













【51CTO.com快譯】從Go到星際爭霸再到Dota,很多人工智能研究人員正在致力創建強化學習(RL)系統,希望人工智能能夠在復雜的游戲中擊敗人類。但人工智能面臨的更大挑戰是創建可以與人類合作而不是競爭的系統。
DeepMind公司的人工智能研究人員開發了一種新技術,以提高DL代理與不同技能水平的人類合作的能力。該技術在2020年度NeurIPS會議上推出,其名稱為Fictitious Co-Play(FCP),它不需要人工生成的數據來訓練強化DL代理。
在使用解謎游戲Overcooked進行測試時,FCP創建了DL代理,在與人類玩家合作時可以提供更好的結果并減少混亂。這種技術為人工智能系統的未來研究提供重要方向。
訓練DL代理
強化學習(RL)可以不知疲倦地學習任何具有明確獎勵、動作和狀態的任務。如果有足夠的計算能力和時間,DL代理可以利用其環境學習一系列動作或“策略”,從而最大化其獎勵。事實證明,DL在玩游戲時非常有效。
但通常情況下,DL代理學習的策略與人類玩法不兼容。當與人類合作時,它們執行的操作會讓人們感到困惑,這使得它們難以在需要人類共同規劃和分工的應用中使用。彌合人工智能與人類之間的差距已成為人工智能社區的重要挑戰。
研究人員正在尋找方法來創建能夠適應各種合作伙伴(包括其他DL代理和人類)習慣的多功能DL代理。
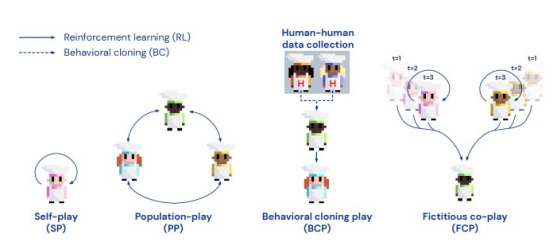
訓練DL代理的不同方法
為游戲訓練DL代理的傳統方法是自我對弈(SP),其中DL代理不斷地與自己的副本對戰。自我對弈(SP) 可以非常有效地快速學習策略,使游戲的回報最大化,但由此產生的DL模型過度擬合了自己的游戲玩法,而與以不同方式訓練的成員合作的結果是很糟糕的。
另一種訓練方法是群體游戲(PP),它訓練DL代理以及具有不同參數和架構的各種合作伙伴。群體游戲(PP)代理在競技游戲中與人類合作的效果比自我對弈(SP)要好得多。但它們仍然缺乏共同回報設置所需的多樣性,在這種情況下,玩家必須共同解決問題并根據環境的變化協調他們的策略。
另一種選擇是行為克隆游戲(BCP),它使用人工生成的數據來訓練DL代理。BCP模型不是從隨機探索環境開始,而是根據從人類游戲中收集的數據來調整參數。這些代理開發的行為更接近于人類發現的游戲模式。如果數據是從具有不同技能水平和游戲風格的不同用戶中收集的,DL代理可以更靈活地適應合作伙伴的行為。因此,它們更有可能與人類玩家兼容。然而,生成人類數據具有挑戰性,特別是因為DL模型通常需要大量練習能達到最佳設置的情況下。
FCP
DeepMind公司新推出的DL技術FCP的主要思想是創建代理,可以幫助具有不同風格和技能水平的玩家,而無需依賴人工生成的數據。
FCP培訓分兩個階段進行:在第二階段,DeepMind的研究人員創建了一組自我對弈DL代理。這種代理是獨立訓練的,并且具有不同的初始條件。因此它們會集中在不同的參數設置上,并創建一個多樣化的DL代理池。為了使代理池的技能水平多樣化,研究人員在訓練過程的不同階段保存了每個代理的快照。
研究人員在論文中指出,“最后一個檢查點代表一個訓練有素的‘熟練’伙伴,而較早的檢查點代表不太熟練的伙伴。值得注意的是,通過為每個合作伙伴使用多個檢查點,這種額外的技能多樣性不會導致額外的培訓成本。”
在第二階段,以代理池中的所有代理作為其合作伙伴訓練新的DL模型。這樣,新代理必須調整其策略才能與具有不同參數值和技能水平的合作伙伴合作。DeepMind公司的研究人員寫道:“FCP代理將跟隨人類伙伴的腳步,并學習一系列策略和技能的通用策略。
測試FCP
DeepMind公司的人工智能研究人員將FCP應用于Overcooked,這是一款解謎游戲,玩家必須在網格世界中移動,與其他玩家互動,并執行一系列步驟來進行烹飪和送餐。Overcooked游戲很有趣,因為它具有非常簡單的動態,但同時需要隊友之間的協調和勞動力分配。
為了測試FCP,DeepMind公司簡化了Overcooked以包含在整個游戲中執行的任務的子集。人工智能研究人員還包括一系列精心挑選的地圖,這些地圖提出了各種挑戰,例如強制協調和狹窄的空間。
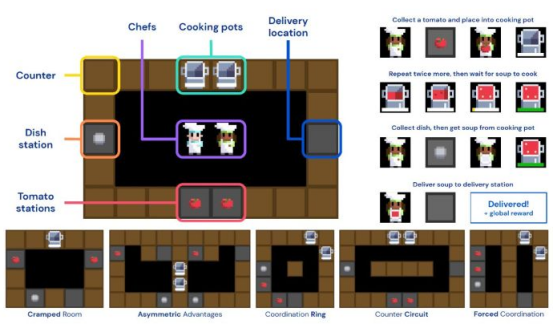
DeepMind使用簡化版的Overcooked來測試DL與FCP
研究人員訓練了一組SP、PP、BCP和FCP代理。為了比較他們的表現,他們首先針對三組玩家測試了每種DL代理類型,其中包括一個基于人類游戲數據訓練的行為克隆(BC)模型、一組在不同技能水平上訓練的SP代理,以及代表低技能的隨機初始化代理。他們根據在相同數量的回合中提供的食數物量來衡量表現。
他們的研究結果表明,FCP的表現明顯優于所有其他類型的DL代理,這表明它在各種技能水平和游戲風格中都能很好地概括。此外,令人驚訝的發現之一是其他訓練方法非常脆弱。研究人員寫道:“這表明,他們可能無法與技術水平不高的代理合作。”
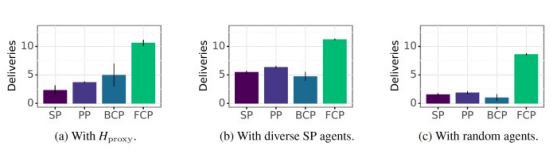
FCP優于其他訓練DL代理的方法
然后,他們測試了每種類型的RL代理與人類玩家合作時的表現。研究人員對114名人類玩家進行了一項在線研究,每人都玩了20個回合。在每一回合中,玩家都被放置在一個隨機的廚房中,并在不知道是哪種類型的情況下與其中一個RL玩家組隊。
根據DeepMind的實驗結果,人類與FCP的組合表現優于所有其他類型的RL代理。
在每兩個回合之后,參與者以1~5的分數對他們與RL代理的體驗進行評分。參與者對FCP的偏好明顯高于其他代理,他們的反饋表明FCP的行為更加連貫、可預測和適應性強。例如,RL代理似乎知道其隊友的行為,并通過在每個烹飪環境中選擇特定角色來防止混淆。
另一方面,調查參與者將其他DL代理的行為描述為“混亂且難以適應”。

DeepMind將人類玩家與不同的DL代理進行組合
還有更多的工作要做
研究人員在論文中指出了他們工作的一些局限性。例如,FCP代理接受了32個DL合作伙伴的訓練,這對于Overcooked的淡化版本已經足夠了,但對于更復雜的環境可能會受到限制。DeepMind公司的研究人員寫道:“對于更復雜的游戲,FCP可能需要一個不切實際的龐大合作伙伴群體規模來代表足夠多樣化的策略。”
獎勵的定義是另一個限制FCP在復雜領域使用的挑戰。在Overcooked中,其獎勵簡單而明確。在其他環境中,RL代理必須完成子目標,直到獲得主要獎勵。他們實現子目標的方式需要與人類玩家的方式兼容,這在沒有人類玩家數據的情況下很難評估和調整。研究人員寫道:“如果一項任務的獎勵功能與人類處理任務的方式不一致,那么這種方法很可能會產生低于標準的DL代理,就像任何無法訪問人類數據的方法一樣。”
DeepMind公司的研究是人類與人工智能協作的更廣泛研究的一部分。麻省理工學院科學家最近的一項研究探索了DL代理在與人類玩Hanabi紙牌游戲時的局限性。
DeepMind公司新推出的DL技術是彌合人類和人工智能問題解決之間差距的重要一步,而研究人員希望為研究人機協作造福未來社會奠定堅實的基礎。
原文標題:DeepMind RL method promises better co-op between AI and humans,作者:Ben Dickson
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】




















