













深度學(xué)習(xí)如煉丹,你有哪些迷信做法?網(wǎng)友:Random seed=42結(jié)果好
每個機器學(xué)習(xí)領(lǐng)域的研究者都會面臨調(diào)參過程的考驗,當(dāng)往往說來容易做來難。調(diào)參的背后往往是通宵達(dá)旦的論文研究與 GitHub 查閱,并需要做大量的實驗,不僅耗時也耗費大量算力,更深深地傷害了廣大工程師的頭發(fā)。
有人不禁要問:調(diào)參是門玄學(xué)嗎?為什么模型明明調(diào)教得很好了,可是效果離我的想象總有些偏差。
近日,reddit 上一則帖子引發(fā)了網(wǎng)友熱議,「機器學(xué)習(xí)調(diào)參領(lǐng)域有哪些迷信的看法或做法呢?」

原貼地址:
https://www.reddit.com/r/MachineLearning/comments/rkewa3/d_what_are_your_machine_learning_superstitions/?sort=confidence
關(guān)于調(diào)參的那些「秘訣」
在機器學(xué)習(xí)中,超參數(shù)調(diào)整是一項必備技能,通過觀察在訓(xùn)練過程中的監(jiān)測指標(biāo)如損失 loss 和準(zhǔn)確率來判斷當(dāng)前模型處于什么樣的訓(xùn)練狀態(tài),及時調(diào)整超參數(shù)以更科學(xué)地訓(xùn)練模型能夠提高資源利用率。
每個人都會根據(jù)自己的實際經(jīng)驗進(jìn)行模型調(diào)參,最終,絕大多數(shù)研究者可能得出的經(jīng)驗就是:
- Random seed = 0 得到壞的結(jié)果
- Random seed = 42 得到好的結(jié)果
- Even-valued k in k-Means = insightful segmentation
有人將這一經(jīng)驗總結(jié)奉為所謂的 ML「迷信做法」,但其實不然,幾乎所有學(xué)者都這樣做。
不過,也有網(wǎng)友對這一經(jīng)驗總結(jié)持懷疑態(tài)度:網(wǎng)友 @SlashSero 遺憾地表示,這種情況甚至?xí)霈F(xiàn)在非常有名的科學(xué)出版物上,尤其是在交叉驗證不可行或者易受其他參數(shù)選擇影響的機器學(xué)習(xí)應(yīng)用中,因此超參數(shù)優(yōu)化(HPO)不可行。不妨看看 NeurIPS 會議論文有多少擁有真正透明的代碼庫和易于復(fù)現(xiàn)的交叉驗證研究,以證實他們的工作較去年提升了 0.5-1% 的性能。
另外,很多時候出于對研究者的信任,但其實會導(dǎo)致新的深度學(xué)習(xí)模型在實踐中并沒有表現(xiàn)出明顯優(yōu)于傳統(tǒng)模型的性能。我們應(yīng)該看到,社區(qū)存在這樣一種現(xiàn)狀:花費大量時間確保模型真正兌現(xiàn)它所表現(xiàn)出的性能,并且可復(fù)現(xiàn)和透明,這是一項吃力不討好的工作。消耗計算資源不說,還有可能失去在一個發(fā)展極快的領(lǐng)域發(fā)表論文和獲得表彰的機會。
為了實現(xiàn)模型最佳性能,各路網(wǎng)友也紛紛曬出自己的煉丹經(jīng)驗:有網(wǎng)友認(rèn)為 Random seed 必須是 10 的倍數(shù),最好是 1000(不過該回答遭到了別人的反駁)。
除了 Random seed 設(shè)置外,有研究者分享了自己的一些科研小技巧。
模型的訓(xùn)練過程,近乎黑盒,假如期間發(fā)生程序錯誤,很難察覺到,有網(wǎng)友建議隨時隨地進(jìn)行「print」是一個很好的習(xí)慣,在程序第一次運行時,一定要打印所有可能的東西,「print」能讓你知道程序進(jìn)行到哪一步,有沒有陷入死循環(huán)...... 其實,絕大多數(shù)程序員都會這樣做。

除了「print」外,有人表示日志記錄也非常有必要,在實驗室做科研,有時為了跑一個程序,需要花費好幾天的時間,但總有那么不順心的地方,要么好久不斷電的實驗室突然斷電,要么服務(wù)器崩了…… 所以隨時隨地保存日志也是每個程序員必備的,查看日志記錄,你能發(fā)現(xiàn)程序運行到哪了,粗略估計模型性能,還能查看錯誤:
還有網(wǎng)友曬出了自己的 dropout 經(jīng)驗,認(rèn)為超過 20% 的 dropout 將使該模式難以恢復(fù)。不過這只是這位網(wǎng)友自己的經(jīng)驗,也有人表示自己采用 90% 的 dropout,模型性能最好。

除此以外,有網(wǎng)友總結(jié)了批大小應(yīng)該是 2 的冪次方。
以上就是網(wǎng)友總結(jié)的一些 ML 煉丹小技巧。
玄學(xué)論文難復(fù)現(xiàn)
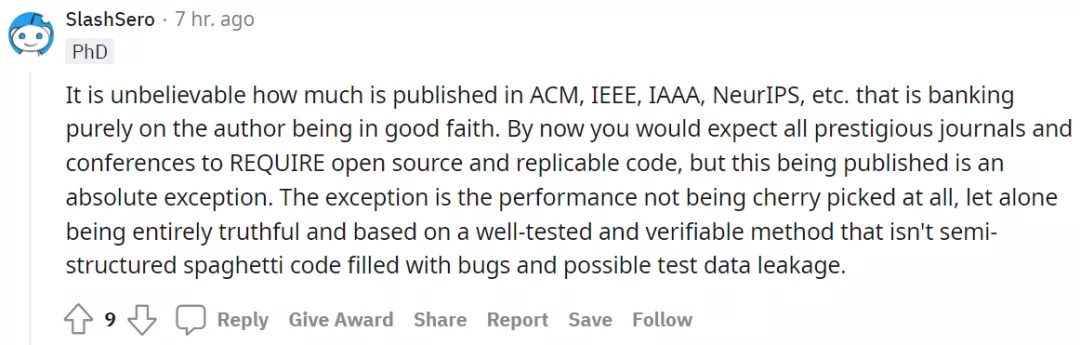
雖然調(diào)參有用,但網(wǎng)友 @ostrich-scalp 犀利地批駁道,「大多數(shù)論文的結(jié)果都是胡說八道,將我的職業(yè)生涯都用來實現(xiàn)這些工作并期望創(chuàng)建像模像樣可用于生產(chǎn)的模型,這是一個極大的錯誤。」
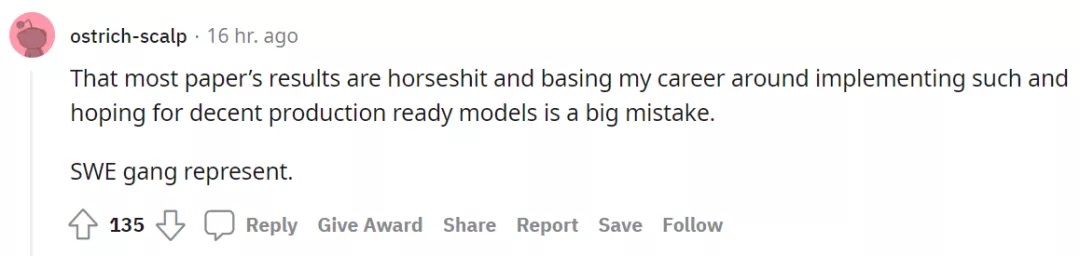
上面那位老哥 @SlashSero 接茬說道,「令人難以置信的是,ACM、IEEE、IAAA 和 NeurIPS 上發(fā)表的論文有多少完全只是出于對作者的信任。到現(xiàn)在為止,你可能希望所有知名期刊和會議都要求論文作者開源和復(fù)現(xiàn)代碼,但這種情況只是例外。」
顯然,機器學(xué)習(xí)是一門技術(shù)。雖然神經(jīng)網(wǎng)絡(luò)黑箱的狀態(tài)讓可解釋性受限,但我們可以在較高層面上通過經(jīng)驗解決面臨的問題。我們需要加載數(shù)據(jù),建立框架,讓系統(tǒng)運行起來,設(shè)定度量標(biāo)準(zhǔn),調(diào)整參數(shù)并分析誤差,進(jìn)行特征工程,結(jié)果可視化等等步驟。最終經(jīng)過數(shù)次迭代直至推理的準(zhǔn)確率不再提升。
那么為什么各種玄學(xué)現(xiàn)象仍然不斷出現(xiàn),拷問著我們的心靈?看來,我們對這門學(xué)科的了解還不夠多。
不過請記住 NIPS 2017 大會上圖靈獎得主 Judea Pearl 演講的最后一頁 Keynote:

數(shù)據(jù)科學(xué)僅當(dāng)能促進(jìn)對數(shù)據(jù)的合理解讀時才能被稱為科學(xué)。
不過也不用怕,深度學(xué)習(xí)調(diào)參總還是有技巧可循的,大致可以總結(jié)如下。這些算不得迷信做法,僅供參考。
- 尋找合適的學(xué)習(xí)率。作為一個非常重要的參數(shù),學(xué)習(xí)率面對不同規(guī)模、不同 batch-size、不同優(yōu)化方式和不同數(shù)據(jù)集,它的最合適值都是不確定的。我們唯一可以做的,就是在訓(xùn)練中不斷尋找最合適當(dāng)前狀態(tài)的學(xué)習(xí)率;
- 權(quán)重初始化。相比于其他的 trick 來說使用并不是很頻繁。只有那些沒有預(yù)訓(xùn)練模型的領(lǐng)域會自己初始化權(quán)重,或者在模型中去初始化神經(jīng)網(wǎng)絡(luò)最后那幾個全連接層的權(quán)重。常用權(quán)重初始化算法是「kaiming_normal」或「xavier_normal」;
- 數(shù)據(jù)集處理,主要有數(shù)據(jù)篩選和數(shù)據(jù)增強;
- 多模型融合,這是論文刷結(jié)果的終極核武器,深度學(xué)習(xí)中一般有幾種方式,比如同樣的參數(shù),不同的初始化方式;不同的參數(shù),通過交叉驗證選取最好的幾組;不同的模型,進(jìn)行線性融合,例如 RNN 和傳統(tǒng)模型;
- 余弦退火和熱重啟的隨機梯度下降。余弦退火就是學(xué)習(xí)率類似余弦函數(shù)慢慢下降,熱重啟就是在學(xué)習(xí)的過程中,學(xué)習(xí)率慢慢下降然后突然再回彈 (重啟) 然后繼續(xù)慢慢下降;
- 嘗試過擬合一個小數(shù)據(jù)集。關(guān)閉正則化 / 隨機失活 / 數(shù)據(jù)擴(kuò)充,使用訓(xùn)練集的一小部分,讓神經(jīng)網(wǎng)絡(luò)訓(xùn)練幾個周期。確保可以實現(xiàn)零損失,如果沒有,那么很可能什么地方出錯了。
- ……
調(diào)參路上各有各的「路數(shù)」,適合自己就好。
最后問一句,煉丹的你有哪些獨門秘籍呢?
參考鏈接:
- https://www.jiqizhixin.com/articles/2020-10-21-3
- https://picture.iczhiku.com/weixin/message1609136710592.html
【本文是51CTO專欄機構(gòu)“機器之心”的原創(chuàng)譯文,微信公眾號“機器之心( id: almosthuman2014)”】





















