













使用AWS云端機器學習,構建無服務器新聞數據管道
譯文【51CTO.com快譯】作為一名分析師,我花很多時間來跟蹤新聞和行業最新資訊。我在休產假時考慮了這個問題,決定構建一個簡單的應用程序來跟蹤有關綠色技術和可再生能源的新聞。使用AWS Lambda及AWS的其他服務(比如EventBridge、SNS、DynamoDB和Sagemaker),可以非常輕松地上手,在幾天內構建好原型。
該應用程序由一系列無服務器Lambda函數和作為SageMaker端點來部署的文本摘要機器學習模型提供支持。AWS EventBridge規則每24小時觸發一次Lambda函數,從DynamoDB數據庫獲取新聞源(feed)。
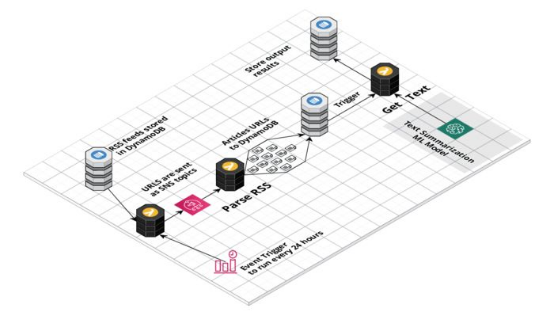
然后這些新聞源作為SNS主題來發送,以觸發多個Lambda分析新聞源并提取新聞URL。每個網站每天更新RSS新聞源最多只更新幾篇文章,因此我們不會發送大批流量,不然可能會導致消耗任何特定新聞出版物的過多資源。
然而,一大問題是提取文章的全文,因為每個網站不一樣。對我們來說幸運的是,goose3之類的庫通過運用機器學習方法提取頁面正文來解決這個問題。由于版權問題,我無法存儲文章的全文,這就是為什么我運用HuggingFace文本摘要轉換器模型來生成簡短摘要。
下面詳細介紹了如何自行構建基于機器學習的新聞聚合管道。
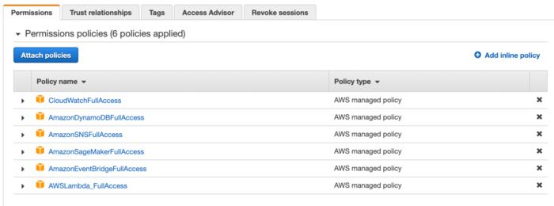
1. 設置擁有必要權限的IAM角色。
雖然這個數據管道很簡單,但它連接許多AWS資源。想授予我們的函數訪問所有所需資源的權限,我們需要設置IAM角色。該角色為函數賦予了使用云端其他資源的權限,比如DynamoDB、Sagemaker、CloudWatch和SNS。出于安全原因,最好不要為我們的IAM角色賦予全面的AWS管理訪問權限,只允許它使用所需的資源。
2. 在RSS Dispatcher Lambda中從DynamoDB獲取RSS新聞源
使用AWS Lambda幾乎可以做任何事情,它是一種非常強大的無服務器計算服務,非常適合短任務。對我而言,主要優點在于很容易訪問AWS生態系統中的其他服務。
我將所有RSS新聞源存儲在DynamoDB表中,使用boto3庫從Lambda訪問它真的很容易。一旦從數據庫獲取所有新聞源后,我將它們作為SNS消息發送,以觸發新聞源解析Lambda。
- import boto3
- import json
- def lambda_handler(event, context):
- # Connect to DynamoDB
- dynamodb = boto3.resource('dynamodb')
- # Get table
- table = dynamodb.Table('rss_feeds')
- # Get all records from the table
- data = table.scan()['Items']
- rss = [y['rss'] for y in data]
- # Connect to SNS
- client = boto3.client('sns')
- # Send messages to the queue
- for item in rss:
- client.publish(TopicArn="arn:aws:sns:eu-west-1:802099603194:rss_to-parse", Message = item)
3. 使用必要的庫創建層
想在AWS Lambdas中使用一些特定庫,您需要將它們作為層來導入。想準備庫導入,它需要位于python.zip壓縮包中,然后我們可以將其上傳到AWS并在函數中使用。想創建層,只需cd進入到Python文件夾中,運行pip install命令,將其壓縮并準備好上傳。
- pip install feedparser -t
然而,我將goose3庫作為一個層來部署時遇到了一些困難。簡單的調查后發現,LXML等一些庫需要在類似Lambda的環境(Linux)中加以編譯。因此如果庫在Windows上編譯,然后導入到函數中,就會發生錯誤。為了解決這個問題,在創建壓縮包之前,我們需要在Linux上安裝該庫。
這有兩種方法。首先,安裝在帶有Docker的模擬Lambda環境上。對我來說,最簡單的方法是使用AWS sam build命令。函數構建后,我只需從構建文件夾中拷貝所需的包,并將它們作為層來上傳。
- sam build --use-container
4. 啟動Lambda函數來解析新聞源
一旦我們將新聞URL作為主題發送到SNS,就可以觸發多個Lambda從RSS新聞源去獲取新聞文章。一些RSS新聞源不一樣,但新聞源解析器庫允許我們使用不同的格式。我們的URL是事件對象的一部分,所以我們需要通過key來提取它。
- import boto3
- import feedparser
- from datetime import datetime
- def lambda_handler(event, context):
- #Connect to DynamoDB
- dynamodb = boto3.resource('dynamodb')
- # Get table
- table = dynamodb.Table('news')
- # Get a url from from event
- url = event['Records'][0]['Sns']['Message']
- # Parse the rss feed
- feed = feedparser.parse(url)
- for item in feed['entries']:
- result = {
- "news_url": item['link'],
- "title": item['title'],
- "created_at": datetime.now().strftime('%Y-%m-%d') # so that dynamodb will be ok with our date
- }
- # Save the result to dynamodb
- table.put_item(Item=result, ConditionExpression='attribute_not_exists(news_url)') # store only unique urls
5. 在Sagemaker上創建和部署文本摘要模型
Sagemaker是一項服務,可讓您輕松在AWS上編寫、訓練和部署機器學習模型。 HuggingFace與AWS合作,使用戶更容易將其模型部署到云端。
這里我在Jupiter notebook中編寫了一個簡單的文本摘要模型,并使用deploy()命令來部署它。
- from sagemaker.huggingface import HuggingFaceModel
- import sagemaker
- role = sagemaker.get_execution_role()
- hub = {
- 'HF_MODEL_ID':'facebook/bart-large-cnn',
- 'HF_TASK':'summarization'
- }
- # Hugging Face Model Class
- huggingface_model = HuggingFaceModel(
- transformers_version='4.6.1',
- pytorch_version='1.7.1',
- py_version='py36',
- env=hub,
- role=role,
- )
- # deploy model to SageMaker Inference
- predictor = huggingface_model.deploy(
- initial_instance_count=1, # number of instances
- instance_type='ml.m5.xlarge' # ec2 instance type
- )
一旦部署完畢,我們可以從Sagemaker -> Inference -> Endpoint configuration獲取端點信息,并用在我們的Lamdas中。
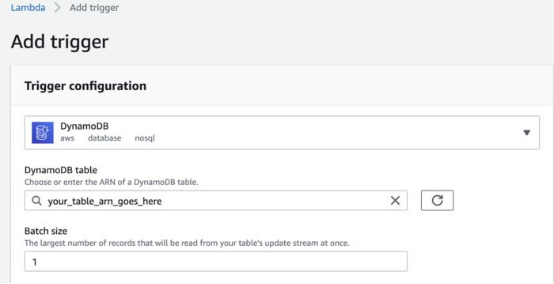
6. 獲取文章的全文、摘要文章并將結果存儲在DynamoDB中
由于版權我們不會存儲全文,這就是為什么所有處理工作都在一個Lambda中進行。一旦URL進入到Dynamo DB表,我啟動了文本處理Lambda。為此,我創建了DynamoDB項生成,作為啟動Lambda的觸發器。我創建了批大小,那樣Lambda每次只處理一篇文章。
- import json
- import boto3
- from goose3 import Goose
- from datetime import datetime
- def lambda_handler(event, context):
- # Get url from DynamoDB record creation event
- url = event['Records'][0]['dynamodb']['Keys']['news_url']['S']
- # fetch article full text
- g = Goose()
- article = g.extract(url=url)
- body = article.cleaned_text # clean article text
- published_date = article.publish_date # from meta desc
- # Create a summary using our HuggingFace text summary model
- ENDPOINT_NAME = "your_model_endpoint"
- runtime= boto3.client('runtime.sagemaker')
- response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType='application/json', Body=json.dumps(data))
- #extract a summary
- summary = json.loads(response['Body'].read().decode())
- #Connect to DynamoDB
- dynamodb = boto3.resource('dynamodb')
- # Get table
- table = dynamodb.Table('news')
- # Update item stored in dynamoDB
- update = table.update_item(
- Key = { "news_url": url }
- ,
- ConditionExpression= 'attribute_exists(news_url) ',
- UpdateExpression='SET summary = :val1, published_date = :val2'
- ExpressionAttributeValues={
- ':val1': summary,
- ':val2': published_date
- }
- )
這就是我們如何使用AWS工具,構建并部署一個簡單的無服務器數據管道以讀取最新新聞的過程。
原文標題:Build a Serverless News Data Pipeline using ML on AWS Cloud,作者:Maria Zentsova
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】



















