













兩種最為常用的數(shù)據(jù)挖掘方法論
本文轉(zhuǎn)載自微信公眾號(hào)「數(shù)倉(cāng)寶貝庫(kù)」,作者趙仁乾 等。轉(zhuǎn)載本文請(qǐng)聯(lián)系數(shù)倉(cāng)寶貝庫(kù)公眾號(hào)。
01CRISP-DM方法論
CRISP-DM方法論由NCR、Clementine、OHRA和Daimler-Benz的數(shù)據(jù)挖掘項(xiàng)目總結(jié)而來,并被SPSS公司大力推廣。CRISP-DM方法論將數(shù)據(jù)挖掘項(xiàng)目的生命周期分為6個(gè)階段,分別是商業(yè)理解、數(shù)據(jù)理解、數(shù)據(jù)準(zhǔn)備、建模、評(píng)估和準(zhǔn)備工作,如圖1所示。在實(shí)際項(xiàng)目進(jìn)行過程中,由于使用者的目標(biāo)背景和興趣不同,有可能打亂各階段順承的關(guān)系。
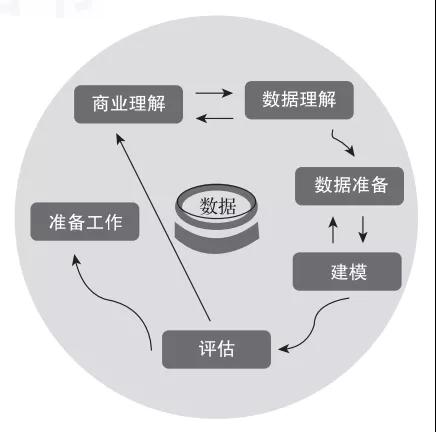
圖1 CRISP-DM方法論
圖1呈現(xiàn)了CRISP-DM方法執(zhí)行流程的6個(gè)階段。各個(gè)階段的順序不是保持不變的,有時(shí)需要在某個(gè)階段向前或向后移動(dòng),這取決于每個(gè)階段的結(jié)果和下一個(gè)階段的具體任務(wù)。箭頭指出了各個(gè)階段之間的關(guān)聯(lián)。
在圖1中,最外圈的循環(huán)表示數(shù)據(jù)挖掘本身的循環(huán)特征。數(shù)據(jù)挖掘是一項(xiàng)持續(xù)的工作。在上一個(gè)流程和解決方案中獲得的經(jīng)驗(yàn)與教訓(xùn),可以給下一個(gè)項(xiàng)目提供指導(dǎo)。下面簡(jiǎn)要介紹每個(gè)階段的特點(diǎn)。
1)商業(yè)理解。該階段的特點(diǎn)是從商業(yè)角度理解項(xiàng)目的目標(biāo)和要求,通過理論分析找出數(shù)據(jù)挖掘可操作問題,制訂實(shí)現(xiàn)目標(biāo)的初步計(jì)劃。
2)數(shù)據(jù)理解。該階段開始于原始數(shù)據(jù)的收集,然后是熟悉數(shù)據(jù)、標(biāo)明數(shù)據(jù)質(zhì)量問題、探索對(duì)數(shù)據(jù)的初步理解、發(fā)掘有趣的子集,以形成對(duì)探索關(guān)系的假設(shè)。
3)數(shù)據(jù)準(zhǔn)備。該階段包括所有從原始的、未加工的數(shù)據(jù)構(gòu)造數(shù)據(jù)挖掘所需信息的活動(dòng)。數(shù)據(jù)準(zhǔn)備任務(wù)可能被實(shí)施多次,而且沒有任何規(guī)定的順序。這些任務(wù)的主要目的是從源系統(tǒng)根據(jù)維度分析的要求,獲取所需要的信息,同時(shí)對(duì)數(shù)據(jù)進(jìn)行轉(zhuǎn)換和清洗。
4)建模。該階段主要是選擇和應(yīng)用各種建模技術(shù),同時(shí)對(duì)參數(shù)進(jìn)行校準(zhǔn),以達(dá)到最優(yōu)值。通常,同一類數(shù)據(jù)挖掘問題會(huì)有多種建模技術(shù)。一些技術(shù)對(duì)數(shù)據(jù)格式有特殊的要求,因此常常需要返回到數(shù)據(jù)準(zhǔn)備階段。
5)評(píng)估。在模型最后發(fā)布前,根據(jù)商業(yè)目標(biāo)評(píng)估模型和檢查模型建立的各個(gè)步驟。此階段的關(guān)鍵目的是,確認(rèn)重要的商業(yè)問題都得到充分考慮。
6)準(zhǔn)備工作。模型完成后,由模型使用者(客戶)根據(jù)當(dāng)時(shí)的背景和目標(biāo)完成情況,決定如何在現(xiàn)場(chǎng)使用模型。
02SEMMA方法論
除了CRISP-DM方法論,SAS公司還提出了SEMMA方法論。其與CRISP-DM方法論內(nèi)容十分相似,流程為定義業(yè)務(wù)問題、環(huán)境評(píng)估、數(shù)據(jù)準(zhǔn)備、循環(huán)往復(fù)的挖掘過程、上線發(fā)布、檢視。其中循環(huán)往復(fù)的挖掘過程包含探索、修改、建模、評(píng)估和抽樣5個(gè)步驟,如圖2所示。
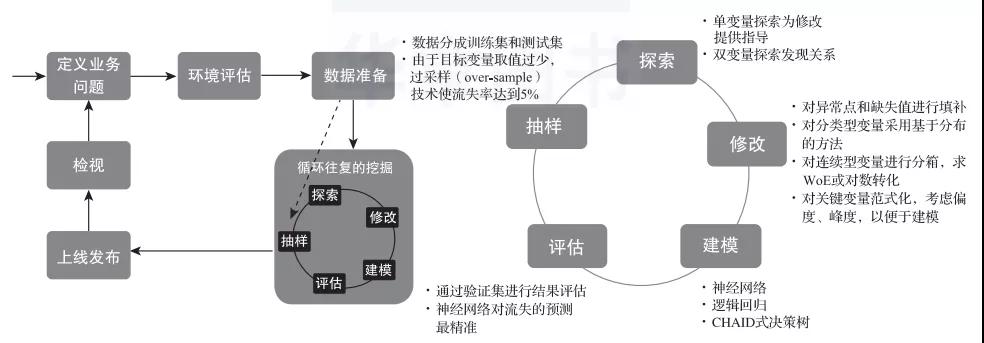
圖2 SEMMA方法論
1)抽樣。該步驟涉及數(shù)據(jù)采集、數(shù)據(jù)合并與抽樣操作,目的是構(gòu)造分析時(shí)用到的數(shù)據(jù)。分析人員將根據(jù)維度分析獲得的結(jié)果作為分析的依據(jù),將散落在公司內(nèi)部與外部的數(shù)據(jù)進(jìn)行整合。
2)探索。這個(gè)步驟有兩個(gè)任務(wù),第一個(gè)是對(duì)數(shù)據(jù)質(zhì)量的探索。變量質(zhì)量方面涉及錯(cuò)誤值(年齡=-30)、不恰當(dāng)(客戶的某些業(yè)務(wù)指標(biāo)為缺失值,實(shí)際上是沒有這個(gè)業(yè)務(wù),值應(yīng)該為“0”)、缺失值(沒有客戶的收入信息)、不一致(收入單位為人民幣,而支出單位為美元)、不平穩(wěn)(某些數(shù)據(jù)的均值變化過于劇烈)、重復(fù)(相同的交易被記錄兩次)和不及時(shí)(銀行客戶的財(cái)務(wù)數(shù)據(jù)更新滯后)等。探索步驟主要解決錯(cuò)誤的變量是否可以修改、是否可以使用的問題。比如,缺失值很多,平穩(wěn)性、及時(shí)性很差的變量不能用于后續(xù)的數(shù)據(jù)分析,而缺失值較少的變量需要進(jìn)行缺失值填補(bǔ)。第二個(gè)是對(duì)變量分布形態(tài)的探索。對(duì)變量分布形態(tài)的探索主要是對(duì)變量偏態(tài)和極端值進(jìn)行探索。由于后續(xù)的統(tǒng)計(jì)分析大多是使用參數(shù)統(tǒng)計(jì)方法,這要求連續(xù)變量最好是對(duì)稱分布的,這就需要我們了解每個(gè)連續(xù)變量的分布情況,并制定好變量修改的方案。
3)修改。根據(jù)變量探索的結(jié)論,對(duì)數(shù)據(jù)質(zhì)量問題和分布問題涉及的變量分別做修改。數(shù)據(jù)質(zhì)量問題涉及的修改包括錯(cuò)誤編碼改正、缺失值填補(bǔ)、單位統(tǒng)一等操作。變量分布問題涉及的修改包括函數(shù)轉(zhuǎn)換和標(biāo)準(zhǔn)化,具體的修改方法需要與后續(xù)的統(tǒng)計(jì)建模方法相結(jié)合。
4)建模。根據(jù)分析的目的選取合適的模型,這部分內(nèi)容在1.3節(jié)已經(jīng)做了詳細(xì)的闡述,這里不再贅述。
5)評(píng)估。這里指模型的樣本內(nèi)驗(yàn)證,即使用歷史數(shù)據(jù)對(duì)模型表現(xiàn)的優(yōu)劣進(jìn)行評(píng)估。比如,對(duì)有監(jiān)督學(xué)習(xí)使用ROC曲線和提升度等技術(shù)指標(biāo)評(píng)估模型的預(yù)測(cè)能力。
本文摘編自《金融商業(yè)算法建模:基于Python和SAS》,經(jīng)出版方授權(quán)發(fā)布。













