













手把手教你對文本文件進行分詞、詞頻統(tǒng)計和可視化(附源碼)
大家好!我是Python進階者。
前言
前幾天一個在校大學(xué)生問了一些關(guān)于詞頻、分詞和可視化方面的問題,結(jié)合爬蟲,確實可以做點東西出來,可以玩玩,還是蠻不錯的,這里整理成一篇文章,分享給大家。
本文主要涉及的庫有爬蟲庫requests、詞頻統(tǒng)計庫collections、數(shù)據(jù)處理庫numpy、結(jié)巴分詞庫jieba 、可視化庫pyecharts等等。
一、數(shù)據(jù)來源
關(guān)于數(shù)據(jù)方面,這里直接是從新聞平臺上進行獲取的文本信息,其實這個文本文件可以拓展開來,你可以自定義文本,也可以是報告,商業(yè)報告,政治報告等,也可以是新聞平臺,也可以是論文,也可以是微博熱評,也可以是網(wǎng)易云音樂熱評等等,只要涉及到大量文本的,都可月引用本文的代碼,進行詞頻分詞、統(tǒng)計、可視化等。
二、數(shù)據(jù)獲取
數(shù)據(jù)獲取十分簡單,一個簡單的爬蟲和存儲就可以搞定,這里以一篇新聞為例進行演示,代碼如下:
import re
import collections # 詞頻統(tǒng)計庫
import numpy as np # numpy數(shù)據(jù)處理庫
import jieba # 結(jié)巴分詞
import requests
from bs4 import BeautifulSoup
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
import warnings
warnings.filterwarnings('ignore')
r=requests.get("https://m.thepaper.cn/baijiahao_11694997",timeout=10)
r.encoding="utf-8"
s=BeautifulSoup(r.text,"html.parser")
f=open("報告.txt","w",encoding="utf-8")
L=s.find_all("p")
for c in L:
f.write("{}\n".format(c.text))
f.close()
代碼運行之后,在本地會得到一個【報告.txt】文件,文件內(nèi)容就是網(wǎng)站上的文本信息。如果你想獲取其他網(wǎng)站上的文本,需要更改下鏈接和提取規(guī)則。
三、詞頻統(tǒng)計
接下來就是詞頻統(tǒng)計了,代碼如下所示。
# 讀取文件
fn = open("./報告.txt","r",encoding="utf-8")
string_data = fn.read()
fn.close()
# 文本預(yù)處理
# 定義正則表達式匹配模式
pattern = re.compile(u'\t|,|/|。|\n|\.|-|:|;|\)|\(|\?|"')
string_data = re.sub(pattern,'',string_data) # 將符合模式的字符去除
# 文本分詞
# 精確模式分詞
seg_list_exact = jieba.cut(string_data,cut_all=False)
object_list = []
# 自定義去除詞庫
remove_words = [u'的',u'要', u'“',u'”',u'和',u',',u'為',u'是',
'以' u'隨著', u'對于', u'對',u'等',u'能',u'都',u'。',
u' ',u'、',u'中',u'在',u'了',u'通常',u'如果',u'我',
u'她',u'(',u')',u'他',u'你',u'?',u'—',u'就',
u'著',u'說',u'上',u'這', u'那',u'有', u'也',
u'什么', u'·', u'將', u'沒有', u'到', u'不', u'去']
for word in seg_list_exact:
if word not in remove_words:
object_list.append(word)
# 詞頻統(tǒng)計
# 對分詞做詞頻統(tǒng)計
word_counts = collections.Counter(object_list)
# 獲取前30最高頻的詞
word_counts_all = word_counts.most_common()
word_counts_top30 = word_counts.most_common(30)
print("2021年政府工作報告一共有%d個詞"%len(word_counts))
print(word_counts_top30)
首先讀取文本信息,之后對文本進行預(yù)處理,提取文字信息,并且可以自定義詞庫,作為停用詞,之后將獲取到的詞頻做詞頻統(tǒng)計,獲取前30最高頻的詞,并進行打印,輸出結(jié)果如下圖所示。
? ?
?
四、可視化
接下來就是可視化部分了,這里直接上代碼,如下所示。
import pyecharts
from pyecharts.charts import Line
from pyecharts import options as opts
# 示例數(shù)據(jù)
cate = [i[0] for i in word_counts_top30]
data1 = [i[1] for i in word_counts_top30]
line = (Line()
.add_xaxis(cate)
.add_yaxis('詞頻', data1,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]))
.set_global_opts(title_opts=opts.TitleOpts(title="詞頻統(tǒng)計Top30", subtitle=""),
xaxis_opts=opts.AxisOpts(name_rotate=60,axislabel_opts={"rotate":45}))
)
line.render_notebook()
輸出結(jié)果是一個線圖,看上去還不錯。
?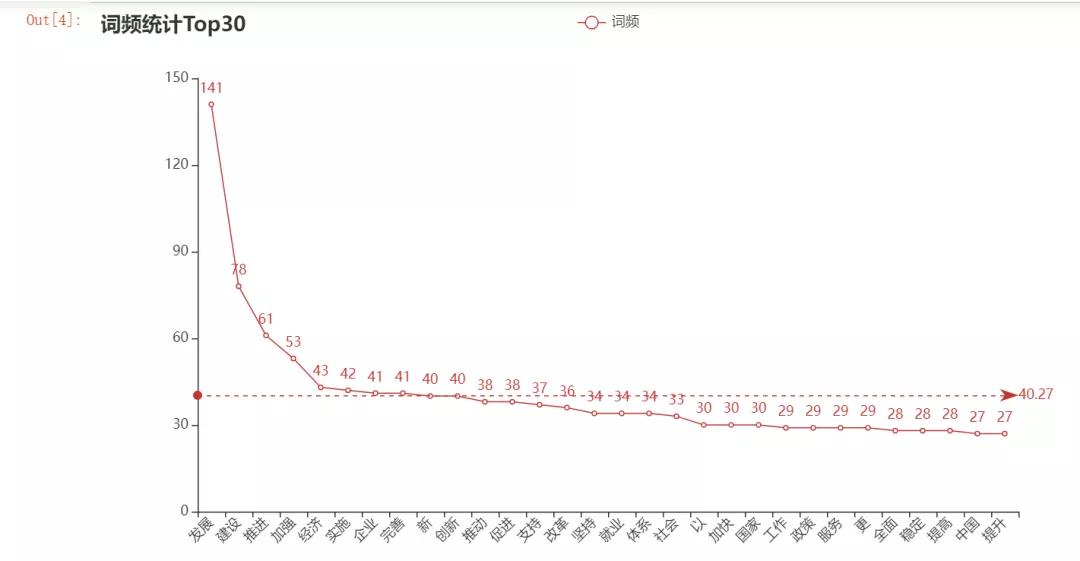 ?
?
五、總結(jié)
本文基于Python網(wǎng)絡(luò)爬蟲獲取到的文本文件,通過詞頻、分詞和可視化等處理,完成一個較為簡單的項目,歡迎大家積極嘗試。在代碼實現(xiàn)過程中,如果有遇到任何問題,請加我好友,我?guī)椭鉀Q哦!

















