Python 實現定時任務的八種方案!
在日常工作中,我們常常會用到需要周期性執行的任務,一種方式是采用 Linux 系統自帶的 crond[1] 結合命令行實現。另外一種方式是直接使用 Python。接下里整理的是常見的 Python 定時任務的實現方式。
利用 while True: + sleep() 實現定時任務
位于 time 模塊中的 sleep(secs) 函數,可以實現令當前執行的線程暫停 secs 秒后再繼續執行。所謂暫停,即令當前線程進入阻塞狀態,當達到 sleep() 函數規定的時間后,再由阻塞狀態轉為就緒狀態,等待 CPU 調度。
基于這樣的特性我們可以通過 while 死循環+sleep() 的方式實現簡單的定時任務。
代碼示例:
- import datetime
- import time
- def time_printer():
- now = datetime.datetime.now()
- ts = now.strftime('%Y-%m-%d %H:%M:%S')
- print('do func time :', ts)
- def loop_monitor():
- while True:
- time_printer()
- time.sleep(5) # 暫停 5 秒
- if __name__ == "__main__":
- loop_monitor()
主要缺點:
- 只能設定間隔,不能指定具體的時間,比如每天早上 8:00
- sleep 是一個阻塞函數,也就是說 sleep 這一段時間,程序什么也不能操作。
使用 Timeloop 庫運行定時任務
Timeloop[2] 是一個庫,可用于運行多周期任務。這是一個簡單的庫,它使用 decorator 模式在線程中運行標記函數。
示例代碼:
- import time
- from timeloop import Timeloop
- from datetime import timedelta
- tl = Timeloop()
- @tl.job(interval=timedelta(seconds=2))
- def sample_job_every_2s():
- print "2s job current time : {}".format(time.ctime())
- @tl.job(interval=timedelta(seconds=5))
- def sample_job_every_5s():
- print "5s job current time : {}".format(time.ctime())
- @tl.job(interval=timedelta(seconds=10))
- def sample_job_every_10s():
- print "10s job current time : {}".format(time.ctime())
利用 threading.Timer 實現定時任務
threading 模塊中的 Timer 是一個非阻塞函數,比 sleep 稍好一點,timer 最基本理解就是定時器,我們可以啟動多個定時任務,這些定時器任務是異步執行,所以不存在等待順序執行問題。
Timer(interval, function, args=[ ], kwargs={ })
- interval: 指定的時間
- function: 要執行的方法
- args/kwargs: 方法的參數
代碼示例:
- import datetime
- from threading import Timer
- def time_printer():
- now = datetime.datetime.now()
- ts = now.strftime('%Y-%m-%d %H:%M:%S')
- print('do func time :', ts)
- loop_monitor()
- def loop_monitor():
- t = Timer(5, time_printer)
- t.start()
- if __name__ == "__main__":
- loop_monitor()
備注:Timer 只能執行一次,這里需要循環調用,否則只能執行一次
利用內置模塊 sched 實現定時任務
sched 模塊實現了一個通用事件調度器,在調度器類使用一個延遲函數等待特定的時間,執行任務。同時支持多線程應用程序,在每個任務執行后會立刻調用延時函數,以確保其他線程也能執行。
class sched.scheduler(timefunc, delayfunc) 這個類定義了調度事件的通用接口,它需要外部傳入兩個參數,timefunc 是一個沒有參數的返回時間類型數字的函數(常用使用的如 time 模塊里面的 time),delayfunc 應該是一個需要一個參數來調用、與 timefunc 的輸出兼容、并且作用為延遲多個時間單位的函數(常用的如 time 模塊的 sleep)。
代碼示例:
- import datetime
- import time
- import sched
- def time_printer():
- now = datetime.datetime.now()
- ts = now.strftime('%Y-%m-%d %H:%M:%S')
- print('do func time :', ts)
- loop_monitor()
- def loop_monitor():
- s = sched.scheduler(time.time, time.sleep) # 生成調度器
- s.enter(5, 1, time_printer, ())
- s.run()
- if __name__ == "__main__":
- loop_monitor()
scheduler 對象主要方法:
- enter(delay, priority, action, argument),安排一個事件來延遲 delay 個時間單位。
- cancel(event):從隊列中刪除事件。如果事件不是當前隊列中的事件,則該方法將跑出一個 ValueError。
- run():運行所有預定的事件。這個函數將等待(使用傳遞給構造函數的 delayfunc() 函數),然后執行事件,直到不再有預定的事件。
個人點評:比 threading.Timer 更好,不需要循環調用。
利用調度模塊 schedule 實現定時任務
schedule[3] 是一個第三方輕量級的任務調度模塊,可以按照秒,分,小時,日期或者自定義事件執行時間。schedule[4] 允許用戶使用簡單、人性化的語法以預定的時間間隔定期運行 Python 函數(或其它可調用函數)。
先來看代碼,是不是不看文檔就能明白什么意思?
- mport schedule
- import time
- def job():
- print("I'm working...")
- schedule.every(10).seconds.do(job)
- schedule.every(10).minutes.do(job)
- schedule.every().hour.do(job)
- schedule.every().day.at("10:30").do(job)
- schedule.every(5).to(10).minutes.do(job)
- schedule.every().monday.do(job)
- schedule.every().wednesday.at("13:15").do(job)
- schedule.every().minute.at(":17").do(job)
- while True:
- schedule.run_pending()
- time.sleep(1)
裝飾器:通過 @repeat() 裝飾靜態方法
- import time
- from schedule import every, repeat, run_pending
- @repeat(every().second)
- def job():
- print('working...')
- while True:
- run_pending()
- time.sleep(1)
傳遞參數:
- import schedule
- def greet(name):
- print('Hello', name)
- schedule.every(2).seconds.do(greet, name='Alice')
- schedule.every(4).seconds.do(greet, name='Bob')
- while True:
- schedule.run_pending()
裝飾器同樣能傳遞參數:
- from schedule import every, repeat, run_pending
- @repeat(every().second, 'World')
- @repeat(every().minute, 'Mars')
- def hello(planet):
- print('Hello', planet)
- while True:
- run_pending()
取消任務:
- import schedule
- i = 0
- def some_task():
- global i
- i += 1
- print(i)
- if i == 10:
- schedule.cancel_job(job)
- print('cancel job')
- exit(0)
- job = schedule.every().second.do(some_task)
- while True:
- schedule.run_pending()
運行一次任務:
- import time
- import schedule
- def job_that_executes_once():
- print('Hello')
- return schedule.CancelJob
- schedule.every().minute.at(':34').do(job_that_executes_once)
- while True:
- schedule.run_pending()
- time.sleep(1)
根據標簽檢索任務:
- # 檢索所有任務:schedule.get_jobs()
- import schedule
- def greet(name):
- print('Hello {}'.format(name))
- schedule.every().day.do(greet, 'Andrea').tag('daily-tasks', 'friend')
- schedule.every().hour.do(greet, 'John').tag('hourly-tasks', 'friend')
- schedule.every().hour.do(greet, 'Monica').tag('hourly-tasks', 'customer')
- schedule.every().day.do(greet, 'Derek').tag('daily-tasks', 'guest')
- friends = schedule.get_jobs('friend')
- print(friends)
根據標簽取消任務:
- # 取消所有任務:schedule.clear()
- import schedule
- def greet(name):
- print('Hello {}'.format(name))
- if name == 'Cancel':
- schedule.clear('second-tasks')
- print('cancel second-tasks')
- schedule.every().second.do(greet, 'Andrea').tag('second-tasks', 'friend')
- schedule.every().second.do(greet, 'John').tag('second-tasks', 'friend')
- schedule.every().hour.do(greet, 'Monica').tag('hourly-tasks', 'customer')
- schedule.every(5).seconds.do(greet, 'Cancel').tag('daily-tasks', 'guest')
- while True:
- schedule.run_pending()
運行任務到某時間:
- import schedule
- from datetime import datetime, timedelta, time
- def job():
- print('working...')
- schedule.every().second.until('23:59').do(job) # 今天 23:59 停止
- schedule.every().second.until('2030-01-01 18:30').do(job) # 2030-01-01 18:30 停止
- schedule.every().second.until(timedelta(hours=8)).do(job) # 8 小時后停止
- schedule.every().second.until(time(23, 59, 59)).do(job) # 今天 23:59:59 停止
- schedule.every().second.until(datetime(2030, 1, 1, 18, 30, 0)).do(job) # 2030-01-01 18:30 停止
- while True:
- schedule.run_pending()
馬上運行所有任務(主要用于測試):
- import schedule
- def job():
- print('working...')
- def job1():
- print('Hello...')
- schedule.every().monday.at('12:40').do(job)
- schedule.every().tuesday.at('16:40').do(job1)
- schedule.run_all()
- schedule.run_all(delay_seconds=3) # 任務間延遲 3 秒
并行運行:使用 Python 內置隊列實現:
- import threading
- import time
- import schedule
- def job1():
- print("I'm running on thread %s" % threading.current_thread())
- def job2():
- print("I'm running on thread %s" % threading.current_thread())
- def job3():
- print("I'm running on thread %s" % threading.current_thread())
- def run_threaded(job_func):
- job_thread = threading.Thread(target=job_func)
- job_thread.start()
- schedule.every(10).seconds.do(run_threaded, job1)
- schedule.every(10).seconds.do(run_threaded, job2)
- schedule.every(10).seconds.do(run_threaded, job3)
- while True:
- schedule.run_pending()
- time.sleep(1)
利用任務框架 APScheduler 實現定時任務
APScheduler[5](advanceded python scheduler)基于 Quartz 的一個 Python 定時任務框架,實現了 Quartz 的所有功能,使用起來十分方便。提供了基于日期、固定時間間隔以及 crontab 類型的任務,并且可以持久化任務。基于這些功能,我們可以很方便的實現一個 Python 定時任務系統。
它有以下三個特點:
- 類似于 Liunx Cron 的調度程序(可選的開始/結束時間)
- 基于時間間隔的執行調度(周期性調度,可選的開始/結束時間)
- 一次性執行任務(在設定的日期/時間運行一次任務)
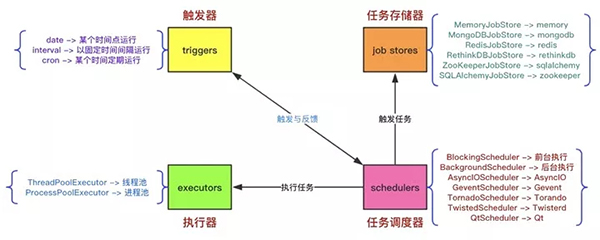
APScheduler 有四種組成部分:
- 觸發器 (trigger) 包含調度邏輯,每一個作業有它自己的觸發器,用于決定接下來哪一個作業會運行。除了他們自己初始配置意外,觸發器完全是無狀態的。
作業存儲 (job store) 存儲被調度的作業,默認的作業存儲是簡單地把作業保存在內存中,其他的作業存儲是將作業保存在數據庫中。一個作業的數據講在保存在持久化作業存儲時被序列化,并在加載時被反序列化。調度器不能分享同一個作業存儲。
- 執行器 (executor) 處理作業的運行,他們通常通過在作業中提交制定的可調用對象到一個線程或者進城池來進行。當作業完成時,執行器將會通知調度器。
- 調度器 (scheduler) 是其他的組成部分。你通常在應用只有一個調度器,應用的開發者通常不會直接處理作業存儲、調度器和觸發器,相反,調度器提供了處理這些的合適的接口。配置作業存儲和執行器可以在調度器中完成,例如添加、修改和移除作業。 通過配置 executor、jobstore、trigger,使用線程池 (ThreadPoolExecutor 默認值 20) 或進程池 (ProcessPoolExecutor 默認值 5) 并且默認最多 3 個 (max_instances) 任務實例同時運行,實現對 job 的增刪改查等調度控制
示例代碼:
- from apscheduler.schedulers.blocking import BlockingScheduler
- from datetime import datetime
- # 輸出時間
- def job():
- print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
- # BlockingScheduler
- sched = BlockingScheduler()
- sched.add_job(my_job, 'interval', seconds=5, id='my_job_id')
- sched.start()
APScheduler 中的重要概念
Job 作業
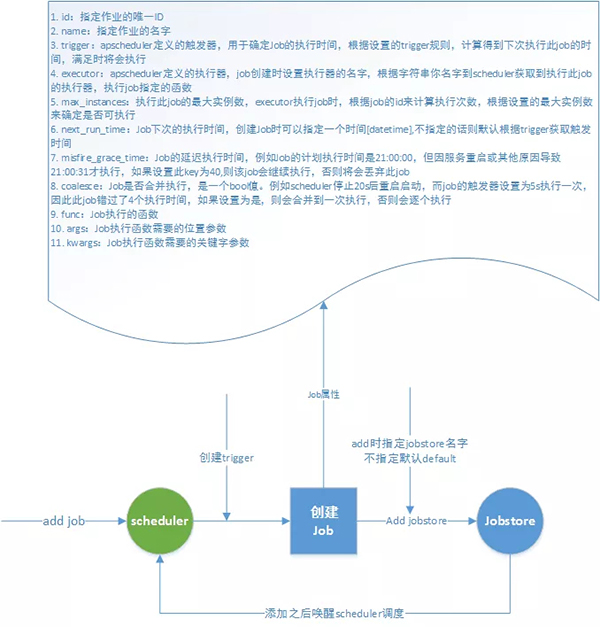
Job 作為 APScheduler 最小執行單位。創建 Job 時指定執行的函數,函數中所需參數,Job 執行時的一些設置信息。
構建說明:
- id:指定作業的唯一 ID
- name:指定作業的名字
- trigger:apscheduler 定義的觸發器,用于確定 Job 的執行時間,根據設置的 trigger 規則,計算得到下次執行此 job 的時間, 滿足時將會執行
- executor:apscheduler 定義的執行器,job 創建時設置執行器的名字,根據字符串你名字到 scheduler 獲取到執行此 job 的 執行器,執行 job 指定的函數
- max_instances:執行此 job 的最大實例數,executor 執行 job 時,根據 job 的 id 來計算執行次數,根據設置的最大實例數來確定是否可執行
- next_run_time:Job 下次的執行時間,創建 Job 時可以指定一個時間 [datetime], 不指定的話則默認根據 trigger 獲取觸發時間
- misfire_grace_time:Job 的延遲執行時間,例如 Job 的計劃執行時間是 21:00:00,但因服務重啟或其他原因導致 21:00:31 才執行,如果設置此 key 為 40, 則該 job 會繼續執行,否則將會丟棄此 job
- coalesce:Job 是否合并執行,是一個 bool 值。例如 scheduler 停止 20s 后重啟啟動,而 job 的觸發器設置為 5s 執行一次,因此此 job 錯過了 4 個執行時間,如果設置為是,則會合并到一次執行,否則會逐個執行
- func:Job 執行的函數
- args:Job 執行函數需要的位置參數
- kwargs:Job 執行函數需要的關鍵字參數
Trigger 觸發器
Trigger 綁定到 Job,在 scheduler 調度篩選 Job 時,根據觸發器的規則計算出 Job 的觸發時間,然后與當前時間比較確定此 Job 是否會被執行,總之就是根據 trigger 規則計算出下一個執行時間。
目前 APScheduler 支持觸發器:
- 指定時間的 DateTrigger
- 指定間隔時間的 IntervalTrigger
- 像 Linux 的 crontab 一樣的 CronTrigger。
觸發器參數:date
date 定時,作業只執行一次。
- run_date (datetime|str) – the date/time to run the job at
- timezone (datetime.tzinfo|str) – time zone for run_date if it doesn’t have one already
- sched.add_job(my_job, 'date', run_date=date(2009, 11, 6), args=['text'])
- sched.add_job(my_job, 'date', run_date=datetime(2019, 7, 6, 16, 30, 5), args=['text'])
觸發器參數:interval
interval 間隔調度
- weeks (int) – 間隔幾周
- days (int) – 間隔幾天
- hours (int) – 間隔幾小時
- minutes (int) – 間隔幾分鐘
- seconds (int) – 間隔多少秒
- start_date (datetime|str) – 開始日期
- end_date (datetime|str) – 結束日期
- timezone (datetime.tzinfo|str) – 時區
- sched.add_job(job_function, 'interval', hours=2)
觸發器參數:cron
cron 調度
- (int|str) 表示參數既可以是 int 類型,也可以是 str 類型
- (datetime | str) 表示參數既可以是 datetime 類型,也可以是 str 類型
- year (int|str) – 4-digit year -(表示四位數的年份,如 2008 年)
- month (int|str) – month (1-12) -(表示取值范圍為 1-12 月)
- day (int|str) – day of the (1-31) -(表示取值范圍為 1-31 日)
- week (int|str) – ISO week (1-53) -(格里歷 2006 年 12 月 31 日可以寫成 2006 年-W52-7(擴展形式)或 2006W527(緊湊形式))
- day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun) – (表示一周中的第幾天,既可以用 0-6 表示也可以用其英語縮寫表示)
- hour (int|str) – hour (0-23) – (表示取值范圍為 0-23 時)
- minute (int|str) – minute (0-59) – (表示取值范圍為 0-59 分)
- second (int|str) – second (0-59) – (表示取值范圍為 0-59 秒)
- start_date (datetime|str) – earliest possible date/time to trigger on (inclusive) – (表示開始時間)
- end_date (datetime|str) – latest possible date/time to trigger on (inclusive) – (表示結束時間)
- timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone) -(表示時區取值)
CronTrigger 可用的表達式:
| 表達式 | 參數類型 | 描述 |
|---|---|---|
| * | 所有 | 通配符。例:minutes=*即每分鐘觸發 |
| * / a | 所有 | 每隔時長 a 執行一次。例:minutes=”* / 3″ 即每隔 3 分鐘執行一次 |
| a – b | 所有 | a – b 的范圍內觸發。例:minutes=“2-5”。即 2 到 5 分鐘內每分鐘執行一次 |
| a – b / c | 所有 | a – b 范圍內,每隔時長 c 執行一次。 |
| xth y | 日 | 第幾個星期幾觸發。x 為第幾個,y 為星期幾 |
| last x | 日 | 一個月中,最后一個星期的星期幾觸發 |
| last | 日 | 一個月中的最后一天觸發 |
| x, y, z | 所有 | 組合表達式,可以組合確定值或上述表達式 |
# 6-8,11-12 月第三個周五 00:00, 01:00, 02:00, 03:00 運行- sched.add_job(job_function, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
- # 每周一到周五運行 直到 2024-05-30 00:00:00
- sched.add_job(job_function, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2024-05-30'
Executor 執行器
Executor 在 scheduler 中初始化,另外也可通過 scheduler 的 add_executor 動態添加 Executor。每個 executor 都會綁定一個 alias,這個作為唯一標識綁定到 Job,在實際執行時會根據 Job 綁定的 executor 找到實際的執行器對象,然后根據執行器對象執行 Job。Executor 的種類會根據不同的調度來選擇,如果選擇 AsyncIO 作為調度的庫,那么選擇 AsyncIOExecutor,如果選擇 tornado 作為調度的庫,選擇 TornadoExecutor,如果選擇啟動進程作為調度,選擇 ThreadPoolExecutor 或者 ProcessPoolExecutor 都可以。Executor 的選擇需要根據實際的 scheduler 來選擇不同的執行器。目前 APScheduler 支持的 Executor:
- executors.asyncio:同步 io,阻塞
- executors.gevent:io 多路復用,非阻塞
- executors.pool: 線程 ThreadPoolExecutor 和進程 ProcessPoolExecutor
- executors.twisted:基于事件驅動
Jobstore 作業存儲
Jobstore 在 scheduler 中初始化,另外也可通過 scheduler 的 add_jobstore 動態添加 Jobstore。每個 jobstore 都會綁定一個 alias,scheduler 在 Add Job 時,根據指定的 jobstore 在 scheduler 中找到相應的 jobstore,并將 job 添加到 jobstore 中。作業存儲器決定任務的保存方式, 默認存儲在內存中(MemoryJobStore),重啟后就沒有了。APScheduler 支持的任務存儲器有:
- jobstores.memory:內存
- jobstores.mongodb:存儲在 mongodb
- jobstores.redis:存儲在 redis
- jobstores.rethinkdb:存儲在 rethinkdb
- jobstores.sqlalchemy:支持 sqlalchemy 的數據庫如 mysql,sqlite 等
- jobstores.zookeeper:zookeeper
不同的任務存儲器可以在調度器的配置中進行配置(見調度器)
Event 事件
Event 是 APScheduler 在進行某些操作時觸發相應的事件,用戶可以自定義一些函數來監聽這些事件,當觸發某些 Event 時,做一些具體的操作。常見的比如。Job 執行異常事件 EVENT_JOB_ERROR。Job 執行時間錯過事件 EVENT_JOB_MISSED。
目前 APScheduler 定義的 Event:
- EVENT_SCHEDULER_STARTED
- EVENT_SCHEDULER_START
- EVENT_SCHEDULER_SHUTDOWN
- EVENT_SCHEDULER_PAUSED
- EVENT_SCHEDULER_RESUMED
- EVENT_EXECUTOR_ADDED
- EVENT_EXECUTOR_REMOVED
- EVENT_JOBSTORE_ADDED
- EVENT_JOBSTORE_REMOVED
- EVENT_ALL_JOBS_REMOVED
- EVENT_JOB_ADDED
- EVENT_JOB_REMOVED
- EVENT_JOB_MODIFIED
- EVENT_JOB_EXECUTED
- EVENT_JOB_ERROR
- EVENT_JOB_MISSED
- EVENT_JOB_SUBMITTED
- EVENT_JOB_MAX_INSTANCES
Listener 表示用戶自定義監聽的一些 Event,比如當 Job 觸發了 EVENT_JOB_MISSED 事件時可以根據需求做一些其他處理。
調度器
Scheduler 是 APScheduler 的核心,所有相關組件通過其定義。scheduler 啟動之后,將開始按照配置的任務進行調度。除了依據所有定義 Job 的 trigger 生成的將要調度時間喚醒調度之外。當發生 Job 信息變更時也會觸發調度。
APScheduler 支持的調度器方式如下,比較常用的為 BlockingScheduler 和 BackgroundScheduler
- BlockingScheduler:適用于調度程序是進程中唯一運行的進程,調用 start 函數會阻塞當前線程,不能立即返回。
- BackgroundScheduler:適用于調度程序在應用程序的后臺運行,調用 start 后主線程不會阻塞。
- AsyncIOScheduler:適用于使用了 asyncio 模塊的應用程序。
- GeventScheduler:適用于使用 gevent 模塊的應用程序。
- TwistedScheduler:適用于構建 Twisted 的應用程序。
- QtScheduler:適用于構建 Qt 的應用程序。
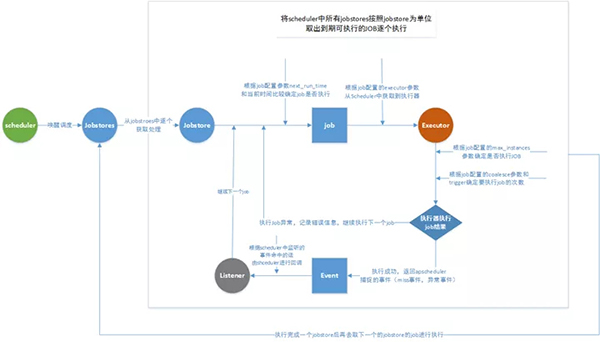
Scheduler 的工作流程
Scheduler 添加 job 流程:
Scheduler 調度流程:
使用分布式消息系統 Celery 實現定時任務
Celery[6] 是一個簡單,靈活,可靠的分布式系統,用于處理大量消息,同時為操作提供維護此類系統所需的工具,也可用于任務調度。Celery 的配置比較麻煩,如果你只是需要一個輕量級的調度工具,Celery 不會是一個好選擇。
Celery 是一個強大的分布式任務隊列,它可以讓任務的執行完全脫離主程序,甚至可以被分配到其他主機上運行。我們通常使用它來實現異步任務(async task)和定時任務(crontab)。異步任務比如是發送郵件、或者文件上傳,圖像處理等等一些比較耗時的操作 ,定時任務是需要在特定時間執行的任務。
需要注意,celery 本身并不具備任務的存儲功能,在調度任務的時候肯定是要把任務存起來的,因此在使用 celery 的時候還需要搭配一些具備存儲、訪問功能的工具,比如:消息隊列、Redis 緩存、數據庫等。官方推薦的是消息隊列 RabbitMQ,有些時候使用 Redis 也是不錯的選擇。
它的架構組成如下圖:
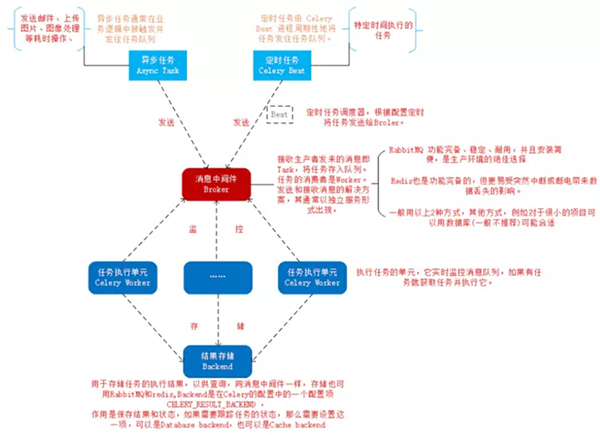
Celery 架構,它采用典型的生產者-消費者模式,主要由以下部分組成:
- Celery Beat,任務調度器,Beat 進程會讀取配置文件的內容,周期性地將配置中到期需要執行的任務發送給任務隊列。
- Producer:需要在隊列中進行的任務,一般由用戶、觸發器或其他操作將任務入隊,然后交由 workers 進行處理。調用了 Celery 提供的 API、函數或者裝飾器而產生任務并交給任務隊列處理的都是任務生產者。
- Broker,即消息中間件,在這指任務隊列本身,Celery 扮演生產者和消費者的角色,brokers 就是生產者和消費者存放/獲取產品的地方(隊列)。
- Celery Worker,執行任務的消費者,從隊列中取出任務并執行。通常會在多臺服務器運行多個消費者來提高執行效率。
- Result Backend:任務處理完后保存狀態信息和結果,以供查詢。Celery 默認已支持 Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy 等方式。
實際應用中,用戶從 Web 前端發起一個請求,我們只需要將請求所要處理的任務丟入任務隊列 broker 中,由空閑的 worker 去處理任務即可,處理的結果會暫存在后臺數據庫 backend 中。我們可以在一臺機器或多臺機器上同時起多個 worker 進程來實現分布式地并行處理任務。
Celery 定時任務實例:
- Python Celery & RabbitMQ Tutorial[7]
- Celery 配置實踐筆記[8]
使用數據流工具 Apache Airflow 實現定時任務
Apache Airflow[9] 是 Airbnb 開源的一款數據流程工具,目前是 Apache 孵化項目。以非常靈活的方式來支持數據的 ETL 過程,同時還支持非常多的插件來完成諸如 HDFS 監控、郵件通知等功能。Airflow 支持單機和分布式兩種模式,支持 Master-Slave 模式,支持 Mesos 等資源調度,有非常好的擴展性。被大量公司采用。
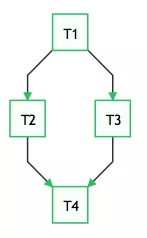
Airflow 使用 Python 開發,它通過 DAGs(Directed Acyclic Graph, 有向無環圖)來表達一個工作流中所要執行的任務,以及任務之間的關系和依賴。比如,如下的工作流中,任務 T1 執行完成,T2 和 T3 才能開始執行,T2 和 T3 都執行完成,T4 才能開始執行。
Airflow 提供了各種 Operator 實現,可以完成各種任務實現:
- BashOperator – 執行 bash 命令或腳本。
- SSHOperator – 執行遠程 bash 命令或腳本(原理同 paramiko 模塊)。
- PythonOperator – 執行 Python 函數。
- EmailOperator – 發送 Email。
- HTTPOperator – 發送一個 HTTP 請求。
- MySqlOperator, SqliteOperator, PostgresOperator, MsSqlOperator, OracleOperator, JdbcOperator, 等,執行 SQL 任務。
- DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator…
除了以上這些 Operators 還可以方便的自定義 Operators 滿足個性化的任務需求。
一些情況下,我們需要根據執行結果執行不同的任務,這樣工作流會產生分支。如:
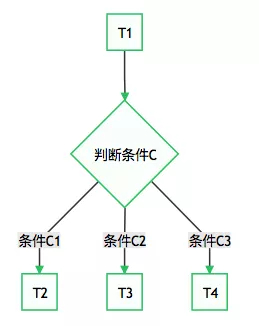
這種需求可以使用 BranchPythonOperator 來實現。
Airflow 產生的背景
通常,在一個運維系統,數據分析系統,或測試系統等大型系統中,我們會有各種各樣的依賴需求。包括但不限于:
- 時間依賴:任務需要等待某一個時間點觸發。
- 外部系統依賴:任務依賴外部系統需要調用接口去訪問。
- 任務間依賴:任務 A 需要在任務 B 完成后啟動,兩個任務互相間會產生影響。
- 資源環境依賴:任務消耗資源非常多, 或者只能在特定的機器上執行。
crontab 可以很好地處理定時執行任務的需求,但僅能管理時間上的依賴。Airflow 的核心概念 DAG(有向無環圖)—— 來表現工作流。
- Airflow 是一種 WMS,即:它將任務以及它們的依賴看作代碼,按照那些計劃規范任務執行,并在實際工作進程之間分發需執行的任務。
- Airflow 提供了一個用于顯示當前活動任務和過去任務狀態的優秀 UI,并允許用戶手動管理任務的執行和狀態。
- Airflow 中的工作流是具有方向性依賴的任務集合。
- DAG 中的每個節點都是一個任務,DAG 中的邊表示的是任務之間的依賴(強制為有向無環,因此不會出現循環依賴,從而導致無限執行循環)。
Airflow 核心概念
- DAGs:即有向無環圖 (Directed Acyclic Graph),將所有需要運行的 tasks 按照依賴關系組織起來,描述的是所有 tasks 執行順序。
- Operators:可以簡單理解為一個 class,描述了 DAG 中某個的 task 具體要做的事。其中,airflow 內置了很多 operators,如 BashOperator 執行一個 bash 命令,PythonOperator 調用任意的 Python 函數,EmailOperator 用于發送郵件,HTTPOperator 用于發送 HTTP 請求, SqlOperator 用于執行 SQL 命令等等,同時,用戶可以自定義 Operator,這給用戶提供了極大的便利性。
- Tasks:Task 是 Operator 的一個實例,也就是 DAGs 中的一個 node。
- Task Instance:task 的一次運行。Web 界面中可以看到 task instance 有自己的狀態,包括”running”, “success”, “failed”, “skipped”, “up for retry”等。
- Task Relationships:DAGs 中的不同 Tasks 之間可以有依賴關系,如 Task1 >> Task2,表明 Task2 依賴于 Task2 了。通過將 DAGs 和 Operators 結合起來,用戶就可以創建各種復雜的 工作流(workflow)。
Airflow 的架構
在一個可擴展的生產環境中,Airflow 含有以下組件:
- 元數據庫:這個數據庫存儲有關任務狀態的信息。
- 調度器:Scheduler 是一種使用 DAG 定義結合元數據中的任務狀態來決定哪些任務需要被執行以及任務執行優先級的過程。調度器通常作為服務運行。
- 執行器:Executor 是一個消息隊列進程,它被綁定到調度器中,用于確定實際執行每個任務計劃的工作進程。有不同類型的執行器,每個執行器都使用一個指定工作進程的類來執行任務。例如,LocalExecutor 使用與調度器進程在同一臺機器上運行的并行進程執行任務。其他像 CeleryExecutor 的執行器使用存在于獨立的工作機器集群中的工作進程執行任務。
- Workers:這些是實際執行任務邏輯的進程,由正在使用的執行器確定。
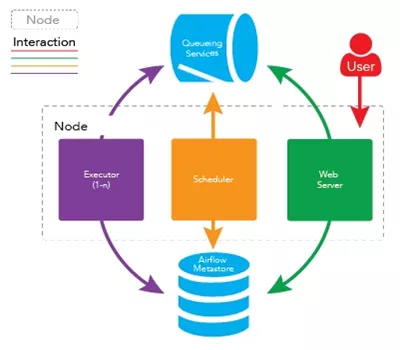
Worker 的具體實現由配置文件中的 executor 來指定,airflow 支持多種 Executor:
- SequentialExecutor: 單進程順序執行,一般只用來測試
- LocalExecutor: 本地多進程執行
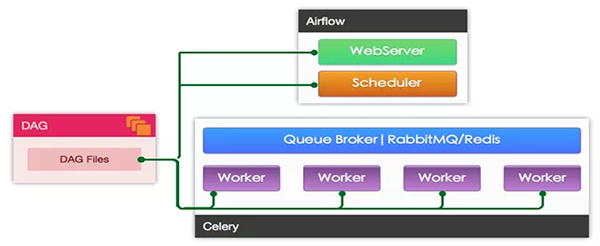
- CeleryExecutor: 使用 Celery 進行分布式任務調度
- DaskExecutor:使用 Dask[10] 進行分布式任務調度
- KubernetesExecutor: 1.10.0 新增,創建臨時 POD 執行每次任務
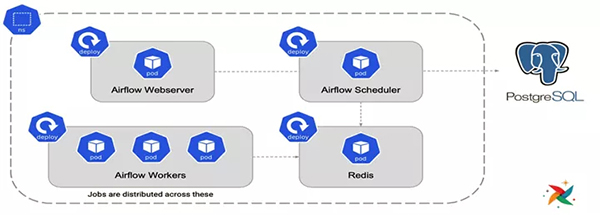
生產環境一般使用 CeleryExecutor 和 KubernetesExecutor。
使用 CeleryExecutor 的架構如圖:
使用 KubernetesExecutor 的架構如圖: