八種方案,保證緩存和數(shù)據(jù)庫的最終一致性
前言
我們通常使用緩存機制來提升系統(tǒng)的性能,緩存系統(tǒng)下的讀寫操作,一般都需要操作數(shù)據(jù)庫與緩存。
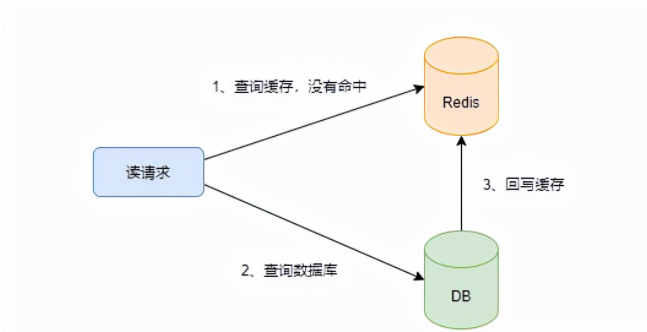
對于讀操作,一般是先查詢緩存,查詢不到再查詢數(shù)據(jù)庫,最后回寫進緩存。
而對于寫操作,究竟是先刪除(更新)緩存,再更新數(shù)據(jù)庫,還是先更新數(shù)據(jù)庫,再刪除(更新)緩存呢?
由于對數(shù)據(jù)庫以及緩存的整體操作,并不是原子性的,再加上讀寫并發(fā),究竟什么樣的方案可以保證數(shù)據(jù)庫與緩存的一致性呢?
下面介紹8種方案,配合讀寫時序圖,希望你能從其中了解到保證一致性的設(shè)計要點。
方案1 給緩存設(shè)置過期時間
這種方案適用于對數(shù)據(jù)一致性要求較低或者寫請求很少的業(yè)務(wù),當(dāng)讀請求沒有命中緩存時,就從數(shù)據(jù)庫中讀,之后回寫到緩存里,同時設(shè)置一個過期時間。
寫請求直接更改數(shù)據(jù)庫,不用操作緩存。因此當(dāng)一個key沒過期時,寫請求更改了數(shù)據(jù)庫,之后的讀還是讀取到舊數(shù)據(jù)。這個時候確實發(fā)生了不一致,但業(yè)務(wù)并不敏感。
方案2 先更新數(shù)據(jù)庫,再更新緩存
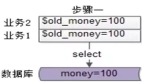
如果利用到緩存,那么肯定是讀多寫少的場景。但不能否定的是,可能會存在突發(fā)的寫多讀少的階段。
在這個特殊的階段中,會頻繁地更改數(shù)據(jù)庫與緩存,但緩存不會被頻繁地讀,更新緩存是在做無用功。
該方案可能還會有將臟數(shù)據(jù)寫回到緩存中的風(fēng)險:
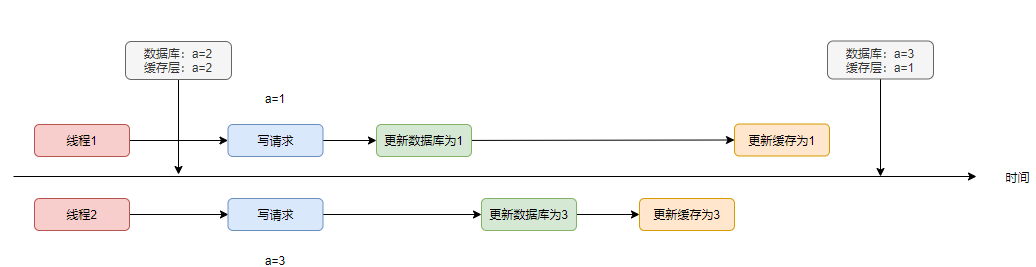
當(dāng)再有讀請求過來時,會直接從緩存中查詢到1,而數(shù)據(jù)庫中的值為3,造成不一致。
因此,該方案的不足在于:
- 寫多讀少時,頻繁更新緩存會降低性能
- 并發(fā)情況下可能存在將臟數(shù)據(jù)寫回緩存的風(fēng)險
方案3 先更新緩存,再更新數(shù)據(jù)庫
和方案2類似,也會存在相同的問題。
方案4 先更新數(shù)據(jù)庫,再刪除緩存
既然方案2與方案3都是更新緩存,這里不妨直接刪除緩存呢?
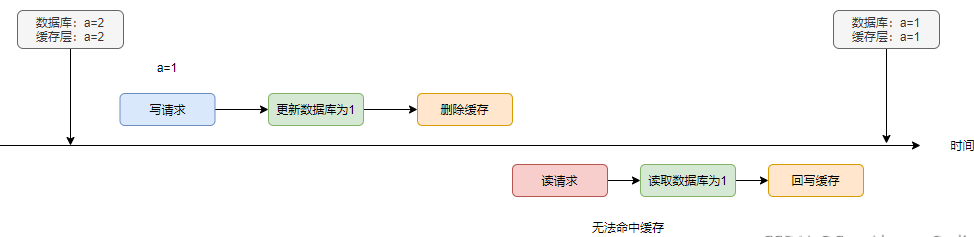
當(dāng)讀寫串行時,不會發(fā)生不一致的情況,貌似是一種比較好的方案。
不過看一下這個例子:
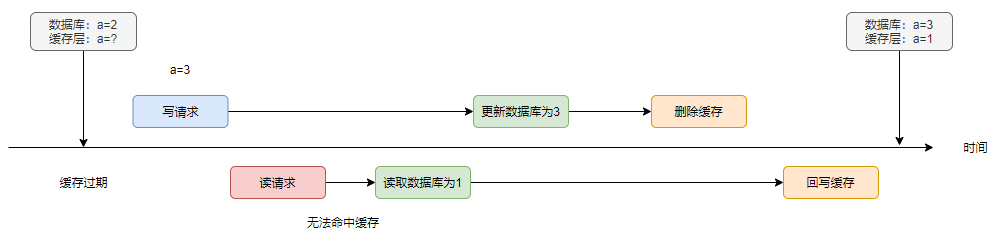
首先系統(tǒng)處于一個緩存過期的初始狀態(tài),接著讀寫并發(fā)。由于讀請求讀到了數(shù)據(jù)庫的舊值,而由于某種原因,回寫發(fā)生在寫請求執(zhí)行完畢之后,造成了刷臟的問題。
這種問題發(fā)生的概率較低,首先緩存得過期,再者讀請求的整條鏈路的執(zhí)行速度慢于寫請求。一般來說,讀肯定是快于寫的。
方案5 先刪除緩存,再更新數(shù)據(jù)庫
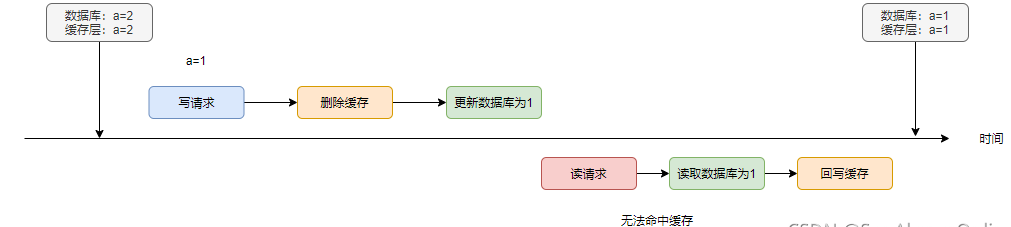
同樣,當(dāng)存在讀寫并發(fā)時,事情就不會往預(yù)料的方向上發(fā)展了,看下面這個例子:
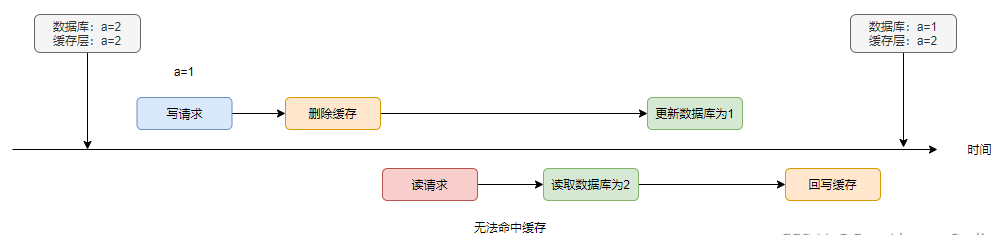
寫請求刪除緩存后,讀請求無法命中緩存,因此讀到數(shù)據(jù)庫的舊值2。寫請求更新完數(shù)據(jù)庫后,讀請求再將1回寫進緩存,同樣存在刷臟的風(fēng)險。
如果a永不過期的且后續(xù)沒有執(zhí)行寫請求的話,那么讀到的一直都是臟數(shù)據(jù),因此我們一般都會設(shè)置緩存的過期時間,作為一種兜底策略。在a過期后,就會重新從數(shù)據(jù)庫中讀取。
該問題發(fā)生的概率一般會高于方案4,那如何去解決呢?
可不可以主動讓臟數(shù)據(jù)過期,也就是讓寫請求再刪一次緩存呢?
可以的,這種方案稱作為延時雙刪。
方案6 延時雙刪
在方案5的第2個案例圖上進行修改:在讀請求刷臟后,寫請求再次刪除緩存。
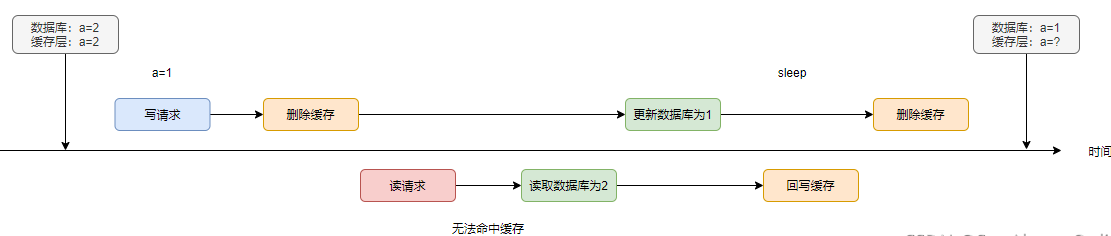
此方案的難點在于,sleep的時間該怎么去確定。如果偏大,同步刪除的話會造成吞吐量的降低與查臟。如果偏小,則有可能第二次刪除在刷臟之前發(fā)生,起不到“雙刪”的作用。
因此,我們需要結(jié)合業(yè)務(wù)對sleep的時間做出評估。一般來說,sleep的時間應(yīng)該稍大于讀請求查詢數(shù)據(jù)與回寫緩存的時間。
延時雙刪,對使用讀寫分離,主從同步的數(shù)據(jù)庫也有奇效。
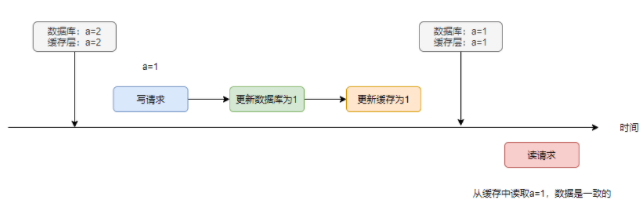
在主從同步正常且沒有出現(xiàn)讀寫并發(fā)的情況下,數(shù)據(jù)庫與緩存是一致的
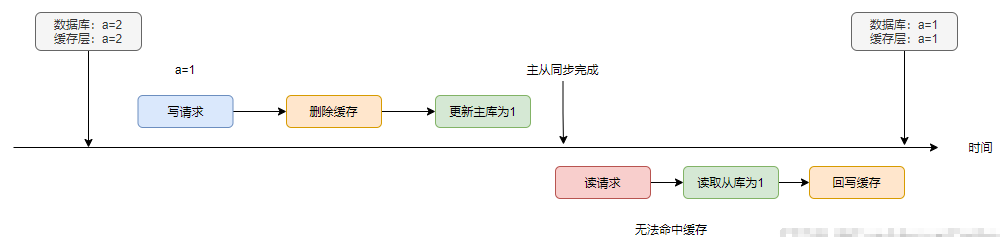
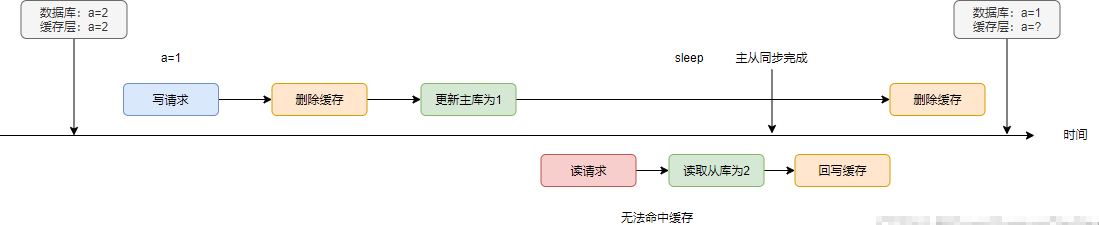
如果主從同步存在延遲呢?導(dǎo)致讀請求讀到a=2,最終會造成不一致的情況
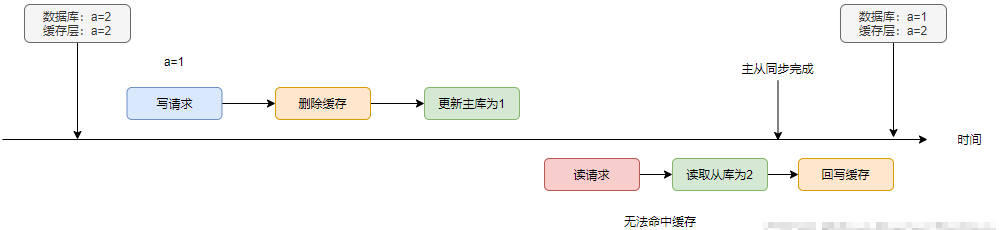
如果使用延時雙刪,就可以有效解決
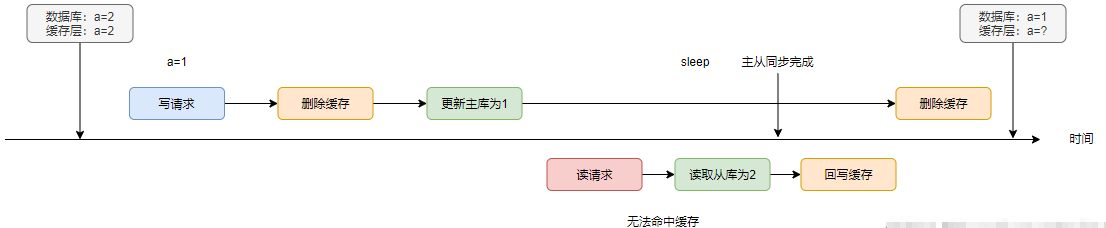
不過這里的sleep時間=讀請求的查詢從庫時間+回寫緩存時間+主從同步的延遲時間
不過為了規(guī)避主從同步延遲造成的數(shù)據(jù)庫與緩存的不一致,可以強迫寫之后的快速讀走主庫。
不過這里還是希望大家,多去了解可能造成主從同步延遲的原因,例如從庫性能差,本地重放sql進度慢;從庫數(shù)量少,造成大量讀之下占用全部cpu;從庫是否正在執(zhí)行DDL語句或者慢查詢等。
延時雙刪看起來趨于完美了,但較真的同學(xué)始終不認(rèn)賬。
- 延時是使用同步的延時,造成吞吐量降低怎么辦?
- 雙刪中第二次刪除怎么辦?
對于第一個問題,可以將第二次刪除改為異步的。
對于第二個問題,可以將第二次刪除改為可重試的。
其實第二個問題,也存在于方案4中,即先更新數(shù)據(jù)庫,再刪除緩存。
我們拿方案4進行優(yōu)化,可以引入消息中間件。
方案7 消息隊列
先更新數(shù)據(jù)庫,接著將刪除緩存的消息投遞到mq中。自身拿到消息后,嘗試進行刪除緩存。如果失敗,則不斷進行重試。
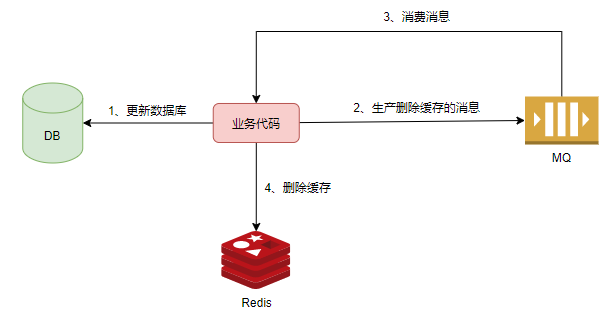
引入了消息隊列,系統(tǒng)的復(fù)雜性提升,可用性降低。
也會帶來各種各樣的問題,例如消息丟失、亂序與重復(fù)消費等。亂序與重復(fù)消費的問題,在刪除緩存的場景下,不會造成任何問題。
不過如果一條刪除緩存的消息的丟失,將會導(dǎo)致在緩存過期前出現(xiàn)數(shù)據(jù)不一致的情況。
這里稍微帶一下mq中如何保證消息不丟失的措施:需要生產(chǎn)端、mq自身與消費端共同去保障。
- 生產(chǎn)端,對生產(chǎn)的消息進行狀態(tài)標(biāo)記,開啟confirm機制,依據(jù)mq的響應(yīng)來更新消息狀態(tài),使用定時任務(wù)重新投遞超時的消息,多次投遞失敗進行報警。
- mq自身,開啟持久化,并在落盤后再進行ack。如果是鏡像部署模式,需要在同步到多個副本之后再進行ack。
- 消費端,開啟手動ack模式,在業(yè)務(wù)處理完成后再進行ack,并且需要保證冪等。
通過以上的處理,理論上不存在消息丟失的情況,但是系統(tǒng)的吞吐量以及性能有所下降。
如果想要詳細(xì)了解如何在各個階段保證消息不丟失,可以移步我的另外一篇文章RabbitMQ如何在各個環(huán)節(jié)保證消息不丟失
引入消息隊列,帶來了可以異步重試的好處,但同時需要通過多種機制去保證刪除消息不丟失。此外,該方案會對業(yè)務(wù)代碼造成一定的侵入。
方案8 消息隊列+訂閱binlog
業(yè)務(wù)代碼只操作數(shù)據(jù)庫,不操作緩存。同時啟動一個訂閱binlog的程序去監(jiān)聽刪除操作,然后投遞到消息隊列中。再啟動一個消費者,根據(jù)消息去刪除緩存。
對binlog不熟悉的同學(xué),可以參考我的另外一篇文章數(shù)據(jù)庫日志——binlog、redo log、undo log掃盲
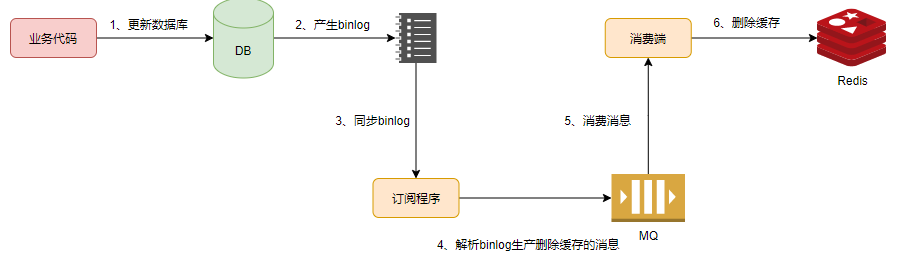
在MySQL中,可以使用canal中間件來訂閱binlog。
在該方案中,再次使用一個中間件來幫我們完成解耦工作,但系統(tǒng)的復(fù)雜度確實也在逐步上升。
總結(jié)
給緩存設(shè)置過期時間
簡單直接,適用于對數(shù)據(jù)一致性要求較低或者寫請求很少的業(yè)務(wù)
先更新數(shù)據(jù)庫,再更新緩存
先更新緩存,再更新數(shù)據(jù)庫
- 寫多讀少時,頻繁更新緩存會降低性能
- 并發(fā)情況下可能存在將臟數(shù)據(jù)寫回緩存的風(fēng)險
先更新數(shù)據(jù)庫,再刪除緩存
- 極低概率在讀寫并發(fā)時發(fā)生刷臟
先刪除緩存,再更新數(shù)據(jù)庫
- 較低概率在讀寫并發(fā)時發(fā)生刷臟
延時雙刪
- sleep的由業(yè)務(wù)評估,稍大于讀請求的查詢數(shù)據(jù)庫與回寫緩存的時間
- 對主從同步延遲也有奇效
- 存在第二次刪除失敗的情況
消息隊列
- 對刪除失敗的消息進行異步重試
- 會對業(yè)務(wù)代碼造成一定的侵入
消息隊列+訂閱binlog
- 解耦
- 系統(tǒng)復(fù)雜度上升
最后
以上的所有方案,都是盡可能的保證數(shù)據(jù)庫與緩存的一致性,也就是最終一致性。
如果使用CAP理論來看待這個由業(yè)務(wù)代碼+數(shù)據(jù)庫+緩存組成的分布式系統(tǒng),首先該系統(tǒng)必須要能容忍網(wǎng)絡(luò)分區(qū),其次對于覺得部分的場景,該分布式系統(tǒng)應(yīng)當(dāng)也需要滿足可用性。也就是說,緩存節(jié)點宕機后或出現(xiàn)網(wǎng)絡(luò)閃斷,整個系統(tǒng)應(yīng)當(dāng)還能夠?qū)ν馓峁┓?wù)。根據(jù)CAP定理,該系統(tǒng)就無法滿足強一致性。對CAP不熟悉的同學(xué),可以參考我的另外一篇文章常說的分布式系統(tǒng)核心理論CAP與BASE到底是什么
如果就要保證強一致性,例如使用Raft方案來做強一致。如果能做到強一致,那么整個系統(tǒng)的性能就會大打折扣。使用到緩存,就會為了提升性能。因此,強一致一般與提升性能是背道而馳的。當(dāng)然,緩存是有過期時間的,這種兜底操作將徹底避免永遠(yuǎn)出現(xiàn)不一致的情況。
對分布式一致性算法Raft不了解的同學(xué),可以參考我的另外一篇文章22張圖,帶你入門分布式一致性算法Raft
從方案1到方案8,系統(tǒng)的復(fù)雜性逐步上升,但確實能解決一些痛點,例如同步刪除性能差,第二次刪除失敗等等。
但是并不存在誰最好誰最差,應(yīng)當(dāng)結(jié)合業(yè)務(wù)來看,脫離業(yè)務(wù)談技術(shù)就是一場空談。
作為技術(shù)人員,我們應(yīng)當(dāng)根據(jù)業(yè)務(wù)場景選擇相應(yīng)的技術(shù),但前提是對各種技術(shù)都有較深的理解,能分析其利弊。
我覺得技術(shù)人員的最好的歸宿,就是能在不斷解決問題的過程中,形成自己的方法論與解決方案。例如形成開源作品或技術(shù)博客,去影響別人。