













RocketMQ Consumer 啟動時都干了些啥?
可能我們對 RocketMQ 的消費者認知乍一想很簡單,就是一個拿來消費消息的客戶端而已,你只需要指定對應的 Topic 和 ConsumerGroup,剩下的就是只需要:
- 接收消息
- 處理消息
就完事了。
簡略消費模型
當然,可能在實際業務場景下,確實是這樣。但是如果我們不清楚 Consumer 啟動之后到底會做些什么,底層的實現的一些細節,在面對復雜業務場景時,排查起來就會如同大海撈針般迷茫。
相反,你如果了解其中的細節,那么在排查問題時就會有更多的上下文,就有可能會提出更多的解決方案。
關于 RocketMQ 的一些基礎概念、一些底層實現之前都已在文章 RocketMQ基礎概念剖析&源碼解析 中寫過了,沒有相關上下文的可以先去補齊一部分。
簡單示例
整體邏輯
首先我們還是從一個簡單的例子來看一下,RocketMQ Consumer 的基本使用。從使用入手,一點點了解細節。
- public class Consumer {
- public static void main(String[] args) throws InterruptedException, MQClientException {
- DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_4");
- consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
- consumer.subscribe("TopicTest", "*");
- consumer.registerMessageListener(new MessageListenerConcurrently() {
- @Override
- public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
- ConsumeConcurrentlyContext context) {
- System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
- return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
- }
- });
- consumer.start();
- System.out.printf("Consumer Started.%n");
- }
- }
代碼看著肯定有些難度,下面的流程圖和上面的代碼邏輯等價,可以結合著一起看。
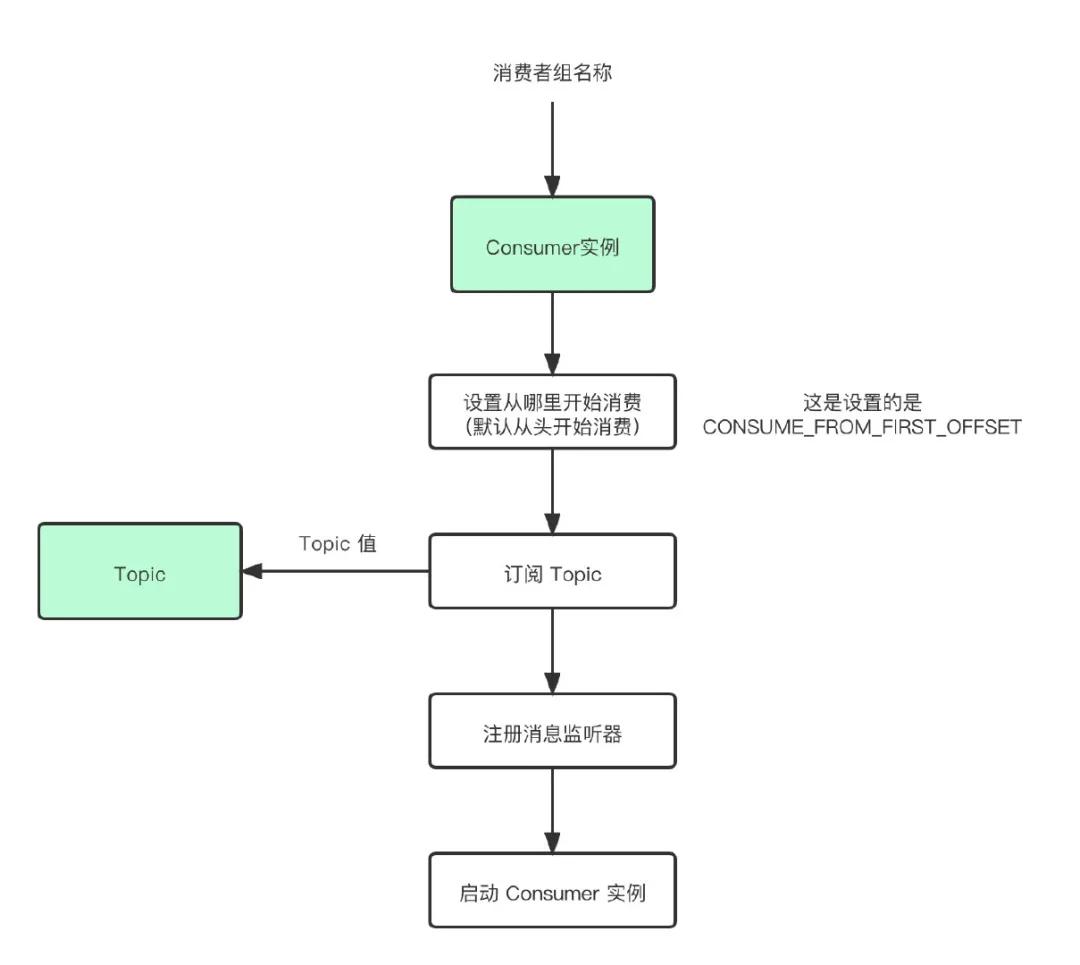
Consumer使用示例
消費點策略
這里除了像 Topic、注冊消息監聽器這種常規的內容之外,setConsumeFromWhere 值得我們更多的關注。它決定了消費者將從哪里開始消費,可選的值有三個:
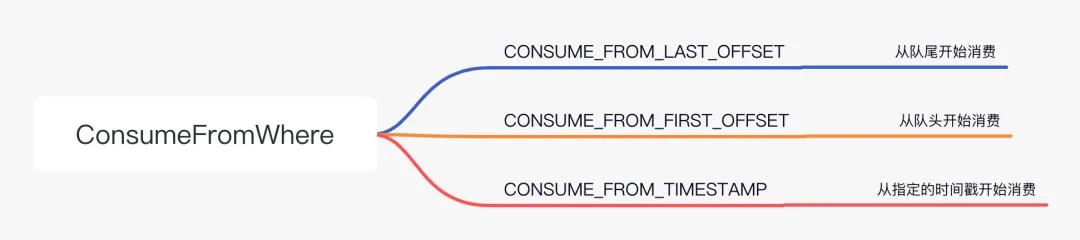
三個可選的 ConsumeFromWhere 的值
實際上 ConsumeFromWhere 的枚舉類源碼中還有另外三個值,但是已經被棄用了。但是這個配置僅對新的 ConsumerGroup 有效,已經存在的 ConsumerGroup 會繼續按照上次消費到的 Offset 繼續消費。
其實也很好理解,假設有 1000 條消息,你的服務已經消費到了 500 條了,然后你上線新的東西將服務重新啟動,然后又從頭開始消費了?這不扯嗎?
緩存訂閱的 Topic 信息
看起來就一行 consumer.subscribe("TopicTest", "*"),實際上背后做了很多事情,這里先給大家把簡單的流程畫出來。
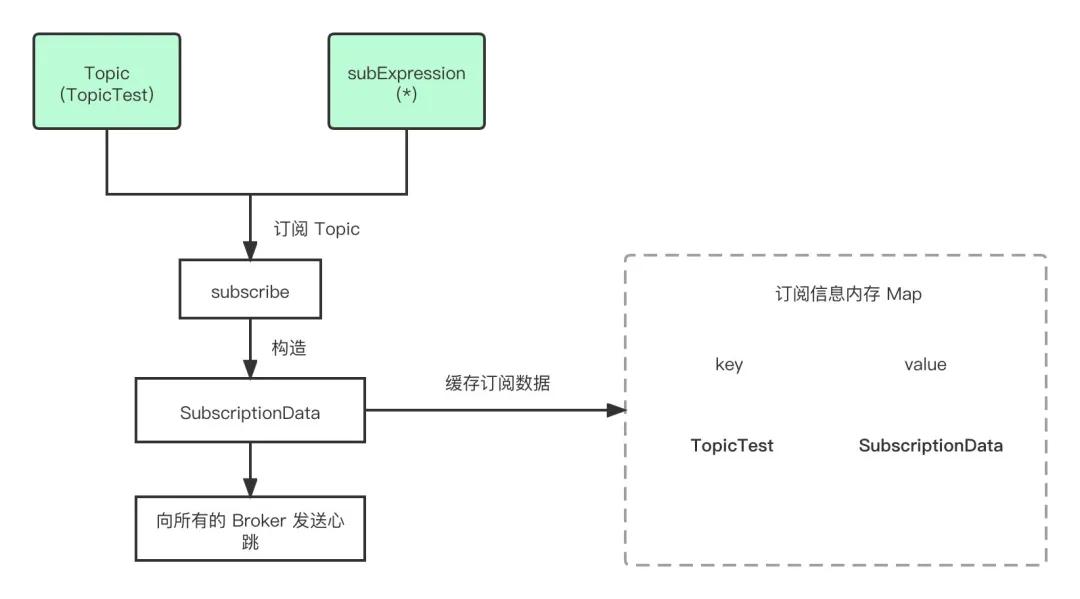
subscribe_topic
subscribe 函數的第一個參數就是我們需要消費的 Topic,這個自不必多說。第二個參數說復雜點叫過濾表達式字符串,說簡單點其實就是你要訂閱的消息的 Tag。
每個消息都會有一個自己的 Tag 這個如果你不清楚的話,可以考慮去看看上面那篇文章
這里我們傳的是 *,代表訂閱所有類別的消息。當然我們也可以傳入 tagA || tagB || tagC 這種,代表我們只消費打了這三種 Tag 的消息。
RocketMQ 會根據我們傳入的這兩個參數,構造出 SubscriptionData ,放入一個位于內存的 ConcurrentHashMap 中維護起來,簡單來說就一句話,把這個訂閱的 Topic 緩存下來。
在緩存完之后會進行一個比較關鍵的操作,那就是開始向所有的 Broker 發送心跳。Consumer 客戶端會將:
- 消費者的名稱
- 消費類型 代表是通過 Push 或者 Pull 的模式消費消息
- 消費模型 指集群消費(CLUSTERING)或者是廣播消費(BROADCASTING)
- 消費點策略 也就是類似 CONSUME_FROM_LAST_OFFSET 這種
- 消費者的訂閱數據集合 一個消費者可以監聽多個 Topic
- 生產者的集合 當前實例上注冊的生產的集合
沒錯,在 Consumer 實例啟動之后還會去運行 Producer 的相關代碼。此外,如果一個客戶端即沒有配置生產者、也沒有配置消費者,那么是不會執行心跳的邏輯的,因為沒有意義。
啟動消費者實例
上文提到的核心邏輯其實都在這里,我們在下面詳細討論,所以簡單示例到這里就結束了。
進入啟動核心邏輯
在啟動的核心入口類中,總共對 4 種狀態進行了分別處理,分別是:
- CREATE_JUST
- RUNNING
- START_FAILED
- SHUTDOWN_ALREADY
但我們由于是剛剛創建,會走到 CREATE_JUST 的邏輯中來,我們就重點來看 Consumer 剛剛啟動時會做些什么。
檢查配置
基操,跟我們平時寫的業務代碼沒有什么兩樣,檢查配置中的各種參數是否合法。
配置項太多了就不贅述,大家只需要知道 RocketMQ 啟動的時候會對配置中的參數進行校驗就知道了。
算了,還是列一列吧:
- 消費者組的名稱是不是空
- 消費者組的名稱不能是被 RocketMQ 保留使用的名稱,即 —— DEFAULT_CONSUMER
- 消費模型(CLUSTERING、BROADCASTING)是否有配置
- 消費點策略(例如 CONSUME_FROM_LAST_OFFSET)是否配置
- 判斷消費的方式是否合法,只能是順序消費或者并發消費
- 消費者組的最小消費線程、最大消費線程數量是否在規定的范圍內,這個范圍是指(1, 1000),左開右開。還有就是最小不能大于最大這種判斷
- ......等等等等
所以你看到了, 即使是牛X的開源框架也會有這種繁瑣的、常見的業務代碼。
改變實例名稱
instanceName 會從系統的配置項 rocketmq.client.name 中獲取,如果沒有配置就會設置為 DEFAULT。,并且消費模型是 CLUSTERING(默認情況就是),就會將 DEFAULT 改成 ${PID}#${System.nanoTime()} 的字符串,這里舉個例子。
- instanceName = "90762#75029316672643"
為什么要單獨把這個提出來講呢?這相當于是給每個實例一個唯一標識,這個唯一標識其實很重要,如果一個消費者組的 instanceName 相同,那么可能就會造成重復消費、或者消息堆積的問題的問題,造成消息堆積的這個點比較有意思,后續我有時間應該會單獨寫一篇文章來討論。
但眼尖的同學可能已經看到了,instanceName 的組成不是 PID 和 System.nanoTime?PID 可能由于獲取的是 Docker 容器宿主機器的 PID,可能是一樣的,可以理解。那 System.nanoTime 呢?這也能重復?
實際上從 RocketMQ 的 Github 這個提交記錄來看,至少在 2021年3月16號之前,這個問題還是有可能存在的。

RocketMQ 官方 Github 的提交記錄
RocketMQ 官方在 3月16號的提交修復了這個問題,給大家看看改了啥:

提交具體內容
在原來的版本中,instanceName 就只由 PID 組成,就完全可能造成不同的消費者實例擁有相同的 instanceName。
熟悉的 RocketMQ 的同學有疑問,在 Broker 側對 Consumer 的唯一標識不是 clientID 嗎?沒錯,但 clientID 是由 clientIP 和 instanceName 一起組成的。
而 clientIP 上面也提到過了,可能由于 Docker 的原因獲取到相同的,會最終導致 clientID 相同。
OK,關于改變實例的名稱就到這,確實沒想到講了這么多。
實例化消費者
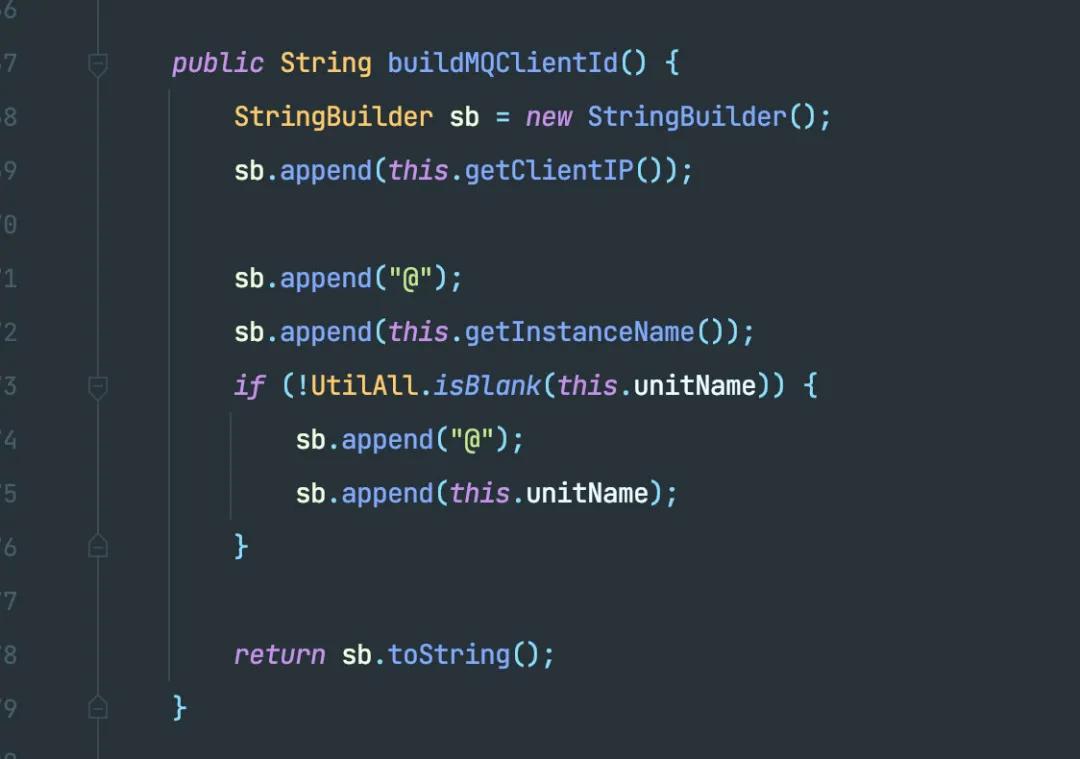
關鍵變量名為 mQClientFactory
接下來就會實例化消費者實例,在上面 改變實例名稱 中講到的 clientID 就是在這一步做的初始化。這里就不給大家列源碼了,你就需要知道這個地方會實例化出來一個消費者就 OK 了,不要過多的糾結于細節。
然后會給 Rebalance 的實現設置上一些屬性,例如消費者組名稱、消息模型、Rebalance 采取的策略、剛剛實例化出來的消費者實例。
這個 Rebalance 的策略默認為:
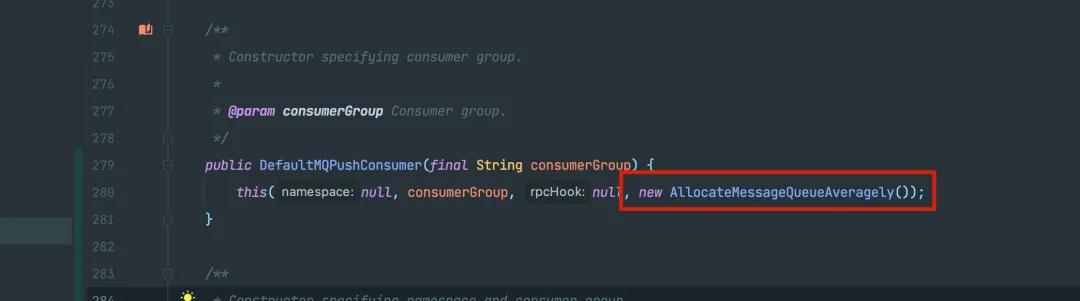
AllocateMessageQueueAveragely 就是一個把 Messsage Queue 平均分配給消費者的策略,更多的細節也可以參考我上面的那篇文章。
除此之外,還會初始化拉取消息的核心實現 PullAPIWrapper。
初始化 offsetStore
這里會根據不同的消息模型(即 BROADCASTING 或者 CLUSTERING),實例化不同的 offsetStore 實現。
- BROADCASTING 采用的實現為 LocalFileOffsetStore
- CLUSTERING 采用的實現為 RemoteBrokerOffsetStore
區別就是 LocalFileOffsetStore 是在本地管理 Offset,而 RemoteBrokerOffsetStore 則是將 offset 交給 Broker 進行原
啟動 ConsumeMessageService
緩存消費者組
接下來會將消費者組在當前的客戶端實例中緩存起來,具體是在一個叫 consumerTable 的內存 concurrentHashMap 中。
其實源碼中叫 registerConsumer:
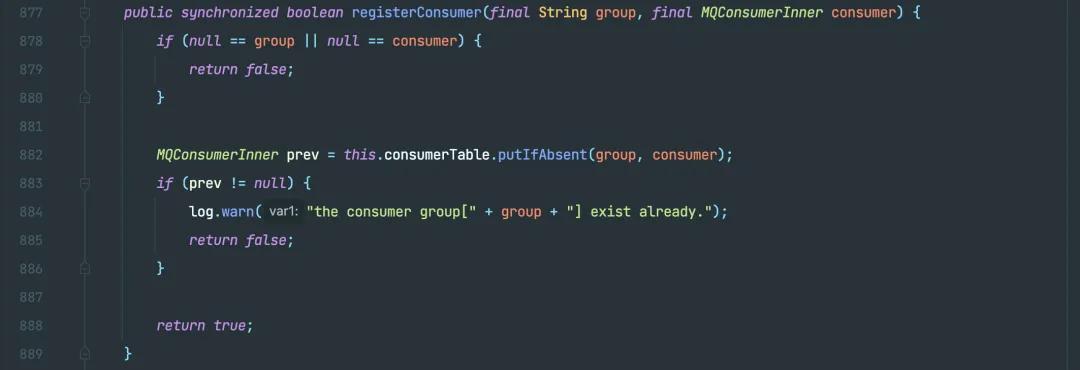
registerConsumer 源碼
但我認為給大家「翻譯」成緩存更合理,因為它就只是把構建好的 consumer 實例給緩存到 map 中,僅此而已。哦對,還做了個如果存在就返回 false,代表實際上并沒有注冊成功。
那為啥需要返回 false 呢?你如果存在了不執行緩存邏輯就好嗎?甚至外面還要根據這個 false 來拋出 MQClientException 異常?
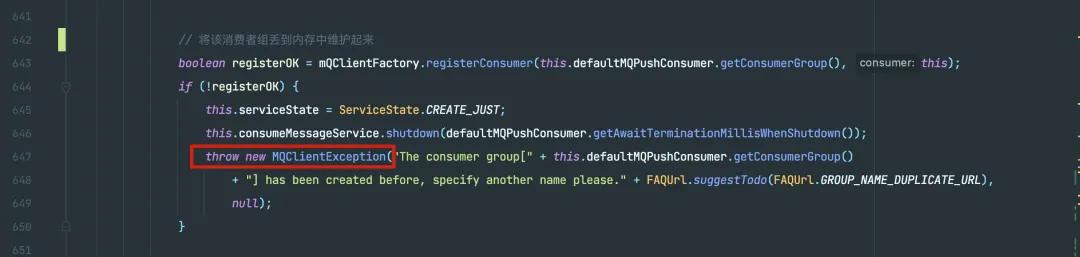
如果注冊失敗,拋出異常
為啥呢?假設你同事 A 已經使用了名稱 consumer_group_name_for_a ,線上正在正常的運行消費消息。得,你加了個功能需要監聽 MQ,也使用了 consumer_group_name_for_a,你想想如果 RocketMQ 不做校驗,你倒是注冊成功了,但是你同事 A 估計要罵娘了:“咋回事?咋開始重復消費了?”
啟動 mQClientFactory
這個 mQClientFactory 就是在 實例化消費者 步驟中創建的消費者實例,最后會通過調用 mQClientFactory.start()。
這就是最后的核心邏輯了。
初始化 NameServer 地址

初始化用于通信的 Netty 客戶端

初始化 Netty 客戶端
啟動一堆定時任務
這個一堆沒有夸張,確實很多,舉個例子:
- 剛剛上面那一步,如果 NameServer 沒有獲取到,就會啟動一個定時任務隔一段時間去拉一次
- 比如,還會啟動定時任務隔一段時間去 NameServer 拉一次指定 Topic 的路由數據。這個路由數據具體是指像 MessageQueue 相關的數據,例如有多少個寫隊列、多少個讀隊列,還有就是該 Topic 所分布的 Broker 的 brokerName、集群和 IP 地址等相關的數據,這些大致就叫路由數據
- 再比如,啟動發送心跳的定時任務,不啟動這個心跳不動
- 再比如,Broker 有可能會掛對吧?客戶端這邊是不是需要及時的把 offline 的 Broker 給干掉呢?所以 RocketMQ 有個 cleanOfflineBroker 方法就是專門拿來干這個的
- 然后有一個比較關鍵的就是持久化 offset,這里由于是采用的 CLUSTERING 消費,故會定時將當前消費者消費的情況上報給 Broker













