顆商用的64位芯片。由于內存一下子進入了GB級別,數據庫的規模也從MB級別變成GB級別的了,C/S架構又讓前端的并發量有了質的提升,因此和shared pool相關的問題逐漸多了起來。而雖然已經進入了VLM時代,不過那時候的HP/IBM們還只有32位的芯片,哪怕是64位的服務器上,要配備好幾個GB的物理內存依然是十分昂貴的。因此那時候的數據庫SHARED POOL的配置都是十分可憐的,200M以上的SHARED POOL就算是比較豪華的了,正是因為這個原因,共享池帶來的并發爭用經常會成為DBA的噩夢。
哪怕后來內存稍微寬松一些了,可以配置較大的共享池了,那時候服務器的CPU還是過于昂貴,因此如何讓CPU把更多的資源用于SQL執行,Oracle在CURSOR共享上下足了大功夫,盡可能地讓一個CURSOR編譯后的資源能夠被更多的會話和執行共享。這個工作讓共享池變得十分復雜,也變成了一個十分容易出問題的組件。90年代末00年代初的DBA都在共享池問題上吃過大苦頭。因此大量的文檔資料都對共享池問題,硬解析問題做了大量的分析。而從DBA這個師傅帶徒弟的方式傳承的職業上,這種恐懼被一代代的傳了下來。
至少在5年前,還經常有DBA和我探討數據庫性能問題的時候,都會把硬解析數量放在比較重要的位置上去考慮。我要費挺大的勁兒去解釋,硬解析雖然多了點,但是你的系統問題主要不是硬解析引起的,因為共享池的爭用并不嚴重。
雖然說,Oracle 10g推出了SGA 動態調整技術之后,共享池引起的大問題逐漸少了很多,而隨著服務器技術的發展,特別是去IOE時代開始的X86替代小型機之后,內存,CPU變得十分便宜了。因此我們的服務器都可以配備了超豪華的CPU/內存/IO資源了,還是有大量的DBA依然受到那時候的影響,對SQL解析十分恐懼。這個恐懼甚至帶到了開源數據庫和國產數據庫上。
實際上,在大多數開源和國產數據庫上,并不存在全局共享的CURSOR,一般來說,CURSOR共享是會話級的。這種設計讓Oracle 復雜的共享池結構對于開源數據庫來說變得簡單的多了,它們只需要共享字典緩存就可以了,SQL執行的CURSOR結構在會話內共享就可以了。這種基于會話的CURSOR共享,對DBA來說絕對是一個福音,因為這種結構十分簡單,不容易出現閂鎖的問題。
當數據庫在高并發SQL執行的時候,只需要增加一點點SQL解析的CPU和內存開銷就可以了。而這兩種資源在現在的服務器上,已經是十分便宜了。因此在開源和國產數據庫上,我們很少聽說SQL解析引起的性能問題。除非是CPU或者內存資源嚴重不足的系統中,這類問題恐怕都不是問題。
采用會話內共享CURSOR是硬件發展的必然選擇,新數據庫也沒必要再去研發Oracle那種復雜的共享池了,這對于數據庫產業來說是件好事,因為真正能夠玩轉復雜的共享池的,目前為止也只有Oracle一家。前陣子有個數據庫研發人員和我探討,他想在他們的自研數據庫里引入類似Oracle的共享池,從而減少SQL解析的開銷。我建議他不要這么做,一條比較爛的SQL消耗的CPU內存資源,就可以把他們花數千萬研發出來的共享池節約的那點可憐的資源全部消耗掉,甚至成十倍百倍的消耗掉,有那個錢還不如投入到改善CBO優化器上去。
幸運的是,現在的DBA不需要像我們那樣經常面對痛苦的共享池問題,那個問題像幽靈一樣,沒有任何跡象,說啥時候爆發就啥時候爆發。那時候,半夜被電話鈴聲吵醒的時候,害怕共享池出問題的恐懼甚至甚過數據庫宕機。