計算原生網絡之元宇宙SDN控制器
元宇宙SDN控制器?
小伙伴們對昨天利用BloomFilter過濾找到密接通信對而畫出的3D拓撲圖很感興趣。
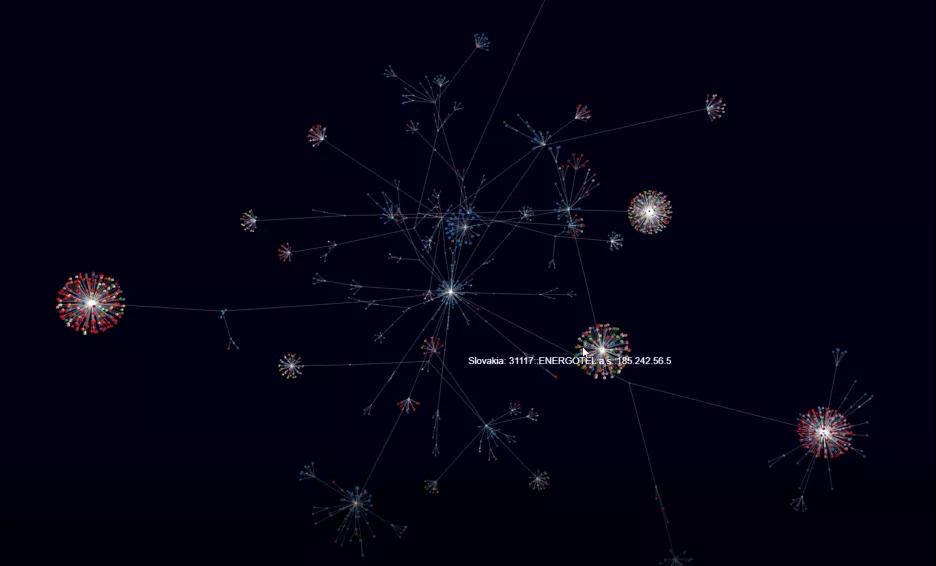
其實它是基于3D js[1]庫實現的,具體如何做渲染可以看昨天分享的zbf的代碼。
當然還有一個項目是3d-force-graph-vr[2]。
等渣有空了買個VR眼鏡應該隨手擼幾行代碼就可以實現類似于切水果的ACL動態阻斷,或者基于拖拽的Ruta的靈活路徑規劃和流量工程。

華為 Compute-Native Networking
前幾天收到一封來自華為的郵件,講了一下它們新的總線協議,突破內存墻和I/O墻,領導數據時代計算系統創新生態型格局。這是在APNet 2021上的一個主題演講[3]:
從原理上看,Compute-native networking(后文縮寫成HCNN)的提出是很不錯的。
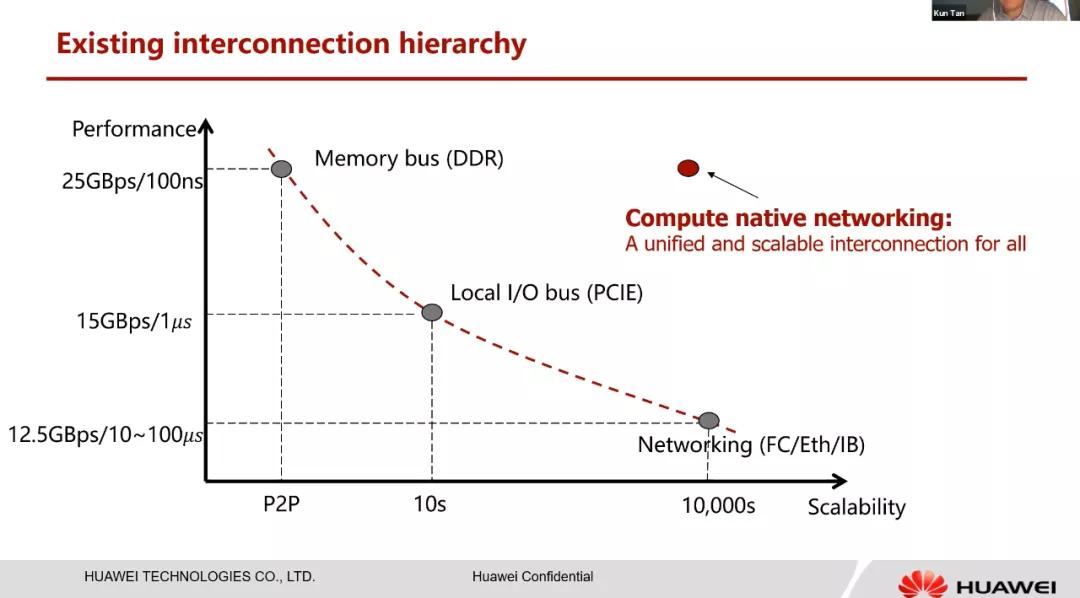
Compute-Native對于延遲和帶寬的追求以及對于通信容量的追求,這圖寫的非常好。PCIe、CXL都因為其總線原因編址和拉遠都存在問題。而超大規模計算的需求在那,這個是大家都要去解決的。整個思路和NetDAM是類似的,但有一點不同的是,整個UB他們是采用的特殊的通信協議:

而NetDAM采用的以太網UDP。
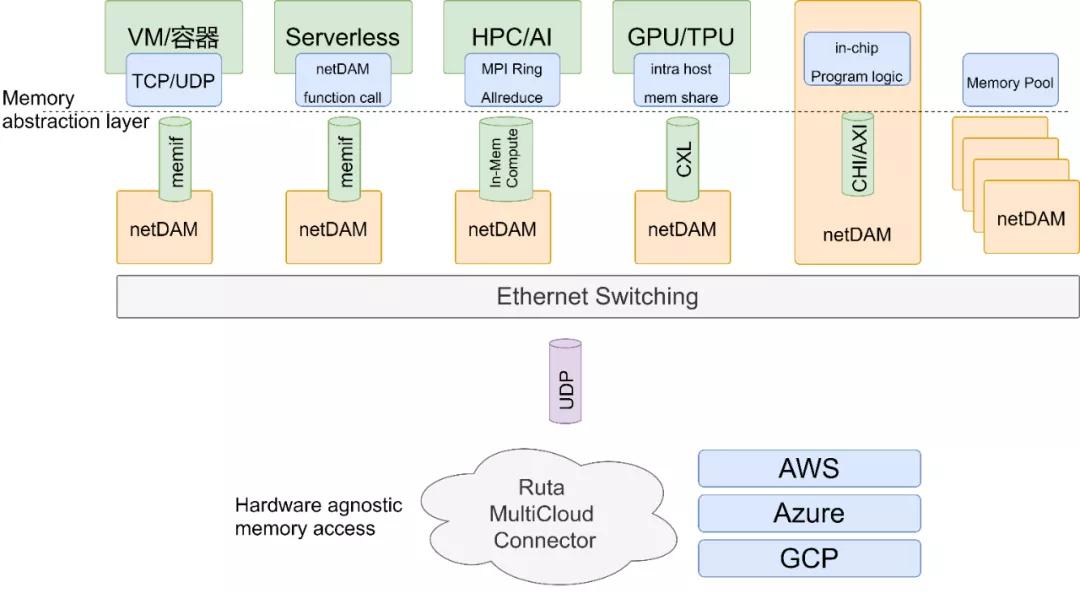
其實很多技術,要推倒重來有各種處理方法都非常容易,但是整個行業又有誰愿意來推倒重來給你做嫁衣? NetDAM項目最早是2020年跟第四范式談合作的時候研發的,最初的想法也就是直接做PCIe Switch然后擴展成一個更好尋址的總線,后面還有一些討論直接利用IP Packet預留寄存器區域和指令的方式來實現Cache一致性和多機同步,這些都是片面的追求極致化而不顧生態的行為。
但是保持開放和持續的后向兼容才是王道,同時能夠讀懂別的架構師在各種約束下的取舍也是十分重要的。例如在HPC這樣的多機訪問場景中,具有統一地址空間的訪問是很不錯的選擇,RDMA本身的通信方式帶來了計算規模的瓶頸,HCNN采用了如下的尋址方式:
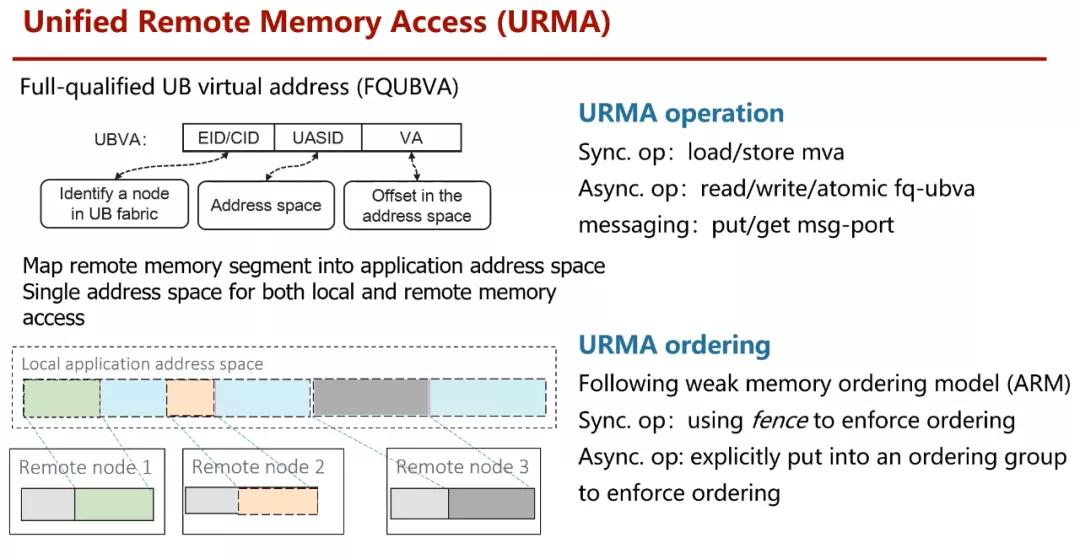
從通信層面上看,的確報文尺寸更小,但是直接尋址對于故障隔離和冗余保護都極為不利,而且整個交換路由網絡都要重新設計,并且最終和其它設備訪問還需要添加特殊的網卡不便于利舊。而NetDAM直接利用P4交換機構建MMU的方式,并且完全支持以太網,整個生態環境上會好很多,Intel、AMD、BRCM、Cisco等很多廠家都有用以太網替代RDMA的利益沖動,而RDMA本身又因為DMA導致處理器在超過200Gbps的情況下會導致大量的Cache miss,另一方面是利舊的原因,例如Fungible這類的東西要求全網更新是完全不可能的,因此構造一個任何設備都可以UDP訪問的接口又給NetDAM這個協議增加了很多平滑遷移的可能性。
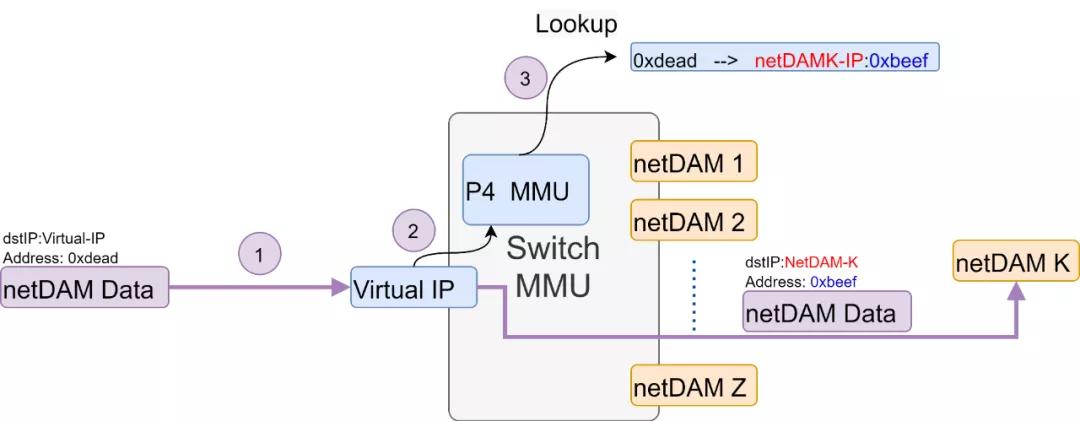
通過IP地址+內存地址,甚至是IPv6地址內嵌內存頁地址才是Compute-Native網絡的最終路徑,IP協議的腰是很難撼動的。
至于計算指令,有些東西物理的延遲就在那里,通過計算范式去做,例如Rust一類語言對內存所有權的管理或許才是未來,而計算上,HCNN的UB簡單的照搬以往的指令。
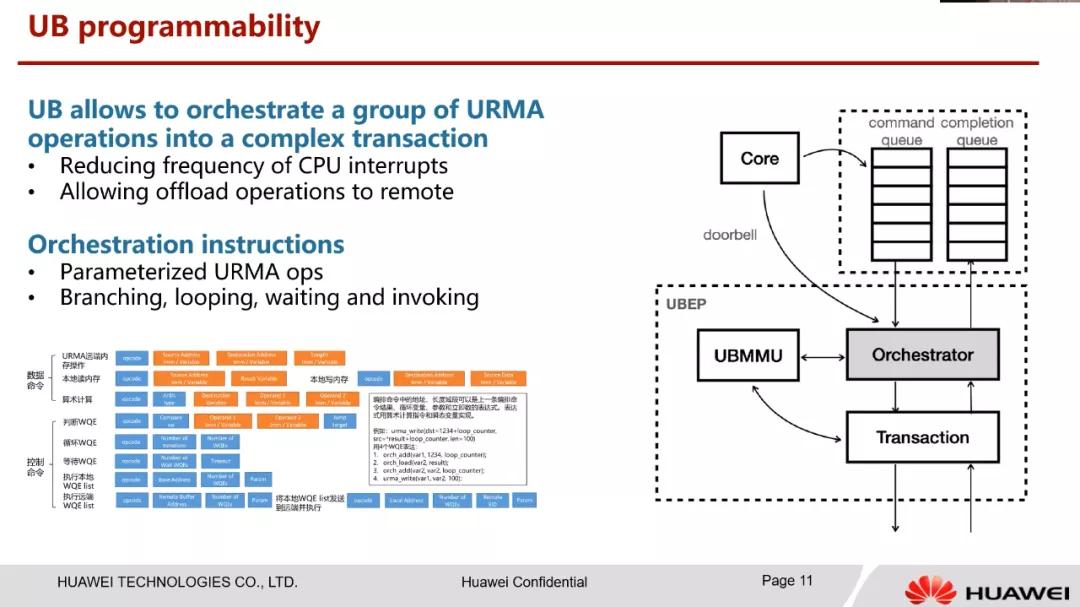
我們做NetDAM也考慮過同樣的處理方式,但是很快就放棄了,因為我們更多的只是做一些Vector、Matrix的Offload,Scalar的處理Offload就等于扯淡。這里TensTorrent的一張圖堪稱經典。
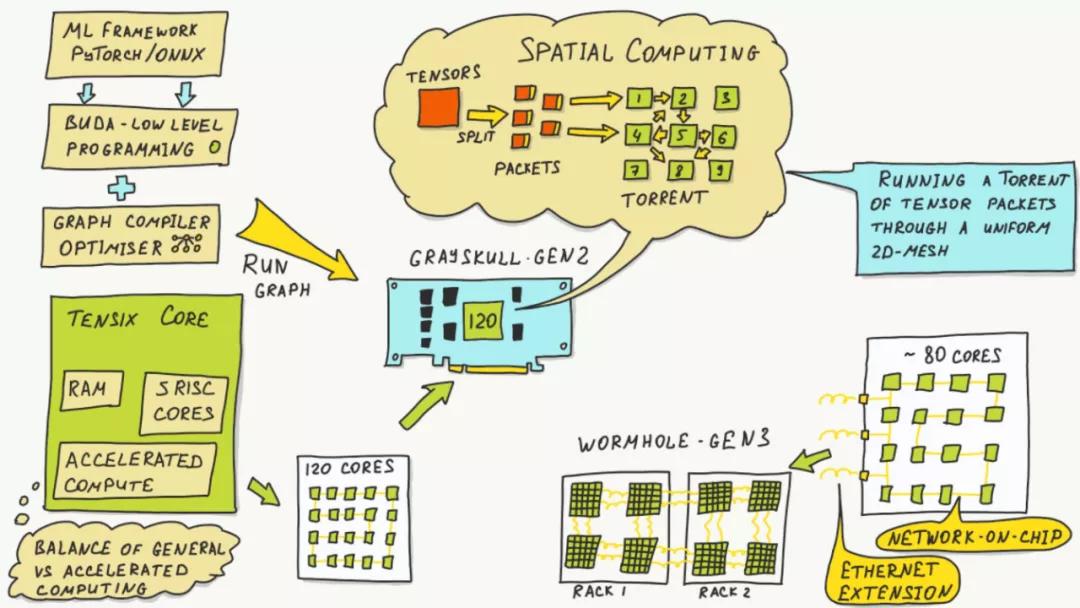
把Tensors拆分成packets,然后利用一個類似于BitTorrent的結構一邊轉發一邊計算,所以我一直說這件事情上Jim Keller和他的小伙伴們是看清楚了的,具體可以看如下的Video:
https://www.youtube.com/watch?v=KOHQQyAKY14
TensTorrent的芯片結構也值得大家去好好學習一下:
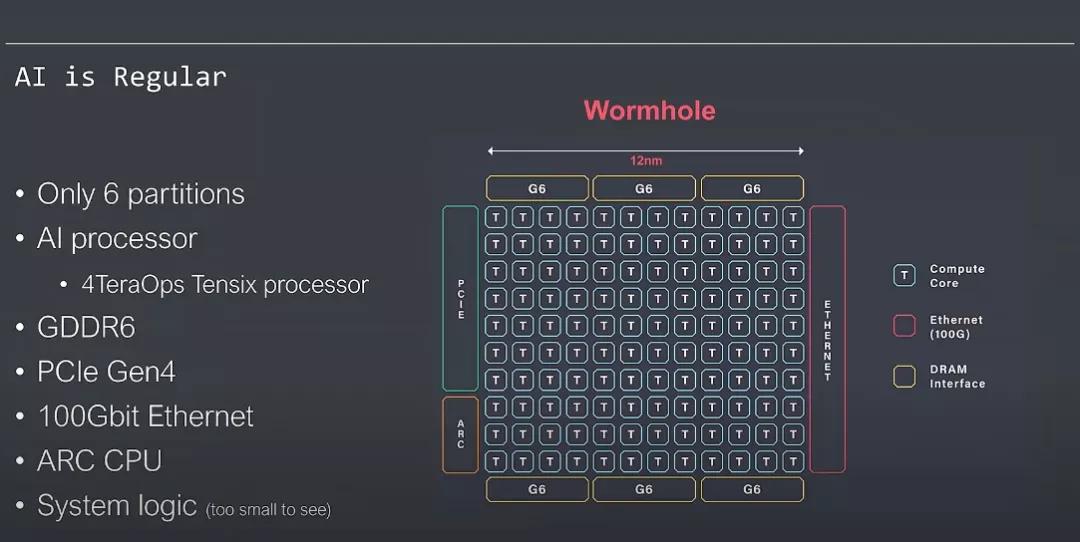
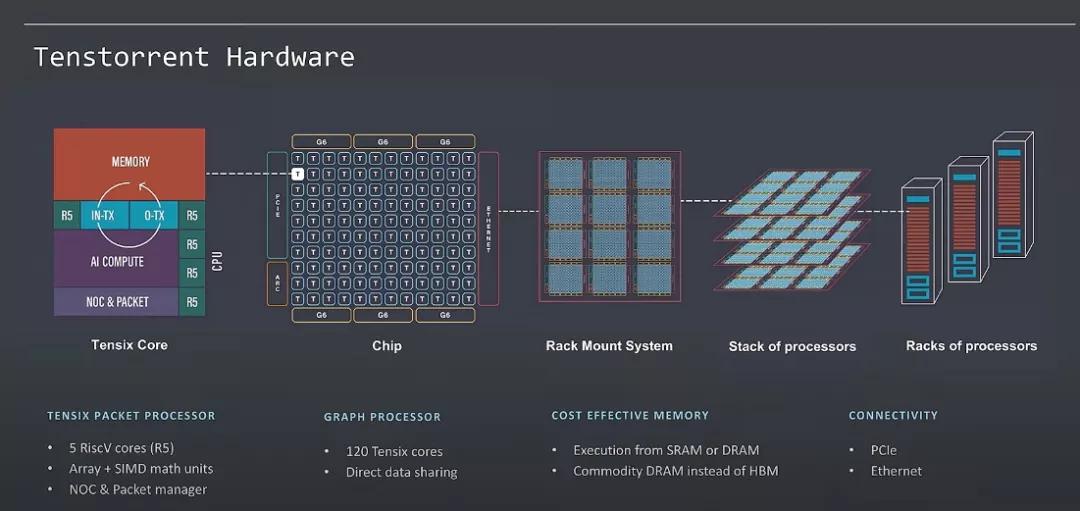
最關鍵的是利用標準的RISC-V核,非常漂亮,這也是架構師必須要考慮的問題,對上的生態兼容問題和編程靈活性的問題:
當然思科的QFP在20年前也是采用同樣的方法,2D-Mesh的片上網絡,然后標準的C編譯環境,多芯片互聯[4]。
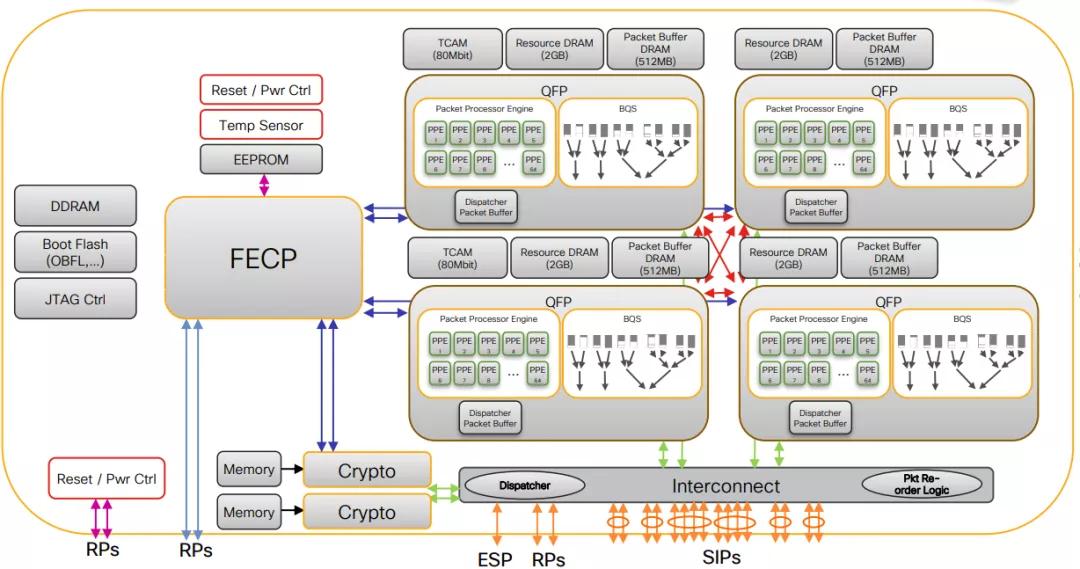
因此我們在NetDAM的設計中也使用UDP使得用戶態可以非常靈活的編程產生指令,同時針對內存訪問,還可以提供類似于memif的結構給其它編程語言。
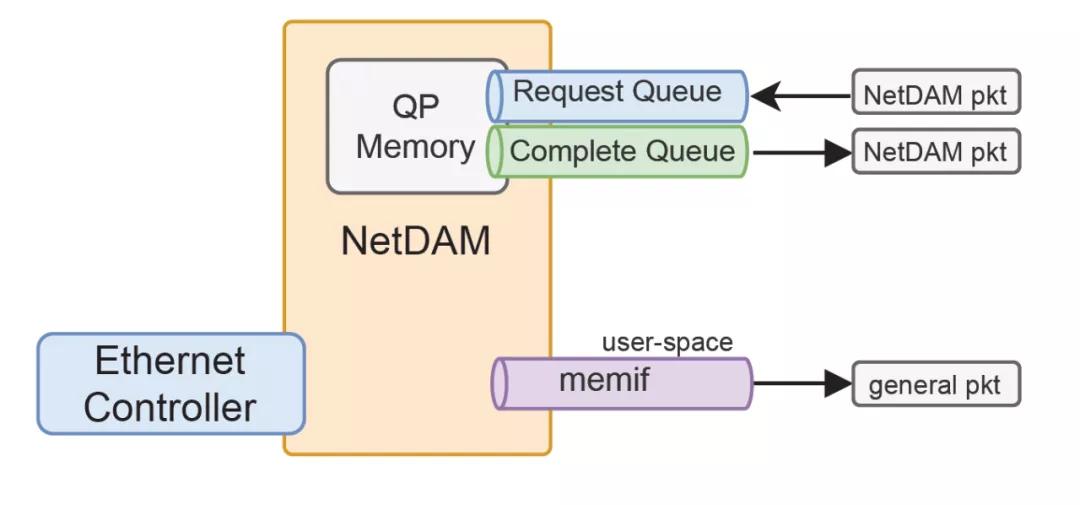
至于某個DPU公司,看過一些當年的文檔[5] 有些東西over-engineering了。
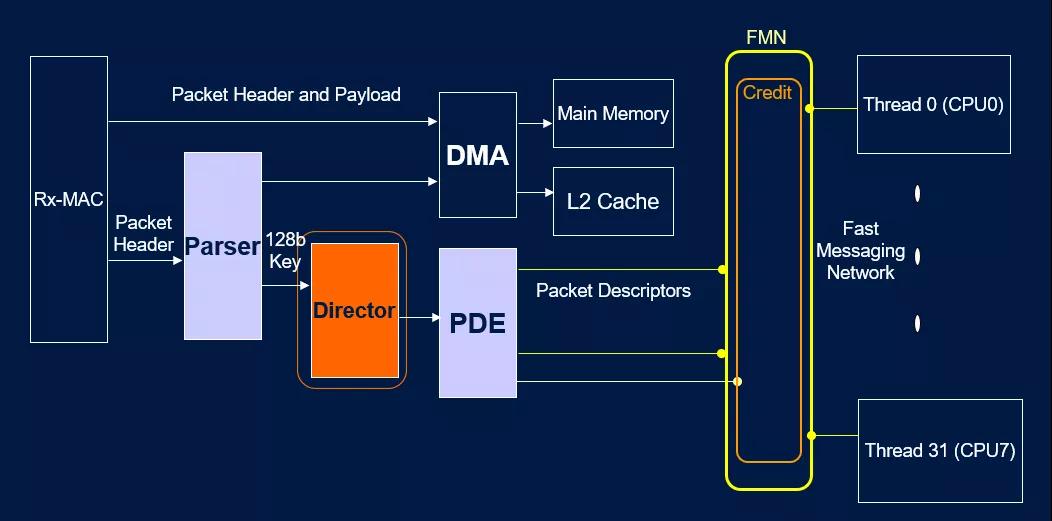
自然而然在靈活性上產生了缺失...其實很多產品都這樣,設計時以處理器為中心:
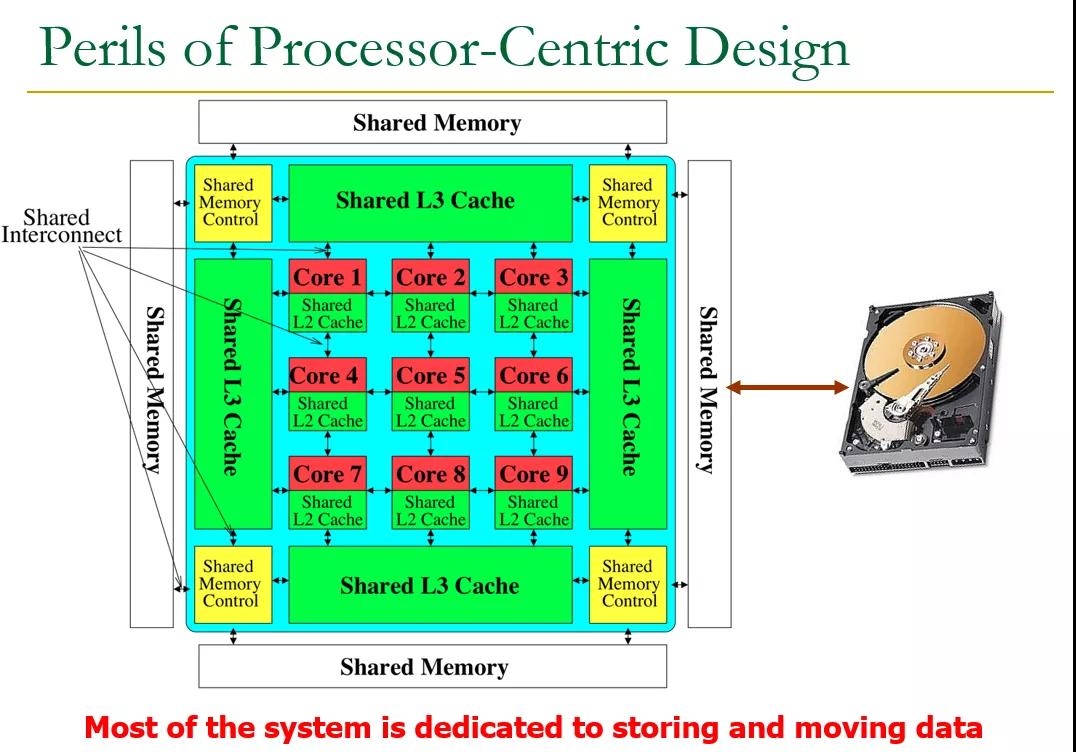
因此從這個結論上來看,Compute-Native networking 只看到了一個很片面的視角,而更多的是以Data-Centric為主,特別是在各個公司都承諾3060碳中和的時候,最應該關注的便是數據的移動。

所以NetDAM會在上面放置一些ALU,實現近存計算(Nearly-In-Memory)或者在轉發報文的時候實現隨路計算。把一些ALU放置在靠近內存和靠近通信的位置就是NetDAM的價值。
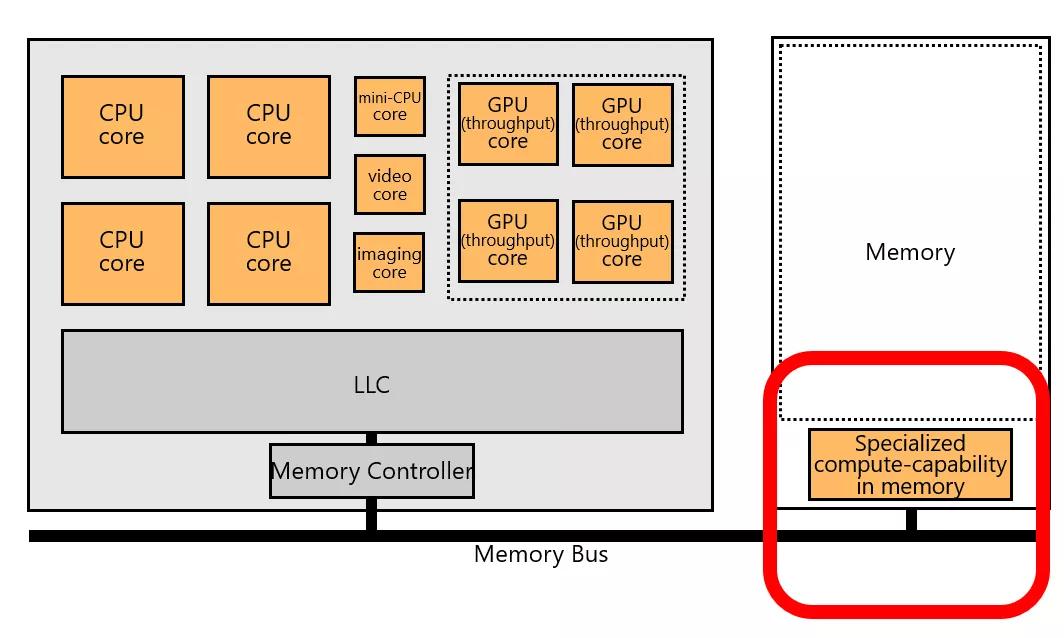
而實現Processing-In-Memory(PIM)還需要很多工作,一方面是微處理器架構,然后軟硬件接口,然后到系統軟件、編程語言,再到算法。
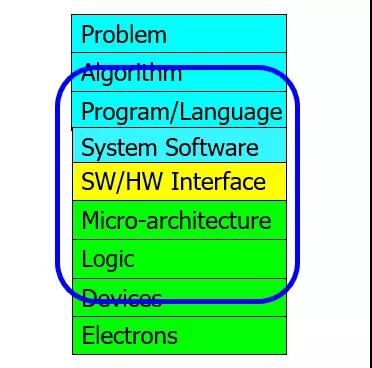
DreamBig才能有未來,至于同名的某個DPU公司,一上手就來QUIC優化,從體系結構來看很有可能又是一個和Marvel CN10K或者x豹類似的多核處理器廠家,因為他家在講QUIC FastPath的時候還提到過嵌入式處理器。
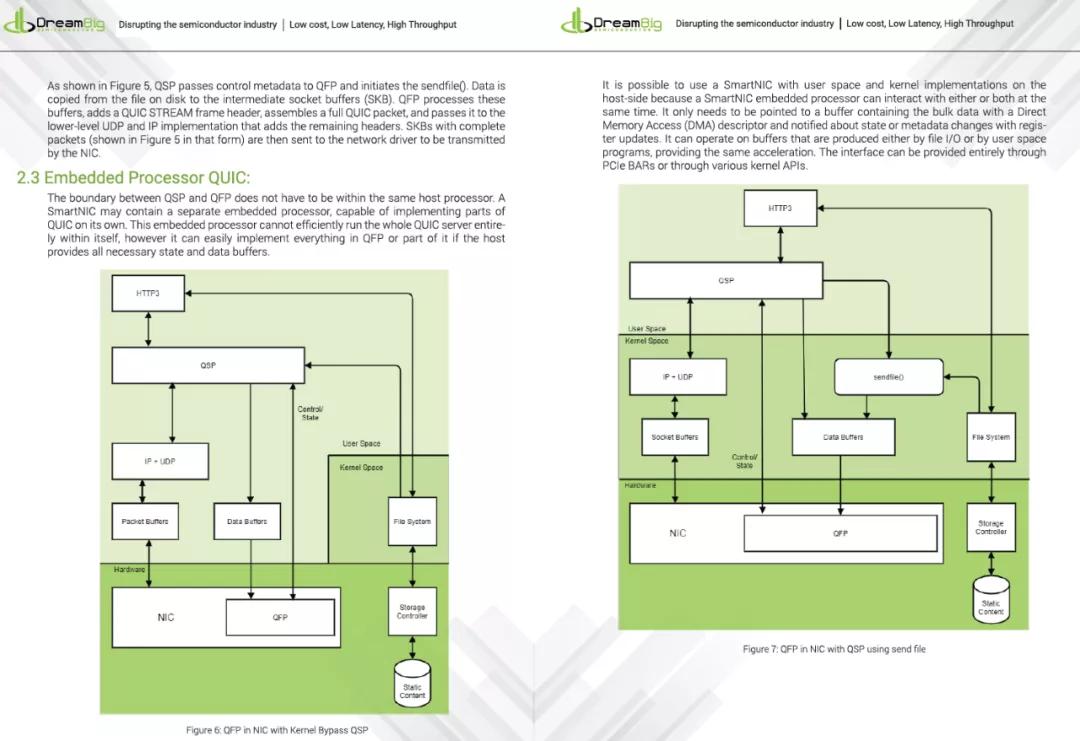
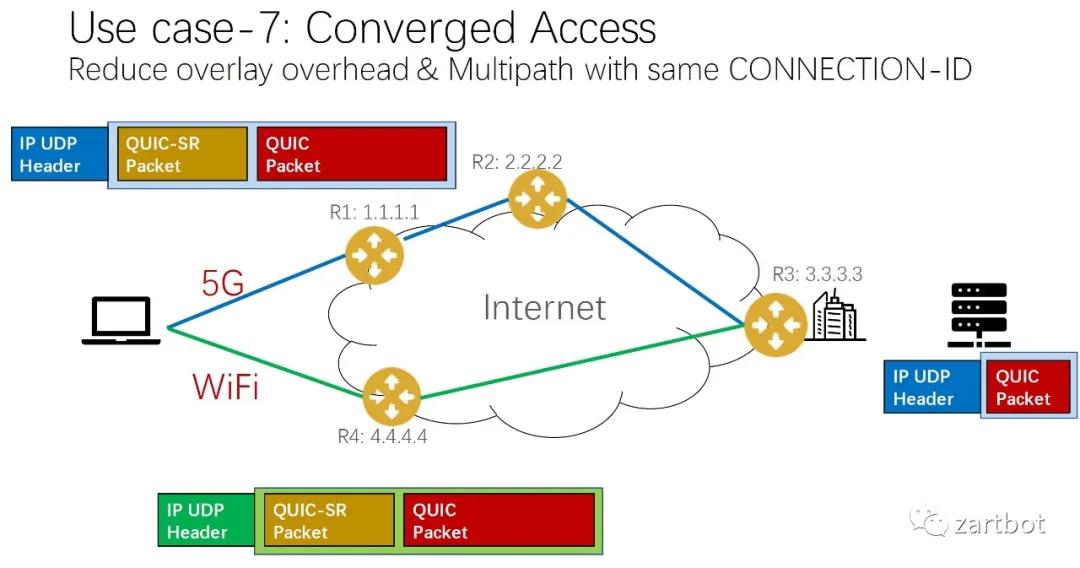
QUIC的Offload是一個非常有趣的話題,但是也可能非常難,因為協議編碼的一些問題,利用QUIC的可靠傳輸和安全性配合SegmentRouting的可編程能力,這也是渣另一個項目Ruta的初衷。
《QUIC-SR:關于NewIP的答案》

云網質量保障計劃
渣去年測完公有云的互通質量后:
《國內共有云互通測試》
《公有云互通測試報告(2)》
終于過了一年中國信息通信研究院聯合中國通信標準化協會在京召開了2021混合云大會,會上啟動了云網質量保障計劃,可喜可賀~至于測量方法上,渣表示就不多評價了,留篇文章自己抄作業吧
《Internet 的性能測量》
《Ruta:不用花10個億也能做千眼》
Reference
[1]3d-force-graph:
https://github.com/vasturiano/3d-force-graph
[2]3d-force-graph-vr:
https://github.com/vasturiano/3d-force-graph-vr,
[3]Compute-native networking:
https://conferences.sigcomm.org/events/apnet2021/records/25/4.Towards%20Compute-Native%20Networking.mp4
[4]Troubleshooting of ASR1K and ISR IOS-XE Made Easy:
https://www.ciscolive.com/c/dam/r/ciscolive/emea/docs/2020/pdf/BRKARC-3147.pdf
[5]RMI MIPS XLR多核處理器培訓.ppt:
https://download.csdn.net/download/zeroqi1706/1486860?utm_source=bbsseo